
XGBoost机器学习模型对乙型肝炎肝硬化诊断的应用价值研究
2023-07-20 02:55韩可兴沈佳培孙伟杰郜玉峰
世界华人消化杂志 2023年13期
李 季,韩可兴,沈佳培,孙伟杰,高 龙,郜玉峰
李季,韩可兴,沈佳培,孙伟杰,高龙,郜玉峰,安徽医科大学第一附属医院感染病科 安徽省合肥市 230032
0 引言
乙型肝炎病毒(hepatitis B virus,HBV)感染对世界公共卫生带来巨大的挑战,相关研究表明全球估计有2.4亿人最终转变为慢性乙型肝炎病毒感染(chronic hepatitis B virus infection,CHBV)[1].我国作为HBV感染大国,CHBV是引起肝硬化的主要原因[2].同时,由于CHBV进展到肝硬化的患者常在失代偿期后才会出现一系列临床症状,例如门静脉高压以及由此导致的急危重症,这导致肝硬化代偿期常因无明显的临床症状而被患者所忽略[3].然而,失代偿期肝硬化会进一步增加患者的死亡率和肝细胞癌(hepatocellular carcinoma,HCC)的发生率[4].正因如此,如何更早的识别CHBV合并肝硬化具有重要的临床意义.
肝活检是诊断肝硬化的金标准,但由于有创性且费用昂贵难以被需要反复进行肝脏状态评估的患者所接受[5,6].此外,由于活检样本通常很小,这导致肝活检的准确性依然是值得怀疑的[7,8].并且由于观察者之间存在解释误差,病理学家之间的诊断意见可能不同[9].肝脏超声瞬时弹性成像(liver ultrasound transient elastography,LUTE)是近年来被大家所接受的能够准确评估肝脏硬度的有效工具[10].然而,不仅LUTE设备的价格,检查中需要配备的探头和后期的维护费用都是昂贵的[11],这导致基层医疗机构可能无法满足患者接受LUTE检查的需求.所以,基于实验室血清学检查指标而建立的针对肝硬化及肝纤维化的无创评分成为研究的热点.例如如谷草转氨酶与血小板比率指数(aspartate aminotransferase/platelet ratio index,APRI)、纤维蛋白-4(fibrosis-4 index,FIB-4)、BARD评分等已经被用于临床工作.其中APRI和FIB-4主要应用于慢性丙型肝炎患者晚期肝纤维化的诊断,但容易受年龄和体重因素的干扰[12,13].而BARD评分虽然简便易行,但准确性很低并且仍需有效的验证队列对其准确性进行验证[14].因此,上述评分可能主要应用于严重肝纤维化的诊断,但对于代偿期肝硬化的预测价值仍需进一步明确[12,13].总之,目前仍需要寻求有效的针对肝硬化的无创评分[15],虽然部分影像学诊断可以有效的判别肝硬化,但在大规模筛查研究中基于血清标志物的无创评分仍是必不可少的[16].
极限梯度提升机(eXtreme gradient boosting,XGBoost)机器学习模型是一种集成的学习算法,与传统机器学习模型不同的是,XGBoost机器学习模型是取所有模型的和为输出,其能在模型运算过程中寻找最优树结构从而发挥更好的拟合作用并且具备更好的模型稳定性,对于存在缺失特征值的样本,XGBoost算法还可以自动学习其分裂方向从而获得最佳的预测效果[5].XGBoost机器学习模型作为一种人工智能算法在医学领域中逐渐成熟,在各种疾病的诊断、治疗和管理中发挥巨大的作用[6-8].
综上,本研究拟基于临床获取的患者一般特征学信息和实验室指标构建XGBoost机器学习模型用以预测CHBV合并肝硬化的发生,为临床对于肝硬化的管理提供参考依据.
1 材料和方法
1.1 材料 选取2010-01/2018-10初次就诊于安徽医科大学第一和第二附属医院感染科的CHBV患者为研究对象,所有患者均未接受治疗.依据中华医学会感染病学分会制定的《慢性乙型肝炎防治指南(2019版)》[17]诊断CHB;依据中华医学会肝病学会制定的《肝硬化诊治指南》诊断肝硬化[18].对以下患者进行排除[19]: (1)合并其他病毒性肝炎;(2)合并酒精性肝病、自身免疫性肝病、药物毒物肝病、遗传代谢性肝病、寄生虫肝病、胆汁淤积性肝病、循环障碍导致肝病及肝脏肿瘤患者;(3)合并其他可能引起肝脏硬度发生改变的肝外疾病,如结缔组织病、慢性阻塞性肺疾病、肺间质纤维化、糖尿病、血液病等.本研究经医院医学伦理委员会批准,所有研究对象均签署了书面的知情同意书.
