
基于改进SSD的行人检测算法
2023-07-17 02:44:44张伦谭光兴
广西科技大学学报 2023年3期
张伦 谭光兴

摘 要:针对目前主流的目标检测算法在检测行人时无法兼顾精度与实时性的问题,提出一种改进单次多框检测器(single shot multibox detector,SSD)的行人检测算法。首先,将高效通道注意力机制引入浅层网络中并重新分配特征权重,引导网络更加关注小尺度行人的特征信息;其次,构造一种新的特征融合模块以改善浅层特征语义信息不足的问题;最后,通过优化原始先验框的参数来生成适用于检测行人的先验框。实验结果表明,改进后的算法在PASCAL VOC2007行人测试集上的平均精度达到82.96%,较SSD提高了3.83%,在小尺度行人测试集上提高了5.48%,同时检测速度达到了69.2FPS,满足实时性的要求。
关键词:单次多框检测器(SSD);行人检测;注意力机制;特征融合
中图分类号:TP391.41 DOI:10.16375/j.cnki.cn45-1395/t.2023.03.013
0 引言
行人检测作为计算机视觉领域中的研究热点之一,是指判断图像或视频帧中是否存在行人并标记其具体位置,在视频监控、智能安防以及自动驾驶等领域应用越来越广泛[1]。虽然现有的方法在行人检测任务中已取得一些研究进展,但由于行人姿态多变、相互遮挡以及小尺度行人目标特征信息较少等因素的影响,仍然存在被误检、漏检的问题,因此对行人检测方法还需进一步研究。
近年来,随着深度学习的迅速发展,基于深度学习的行人检测方法在行人检测技术中占据了主导地位,该方法主要分为两阶段检测算法和单阶段检测算法。两阶段检测算法首先生成目标的候选区域,然后将其送入分类器中进行分类和回归[2]。此类算法检测精度较高,但由于模型复杂度高、计算量庞大,导致其检测速度较慢。代表性算法有Faster R-CNN[3]、Mask R-CNN[4]等。单阶段检测算法无需生成候选区域,而是直接通过回归来预测目标框,将检测转化为回归问题,虽然精度会有所损失,但是检测速度比两阶段算法更快。代表性算法有YOLO(you only look once,YOLO)[5]、单次多框检测器(single shot multibox detector,SSD)[6]、YOLOv2[7]以及YOLOv3[8]等。
