
结合改进注意力机制的YOLO目标检测算法
2023-07-17 08:51:11李杰
计算机时代 2023年7期
李杰

关键词:YOLO;目标检测;多尺度卷积;注意力机制
0 引言
自从Hinton 提出利用神经网络对图像数据中的高维特征进行自主学习[1]以来,基于深度学习的目标检测已成为计算机视觉领域中一个重要的研究热点[2]。目标检测的方法主要分为双阶段和单阶段目标检测算法。双阶段目标检测算法,如Fast R-CNN[3]、Faster R-CNN[4]等,都是通过生成预选框再利用神经网络对候选框进行分类识别。单阶段目标检测算法,如YOLO (you only look once) [5]、YOLO 9000[6]等,将目标检测问题转化为回归问题,由一个无分支的深度卷积网络实现目标的定位和分类。单阶段算法有着较高的检测速率,但还存在检测精度不足的问题。
注意力机制是对特征图进行加权处理[7],旨在突出强调目标信息。Hu[8]等人通过卷积运算学习各通道权重来自适应地重新校准通道特征响应。Woo 等人提出一种混合注意力机制CBAM(convolutional blockattention module)[9],将特征图沿通道和空间两个不同的维度顺序地进行自适应特征细化。Sun 等人将ShuffleNet 结构引入到YOLOv4 中[10],减少参数量的同时检测精度和速度方面也有所提升;Fu 等人将CBAM注意力模块添加到YOLOv4-head 中[11],对小目标、重叠目标具有更好的检测效果。但上述研究还存在检测精度不足或是没有在大型公共数据集上进行综合性能测试。
为此,本文在YOLOv5s 的基础上进行了研究和改进。①将多尺度卷积与注意力机制结合,提出一种改进CBAM 注意力机制模块,增大特征提取模块的感受野;②将改进CBAM 模块引入YOLOv5s 网络中,使用改进后的注意力机制模块进行特征筛选,提高改进检测网络准确率。
1 YOLOv5s 和CBAM 算法
1.1 YOLOv5s 算法
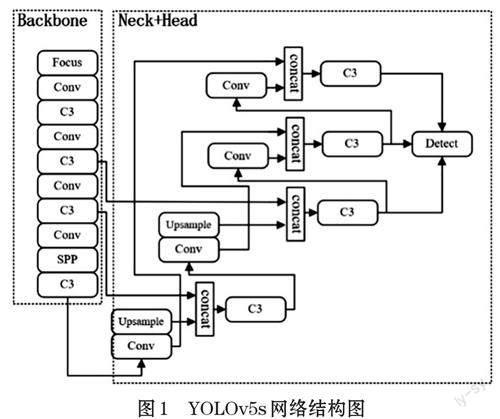
本文在YOLOv5s网络的基础上进行改进。YOLOv5s的网络结构分为主干网络部分Backbone、特征增强部分Neck 和预测部分Head,如图1 所示。
网络主干Backbone 主要由连续卷积模块Conv 和利用划分通道的思想构建的C3 模块。C3 模块是由1×1 和3×3 卷积构成,包含LeakyReLU 函数激活的BottleneckCSP 结构。主干网络末端还加入一个特征金字塔池化模块SPP,使用多尺度的特征融合以获取更多小目标的有用信息从而提升算法对小目标检测的精确度。
特征增强Neck 部分采用了FPN[12]+PAN 结合的方式对特征进行融合从而获得更好的效果。PAN 包含了自上而下和自底向上两条路径上的特征融合,这也使网络获得更高的性能。
预测部分Head使用的是GIOU_Loss作为Boundingbox 的损失函数,并且在进行非最大值抑制时引入加权因子,在Bounding box 回归时平衡了正负样本之间的差距。
1.2 CBAM 算法
注意力机制是一种能够让神经网络拥有能区分重点区域信息的能力,并对该区域投入更大的权重,突出和加强有用特征,抑制和忽略无关特征。由Woo等人提出的CBAM 算法是一种混合注意力机制。算法结构如图2 所示。
CBAM 注意力机制可分为两个顺序子模块:通道注意模块和空间注意模块。结构采取串联形式。Woo等人已经证明将通道注意子模块放在空间注意子模块之前会有更好的效果[9],因此本文也使用相同的顺序结构。
2 引入多尺度卷积的改进注意力机制
传统混合域注意力机制CBAM,注意力子模塊会将特征图直接进行通道域和空间域的全局最大池化和全局平均池化。这样做法虽然能够简便的提取通道域和空间域的权重,但模块对于特征图中的信息的利用率低,从而影响检测网络的准确性。