1.2 方法 收集所有研究对象就诊时的年龄、性别信息.留取24 h内血液样本送检,包括血常规、生化常规、HBV DNA定量检测等.具体指标包括白细胞计数(white blood cell,WBC)、血小板计数(platelet counts,PLT)、甲胎蛋白(alpha fetoprotein,AFP)、白蛋白(albumin,ALB)、球蛋白(globulin,GLB)、谷氨酸氨基转移酶(alanine aminotransferase,ALT)、谷草转氨酶(aspartate aminotransferase,AST)、谷氨酰转肽酶(glutamyl transpeptidase,GGT)、HBV DNA定量.
统计学处理所有数据的处理均通过R(http://www.R-project.org)和EmpowerStats(http://www.empowerstats.com)软件实现.符合正态分布的连续性变量采用均数±标准差(mean±SD)的形式表示,否则采用中位数及四分位数表示,分类变量采用百分比表示.加权线性回归(用于连续性变量)和加权χ2(用于分类变量)用于评估组间差异.在建立XGBoost机器学习模型前,首先基于正则化原理消除了预测变量之间的共线性以防止过度拟合.随后,设置了相应的迭代次数(n-rounds)以提高模型的预测效能.最终模型的主要设置参数如下: booster=gbtree,objective=binary:logistic,learning rate (eta)=0.3,gamma=5,max depth=6,min_child_weight=1,subsample=1,colsample_bytree=1,n-rounds=100.通过获取每个预测变量的Gain值绘制出所有预测变量的相对重要度的排序图.计算公式为: 相对重要度=[(1/第一位变量Gain值)×其他变量Gain值].我们计算了系统的评价指标以对我们建立的模型进行评估.准确度和AUC主要用于评估模型的预测能力,Logloss表示预测概率与实际概率之间的拟合程度,其值越小表示拟合概率越高.而召回率和F1评分主要评估数据不均衡时该模型的综合评估能力[20].Kappa值主要用于评估所建立的模型是否具有较好的可重复性,依据既往研究我们认为当Kappa值≥0.40时提示所建立的模型具有良好的可重复性[5].绘制DCA曲线以评估临床适用性,产生CA曲线以评估模型的校准度.aP<0.05说明具有统计学差异.
2 结果
2.1 训练集与验证集研究对象临床特征 最终本研究共纳入研究对象1087例,按照3:1的比例随机原则拆分为训练集(817例)和验证集(270例).其中训练集研究对象发生肝硬化103例,验证集32例.训练集和验证集之间所有的临床资料具有均衡性(表1).在训练集中除HBV DNA、GLB、ALT之外,两组间其余指标均存在明显的统计学差异(P<0.05)(表2).