YOLO是典型的单尺度目标检测算法,对于多尺度目标检测任务并不适用。SSD首次从多尺度特征图中检测不同尺度的目标,在提高精度的同时兼顾了速度,但该算法对小尺度目标的检测能力较弱。为了进一步提高对小尺度目标的检测能力,研究者们在SSD的基础上提出了多种改进算法。DSSD[9]将主干网络替换为残差网络ResNet101,并利用反卷积和跨连接融合上下文信息,改善了对小尺度目标的检测效果。DF-SSD[10]构造了主干网络DenseNet-s-32-1,并提出一种多尺度特征融合方法,使浅层位置特征与深层语义特征相结合,在一定程度上解决了小尺度目标的检测问题。然而,上述算法主要是通过使用更深的主干网络来增强模型的特征提取能力,或者是利用反卷积将深层特征与浅层特征进行有效融合等方法来提高对小尺度目标的检测能力,在提升检测精度的同时却牺牲了网络的运算速度,无法满足实时检测场景的要求。
综上所述,针对图像背景复杂、行人目标存在遮挡或重叠以及远距离下行人尺度过小等问题,同时考虑精度和实时性检测的要求,本文在保留SSD主干网络的基础上,首先,通过引入一种轻量级注意力机制来增强小尺度行人的特征表达能力;然后,构造一种新的特征融合模块来增强浅层特征图中的语义信息,提升对小尺度行人的检测能力;最后,根据行人目标的宽高比特性对原始先验框进行优化,使其更加适用于检测行人目标,提高检测效率。
1 SSD算法
SSD算法是一种经典的单阶段多尺度目标检测算法,其网络结构如图1所示。首先,对原始图像进行预处理后作为网络输入;其次,使用VGG16网络作为主干网络来提取浅层特征图,并将VGG16末端的2个全连接层FC6、FC7替换为2个卷积层Conv6、Conv7;然后,在此基础上额外增加4组卷积层来提取深层特征图,从而一共提取出层次由浅到深的6个多尺度特征图:Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2,其中,浅层特征图感受野小,适合检测小目标,深层特征图感受野大,适合检测大目标;最后,在不同尺度的特征图上设置不同尺寸和数量的默认先验框,并通过2个大小为3*3的卷积核分别输出先验框的位置偏移量和类别置信度,使用非极大值抑制(non-maximum suppression,NMS)以及置信度过滤的后处理方法来获取最终精准的检测结果。
为了适应图像中不同大小和形状的目标,SSD算法引入了Faster R-CNN算法中所使用的先验框机制。若使用[m]个特征图进行预测,则在第[k]个特征图上的先验框尺寸计算公式如下:
[Sk=Smin+Smax?Sminm?1k?1, k∈[1,m]]. (1)
式中:[Smin]=0.2,[Smax]=0.9,分别代表最浅层和最深层先验框的尺度;k表示先验框尺寸相对于原图像的比例。然后对每个先验框尺寸设置不同的宽高比,将其标记为[a∈1,2,3,12,13],则每个先验框的宽([wak])、高([?ak])计算公式为:
[wak=Ska,?ak=Sk/ .] (2)
