
字轮式仪表智能图像抄表系统的设计
2023-07-17 08:25:38顾允迪徐望明
液晶与显示 2023年7期
顾允迪,徐望明,2*,何 钦
(1. 武汉科技大学 信息科学与工程学院,湖北 武汉 430081;2. 武汉科技大学 教育部冶金自动化与检测技术工程研究中心,湖北 武汉 430081)
1 引 言
随着中国物联网技术的发展,基于物联网的智能仪表正逐渐取代老式机械仪表,但是生活中仍然存在着大量老式字轮表(如水表、电表、燃气表等)需要进行抄表。传统人工抄表方式存在着工作效率低、工作量大且容易出错的问题,自动抄表(Automatic Meter Reading,AMR)已成为一种必然趋势,已经有许多相关的设计被提出。基于M-Bus 总线或RS-485 总线的有线抄表技术通过在一定区域铺设电缆对该区域仪表进行集中读数,虽然解决了低效的问题,但在已投入使用的建筑中铺设电缆会影响用户的日常生活和业务[1]。使用GPRS 远程通信技术虽然可靠性高、覆盖面广、成本低,但是存在用户容量小、信号差的问题[2],且随着2G 退网,GPRS 网络用户数量将会日益萎缩。基于LoRa 的远程通信技术虽然在电池寿命和成本上有优势,但是其服务质量(QoS)、通信延迟和可靠性相对较差[3-4]。相比之下,窄带物联网(NB-IoT)技术具有高服务质量、高可靠性、高覆盖、低延迟、低功耗、低成本等优势,可广泛应用于远程抄表系统[5-8]。
近年来,光学字符识别(Optical Character Recognition,OCR)技术飞速发展[9-10],国内外学者基于OCR 技术在仪表读数识别任务中展开了大量研究。早期的识别方法采用传统图像处理技术,如模板匹配[11-13]和特征提取及分类[14],依赖预先做好的字符模板或人工设计的特征,对图像质量要求高,鲁棒性较差且对字轮表中出现的双半字符(两个读数字符均出现一部分)的情况识别效果较差。随着神经网络特别是卷积神经网络(CNN)和循环神经网络(RNN)的广泛应用,对图像质量差、环境复杂的仪表图像读数识别成为可能。王志威等[15]改进残差网络[16]在分割出的二值字符图像上训练分类网络。王望等[17]训练了一个轻量级CNN 用于二值字符图像分类,并通过合成二值双半字符图像解决了双半字符训练样本少的问题。上述方法依赖于图像二值化效果,对表盘表面存在污渍或复杂光照情况的鲁棒性较差。杨帆等[18]设计了一个全卷积序列识别网络(FCSRN),基于CTC[19]损失函数提出一种增强损失函数,样本标签不用真实标签而用双半字符中“较低状态”的字符标签,引导模型将双半字符识别为“较低状态”字符而非“较高状态”字符。综上所述,字轮式仪表读数识别的难点主要在于存在的双半字符训练样本少及双半字符与其对应的两个单字符具有较大相似性,故双半字符的识别更具挑战性。
