
基于改进YOLOv3的电梯内电动车检测算法
2023-07-17 05:57:28杨献瑜
计算机时代 2023年7期
关键词:目标检测
杨献瑜
关键词:目标检测;轻量化网络;注意力模块;YOLOv3;CIOU
0 引言
电梯作为高层建筑中的重要交通工具,常见的安全隐患问题如轿厢困人、电梯冲顶、反复开关门、携带可燃易爆物品等[1],通过“智慧电梯”[2]安全管理平台得到了有效解决,但目前对禁止电动车等可燃易爆物品进入电梯仍缺乏有效的方法[3]。2021 年5 月,四川省某小区的电梯内一辆电动车瞬间爆燃,导致多人受伤。2021 年11 月,合肥市一小区住户的电动自行车在屋内充电时燃烧,导致火情。因此,有必要对电动车进入电梯进行检测。
防止电动车进入电梯,可在电梯口附近立警示牌,以及对电梯内监控视频进行监测等。这些方法虽然有效,但效率低。如今基于深度学习的目标检测算法被广泛应用于计算机视觉的各个领域,达到了非常好的效果。2019 年华志超[4]在YOLOv1 中添加批规范化算法以及改进损失函数,实现电梯禁入目标检测。2020 年岑思阳[5]在YOLOv3 中使用GIOU 损失函数并改进边界框的生成,实现电梯内人脸检测。2021 年张媛等人[6]提出了基于YOLOv3 的电动车检测算法,实现电梯内电动车实时检测。
虽然以上算法对目标具有良好的检测效果,但模型计算量和参数量较大,难以在硬件条件有限的边缘设备上应用。因此,本文提出基于改进YOLOv3 的电梯内电动车检测算法,实现模型的轻量化。首先将YOLOv3 中负责提取特征的主干网络Darknet53 替换为MobileNetv2;然后在主干网络和特征融合网络之间引入CA 注意力机制,提高模型的检测能力;最后使用CIOU 作为计算目标边界框的回归定位损失,增强精准定位效果。
1 YOLOv3 检测模型
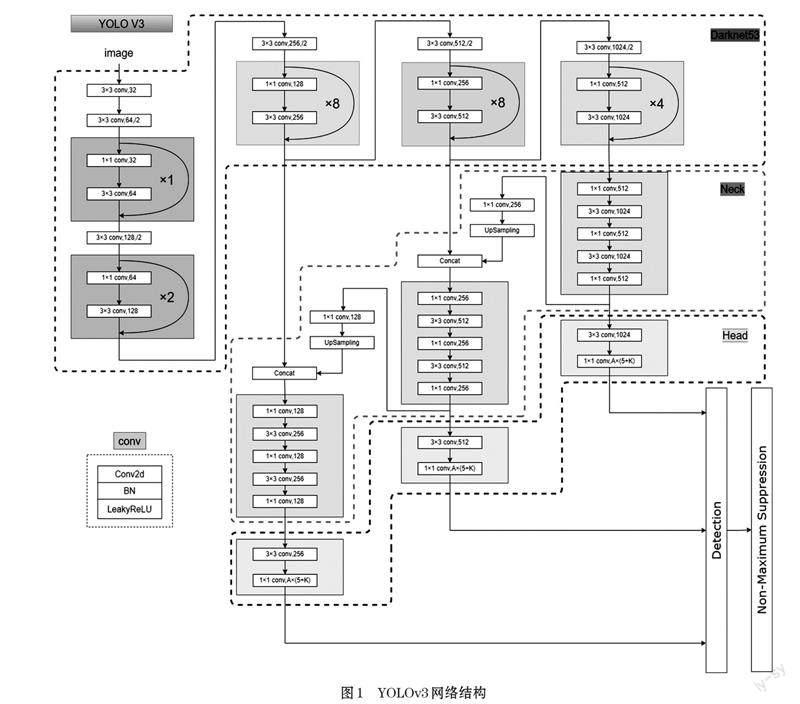
YOLOv3 由Joseph Redmon 等人[7]在2016 年提出,是一种单阶段目标检测算法。该网络采用Darknet53作为主干特征提取网络,使用特征金字塔结构[8]加强特征提取,利用检测头对有效特征层进行预测。图1展示了YOLOv3 的网络结构。
2 改进YOLOv3 检测模型
2.1 MobileNetV2
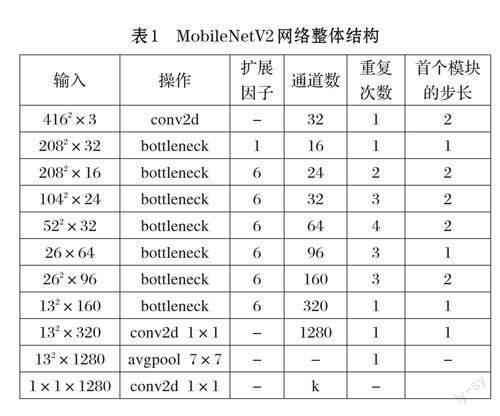
2018 年Google 提出了轻量化网络MobileNetV2[9]。该网络主要包含17 个倒残差结构(bottleneck),每个倒残差结构由一个3×3的DW卷积(depthwise convolution)和两个1×1 的PW 卷积(pointwise convolution)组成。相较于普通卷积,由DW 卷积和PW 卷积构成的深度可分离卷积,能大幅减少模型的参数量以及运算成本。MobileNetV2 第二个特点是linearbottlenecks,主要表现在倒残差结构中的第二个PW 卷积后使用线性激活函数,以减少特征信息的损失。MobileNetV2 网络整体结构如表1 所示。在本文中,将使用轻量化网络MobileNetV2 来对YOLOv3 检测模型进行改进。
2.2 CA 注意力机制
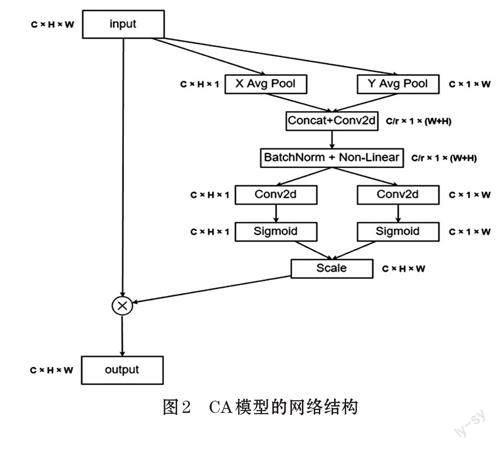