当[a ]=1时,会额外添加一个尺寸为[S'k=SkSk+1]的先验框,于是特征图上的每个网格均生成6个先验框。但实际实现时,SSD在特征圖Conv4_3、Conv10_2和Conv11_2上并不使用[a]=3和[a]=[13]的先验框,即只设置了4个先验框。因此,SSD总共生成8 732(38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8 732)个先验框来进行目标检测。
2 本文算法
SSD算法利用浅层网络检测小目标,深层网络检测大目标,于是减少了整个模型的检测负担。但是浅层网络存在特征提取不充分的问题,导致小尺度目标的检测效果较差。为了改善小尺度行人检测困难的问题,提高行人检测精度,本文在原始的网络中引入了高效通道注意力机制(efficient channel attention,ECA)和特征融合模块(feature fusion module,FFM)。改进后的网络结构如图2所示。
2.1 注意力机制模块
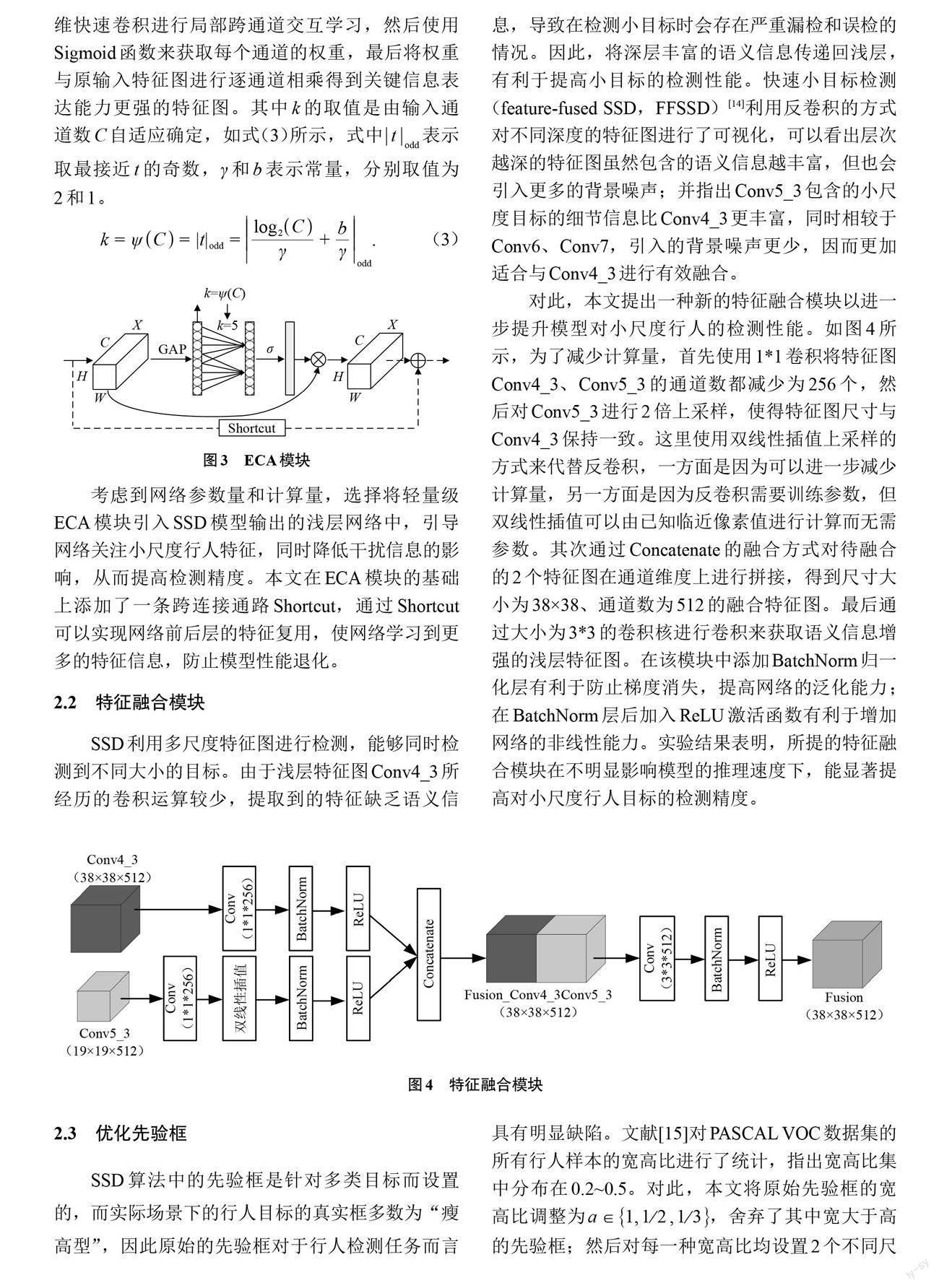
图像中背景信息干扰以及遮挡等情况的存在增加了检测行人的难度。如今,将注意力机制应用于目标检测模型上取得了显著的效果。Hu等[11]最早在2017年提出了通道注意力机制(squeeze-and-excitation,SENet),能够自适应地对通道特征进行加权,有效放大特征的关键信息。Woo等[12]设计了混合域卷积注意力模块(convolutional block attention module,CBAM),通过将通道注意力机制与空间注意力机制相结合,帮助网络自适应地在通道和空间维度上调节特征权重,能够获得比SENet更好的效果,但增加了网络模型的复杂度与计算量。Wang等[13]在CVPR2020中提出了ECA,在引入极少的额外参数和可忽略的計算量的情况下,能使网络具有更优的性能。如图3所示,在对输入进行全局平均池化(global average pooling,GAP)后,并未减少特征通道数,而是直接使用大小为k的一维快速卷积进行局部跨通道交互学习,然后使用Sigmoid函数来获取每个通道的权重,最后将权重与原输入特征图进行逐通道相乘得到关键信息表达能力更强的特征图。其中k的取值是由输入通道数C自适应确定,如式(3)所示,式中[todd]表示取最接近t的奇数,[γ]和b表示常量,分别取值为2和1。
[k=ψC=|t|odd=log2Cγ+bγodd]. (3)
考虑到网络参数量和计算量,选择将轻量级ECA模块引入SSD模型输出的浅层网络中,引导网络关注小尺度行人特征,同时降低干扰信息的影响,从而提高检测精度。本文在ECA模块的基础上添加了一条跨连接通路Shortcut,通过Shortcut可以实现网络前后层的特征复用,使网络学习到更多的特征信息,防止模型性能退化。