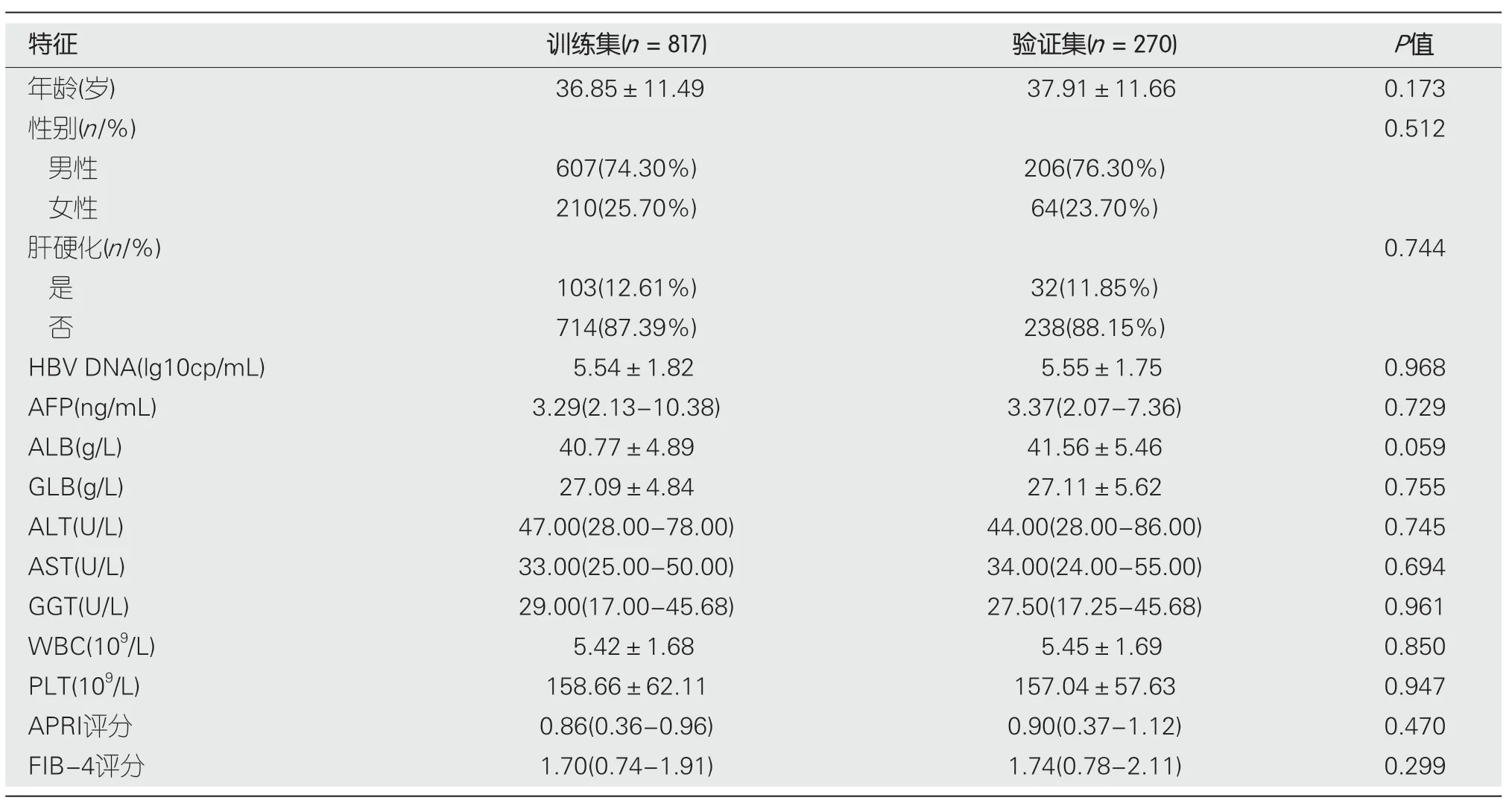
表1 训练集与验证集临床特征资料

表2 训练集患者临床特征资料
2.2 肝硬化XGBoos机器学习模型的建立 所有预测变量均进入模型,依据图1结果可知血小板的相对重要度最高.通过混淆矩阵图展示了训练队列中真阳性、真阴性、假阳性和假阴性参与者的具体细节(图2A).训练集阳性预测值(0.90)和阴性预测值(0.95)提示所建立的模型对肝硬化和非肝硬化的研究对象都具有较高的预测率,模型准确度为0.95.运用ROC曲线下面积评估所建立模型对于CHB合并肝硬化患者的预测效能,AUC为0.95,提示所建立模型具有较高的预测效能(表3,图3).训练集建立的模型Logloss值为0.15,提示肝硬化的预测概率与实际概率之间拟合度良好.同时,召回率(0.73)和F1评分(0.81)提示所建立模型对不均衡数据同样具有较好的预测效能.Kappa值为0.78,提示目前所建立的模型具有较好的可重复性.利用训练集所建立的XGBoost机器学习模型评估指标见表2.校准曲线提示预测值与实际值之间具有良好的一致性(图4A).DCA曲线的含义是经预测模型评估后进行干预的患者是否能够比那些未经评估直接进行干预或者不进行干预的患者有更好的获益度.依据图5可知经预测模型评估后能够使患者获得更好的获益度.
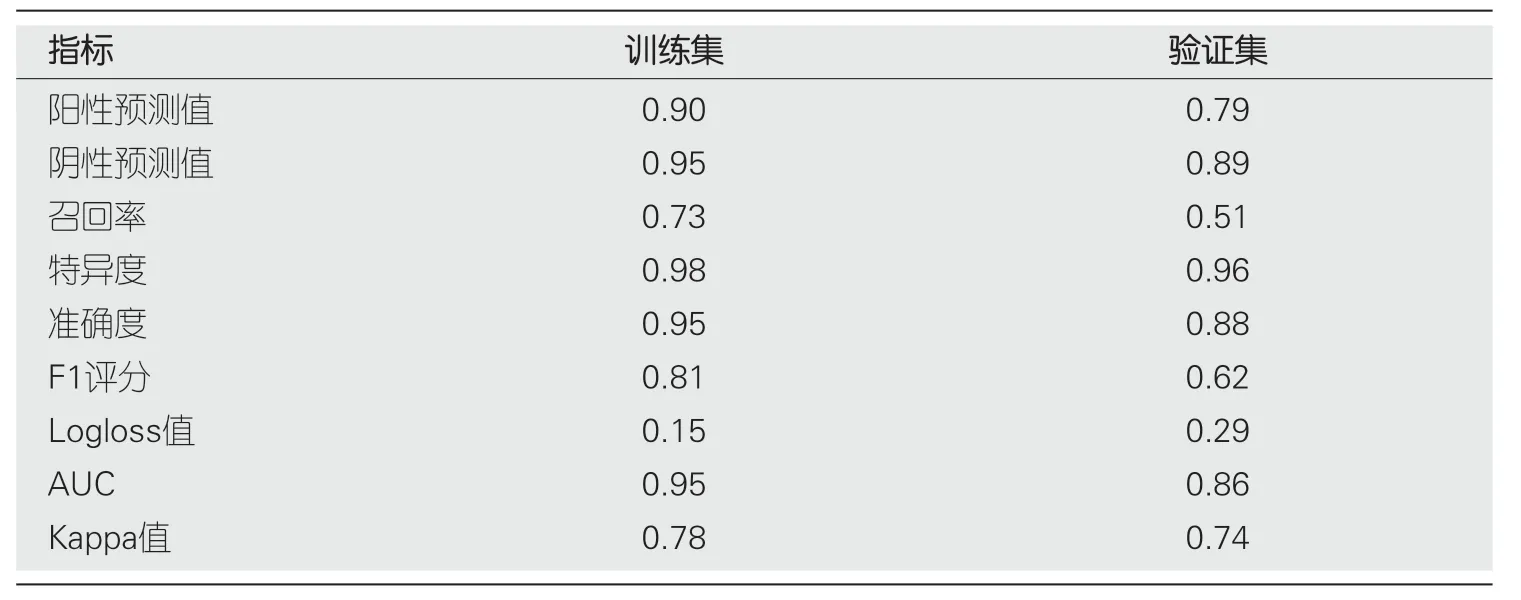