在深度学习中,注意力机制能够增强网络对有效特征信息的提取,提高检测精度。2021 年Qibin Hou等人提出CA(Coordinate Attention)[10]注意力机制,不仅考虑了通道信息,还考虑了方向相关的位置信息。相比于CBAM[11],CA 实现更为简单,并且能在空间维度上构造远程的依赖关系。在CA 中,首先对输入进来的特征图分别沿着水平和垂直方向进行平均池化,得到两个不同的特征图。然后对两个特征图进行拼接以及卷积操作降维,建立远程依赖关系。再对得到的特征图进行BN 操作以及h-swish 激活。最后,沿着空间维度对特征图进行分割,得到沿水平方向以及沿垂直方向的注意力特征图,对这两组注意力特征图使用卷积操作进行升维,使用Sigmoid 将值域限制在0 和1 之间。基于CA 模块的网络结构如图2 所示。在本文中,将使用CA 注意力機制来对YOLOv3 检测模型进行改进。
2.3 CIOU 损失函数
YOLOv3 损失函数包括边界框定位损失、置信度损失以及类别损失,其中边界框定位损失使用MSE 损失函数进行计算。2016 年Jiahui Yu 等人[12]提出了IOU 损失,相较于MSE 损失,IOU 损失能够更好的反应边界框的重合程度,具有尺度不变性。2019 年,Zhaohui Zheng 等人[13]提出了DIOU 损失以及CIOU 损失,DIOU 损失在IOU 损失的基础上添加了中心点归一化距离,使收敛速度更快、回归精度更高。CIOU 损失是对DIOU 损失的进一步改进,将长宽比参数引入到损失函数中。CIOU 损失共包含重叠面积、中心点距离、长宽比3 种几何参数,其计算公式为:
其中,P 表示预测框,G 表示真实框,IOU 反映的重叠面积;ρ(b,bgt)表示的是预测框中心点坐标与真实框中心点坐标的欧式距离,c 表示的是覆盖预测框与真实框的最小外接边界框对角线长度,ρ2(b,bgt)/c2反映的是中心点距离;v 表示的是预测框与真实框长宽比一致性参数,α表示的是平衡参数,αv 反映的是长宽比。因此,CIOU 损失能更好的反应边界框的重合重度,加速损失函数收敛。在本文中,将使用CIOU 损失函数来对YOLOv3 检测模型进行改进。
2.4 改进后的网络总体结构
本文对YOLOv3 检测模型进行改进,使用MobileNetV2作为骨干网络提取特征,减少模型的参数量和计算量;使用CA 注意力模块,让模型更加关注图像中有用的特征信息,提高模型性能;使用CIOU 损失替换MSE 损失,加速网络收敛以及实现精准定位。改进后的YOLOv3 检测模型命名为YOLO-MAC,其网络总体结构如图3 所示。
3 实验与结果分析
3.1 数据集采集与处理
本文通过网上搜索、爬虫、实地拍摄等方法,对电梯内电动车图片进行采集,共筛选出2300 张电梯内电动车图片。为丰富图片的特征,对采集到的图片添加随机遮挡、高斯模糊、亮度调节、水平翻转等数据增强算法,对数据集进行扩充。扩充后共有3300 张图片,其中划分2700 张图片作为训练集、300 张图片作为验证集、300 张图片作为测试集。数据增强后的图片如图4 所示。
3.2 实验环境以及超参数设置
本文实验在Ubuntu 20.04.2 操作系统下,采用Pytorch1.10.1 深度学习框架,CUDA 版本为11.6,使用Python3.7.10。计算机硬件包括NVIDIA GeForceRTX 3060 12GB GPU、Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz、24GB 内存。