目前已有部分基于物联网技术与图像处理技术的自动抄表系统被提出。马学文[20]针对指针式工业仪表使用STM32F407作为主控制器,使用4G 模块将采集的图像上传至云端,设计了基于Hough 变换与径向灰度统计的指针式仪表读数识别方法。江亚杰[21]针对LCD 段码表使用树莓派作为边缘计算平台,设计了基于Faster-RCNN的读数识别算法并通过WIFI 模块将识别的读数上传至云端。王杜毅等[22]使用ARM926 作为主控制器,使用当前采集图像与模板图像的差值进行压缩感知从而降低了使用NB-IoT 传输图像过程中的功耗。不同的系统设计可以解决不同的实际问题。
针对以上问题,本文设计了一种基于NB-IoT和轻量级CNN 的智能抄表系统,通过NB-IoT 模组将采集的表盘图像远程传输至云平台并在云平台内对表盘图像自动识别读数,实现了对水表、电表、燃气表等字轮式仪表的智能远程抄表。同时,设计了一种基于多标签分类的轻量级CNN 模型识别表盘读数,提高了表盘读数字符尤其是双半字符的识别精度,并通过实验证明了其有效性。
2 系统总体框架
如图1 所示,本文设计的智能图像抄表系统以NB-IoT 网络为基础,主要由采集层、传输层、应用层组成。

图1 智能抄表系统结构Fig.1 Structure of intelligent meter reading system
采集层为安装在字轮式仪表上的图像采集终端,具有定时采集图像、向云平台发送图像数据、接收云平台下发的指令等功能;传输层为整个系统的桥梁,连接图像采集终端与云平台,以MQTT 协议实现图像数据的上传及云平台指令的分发;应用层为云平台,包括接收图像数据、下发指令、读数识别、管理系统等功能。为了降低功耗、延长电池使用时间,图像采集终端平时处于休眠模式,当需要采集和上传图像数据时便会自动唤醒。当云平台接收到图像后便会自动对其进行识别,先定位得到每个读数字符的位置信息并分割出相应的子图像,然后使用离线训练好的字符识别模型对每个读数字符子图像进行识别,从而得到当前表盘的完整读数。
3 图像采集终端设计
3.1 图像采集终端硬件设计
图像采集终端总体结构及实物电路板如图2所示。电源模块包括电池与线性稳压电源,分别为Air302 模组、AT32 微控制器、摄像头及照明模块供电。照明模块为多组高亮LED,为系统提供辅助光源,保证摄像头采集到清晰的表盘图像。AT32 微控制器通过GPIO 接口与摄像头模组及照明模块相连,实现图像采集功能。时钟模块为摄像头模组及AT32 微控制器提供运行需要的时钟信号。Air302 模组作为AT32 的上位机实现采集终端的定时唤醒、休眠、图像传输及接收指令的功能。
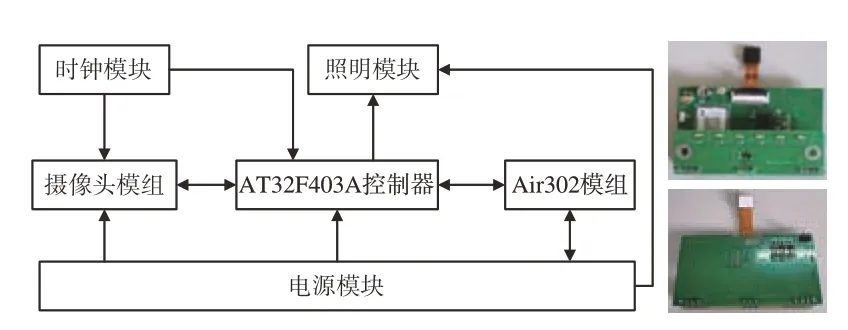
图2 图像采集终端结构图及实物电路板Fig.2 Structure diagram and physical circuit board of image acquisition terminal
(1)Air302 模组