表3 训练集和验证集模型评价指标

图1 预测变量相对重要度排序图.PLT: 血小板计数;AFP: 甲胎蛋白;ALB: 白蛋白;GGT: 谷氨酰转肽酶;AST: 谷草转氨酶;WBC: 白细胞计数;GLB: 球蛋白;HBV DNA: 乙型病毒性肝炎脱氧核糖核酸;ALT: 谷氨酸氨基转移酶.
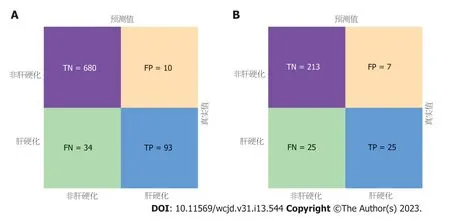
图2 XGBoost机器学习模型预测CHB合并肝硬化混淆矩阵图.A: 训练集;B: 验证集.TP: 真阳性;FP: 假阳性;TN: 真阴性;FN: 假阴性.XGBoost: 极限梯度提升机;CHB: 慢性乙型肝炎.

图3 XGBoost机器学习模型预测CHBV合并肝硬化ROC曲线图.ROC曲线: 受试者工作特征曲线;AUC: 受试者工作特征曲线下面积;XGBoost: 极限梯度提升机;CHBV: 慢性乙型肝炎病毒感染.
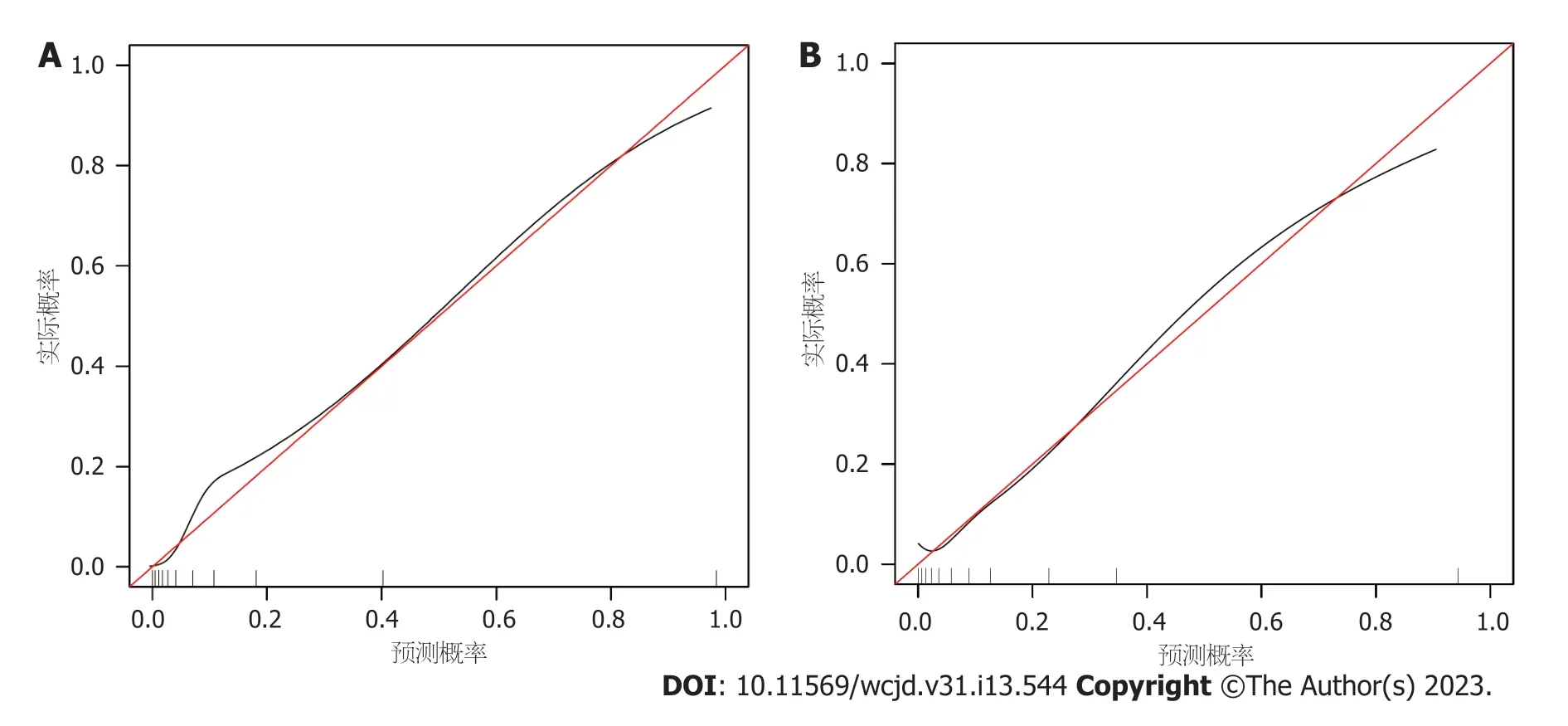
图4 XGBoost机器学习模型预测CHBV合并肝硬化校准曲线图.A: 训练集;B: 验证集.XGBoost: 极限梯度提升机;CHBV: 慢性乙型肝炎病毒感染.
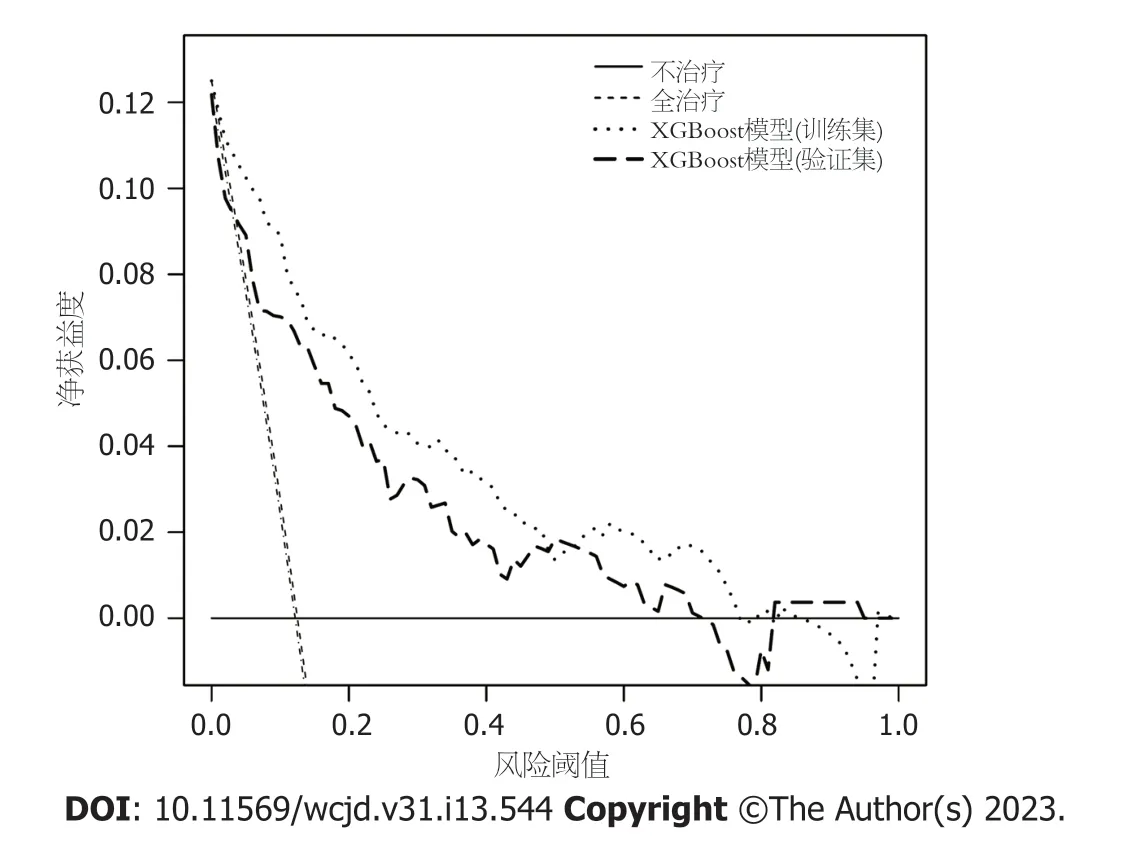
图5 XGBoost机器学习模型预测CHB合并肝硬化决策曲线图.XGBoost: 极限梯度提升机;CHB: 慢性乙型肝炎.