本文沿用传统混合域注意力机制CBAM 的顺序串联结构,并对其通道注意子模块和空间注意子模块进行了改进,构建一种改进CBAM 注意力机制模块,下面描述每个改进注意力子模块的细节。
2.1 通道注意子模块
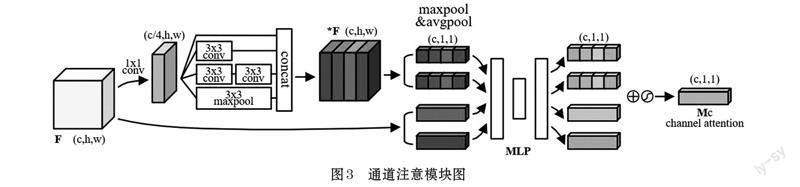
将多尺度卷积引入到注意力机制中,基于便利性也为了减少网络参数只使用3×3 的卷积,同时结构中保留了一个没有任何操作的路径来增加网络性能。此外,池化操作对于当前卷积网络的性能提升是必不可少的,因此添加一个并行池化路径也具有好的效果[14]。为了避免池化层的输出与卷积层的输出合并会导致特征图维度的增加,先使用1×1 卷积来约简计算,由于有共计四层的输出,所以将原特征图的通道数降为原来的1/4。
对于一个输入特征图F ∈ Rc × h × w,通道注意子模块对原特征图进行两路并行处理,第一部分进行多尺度卷积操作生成新的特征图*F ∈ Rc × h × w 再进行最大池化和平均池化,第二部分不进行任何操作直接进行最大池化和平均池化,得到四个的通道注意力向量:{ } Fcmax ,F cavg ,*Fcmax ,*F cavg ∈ Rc × 1 × 1,分别表示平均池化特征和最大池化特征。利用一个共享的多层感知机(multi-layer perceptron, MLP) 学习各通道信息的重要性,最后将四个通道注意力向量逐元素求和来合并再经过Sigmoid 函数激活得到最终的通道注意权重Mc(F)。简而言之,通道注意力权重计算公式为:
2.2 空间注意子模块
将通道注意的结果进一步进行空间权重的提取。空间注意子模块对输入特征图F' ∈ Rc × h × w 也进行与通道注意子模块相同的两路并行处理,第一部分使用相同的改进多尺度卷积生成新的特征图*F' ∈ Rc × h × w再沿通道轴应用最大池化和平均池化,第二部分不进行任何操作,直接应用最大池化和平均池化,将得到4个的空间注意力矩阵:{F's }max ,F 'savg ,*F 'smax ,*F 'savg ∈ R1 × h × w,分别表示通道中的平均池化特征和最大池化特征,并将它们连接起来以生成有效的特征描述图。在特征将通道权重Mc (F)与输入F进行对应通道的加权,得到通道注意的结果。共享网络MLP 是带有一个隐藏层的多层感知器,为了减少参数量,隐藏层的大小设置为R(c/r) × h × w,其中r 是缩减率,本文中r 设为16。这样两层卷积在减少卷积参数量的同时也能够对各个通道上的特征重要程度进行学习。改进通道注意模块如图3 所示。
2.3 改进CBAM 注意力模块
将两个改进子模块顺序串联,先用改进通道注意力子模块校正,然后对结果在进行空间注意力子模块校正。整个改进注意力过程可以用公式概括为:
相比CBAM 中只对原特征图进行最大池化和平均池化操作,在改进CBAM 结构中增加了使用卷积、拼接的多尺度卷积运算来生成新的特征图,两路运算并行处理。引入多尺度卷积能够提升运算所得的通道注意权重和空间注意权重的感受野,强调目标信息同时过滤其他冗余信息。
3 结合改进CBAM 的YOLOv5s 算法
在原始YOLOv5s 中,特征增强部分会对特征图进行反复融合, 并且还会使用多个连续卷积运算。这种做法虽然能够使不同尺度的特征信息相互结合,但此过程也会产生大量冗余信息,降低网络的检测精度。同时对高维特征图使用多个连续卷积运算,增加网络运行的参数和计算量,也会影响网络的检测性能[13]。
在目标检测网络中添加注意力机制,能够显著增强特征中的重要信息,对物体检测有着重要的作用[7]。因此将改进CBAM 引入到YOLOv5s 中。在输入预测部分进行预测前,使用改进后的注意力模块对其进行处理以提取到更全面、更重要的目标信息,过滤其他冗余信息,增加检测网络的准确率[15]。改进后的YOLOv5s 网络结构如图5 所示。
4 实验结果分析
4.1 数据集和网络训练
