
基于机器学习的基金收益预测
2023-07-11 11:12:02李仁宇叶子谦
统计与决策 2023年11期
李仁宇,叶子谦
(1.武汉大学 经济与管理学院,武汉 430072;2.长江证券(上海)资产管理有限公司,上海 200135)
0 引言
党的二十大报告指出,全面建设社会主义现代化国家的首要任务是高质量发展。理财市场作为多层次资本市场的重要组成部分,是推动新时代中国特色金融体系高质量发展的主要支撑。2022年以来,党中央、国务院通过一揽子经济政策[1],以降低实体经济融资成本,为理财市场提供了有利的市场环境,理财市场规模稳步增长[2]。随着2022 年资管新规的全面落地,全面净值化发展是理财产品的新特色,但无法避免的净值波动在一定程度上难以满足我国多数投资者短期、低风险的理财需求。基金产品通过分散投资的策略能够有效地降低投资风险,逐渐进入个人投资者的视野。截至2023年2月,中国公募基金的产品数量已达到10537支,数量远超上市公司股票的基金产品无疑增加了投资者的选择困难。2022 年颁布的《国务院办公厅关于推动个人养老金发展的意见》加强了个人养老金作为我国养老金体系第三支柱的作用。作为个人养老金账户的投资标的之一,由基金产品组成的养老目标FOF基金能够满足投资者资产增值的目的,同时也将成为机构投资者重点布局的领域之一。由此可见,无论对于个人还是机构投资者而言,资产保值增值的需求都更加迫切,为了更好地满足投资理财的需求,基金研究的重要性日益突显。通过选择优质基金,有助于构建更加稳定、更具收益的投资组合,帮助居民和机构投资者进行资产保值增值,引导投资者树立价值投资理念,从而更好地促进我国资本市场的高质量发展。
基金能否获得超越市场基准的收益始终是基金研究的核心问题,对此学术界存在不同的观点。Fama和French(2010)[3]认为几乎所有的基金均无法获得显著的超额收益,而Kosowski 等(2006)[4]的研究表明部分基金能够获得显著并且持续超越市场基准的收益。基金收益预测研究同样是基金研究的核心之一,近些年的研究成果陆续发现了具备基金收益预测性的指标。早期的研究表明基金的净值类特征,例如动量[5]、资金流[6]以及基金近期超额收益[7]等均被验证具备基金收益预测性。后续的研究从基金的持仓角度进行分析,进一步丰富了基金特征的分析维度。通过对比基金持股与基准指数成分股的差异,Cremers 和Petajisto(2009)[8]、Doshi等(2015)[9]分别引入了主动份额与主动权重用来描述基金的主动管理程度,并根据样本外数据验证了主动管理程度高的基金能够获得超额收益。由于中国公募基金的全持仓信息为每半年披露一次,投资者并不能及时了解基金的最新持仓信息,因此基金的真实收益与披露持仓的模拟收益之间存在一个差值,而Kacperczyk 和Seru(2007)[10]的研究表明收益差高的基金更容易获得超额收益。