Air302 是基于EC616 芯片的NB-IOT 模组,具有低功耗、低成本、开发便捷等优势。Air302 支持2.2~4.3 V 供电,在PSM(Power Save Mode)模式下电流仅为800 nA,支持LuatOS 嵌入式实时操作系统,以Lua 脚本语言进行开发,从而用少量代码实现了业务逻辑。Air302 模组外围电路包括射频天线、贴片SIM(Subscriber Identity Module)卡、串口接口及复位、下载按键。本文图像采集终端采用的Air302 与AT32 微控制器通过串口相连实现数据传输。
(2)AT32 微控制器
本文采用的微控制器是基于32 位ARM Cortex M4 内核的AT32F403A,拥有高达1 MB Flash、最高224 KB 内存,具有高能效、高容量、低成本特点,适合对成本敏感及高运算需求的场景。AT32F403A 的闪存存储器支持两种配置,即256 KB 零等待(ZW)Flash、768 KB 非零等待(NZW)Flash、96 KB RAM 和128 KB 零等待Flash、896 KB 非零等待Flash、224 KB RAM,可通过寄存器切换配置方案。非零等待Flash 的执行速率是零等待Flash 的0.4 倍,因此需要将实时性高的程序编译到零等待Flash 中。
(3)摄像头模组
摄像头模组采用GC0328,最大支持图像分辨率为640×480。本文配置为320×240 以减少网络传输的数据量,通过DVP 接口与AT32 相连。
(4)电源模块
由于部分老式字轮表并未通电,因此采集终端设计使用两节ER14505 锂亚硫酰氯电池作为电源。电池额定电压3.6 V,额定容量为2 700 mAh。锂亚电池一路直接为Air302 模组供电,另一路经过RT9013 线性稳压芯片,将3.6 V 电压降为3.3,2.8,1.5 V 为AT32、摄像头及LED 供电。RT9013 的 使 能 脚 与Air302 的GPIO 相 连,当 图像采集终端需要采集图像时,Air302 控制GPIO输出高电平,使能线性稳压电源为AT32 与摄像头等供电。当图像上传完毕后,关闭线性稳压电源。在采集终端进入休眠后,线性稳压电源处于关闭状态,进一步降低整机功耗。
(5)照明模块
照明模块的补光效果直接影响后续读数识别算法的精度。如图3 所示,若按图3(a)的设计,LED 直射表盘会造成表盘图像光照不均,甚至在表盘上形成光斑,导致算法无法正确识别读数。因此,本文创造性地设计多组高亮侧光LED 直射图像采集终端的外壳内壁,经外壳内壁反射形成漫射照明,如图3(b)所示。虽然该设计中LED灯组在同一功率下光照强度低于直射照明,但能有效减小光斑形成。

图3 照明模块设计对比Fig.3 Comparison of lighting module design
3.2 图像采集终端软件设计
图像采集终端软件分布在Air302 与AT32中,其中Air302 利用Lua 脚本语言开发,主要包括系统休眠唤醒及数据传输;AT32 在Keil5 下使用C 语言开发,主要包括采集图像及图像压缩。
(1)Air302 程序设计