为验证本文所提出的结合改进注意力机制的YOLOv5s 目标检测网络的性能, 在PASCAL VOC 数据集上进行了训练和验证。在本实验中,将图片转换为长宽512 大小作为网络输入,选取VOC 2012 训练验证集及VOC 2007 训练验证集作为训练数据,将VOC 2007 训练验证集部分数据作为验证集。
本文在TeslaV100 上进行训练和测试模型。操作系统是Ubuntu18.04,开发语言是Python,框架是PyTorch,训练采用了Amd 优化器进行参数优化。在训练时使用迁移学习加载预训练模型。训练网络时,网络输入大小为512×512 彩色图像,batch_size 为64,初始学习率为0.0032,迭代总批次为200,权重衰减设置为0.00012. 学习率采用余弦退火衰减来保证模型更好的收敛。
4.2 结果与对比
将训练后的网络在PASCAL VOC 测试集上进行测试,在IOU 阈值为0.5 的情况下,绘制了召回率-精确度曲线图,如图6 所示。横坐标Recall 表示召回率,纵坐标Precision 表示精度。改进后的模型对各个类别均有一定的检测精度,并对数据集中所有类别的平均准确率(mAP)达到了76.1%。
4.2.1 改进前后结果对比
为对比改进后的检测网络的检测效果。分别对YOLOv5s、YOLOv5s+CBAM、YOLOv5s+改进CBAM三种模型在PASCAL VOC 测试集上的平均准确率mAP 和其他性能指标进行了测试。如表1 所示,其中加粗数值为三种模型中表现最优值。
实验结果表明在两种IOU阈值下,本文的YOLOv5s+改进CBAM 模型相較于其他两种模型在平均准确率方面均有所提升。当IOU 阈值为0.5 时,本文方法相较于原始YOLOv5s 模型的mAP 上升了0.9%,相较于YOLOv5s+CBAM 模型的mAP 上升了0.3%。当IOU阈值在区间[0.5:0.95]时,本文方法较另外两种模型分别提高了1.1%、0.4%。在检测精度方面,YOLOv5s+改进CBAM 模型精度为78.4%,为最优值。在召回率方面较其他两种模型低,但F1-score 均较其他两种模型分别提高了1.2%、0.9%。
为了更直观的发现改进网络检测能力的提升,实验进一步获取了改进前后的可视化测试结果,如图7所示。
对比原始YOLOv5s 模型和本文的YOLOv5s+改进CBAM 模型,改进后的模型在复杂场景下能够检测出更多目标。对于图中未遮挡的目标,改进后的模型能有更高的置信度。尽管有遮挡部分的目标较原始YOLOv5s 模型识别置信度有所下降,但改进后的模型仍然能成功检测出这些目标,也进一步证明了改进后的模型有更好的检测性能。
4.2.2 不同检测算法对比
本文将改进后的网络与近年来其他目标检测网络进行比较,结果如表2 所示,表中加粗数值为表现最优值。
以ResNet-152 为骨干的PS-DK 网络,由于使用了足够大且深的骨干网络,其检测准确率达到了79.5%,改进后的网络的准确率较之低了3.4%,但改进后的网络参数量更少,仅为PS-DK 网络参数的1/10。另外对于一些轻量化网络,如EEEA-Net-C2 网络,尽管参数量有所增加,但在检测准确率方面较之提高了4.4%。结果表明改进后的检测网络在与近年来其他先进的目标检测网络对比中,也表现出较好的性能。
5 结束语
本文提出了一种改进注意力机制模型,并将其引入到YOLOv5s 目标检测网络中,提高检测网络的准确率。提出改进CBAM 结构,引入多尺度卷积增加特征感受野提升算法性能的效果。YOLOv5s 目标检测网络在输入预测部分前使用改进注意力机制模块,提高网络检测的准确率。改进后的网络在VOC 数据集上的准确率达到了76.1%,较原网络整体准确率提升了0.9%,F1-score 也获得了1.2% 的提升,同时在近年来的目标检测网络中表现出不错的性能。接下来还将继续优化网络结构,同时研究如何提升对有遮挡的目标的检测效果。
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