随着基金指标的不断扩充,各个预测指标均含有一定的信息和噪音,由于金融市场上的指标普遍具有信噪比较低的特点,因此如何将多维度的基金特征有效利用、剔除噪音从而提取有效的信息,进而构建具有超额收益的基金组合成了新兴的研究热点。机器学习算法作为人工智能的一个重要分支,可以对一列特征进行降维,从大量指标中提取有效的信息,近年来,已有许多学者将其应用于资产定价的研究之中[11,12]。基于机器学习算法的预测模型可以通过海量的数据进行迭代学习,从而提供稳健的决策建议,特别是在针对贴合实际情况的高维非线性数据研究中表现出优秀的适应性[11]。在基金收益预测研究领域,Li和Ross(i2020)[13]从股票的异象因子对股票未来收益具备显著预测能力的角度出发,通过基金持仓股票信息与增强回归树算法验证了非线性模型对美国市场中基金具备显著的收益预测能力;DeMiguel等(2021)[14]证明了梯度提升决策树算法(Gradient Boosting Decision Tree,GBDT)可以从基金的常规特征中提取出有效信息,通过GBDT模型预测业绩最好的基金所构建的多头组合可以获得显著的风险调整后收益。
虽然已有研究结果表明机器学习模型具备基金收益预测能力,但探究机器学习模型对中国市场基金收益预测能力的相关研究仍然不足。本文参考已有的相关文献,以中国市场基金作为样本,系统地构建了30 个基金异象因子,研究机器学习算法对预测基金未来收益的有效性。
1 研究设计
1.1 样本数据
本文的基金研究样本为Wind数据库中投资类型属于普通股票型与偏股混合型的开放式基金,并剔除了投资港股的沪港通基金和分级基金。为了避免基金建仓期导致数据缺失等问题,本文还剔除了成立时间不满一年的基金,同时要求在每个截面上使用的基金样本要具备两年以上的月度收益数据。由于2005年之前符合上述条件的基金样本数量过少,因此,本文选取2005—2021年作为研究区间[15]。本文所使用的基金因子数据中,除了FamaFrench三因子、Carhart 四因子数据来源于CSMAR 数据库,其他所用到的基金净值数据以及持仓股票数据均来源于Wind数据库。
1.2 因子检验方法
1.2.1 投资组合排序分析法
投资组合排序分析法是根据待检验的因子特征变量数值大小对资产进行排序和分组,构建投资组合,然后持有一段时间以计算每个投资组合的超额收益,通过比较不同投资组合的收益大小来判断是否存在显著差异,以测试该因子是否能够预测资产的横截面收益率。由于该方法是一种非参数分析方法,所以不需要对变量的分布以及变量之间的关系进行严格的假设,常用于实证资产定价研究[16]。