2.2 特征融合模块
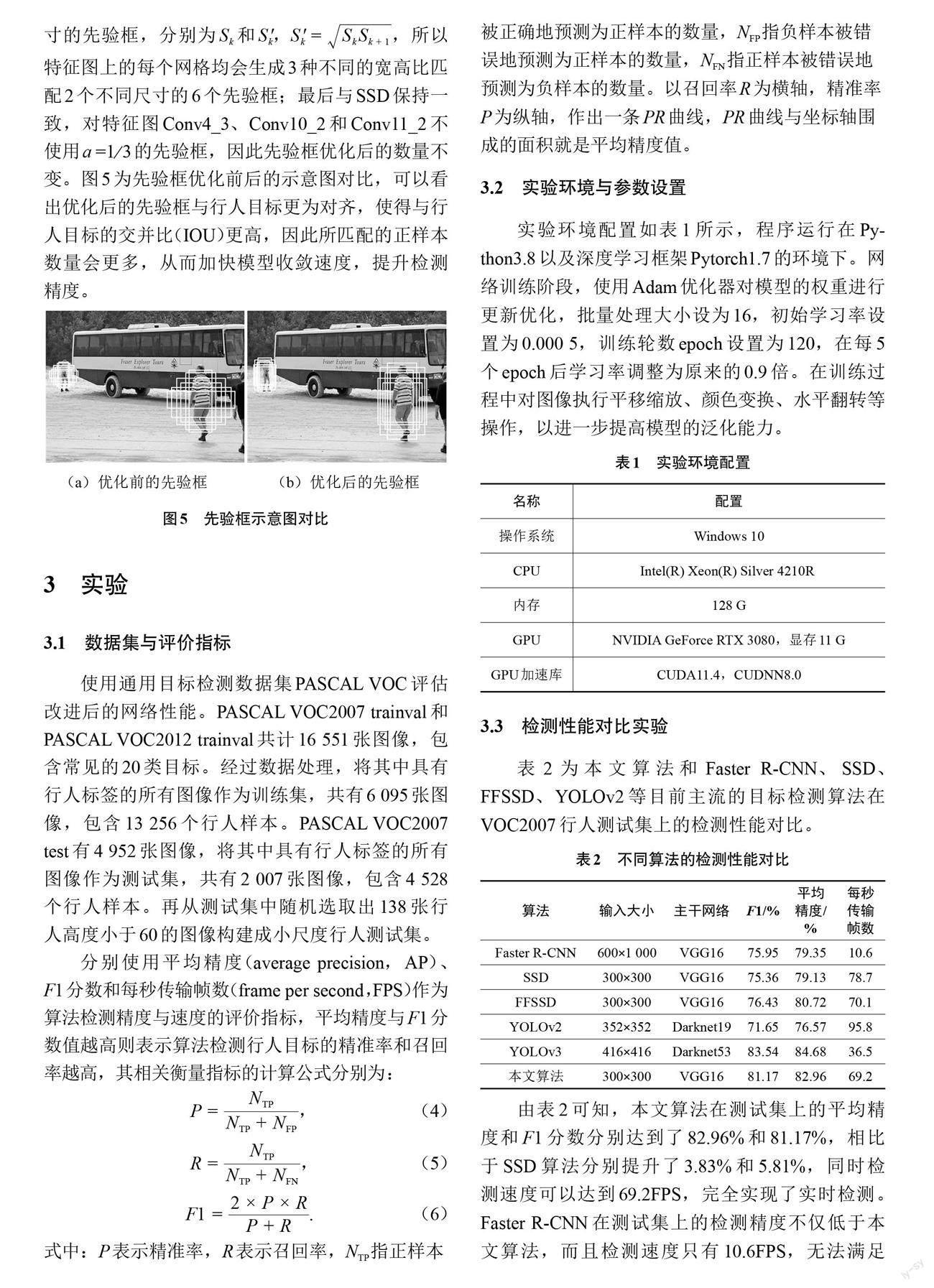
SSD利用多尺度特征图进行检测,能够同时检测到不同大小的目标。由于浅层特征图Conv4_3所经历的卷积运算较少,提取到的特征缺乏语义信息,导致在检测小目标时会存在严重漏检和误检的情况。因此,将深层丰富的语义信息传递回浅层,有利于提高小目标的检测性能。快速小目标检测(feature-fused SSD,FFSSD)[14]利用反卷积的方式对不同深度的特征图进行了可视化,可以看出层次越深的特征图虽然包含的语义信息越丰富,但也会引入更多的背景噪声;并指出Conv5_3包含的小尺度目标的细节信息比Conv4_3更丰富,同时相较于Conv6、Conv7,引入的背景噪声更少,因而更加适合与Conv4_3进行有效融合。
对此,本文提出一种新的特征融合模块以进一步提升模型对小尺度行人的检测性能。如图4所示,为了减少计算量,首先使用1*1卷积将特征图Conv4_3、Conv5_3的通道数都减少为256个,然后对Conv5_3进行2倍上采样,使得特征图尺寸与Conv4_3保持一致。这里使用双线性插值上采样的方式来代替反卷积,一方面是因为可以进一步减少计算量,另一方面是因为反卷积需要训练参数,但双线性插值可以由已知临近像素值进行计算而无需参数。其次通过Concatenate的融合方式对待融合的2个特征图在通道维度上进行拼接,得到尺寸大小为38×38、通道数为512的融合特征图。最后通过大小为3*3的卷积核进行卷积来获取语义信息增强的浅层特征图。在该模块中添加BatchNorm归一化层有利于防止梯度消失,提高网络的泛化能力;在BatchNorm层后加入ReLU激活函数有利于增加网络的非线性能力。实验结果表明,所提的特征融合模块在不明显影响模型的推理速度下,能显著提高对小尺度行人目标的检测精度。
2.3 优化先验框
SSD算法中的先验框是针对多类目标而设置的,而实际场景下的行人目标的真实框多数为“瘦高型”,因此原始的先验框对于行人检测任务而言具有明显缺陷。文献[15]对PASCAL VOC数据集的所有行人样本的宽高比进行了统计,指出宽高比集中分布在0.2~0.5。对此,本文将原始先验框的宽高比调整为[a∈1,12,13],舍弃了其中宽大于高的先验框;然后对每一种宽高比均设置2个不同尺寸的先验框,分别为[Sk]和[S'k,S'k=SkSk+1],所以特征图上的每个网格均会生成3种不同的宽高比匹配2个不同尺寸的6个先验框;最后与SSD保持一致,对特征图Conv4_3、Conv10_2和Conv11_2不使用[a ]=[13]的先验框,因此先验框优化后的数量不变。图5为先验框优化前后的示意图对比,可以看出优化后的先验框与行人目标更为对齐,使得与行人目标的交并比(IOU)更高,因此所匹配的正样本数量会更多,从而加快模型收敛速度,提升检测精度。