Air302 开机后首先检查开机原因。如果是普通上电或复位上电,便会进行初始化工作,然后联网获取云平台下发的休眠时间并存入低功耗内存中,随后进入休眠模式。如果是唤醒上电,接着检查是否到达采集时间。当采集时间到达时,使能线性稳压电源,接收AT32 通过串口发送的图像数据。在上传表盘图像数据的同时,会将锂亚电池电压、信号强度、Air302 的IMEI(International Mobile Equipment Identity)码以及贴片SIM 卡 的IMSI(International Mobile Subscriber Identification Number)码一起上传。待数据上传完毕,查询云平台是否有下发指令或是否更新休眠时间,若无,便重新进入休眠模式。Air302 程序流程图如图4 所示。
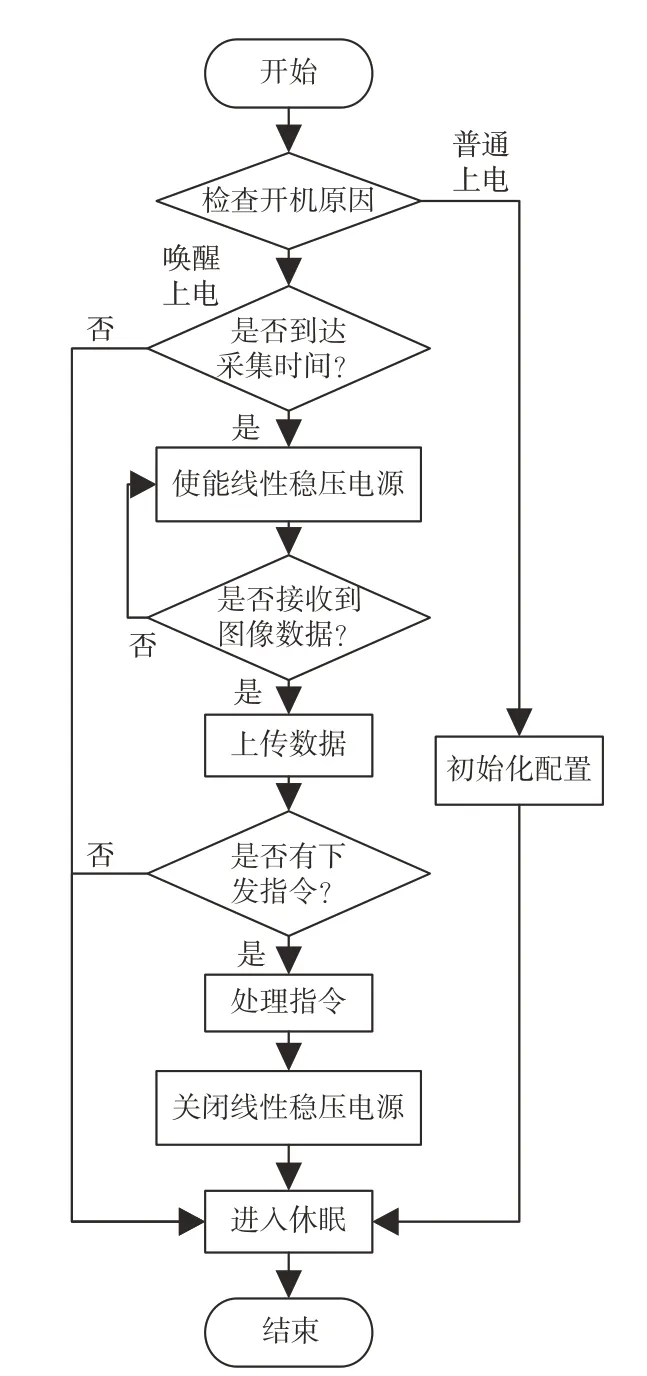
图4 Air302 工作流程Fig.4 Air302 workflow
(2)AT32 程序设计
AT32 同时具有单精度浮点单元(FPU)和数字型号处理器(DSP),运算能力强。由于本文设计的AT32 程序具有较高内存需求,因此当AT32 开机后首先将内存扩展至224 KB,同时初始化GPIO、I2C 接口并点亮补光LED。为了减小数据上传的流量消耗,通过I2C 配置摄像头模组输出YUV 格式数据以便AT32 对此数据进行JPEG压缩。申请150 KB 内存用于存储摄像头输出的YUV 图像数据,申请30 KB 内存用于存储压缩后的JPEG 格式图像数据。当压缩完成后,通过串口将JPEG 格式图像发送至Air302 中。AT32 程序流程图如图5 所示。
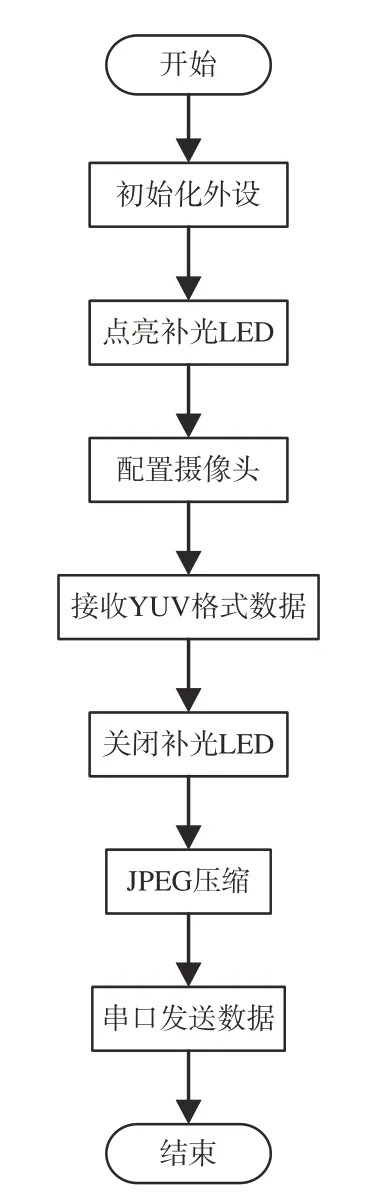
图5 AT32 工作流程Fig.5 AT32 workflow
4 表盘读数识别算法
4.1 读数识别算法基本流程
本文读数识别算法的流程如图6 所示,分为离线过程和在线过程。由于本设计中每个图像采集终端唯一对应一台固定的仪表表盘,为减小图像处理算法复杂度,可事先离线为每个仪表准备一张采集好的表盘图像作为模板图像(参考图像),标记其读数区域每个字符的位置信息及小数位数信息并存入云平台数据库。考虑到受安装条件限制,图像采集终端不一定能正立安装,要求制作的模板图像正立即可。图6中展示了实际场景下倒装而采集的图像以及与其对应的正立的模板图像。当云平台在线接收到图像采集终端上传的当前表盘图像后,将其视为识别算法的输入图像,为不受图像采集终端安装方位的限制,同时为防止后期图像采集终端可能出现局部移位、旋转或光照变化等因素带来影响,这里通过图像局部特征(如SIFT[23]或SURF[24]特征)提取与匹配方法,计算透视变换矩阵,将输入图像投影到模板图像所在坐标空间,从而可通过离线记录的读数字符位置信息分割出输入图像上每个读数字符的子图像。最后,将每个读数字符子图像依次输入离线训练好的字符识别CNN 模型,即可在线识别得到最终读数。

图6 读数识别方法流程Fig.6 Reading recognition method flow