具体而言,将待检验的变量从小到大进行排序,然后根据十分位点将样本基金划分成十个组合。第一个投资组合包括所有变量值小于第一个十分位点的样本,记为“Low”组,即空头组合。变量值在第一断点和第二断点之间的样本构成第二个组合,以此类推。排序变量值高于最高断点的样本将被放在最后一个投资组合中,标记为“High”组,即为多头组合。设定每月月末对投资组合进行调仓,计算每个投资组合的资产收益率,组合内部单个资产的权重设为等权重。“High”组合与“Low”组合的收益率之差,即多空对冲组合的收益率。如果多空对冲组合的收益率显著大于0,则说明待检验的变量可以显著预测资产的未来收益。除了检验多空对冲组合的原始收益率以外,本文还使用FF3因子模型[17]计算了风险调整后收益。
检验收益率序列是否显著通常用t统计量来判断。不过由于时间序列数据往往表现出自相关或异方差,这将会导致用于检验原假设的标准误差、P 值和t 统计量都可能不准确,从而影响显著性的判断。所以本文使用了Newey和West(1987)[18]的方法对t 统计量进行调整,即Newey-West t统计量,简称NW-t检验。
1.2.2 Fama-Macbeth回归检验
Fama-Macbeth 回归分析法是由Fama 和Macbeth(1973)[19]提出的一种参数检验方法。该方法分为两个步骤。第一步是横截面回归,所使用的被解释变量是t期的资产超额收益率,解释变量是t-1期的特征变量和控制变量,如下所示:
其中,Yi,t表示资产i在t期的收益率,X1i,t-1是资产i在t-1 期的特征变量X1,β1,t-1是t-1 期特征变量X1 的系数,αt表示截距项,εi,t表示残差项。在每个截面分别进行上述回归,从而获得每个回归系数的时间序列。
第二步是时间序列检验,即检验第一步得到的回归系数的平均值是否显著异于0。
1.3 聚合方法
1.3.1 线性回归
经典的线性回归以最小化残差平方和为目标,对一个或多个自变量和因变量之间的关系建立一个回归方程。其表达式为:
或简写成:
其中,Y 表示因变量,X 表示自变量,β为拟合系数。对于给定的样本Xi,因变量真实值为Yi,预测值为=βT Xi,将平方损失函数定义为该函数的损失函数:
其中,n 为样本数量。通过最小化损失函数,便可求得方程的最优拟合系数,该方程被称为普通最小二乘回归(OLS)。本文将OLS模型作为基准模型,与机器学习算法进行比较。
1.3.2 LightGBM模型
LightGBM(Light Gradient Boosting Machine,简 称LightGBM或LGBM)是梯度提升树的改进方法之一。梯度提升决策树(Gradient Boosting Decision Tree,简称GBDT)是一种Boosting 算法,Boosting 算法的原理是通过集成弱分类器来提高模型预测的稳定性和准确性。GBDT 的主要思想是:将每个CART 树作为一个基学习器,将每一棵树拟合之前所有树的残差,构建新的树加到当前模型中形成新的模型,而为了消除残差,模型在残差减少的梯度(Gradient)方向上建立一个新的模型,使损失函数沿着梯度方向下降。通过重复以上过程,不断降低模型的残差,从而获得最终的模型。其中,每个决策树进行分支时,以最小化平方误差为目标,对每一个特征的每一个阈值进行穷举以寻求最优的分割点。
