
理论与应用并举
2023-07-17 05:31孙道功陈艺玮
辞书研究 2023年4期
孙道功 陈艺玮
摘 要 《面向应用的汉语语义构词研究》一书,采用定量统计和定性说明相结合的方法,基于数据库中5万多个合成词对语义构词规律进行深入探索,归纳得出字义与词义的关系类型和语义构词规则。该书分析角度新颖,构思缜密,展示出诸多的新特色,特别是通篇运用了基于数据库的数量统计方法,提出了语义关系分析描写的具体路径,综合运用多种理论多维深度解释构词规则,并尝试把语义构词的研究成果直接应用于中文信息处理。
关键词 构词规则 语义构词 理论与应用
《面向应用的汉语语义构词研究》一书,是亢世勇教授等(2020)基于《汉语语义构词数据库》,对语义构词规律进行探索的新成果。该书主体部分基于数据库归纳得出字义与词义的关系类型和语义构词规则。书中对字义与词义关系的定量分析和类型归纳,既是对传统词汇学研究方法的革新,也是对当前汉语字、词义关系研究的有益补充。众所周知,现代汉语词汇系统在不断扩大,但“汉字”却没有增加,这说明新词语是由旧有构词材料通过新的组合方式产生的。该书在对常用双音节合成词词义分析的基础上,通过对三音节合成词新词语进行研究,寻求常用汉字的语义构词规律。这一研究具有重要的实践意义,特别是对于提高计算机未登录词语的识别效率,提高语言信息处理的准确度,都具有很高的实用价值。
《面向应用的汉语语义构词研究》对语素义和词义关系的分析细致全面、角度新颖、构思缜密,展示出诸多新特色,体现了作者在词义关系分析方面的新颖视角和独特见解。其中有四点特别突出。
一、 通篇运用了基于数据库的定量统计方法
定量和定性相结合,是当前语言研究的重要趋势。为了对词义关系进行量化分析,该书构建了《汉语语义构词数据库》,并基于数据库定量统计,分析归纳了词义关系及类型。多样化的数据统计成为该书的一大特色和亮点。
研究过程中,科学精确的数字统计和简明直观的图表运用让各类词语的义类构成特点和词义关系一目了然,也让传统词汇学中的某些模糊表达变得具体直观。书中对义位义类的主要构成方式、语素义与词义(义位)的关系分析等方面都有体现。传统词汇学对语素义和词义关系的分析,通常采用“语素义基本反映词义”“语素义部分地反映词义”等笼统的说法,该书采用定量统计和定性说明相结合的方法,通过对数据库中5万多个合成词的考察分析,把字义与词义的关系归纳为八种类型:A+B=A=B(如“哄骗”)、A+B=A(如“人物”)、A+B=B(如“阿哥”)、A+B=C(如“爪牙”)、A+B=A+B(如“陪考”)、A+B=A+B+D(如“冷眼”)、A+B=A+D(如“救星”)、A+B=D+B(如“走运”)。在类型归纳的基础上,分类并统计出各个类型的所占比例,并对每一类型的义类构成和构词特点进行解释描写。作者基于数据库考察发现,只有第四种类型(A+B=C)看不出字义与词义的关系,其他七种字义与词义都有明显的关系。但是第四种只占词语总量的8.02%,而其他七种加起来占91.98%。在这八种类型中,第六种(A+B=A+B+D)所占比例最高,达到44.99%,第五种(A+B=A+B)所占比例次之,占27.60%。定量统计数据表明,汉语词汇中字义与词义有密切的关系。由字义可以推知词义,这是汉语词汇的重要特点。可以认为,具体直观的数据和图表让读者对语义构词规则有了更清楚的了解和把握,特别是用字母标示出字义与词义的关系模式,便于语义形式化和自然语言处理。
定量研究的主要优势是“化繁为简”,将纷繁复杂的语言现象通过必要的裁剪、删节、修整、简化,最终转变成为几个关键的“变量”,并以此来开展研究和定性分析。在对每一类型的构词规则和特点归纳总结时,先用表格说明义位义类的主要构成方式,再对表格数据进行解释,不仅简明易懂,也更具客观性和说服力。该书善于利用数据表达,将一些复杂繁琐的笼统说明改为定量统计分析,可以很大程度上增强内容的解释力。毫无疑问,各种图表的综合运用让内容分析更加成系统、有条理,表达更加直观、透彻、有序。通篇运用了基于数据库的定量统计方法,成为该书的一大亮点。