3 实验
3.1 数据集与评价指标
使用通用目标检测数据集PASCAL VOC评估改进后的网络性能。PASCAL VOC2007 trainval和PASCAL VOC2012 trainval共计16 551张图像,包含常见的20类目标。经过数据处理,将其中具有行人标签的所有图像作为训练集,共有6 095张图像,包含13 256个行人样本。PASCAL VOC2007 test有4 952张图像,将其中具有行人标签的所有图像作为测试集,共有2 007张图像,包含4 528个行人样本。再从测试集中随机选取出138张行人高度小于60的图像构建成小尺度行人测试集。
分别使用平均精度(average precision,AP)、F1分数和每秒传输帧数(frame per second,FPS)作为算法检测精度与速度的评价指标,平均精度与F1分数值越高则表示算法检测行人目标的精准率和召回率越高,其相关衡量指标的计算公式分别为:
[P=NTPNTP+NFP], (4)
[R=NTPNTP+NFN], (5)
[F1=2×P×RP+R]. (6)
式中:P表示精准率,R表示召回率,NTP指正样本被正确地预测为正样本的数量,NFP指负样本被错误地预测为正样本的数量,NFN指正样本被错误地预测为负样本的数量。以召回率R为横轴,精准率P为纵轴,作出一条PR曲线,PR曲线与坐标轴围成的面积就是平均精度值。
3.2 实验环境与参数设置
实验环境配置如表1所示,程序运行在Python3.8以及深度学习框架Pytorch1.7的环境下。网络训练阶段,使用Adam优化器对模型的权重进行更新优化,批量处理大小设为16,初始学习率设置为0.000 5,训练轮数epoch设置为120,在每5个epoch后学习率调整为原来的0.9倍。在训练过程中对图像执行平移缩放、颜色变换、水平翻转等操作,以进一步提高模型的泛化能力。
3.3 检测性能对比实验
表2为本文算法和Faster R-CNN、SSD、FFSSD、YOLOv2等目前主流的目标检测算法在VOC2007行人测试集上的检测性能对比。
由表2可知,本文算法在测试集上的平均精度和F1分数分别达到了82.96%和81.17%,相比于SSD算法分别提升了3.83%和5.81%,同时检测速度可以达到69.2FPS,完全实现了实时检测。Faster R-CNN在测试集上的检测精度不仅低于本文算法,而且检测速度只有10.6FPS,无法满足实时性要求;与FFSSD相比,本文算法在速度上几乎与之持平,但检测精度明显更高;YOLOv2虽然具有优异的检测速度,但检测精度远低于本文算法;YOLOv3的平均精度与F1分数只比本文分别高出1.72%和2.37%,但本文算法的检测速度具有明显优势。从上述分析可知,本文所提算法在提升检测精度的同时具有良好的检测速度,兼顾了行人检测的精度与实时性。