4.2 读数字符识别CNN 模型
字轮式仪表要求能准确识别完整数字字符和双半字符。鉴于传统方法精度有限,本文采用卷积神经网络(CNN)方法进行识别。将仪表读数字符分为20 类,其中类别标签“0”~“9”分别表示0~9 对应的10 个完整单字符,类别标签“10”~“19”分别表示10 个双半字符,如“10”表示超过“0”(称为“较低状态”)但是还未到“1”(称为“较高状态”)的双半字符、“11”表示超过“1”但是还未到“2”的双半字符,依此类推。然而,在实际采集的表盘图像中双半字符图像数据量占比极少,导致训练过程中数据不均衡,严重影响双半字符的识别精度。为避免训练过程中数据不均衡的影响,在每类字符图像中随机筛选1 000 张图像,通过人工清洗筛去标注错误的图像。
神经网络[25]在样本充足且形式多样的情况下可大幅改善字符识别的鲁棒性,精度远高于传统方法。在图像处理中卷积神经网络应用最为广泛,其基本结构包括卷积层、池化层、批归一化层、激活层及全连接层。卷积层用于提取图像特征,池化层用于压缩特征,批归一化层用于约束特征分布,激活层用于引入非线性因素,全连接层用于分类。
实际表盘读数字符的图像尺寸较小,太深的神经网络会导致过拟合,因此本文采用轻量级卷积神经网络,其结构如图7 所示。输入图像尺寸为28×28的单通道图像,第一个卷积层采用16个5×5 的卷积核,步长为1,填充2 个像素,并依次经过批归一化层、激活层、池化层。之后的每一层使用2 个3×3 的卷积层,步长为1,填充1 个像素,在通道数上先降维再升维,这样能在有效降低参数量的情况下提高感受野。使用全局平均池化与最后一个卷积层的池化层相连,整合全局空间信息,降低参数量。最后经过两个全连接层得到20维的网络输出。本文所使用的卷积神经网络总参数量为44 084。
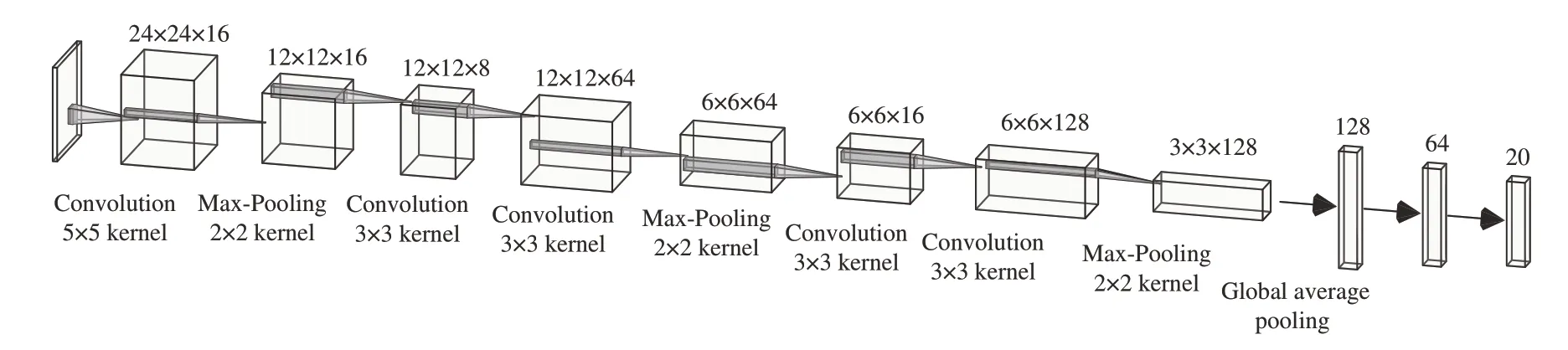
图7 本文方法使用的卷积神经网络结构Fig.7 CNN structure used in this method
双半字符与其对应的两个单字符具有较大相似性,当双半字符中某一字符占比极大而另一字符占比较小时,神经网络会倾向于将其识别为其中占比较大的单字符,然而此时仍处于还未完全进位的状态,因此若将其识别为其中占比较大的单字符会造成读数错误。同时对于人而言也很难判断其是否是双半字符,会造成标签错误,导致模型难以训练。因此本文提出一种基于多标签分类的思想改进CNN 字符识别模型,同时给予双半字符样本表示是否为双半字符的标签及双半字符中占比较大的单字符的标签。标签向量由20 维组成,前10 维表示是否属于单字符或双半字符中占比较大字符的标签,后10 维表示是否属于双半字符。如单字符“1”的标签为“0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0”,“0”~“1”之间的双半字符且“1”的占比较大的样本标签为“0,1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0”。