2.3 肝硬化XGBoos机器学习模型的内部验证 我们利用验证集对上述建立的模型进行了验证,验证集中模型评估指标见表3.混淆矩阵图提示XGBoost模型筛选出的真阳性(肝硬化)病例数为25,真阴性(非肝硬化)的病例为213例(图2B).验证集阳性预测值(0.79)和阴性预测值(0.89)提示所建立的模型在验证集中对肝硬化和非肝硬化的研究对象同样具有较高的预测率.验证集中XGBoost模型准确度为0.88,AUC为0.86,提示模型具有较高的预测效能(图3).召回率(0.51)和F1评分(0.96)提示所建立模型在验证集中对不均衡数据同样具有较好的预测效能.Kappa值为0.74,提示目前所建立的模型在验证集中同样具有较好的可重复性(表3).校准曲线提示验证集中预测值与实际值之间具有良好的一致性(图4).DCA曲线提示验证集中经XGBoost模型评估后接受干预的患者较未经评估直接进行干预或者不进行干预的患者有更好的获益度(图5).
2.4 多个模型的比较 为了更好地展示本研究中肝硬化XGBoos机器学习模型的优势,我们将其与经典的用以评估肝硬化的APRI评分和FIB-4评分进行了比较.依据结果可知,在训练集中APRI评分与FIB-4评分的AUC分别为0.772和0.809,验证集中分别为0.747和0.785(图6).两个经典评分对于肝硬化的区分度都小于XGBoost机器学习模型.此外,APRI评分和FIB-4评分的校准曲线提示训练集和验证集中的预测值与实际值之间的一致性较差(图7).两个经典评分的DCA曲线提示经APRI评分和FIB-4评分评估后接受干预的患者虽然能够提高患者的获益度,但明显低于XGBoost机器学习模型(图8).
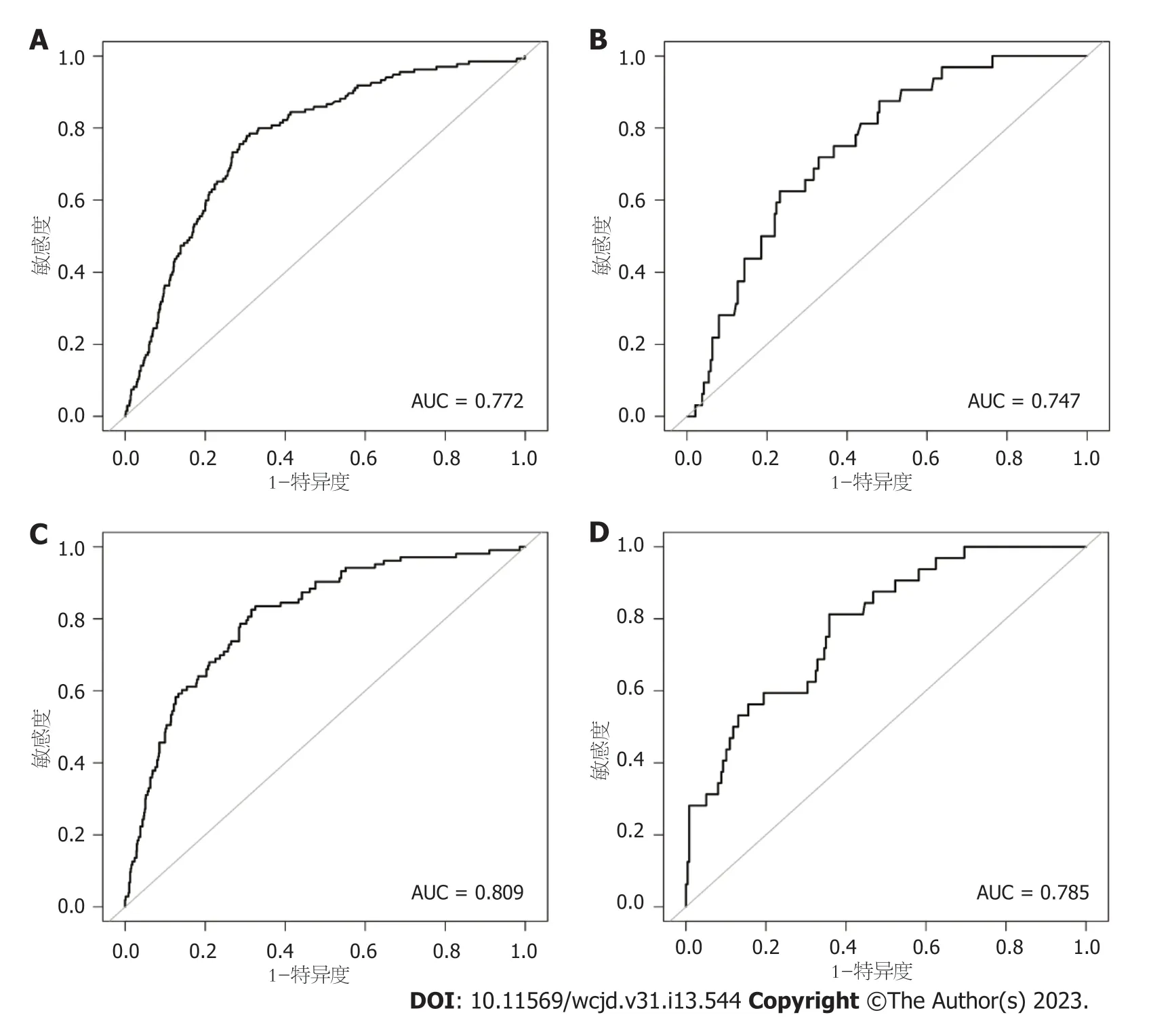
图6 APRI评分和FIB-4评分预测CHBV合并肝硬化ROC曲线图.A: APRI评分(训练集);B: APRI评分(验证集);C: FIB-4评分(训练集);D: FIB-4评分(验证集).AUC: 受试者工作特征曲线下面积;CHBV: 慢性乙型肝炎病毒感染;ROC曲线: 受试者工作特征曲线.

图7 APRI评分和FIB-4评分预测CHBV合并肝硬化校准曲线图.A: APRI评分(训练集);B: APRI评分(验证集);C: FIB-4评分(训练集);D: FIB-4评分(验证集).CHBV: 慢性乙型肝炎病毒感染;APRI: 谷草转氨酶与血小板比率指数;FIB-4: 纤维蛋白-4.
3 讨论