3.4 消融實验
通过消融实验来分析引入新的模块以及优化先验框(I-Anchor)后对模型检测性能的影响,结果如表3所示。
对比SSD和模型A、B可知,引入注意力机制和特征融合模块后在平均精度上分别提高了0.82%、2.85%;而从检测速度来看,只比原来降低了3.6FPS和5.2FPS,这主要是由于注意力机制的轻量级和特征融合模块结构的简单。对比SSD和模型C可知,优化先验框后,模型的平均精度提高了2.11%,证明了在提供相同数量的先验框的情况下,优化后的先验框区域质量更高;同时由于先验框数量没有增加,模型结构也没有改变,所以检测速度并未受到影响。对比SSD和模型D、E、F可知,任意组合其中2种方法均能提升模型的检测精度,而最终集合3种方法的本文算法模型则在平均精度上取得了最优结果。
3.5 小尺度行人检测实验
为验证本文算法在检测小尺度行人时的有效性,将其与原SSD算法在构建的小尺度行人测试集上进行检测对比,结果如表4所示。由表4可知,本文算法对小尺度行人的平均精度和F1分数比SSD分别提高了5.48%和7.74%,这表明本文对于检测小尺度行人的改进是有效的,大幅度提升了对小尺度行人的检测能力。图6为检测结果部分可视化对比。
从图6中能够看出,SSD对大尺度行人具有不错的检测效果,但很难检测到距离较远的小尺度行人。而本文算法能够精准地检测到更多数量的小尺度行人,也检测到了部分被遮挡的行人,说明本文算法对遮挡行人也具有一定的有效性。此外,本文算法识别出行人的置信度更高,说明对目标的辨识能力更强。综上充分表明本文算法在保证实时性的前提下,可以减少小尺度行人漏检的问题,提高行人检测精度。
4 结论
为了更好地检测行人目标,与目前大多数目标检测算法利用更深的主干网络或采取较为复杂的特征融合方式以牺牲大量的检测速度来提高检测精度不同,本文在SSD网络的基础上,通过引入通道注意力机制来增强网络对关键信息的表达能力,构造一种新的特征融合模块,使浅层特征图充分利用上下文信息,提升对小尺度行人的检测能力;最后根据实际场景下行人的宽高比特性,对原始先验框进行优化,提高对行人的检测效率。实验结果表明,本文算法在PASCAL VOC2007行人测试集和构建的小尺度行人测试集上的整体性能要优于SSD和其他大多数目标检测算法,在保证实时检测的同时显著提升了对行人的检测精度。下一步工作则是对模型体积进行量化,使其便于部署到嵌入式设备上。
参考文献
[1] 邓杰,万旺根.基于改进YOLOv3的密集行人检测[J].电子测量技术,2021,44(11):90-95.