相比于传统图像分类使用的交叉熵损失(Cross Entropy Loss),本文使用二值交叉熵损失(Binary Cross Entropy Loss)。该方法除了能预测单字符或双半字符类别以外,还能预测双半字符中“较低状态”和“较高状态”的占比关系,即占比较大或较小,可用于在后处理阶段判别双半字符对应的仪表读数。
模型输出根据公式(1)得到预测字符类别c、公式(2)得到预测结果的置信度p。其中:x1表示模型输出的前10 维;x2表示模型输出的后10 维;pthresh表示将字符识别为双半字符的置信度阈值,本文取0.5 效果最佳。若预测为双半字符,可通过argmax(x1)得到双半字符中占比较大字符对应的向量索引(0~9)。
通过观察实际表盘图像,可能是字轮表机械部件的原因,发现如图8 所示的某些表盘读数区域前几位字符处会露出一部分相邻字符区域,这时CNN 模型很可能会将其预测分类为双半字符。在最终判别双半字符的读数时,若直接将其判别为“较低状态”的字符显然是不合理的。因此本文使用后处理操作来判定双半字符的最终读数,其具体做法为:

图8 含有特殊双半字符的图像示例Fig.8 Example images containing special double halfcharacters
(1)若表盘图像读数区域最后一位或最后几位连续出现双半字符,将该双半字符判别为其中“较低状态”的字符;
(2)若表盘图像前几位出现双半字符,将该双半字符判别为其中占比较大的字符。
5 实验及结果分析
通过实验研究分别评估智能抄表系统读数识别准确率、图像采集终端功耗及整体系统功能。模型训练和推理平台所用处理器为Intel(R)Xeon(R) Gold 5218 CPU @ 2.30 GHz,64 GB内存,显卡为NVIDIA RTX3090,操作系统为Ubuntu21.04。在PyTorch 深度学习框架下搭建神经网络。本文数据集构建于在实际场景下339 个不同仪表上采集到的66 000 张表盘图像。在预处理后,通过筛选得到20 类20 000 张单通道字符图像作为训练集,1 436 张不同表盘共8 263 张字符图像作为测试集。训练过程中学习率为0.001,使用Adam 优化器,迭代50 次。CNN 模型训练的收敛曲线如图9 所示,包括损失曲线和准确率曲线。

图9 CNN 模型训练的收敛曲线Fig.9 Convergence curves for CNN model training
5.1 读数识别性能评价及比较
针对字轮式仪表的读数识别任务,本文采用字符识别准确率(Character Accuracy Rate,CAR)及读数识别准确率(Reading Accuracy Rate,RAR)两个指标来衡量模型,其定义如式(3)和式(4)所示:
其中:Nrc表示识别正确的字符样本数量,Nc是测试集中读数字符样本总数量,Nrm表示表盘中所有读数识别完全正确的表盘样本数量,Nm表示测试集中表盘图像总数量。