本文实验设置网络输入为416×416×3,在每次迭代的时候使用余弦退火来对学习率进行衰减,采用SGD 优化算法进行参数更新,引入遷移学习的方式获得骨干网络预训练权重。模型初始学习率设置为0.001,将训练分为两个阶段。在第一阶段,特征提取网络被冻结,批处理大小设置为16,迭代次数为50 轮。在第二阶段,特征提取网络解冻,批处理大小设置为8,迭代次数为50 轮。
3.3 实验结果分析
为了验证改进算法YOLO-MAC 的可行性,以及改进方法对电梯场景下电动车检测模型的影响,将YOLOv3 与替换骨干网络后的模型YOLO-M、加入CA 注意力机制的YOLO-MA 以及本文提出的YOLO-MAC 进行对比分析。对比实验使用相同的测试集,从计算量、参数量、mAP 和FPS 四个方面对模型进行比较,实验结果如表2 所示。
从表2 可以看出,使用轻量化网络MobileNetV2替换YOLOv3 的特征提取网络DarkNet53,可以大幅减少模型的计算量以及参数量,但同时也造成了约3%的mAP 精度损失。在YOLO-M 模型中加入CA 注意力模块后,使模型对电梯内电动车的检测精度从87.37% 提升到89.23%,证明CA 注意力模块的有效性。最后,在YOLO-MA 的基础上对模型损失函数进行改进,进一步提高了检测精度,mAP 值达到89.89%。在FPS 方面,改进后的模型YOLO-MAC,检测速度比YOLOv3 提升7.2 帧/秒,适合部署于边缘设备上。综上所述,YOLO-MAC 模型兼顾了推断速度和检测精度,更适合进行电梯内的电动车检测。
图5 对比了YOLOv3 以及改进后的YOLO_MAC对电梯内的电动车图像进行检测的结果。从图5 可以看出,YOLO-MAC 算法不仅检测效果好,而且定位性能更高,验证了本文改进方法的有效性。
4 结论
针对YOLOv3 算法模型参数量较多,难以在硬件条件有限的边缘设备上进行检测等问题,本文提出一种基于改进YOLOv3 的电梯内电动车检测算法。该方法以单阶段目标检测算法YOLOv3 为基础,使用轻量化网络MobileNetV2 作为骨干网络提取特征,引入CA 注意力模块,使用CIOU 对损失函数进行改进。实验结果表明,改进的YOLO-MAC 的mAP 与YOLOv3相近,但有效地减少了模型的计算量和参数量,检测速度比YOLOv3 提升7.2 帧/秒。这证明该算法可行有效,能够满足电梯内电动车检测任务。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21 18:48:01
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
无线互联科技(2016年7期)2016-05-30 13:57:06
电脑知识与技术(2016年5期)2016-04-14 13:48:16
科技视界(2016年4期)2016-02-22 13:09:19
哈尔滨理工大学学报(2015年5期)2016-01-19 18:06:12
湖南大学学报·自然科学版(2015年10期)2015-11-30 18:52:07
现代电子技术(2015年20期)2015-10-26 22:48:16