二、 提出了词义关系分析描写的具体路径
国内研究词汇语义关系的论文或论著颇多,但是其分析大多仍停留在举例式的分析层面。该书对语义关系的分析全部立足于语义构词数据库,同时提出了词义关系分析描写的具体路径。
首先,基于人机两用的研究理念,设立“字位”作为词义关系分析和描述的基点。“字位”指一个单音单义的汉字,是最小的语义构词单位,即每个“字位”包括一形、一音、一义。故一个多音多义的汉字可以形成多个字位。“字位”有点像词典学中的义项,但又不完全相同。“字位”是针对字而言的,都是单音节的。而义项是对词而言的,可以是单音节或多音节。以“字位”为描写单位可以避免描写结果比较粗疏的问题,使信息描述的颗粒度更小,获得的信息也更精细化。书中遵循“一字一条、一义一条、意义与语法功能结合”等原则将“国标GB2312”所定义的6763个汉字衍生为17430个字位,按照《同义词词林》的三级语义分类体系(大类、中类、小类)给每个字位归类,录入数据库,建成了大型的《汉字义类信息库》。其次,在字、词语义分类信息库的基础上,通过统计比较说明字、词语义分布的实际情况以及二者之间的对应关系,为进一步进行语义构词规则的研究提供基础。基于信息库考察,书中提出了字、词义之间的三个一致性:(1) 字的义类体系和词的义类体系基本一致;(2) 字、词在各个义类中的分布比例基本一致;(3) 除个别的类外,字、词的绝对数量多少一致。可见,汉语中字与词在义类上有着明确的对应关系。再次,选取定量的双音合成词,利用“汉字义类信息库”对构成双音合成词的每个字进行语义标注,建成大型的《汉语语义构词数据库》,在此基础上进行现代汉语语义构词规则的研究,通过统计归纳得出由字义整合成词义的具体规则。
基于书中提出的词义关系分析描写的具体路径,作者对现代汉语中的5万多个双音合成词和6830个三音节合成词新词语内部的词义关系进行分析描写。特别需要注意的是,“字位”的设置以及《汉字义类信息库》的构建,都是为了描写词汇内部的词义关系服务的。在此基础上,基于字义和词义的关系,构建了《漢语语义构词数据库》。该库中合成词的标注信息非常丰富,涉及合成词语义类,前字、后字的语义类和释义,字、词语义关系类型等,从不同层级明确合成词的语义构成情况,其建库方式和标注信息也为之后的词义关系研究提供了参考模板。
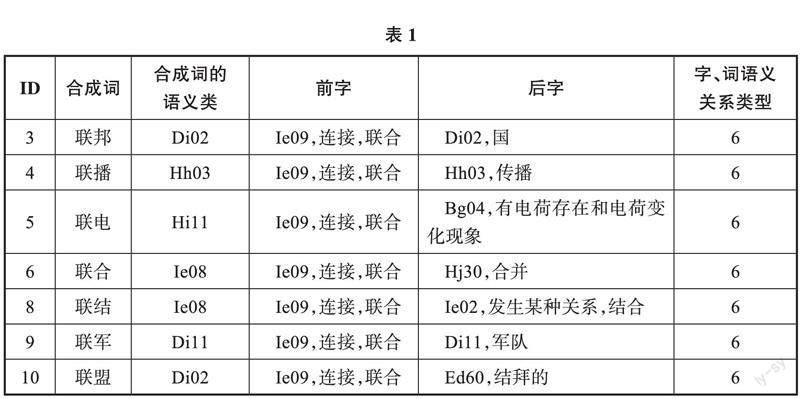
数据库中语义类标记包括三级,其中大类有12个:A人、B物、C时间与空间、D抽象事物、E特征、F动作、G心理活动、H活动、I现象与状态、J关联、K助语、L敬语。各个大类内部按照词义之间的同义程度分出若干中类,中类包括94个,其标记符号是在大类字母后面添加小写的a、b、c、d等表示。各个中类内部进一步按照词义之间的同义程度分出小类,小类包括1428个,其标记符号是在大类、中类字母后面用数字01、02、03、04等表示。样例如表1:
表1中的标记符号部分说明如下:“联邦”,合成词的语义类是Di02,大类D表示抽象事物,中类i表示社会、政法,小类02表示国家。前字符号Ie09,大类I 表示现象与状态,e 表示事态,小类09表示连接、联合;后字符号Di02,与“联邦”的义类符号一致。“字、词语义关系类型”对应的6表示“联邦”语义关系类型是“A+B=A+B+D”。再如“联播”,合成词的语义类是Hh03,大类H表示活动类,h表示文体活动类,小类03表示传播。前字Ie09,大类I 表示现象与状态,e 表示事态,小类09表示连接、联合;后字Hh03与“联播”的义类一致,其他不再赘述。
毫无疑问,明确合成词的各级语义单位,不仅在描写词义组成情况时比较方便,而且可以使描写结果更加系统科学。特别是对词语义类分类情况的描述和对构词规则特点的总结,具有明确性和系统性,为现代汉语词汇语义关系的描写提供了范式。