本文方法的识别结果如表1所示,对比方法包括传统的支持向量机(Support Vector Machines,SVM)分类法、HOG(Histogram of Oriented Gradient)特征提取与SVM 相结合的方法(HOG+SVM)、LeNet-5[26]卷积神经网络方法、文献[17]所采用的轻量级卷积神经网络方法以及具有更深层次的VGG16 卷积神经网络方法。其中,SVM方法直接使用标准化后的像素作为特征向量,选用高斯核函数,松弛变量为100;HOG+SVM 方法是提取图像的HOG 特征向量后再使用SVM分类;LeNet-5主要包含2个5×5的卷积层、2个池化层和3 个全连接层,使用ReLU 激活函数替代Sigmoid 激活函数;文献[17]所采用的轻量级卷积神经网络将原网络的10 分类修改为20 分类;由于VGG16 有5 个池化层不适合28×28 尺寸的输入,因此在对比实验时使用32×32 尺寸的输入。由于除了本文方法外其余方法无法获得双半字符中的占比关系,因此其余方法在判别双半字符读数时直接将其判别为“状态较低”的字符。对于基于卷积神经网络的方法,表1 中还列出了模型参数量和推理时间进行比较。从结果来看,在双半字符的置信度阈值pthresh取0.5 时,本文方法整体效果最佳,字符识别准确率(CAR)达到了96.36%,非常接近VGG16 方法的96.62%,而模型参数量却比VGG16 要少数百倍,所用推理时间约为VGG16 的1/3,同时读数识别率(RAR)是所有对比方法中最高的,达到了94.15%。
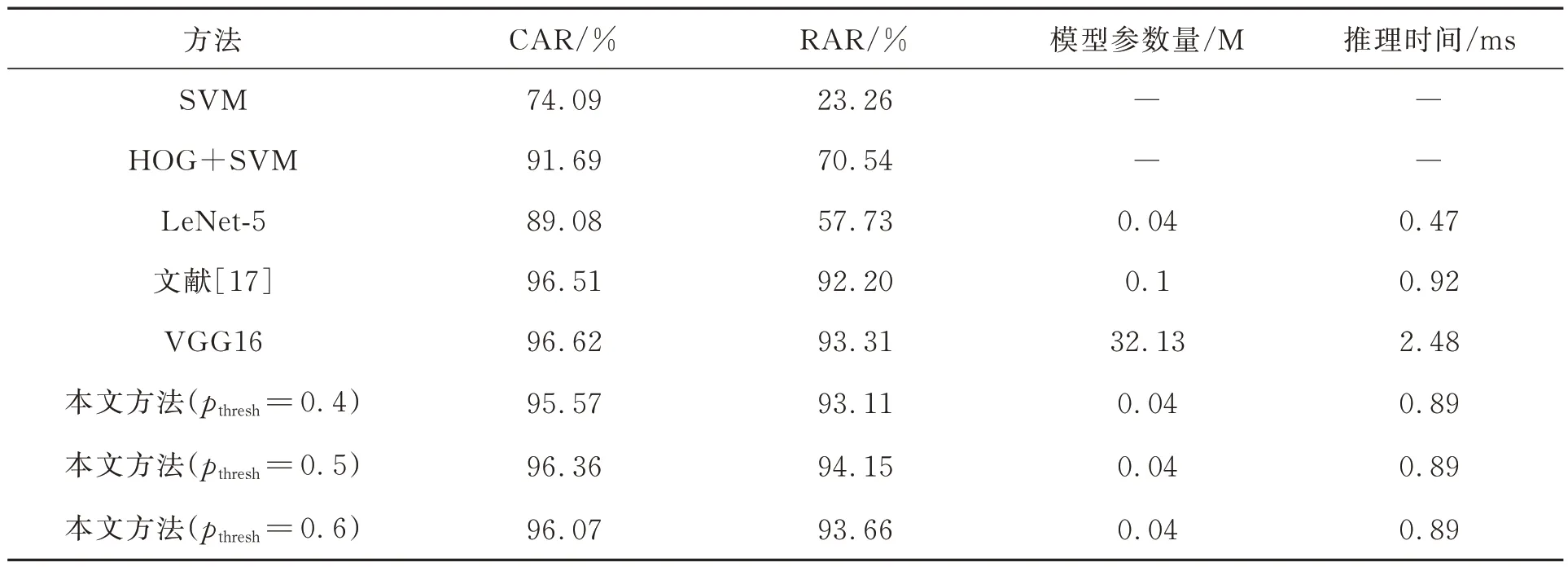
表1 不同方法的识别结果Tab.1 Recognition results of different methods
为了进一步说明和解释本文提出的基于多标签分类的CNN 字符识别模型所发挥的作用,借助Grad-CAM[27]工具绘制卷积神经网络所关注图像区域的热力图,如图10 所示,颜色越深则强度越高。图10(a)和图10(b)分别展示了单字符图像和与之接近的双半字符图像的热力图分布,其中第1 列是列举的单字符或双半字符图像,第2 列对应于本文CNN 模型输出的后10 维中最大置信度所在类别的热力图,第3列对应于本文CNN模型输出的前10 维中最大置信度所在类别的热力图。可见,图10(a)中第2 列的强度都较低,而图10(b)中第2 列都存在强度较高的区域,从而很好地区分了单字符图像和双半字符图像;图10(a)中第3列的强度较高之处位于单字符图像中心附近,符合实际情况,而图10(b)中第3 列的强度较高之处均位于占比较大的半字符中心附近,从而很好地说明了本文CNN 模型在识别双半字符时能准确关注到其中占比较大的字符区域。

图10 Grad-CAM 热力图Fig.10 Grad-CAM heatmap
5.2 图像采集终端功耗测试