[2] 朱宗洪,李春贵,李炜,等.改进Faster R-CNN模型的汽车喷油器阀座瑕疵检测算法[J].广西科技大学学报,2020,31(1):1-10.
[3] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[C]//29th Annual Conference on Neural Information Processing Systems (NIPS),2015:91-99.
[4] HE K M,GKIOXARI G,DOLLAR P,et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision,2017:2961-2969.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[6] LIU W,ANGUELOV D,ERHAN D,et al.SSD:single shot multibox detector[C]//European Conference on Computer Vision. Springer,Cham,2016:21-37.
[7] REDMON J,FARHADI A.YOLO 9000:better,faster,stronger[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Honolulu,HI,USA,2017:6517-6525.
[8] REDMON J,FARHADI A.Yolov3:an incremental improvement[J].ArXiv,2018.DOI:10.48550/arXiv.1804. 02767.
[9] FU C Y,LIU W,RANGA A,et al. DSSD:deconvolutional single shot detector[J].arXiv,2017.DOI:10.48550/arXiv.1701.06659.
[10] ZHAI S P,SHANG D R,WANG S H,et al.DF-SSD:an improved SSD object detection algorithm based on DenseNet and feature fusion[J].IEEE Access,2020,8:24344-24357.
[11] HU J,SHEN L,ALBANIE S,et al.Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018:7132-7141.
[12] WOO S,PARK J,LEE J Y,et al.Cbam:convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision(ECCV),2018:3-19.
[13] WANG Q L,WU B G,ZHU P F,et al.ECA-Net:efficient channel attention for deep convolutional neural networks[C]//Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition,2020:11531-11539.
[14] CAO G M,XIE X M,YANG W Z,et al.Feature-fused SSD:fast detection for small objects[C]//International Conference on Graphic and Image Processing,2017.
[15] 熊壽禹,陶青川,戴亚峰.一种轻量级的卷积神经网络的行人检测方法[J].计算机应用与软件,2021,38(9):220-225,231.
Pedestrian detection algorithm based on improved SSD
ZHANG Lun,TAN Guangxing*
(School of Automation, Guangxi University of Science and Technology, Liuzhou 545616, China)
Abstract: Aimed at the problem that the current mainstream object detection algorithms cannot balance precision and real-time performance in pedestrian detection, a pedestrian detection algorithm based on improved single shot multibox detector (SSD) is proposed. Firstly, in order to guide the network to pay more attention to the feature information of small-scale pedestrians, the efficient channel attention mechanism is introduced into the shallow network to redistribute feature weights. Then, a new feature fusion module is designed to improve the insufficient semantic information of shallow feature. Finally, by optimizing the parameters of the original anchor to generate the anchor suitable for detecting pedestrians. Experimental results show that the proposed algorithm has an average accuracy of 82.96% on the PASCAL VOC2007 test set, which is 3.83% higher than that of the SSD, and 5.48% higher than that on the small-scale pedestrian test set respectively. At the same time, the detection speed reaches 69.2 frames per second, which meets the requirement of real-time performance.
Key words: single shof multibox detector (SSD); pedestrian detection; attention mechanism; feature fusion
(责任编辑:黎 娅)
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
软件导刊(2017年7期)2017-09-05 06:27:00
无线互联科技(2017年12期)2017-07-18 17:40:58
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