此外,在解释说明语素义和词义关系时,该书不单纯局限于两个语素的联系,对构词语素进行搭配类型、转指方式的分析,扩大对语素义和词义关系分析的范围。不局限于已有的分析方法,不囿于已有的研究视角,而探寻新的分析角度,是该书在词义关系分析方面特别值得称赞的地方。唯有如此,才可以更好地将合成词深层的语义构词特点揭示出来,也使词义关系研究突破了传统分析的局限。
三、 综合运用多种理论多维深度解析构词规则
传统词义研究中往往存在重描写轻解释的现象。该书在分析词义关系类型时,把分析描写和理论解释有机结合起来,特别是对现象的解释,综合运用多种理论,有深度且多有创见,超越了当前学界的同类研究。
譬如在分析双音名词中无向词语的语义构词特点时,基于词语的物性角色来说明每个语素的隐喻、转喻或隐转喻情况;然后在生成词库理论的指导下,对同义类语素双音合成名词中的无向词语的语义变化进行了分析。首先根据两个语素义如何通过转喻或隐喻变为词义,将无向词语分为八类:(1)前项-后项转喻(包含整体转喻),如须眉、裙钗、山水等;(2)前项-后项隐喻(包含整体隐喻),如心腹、鸳鸯、樊笼等;(3)前项转喻-后项隐喻,如肉票;(4)前项隐喻-后项转喻,如琼筵;(5)前项隐喻-整体隐喻,如眼线;(6)前项转喻-整体隐喻,如草包;(7)前项隐喻-整体转喻,如兔唇;(8)前项转喻-整体转喻,如布衣。其中(1)、(2)两种占比最高,分别达到60.03%和24.80%,其他六种类型仅占15.17%。然后根据物性结构理论,分析每一类中无向词语的语素义体现了词义的哪种物性结构。最终得出无向词语的语素义转变为词义的具体途径。并基于分析归纳得出了22种物性关系,来解释语素义体现的物性角色类型,以及与词义是何种关系,是基于相关性发生转喻还是相似性发生隐喻等。同时,将无向词语中的物性关系与构词类型对应起来。无向词语语素义通常要通过隐喻或转喻才能变为词义,因此无向词语的构词类型大部分为第四类(A+B=C)或第六类(A+B=A+B+D)。由此可以看出,前项和后项两个语素更偏向同时进行转喻或者同时进行隐喻来得到词义。人们更容易将语素义和词义联系到一起,更容易通过语素义理解词义,这符合人类普遍的认知规律。不难看出,综合运用概念整合与隐喻、转喻理论,生成词库理论等多种理论,从多个视角来研究词义与其构成语素义表面上不存在关系的原因,超越了当前此类研究的论文或论著。
为了给构词规则的理论阐释提供更丰富的信息,作者在语料库中标注了丰富的语义信息,如构词类序、四项规则、转义作用的对象、转义的类型、转义涉及具体要素、释义、具体阐释和语义角色框架等八种参数。词语信息要素齐全,不仅便于对于现代汉语中的构词类型进行多维细致的考察分析,同时给语料库的使用带来极大便利,也为后续语料库的开发提供了参考。
综合运用多种理论分析汉语中司空见惯的构词规则,不仅优于单一理论背景下的构词规则解释,同时也富有启发意义。这启发我们要深入考虑如何把几种理论结合起来对某一语言现象进行细致解释,而不单单停留在表面。例如以隐喻和转喻理论為主线贯穿整个分析过程,以词语的物性角色为基础,将物性角色看作词语的一部分,用隐喻和转喻概括与物性角色糅合的合成词的语义特点等,书中的这些做法都为汉语的词汇语义研究提供了新的尝试,带来了新的思考。
四、 语义构词的研究成果直接应用于中文信息处理
未登录词的识别与处理,一直是中文信息处理的难点。实践证明,基于大规模语料库的语义构词模式的自动分类,可以显著提高对未登录词的识别效率。
该书提出了一种新的基于层次加权图编辑距离(GED:Graph edit distance)的使用模糊化(Fuzzification)、核技术(Kernel Techniques)和惩罚因子(Penalty factors)的多目标优化分类器(FKP-MCOC)方法,并将其用于汉语语义构词模式的预测分析。首先计算每个语义构词图和原型图之间的层次加权的GED,然后计算它们之间的相似性度量,经过归一化的GED被嵌入到一个新的特征向量空间,基于新的特征向量空间,使用FKP-MCOC模型和算法来预测语义构词模式。在汉语语义构词模式分析数据集上的实验结果与支持向量机(SVM:Support Vector Machines)的比较分析表明,书中提出并使用的基于层次加权GED的FKP-MCO分类器方法可以显著增加不同构词模式的分离度以及在一个新的复合词语义模式数据上的预测性能。