图像采集终端采用直流电源供电,供电电压为3.6 V。图像采集终端完成一次工作周期同时记录工作电流,使用电流表分辨率为10 μA。当终端进入休眠模式后停止记录,功耗测试结果如图11 和表2 所示。根据测试结果,图像采集终端的休眠电流小于电流表分辨率,最大工作电流为100 mA,若每日采集1 次,两节锂亚电池可使用5 年以上。

表2 功耗测试结果Tab.2 Test result of power consumption
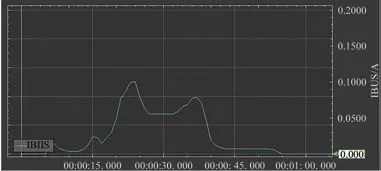
图11 单次工作周期电流波形Fig.11 Current waveform of single duty cycle
5.3 系统测试
本文设计了一个完整的智能图像抄表系统。测试时,首先通过云平台下发指令,设置图像采集终端的参数,图像采集终端将此参数保存在低功耗内存中,在每次唤醒时读取。设置图像采集终端休眠时间为24 h,即每天采集一次图像并上传至云平台,云平台再将其存入数据库内并调用读数识别算法得到表盘读数,最后抄表管理平台通过MQTT 协议将表盘图像及识别结果提取出来,如图12 所示,可在仪表管理平台查看表盘读数识别结果并能监视某一仪表近些天以来的日用量,方便供应公司和物业公司实现信息化管理。

图12 抄表管理平台Fig.12 Meter reading management platform
6 结 论
针对人工抄表效率低和现有图像识别方法对双半字符识别不准的问题,本文提出了一种基于NB-IoT 和轻量级CNN 的智能图像抄表系统,适用于字轮式仪表。本文的读数识别算法使用局部特征提取与匹配方法分割出读数字符子图像,使用基于多标签分类的轻量级CNN 模型识别出读数字符。实验结果表明,本系统的图像采集终端休眠电流小于10 μA,可保证两节锂亚电池工作5 年以上;所提出的字轮式仪表读数识别算法能准确识别单字符和双半字符,在测试集上达到了96.36%的字符识别准确率和94.15%的读数识别准确率,整体性能优于所对比的其他识别算法。为减小图像处理算法复杂度,目前方法需人工制作仪表表盘的模板图像,通过图像匹配定位读数字符位置,不适用于开放环境下移动式图像采集终端,因此下一步工作是实现对读数字符的自动检测定位,并进一步通过深度学习[28]提升算法的识别精度,使其适用于更多应用场景,如使用移动机器人或无人机进行巡检抄表的场合。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
中国公路(2017年19期)2018-01-23 03:06:36
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
中国公路(2017年15期)2017-10-16 01:32:04
中国公路(2017年9期)2017-07-25 13:26:38
中国公路(2017年7期)2017-07-24 13:56:40
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