我国是慢性HBV感染大国,不幸的是,尽管核苷(酸)类似物或干扰素可以有效地抑制HBV复制,但这些都不是治愈性的治疗方法[21].这些药物不直接靶向共价闭环DNA,这是负责肝内病毒持续存在的关键分子[22].持续活化的乙型肝炎病毒通过介导免疫应答导致肝脏细胞的坏死和炎症,长期的肝细胞坏死和纤维组织增生导致许多患者最终发展成为肝硬化甚至肝纤维化[23].尽管肝活检能够准确肝硬化,但很多因素限制了这种检测手段被更多的患者所接受,尤其是没有任何临床症状的早期肝硬化群体.为了克服肝活检的局限性,目前对于非侵入性技术来评估肝脏僵硬度逐渐成为了热点[24].本研究利用临床便于获取的资料构建了能够有效预测CHB合并肝硬化的XGBoost机器学习预测模型并进行了内部验证.
通过相对重要度排序图可知排在前5位的预测因子分别是血小板、AFP、ALB、GGT和年龄.血小板是骨髓中来源于巨核细胞的无核细胞碎片,在止血中起关键作用[25].血小板减少是肝硬化患者常见的并发症,其发病机制不是单一的[26,27].既往研究已经报道了血小板在脾脏中被破坏增加是由于门静脉高压引起的脾脏增大的结果[28],最近的研究表明[29],肝脏中TPO生成减少和骨髓中血小板生成受损是额外的因素.除此之外,PLT相关的免疫球蛋白升高导致PLT刺激因子减少也是主要的原因[30].因此,以PLT为预测因子能够建立对肝硬化的预测模型得到了研究者们的一致认可[19,31].甲胎蛋白于1964年首次在肝细胞癌(hepatocellular carcinoma,HCC)患者的血清中发现,此后一直是HCC的主要诊断生物标志物[32].除此之外,非HCC疾病也可以出现AFP的升高,例如肝硬化、肝炎、胆管癌、睾丸生殖细胞瘤和转移性结肠癌[33],在肝脏良性疾病中,相关研究表明肝硬化的AFP含量较肝炎升高明显[34],这也与本研究的结果相似.白蛋白是血清(3.5 g/dL-5.0 g/dL,约占所有血清蛋白的一半)和细胞外液中最丰富的蛋白质[35],主要由肝脏细胞产生,其不仅反应机体的基础营养水平,而且可以反应肝脏细胞结晶片段受体(FcRn)的表达能力,肝硬化患者由于FcRn表达的减低而白蛋白生成减少[36].γ-GGT位于肝细胞的毛细血管表面和胆管上皮细胞的膜侧,是一种膜结合酶[37],其不仅反应胆汁分泌阻塞和胆管损伤的程度,也是是反应肝细胞损伤的重要标记物[38],并且既往研究证明GGT与单纯的ALT及AST相比对肝硬化可能具有更好的预测价值[39],这与本研究的结果相同.随着公共卫生工作的努力,目前HBV的主要传播途径是母婴传播,这也导致CHB的年龄分布与其他非传染性慢性疾病不同.既往研究表明CHB患病率与年龄成负向相关关系[40],因此年龄越高的CHB患者往往有更长的CHB病程让人容易理解,这使得年龄成为CHB合并肝硬化的高危因素,本研究结果与既往研究类似[41].