书中的实验结果表明,对于八类不同的汉语语义构词目标模式的预测平均准确率为88.79%,比支持向量机的性能平均值高出4.85个百分点。可以看出,基于汉语构词模式形成的FKP-MCOC的预测性能要显著好于目前通常使用凸二次规划方法的SVM。FKP-MCOC方法的显著特征是将每个输入数据与模糊隶属度关联能够显著降低数据中噪声和异常的干扰;同时,语义层次加权核的应用能够将非线性可分的问题转化为线性可分的问题。特别是基于语义层次加权核的FKP-MCOC模型能够有效地用于汉语语义构词模式的自动分类,以便提高机器对汉语词语的认知和理解的准确性。
该书把汉语语义构词的研究成果直接应用于中文信息处理,并取得了很好的测试效果。一方面,说明了书中基于数据库归纳得出的构词规则适用性强,可以用于识别未登录词。另一方面,也对进一步开展汉语多音节词以及混合不同音节的词语的自动识别和预测,提供了基础和参考。
此外,该书还提出了诸多富有新意的新观点。譬如汉语合成词中90%以上字义与词义有直接或间接的联系,可以由字义推出词义,但A+B=C类是例外。这类词语的语义透明度低,语素组合后产生了新的意义,无法由语素义直接推知词义。对于这一难题,该书提出了新的解决思路,采用生成词库论的物性结构理论分析这类词转义产生的途径,突破“套用句法模式分析构词法”的传统方法,很好地解释了该类词语素义和词义之间的关系。同时也证明了物性结构理论在词义分析方面的强大解释力,丰富和发展了汉语词汇语义学理论。在语义类方面,将双音合成词的语义类构成特点归纳为四种规则:同类规则、后向型规则、前向型规则和无向型规则。对每一规则的词义构成特点进行了细致描写,特别是提出无向型词语的语素义发生了转指,语素义义类与词义不一致,探讨这类词的语义特点更有助于更好地解释某些语义现象。文中结合隐喻、转喻理论和生成词库理论来说明该类词转义产生的具体途径和方式,为现代汉语词汇语义研究提供了新角度和新方法。
五、 结语
正如任何事物都不是完美无缺的一样,该书也存在一些值得商榷之处。如,虽然各项研究都建立在大规模数据库的基础上,通过统计比较说明字、词语义分布的实际情况以及二者之间的对应关系,为进一步进行语义构词规则研究提供了理论基础,但是整本书统计数据较多,对现象的解释相对还较少,尤其是在第二至四章,多是对统计结果的归纳总结,较少对特点进行解释说明和原因分析。此外,書中将字、词的语义类分为大类、中类和小类,每一类用相应的字母来标示。这一做法为语义形式化研究提供了基础和便利,但是也不可避免地降低了内容的可读性,特别是在阅读语义构词规则时,有时候很难直接想到字母所代表的是哪一语义类,往往需要往前翻看对义类分布的相关介绍才能知晓。同时,书中语义构词的研究成果,虽然在未登录词的识别中取得了较好的实验结果,但是在全面应用于计算机语言信息处理、提升中文信息处理的效度等方面,还有待进一步检验。
瑕不掩瑜,《面向应用的汉语语义构词研究》一书,理论和应用并举,定量和定性结合,对汉语的语义构词问题进行了全方位研究,提出了解决问题的新思路和新方法,还为汉语语义构词研究提供了新范式。理论与应用并举,是语言学研究的方向。该书作为一部兼顾理论与应用的汉语语义构词研究的力作,值得读者仔细研读。
参考文献
1. 亢世勇等.语言资源开发与应用.外语教学与研究出版社,2018.
2. 亢世勇等.面向应用的汉语语义构词研究.中国社会科学出版社,2020.
3. 孙道功.应用与前瞻:现代汉语新词语计量研究与应用.辞书研究,2010(2).
(责任编辑 刘 博)