4 结论
本研究依然存在一定的局限性.首先,所有纳入的研究对象均未接受任何病毒治疗,经治疗后的患者能否适用于本研究的结论仍需经标准治疗方案条件下的队列研究证明.第二,由于发生肝硬化的阳性病例数不足所有病例数的20%,目前建立的模型整体敏感性一般,目前的结论仍需更多样本的支持.最后,本研究中对模型进行了内部验证,但未能得到外部队列的验证,这也导致目前的研究结果在外推时受到一定的局限性.然而,目前模型所利用的预测变量在既往研究中均以得到了证明,本研究的结果依然能够证明XGBoost机器学习模型在CHB合并肝硬化预测中的价值.
文章亮点
实验背景
慢性乙型肝炎病毒感染(chronic hepatitis B virus infection,CHBV)进展至肝硬化是一个缓慢的过程,在肝硬化失代偿期发生之前常因无明显的临床症状而被患者忽略.肝硬化失代偿期时不良事件的结局发生率升高明显,这使得肝硬化的无创评估成为研究热点.然而,目前有关肝硬化早期诊断的机器学习模型仍是缺乏的.
实验动机
本研究重点探究CHBV患者的年龄、性别以及常规血清学指标所建立的极限梯度提升机(eXtreme gradient boosting,XGBoost)机器学习模型预测肝硬化的有效性.旨在为CHBV患者提供安全、无创、简便、实用的诊断方法.
实验目标
基于CHBV患者的年龄、性别以及常规血清学指标等信息建立预测CHB进展为肝硬化的机器学习模型,为肝硬化的管理提供参考.
实验方法
选取2010-2018年首次就诊于安徽医科大学第一附属医院和第二附属医院并行肝活检的CHBV患者.按照随机原则以3:1的比例将所有患者分为训练集和验证集.利用训练集患者一般资料及常规血清学指标构建XGBoos机器学习模型,并利用验证集进行内部验证.同时,计算谷草转氨酶与血小板比率指数(aspartate aminotransferase/platelet ratio index,APRI)、纤维蛋白-4(fibrosis-4 index,FIB-4)评分并与研究中构建的模型进行比较.受试者工作特征曲线下面积(area under curve,AUC)以评估模型区分度,校准曲线(calibration curve,CA)及决策曲线(decision curve analysis,DCA)以评估模型校准度及获益度.
实验结果
最终纳入研究的CHBV病例1087例,其中训练集817例,验证集270例.训练集中有103例患者发生肝硬化,肝硬化患者APRI和FIB-4评分明显高于非肝硬化患者(P<0.05).在训练集中,所有预测因子中血小板的相对重要度最高.利用训练集构建的XGBoost机器学习提示后的结果提示AUC为0.95,验证集的AUC为0.86,两者Kappa值分别为0.78和0.74.CA曲线提示模型预测情况与真实情况拟合情况吻合度较高.训练集和验证集的DCA曲线提示所建立模型能够使患者获得较高的获益度.研究中构建的XGBoost机器学习模型对于肝硬化的预测效能优于APRI评分和FIB-4评分.
实验结论
以CHBV患者的年龄、性别以及常规血清学指标为预测变量构建的XGBoost机器学习模型具有较好的预测效能,有助于肝硬化早期发现,使患者获益.
展望前景
本研究证实了利用常规资料构建XGBoost模型在预测CHBV进展为肝硬化时的可行性.基于XGBoost的优势,随着更多有效的预测变量被纳入模型,预测效能将会进一步提升.未来的研究重点在于提高临床资料的完整性和多样性,保持对有关CHBV的新型血清标志物的关注并及时纳入模型进行验证.
猜你喜欢
出版人(2022年8期)2022-08-23
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
肝博士(2020年4期)2020-09-24
英语文摘(2020年6期)2020-09-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
电影(2018年8期)2018-09-21
解放军健康(2017年5期)2017-08-01
中国卫生标准管理(2015年4期)2016-01-14
Coco薇(2015年10期)2015-10-19