作为GBDT 的改进方法,LightGBM 同样是Boosting 算法的代表性非线性机器学习模型之一。LightGBM使用决策树作为基学习器,通过Boosting算法集成多个简单的基学习器,再通过多个学习器的学习,不断降低模型值和实际值的差。它的主要特点有:使用直方图算法进行优化从而使得训练速度更快,降低了内存使用率;使用GOSS减少大量只具有小梯度的样本,在计算信息增益的时候只利用具有高梯度的数据,从而减少了计算开销;带深度限制的Leaf-wise 的叶子生长策略,使用带有深度限制的按叶子生长算法,不仅减少了时间和空间的开销,而且有效降低了过拟合;支持并行计算从而减少计算时间等。
1.4 模型设计
本文使用LightGBM 模型,基于基金异象因子构建基金收益预测的多因子模型。具体步骤为以t-1 期的N 个因子为解释变量,t 期的基金收益为被解释变量进行拟合训练。设定模型形式为:
其中,f(·) 定义一个参数为θ的函数,代表降维模型,Rt,i为基金i第t期的超额收益,xt-1,i为基金i第t-1 期的N个异象因子,∊t,i为误差项。每个异象因子在截面上进行了标准化处理。本文采用滑动窗口法划分训练集、验证集与测试集,其中训练集为12个月,验证集和测试集分别为1 个月。最后根据模型的预测值对下一个月的基金进行排序分组进而构建投资组合。如图1 所示,假设当前处于2006 年2 月,训练集则由2005年12个月的数据构成并用于模型拟合训练。2006年1月作为验证集数据,将用于机器学习模型的样本外调参,本文将采用网格调参(Grid Search)方式筛选最优的机器学习模型超参数,最终使用筛选所得的最优超参数,通过训练集与验证集的数据进行模型训练。模型完成训练以后将2006年2月的因子输入模型即可预测2006年3月的收益,然后根据预测值对基金排序分组构建多头组合、空头组合以及多空组合。
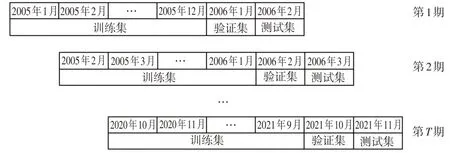
图1 滑动窗口法
1.5 因子说明
本文的实证分析皆通过月度频率进行计算,而部分异象因子数据需要使用基金季频的前十大重仓或半年频的全持仓信息,对于这类因子,本文将季频与半年频的数据进行月度填充。由于基金的季报与半年报存在披露延迟的情况,因此数据填充时将使用已披露的最新一期报告中的相关信息。本文参考大量文献,系统性地梳理了30 个已被证实有效的基金因子进行研究,详细的因子名称及描述见下页表1。
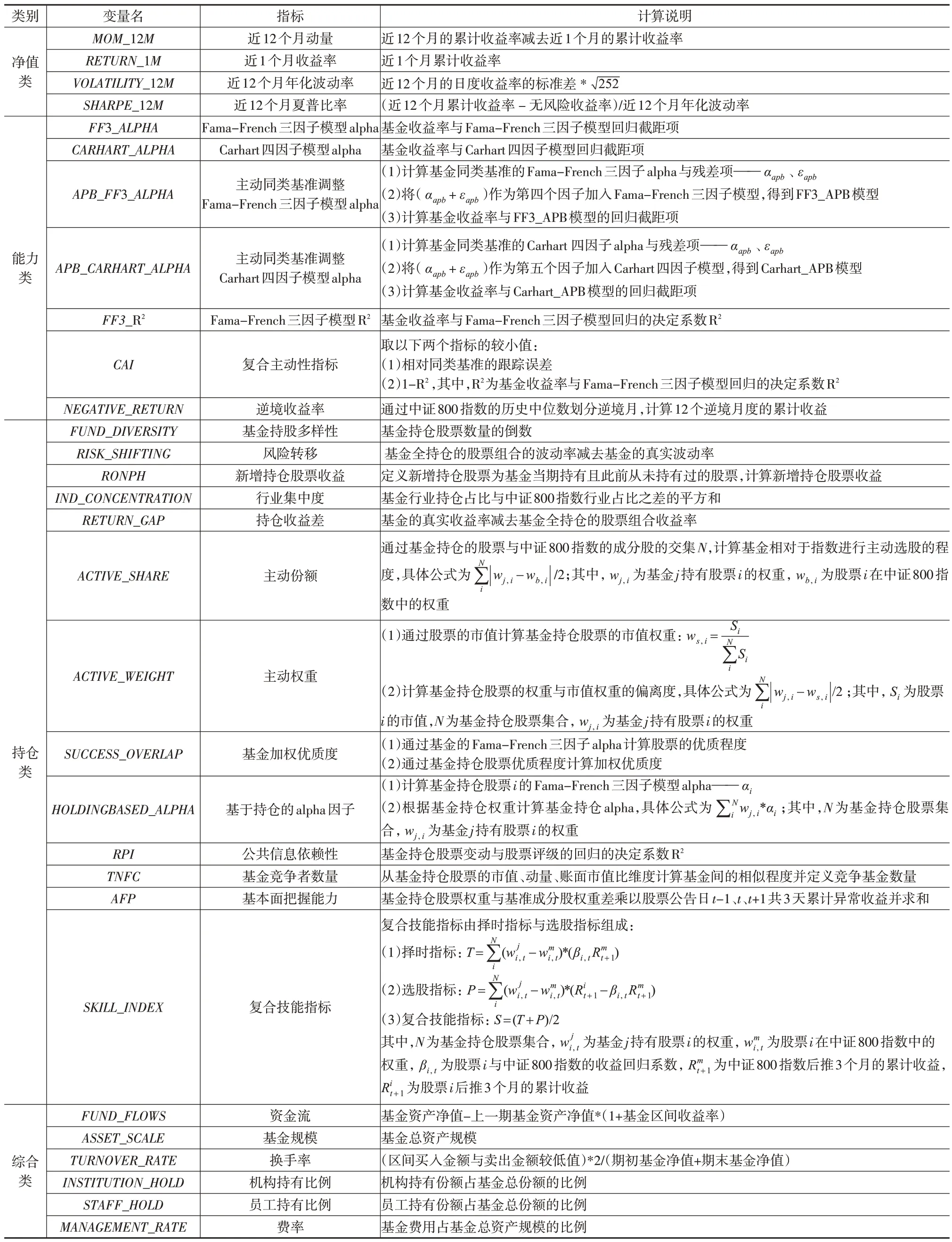
表1 基金因子汇总
2 实证分析
2.1 投资组合排序分析
本文检验了机器学习模型在中国公募基金市场的实证绩效。后文表2 展示了LightGBM 模型在滑动窗口划分的测试样本中的十组基金组合的平均月度收益率、经过Fama-French 风险因子调整后的收益率以及经过Newey-West 方法调整的t 值。整体而言,LightGBM 模型所构建的多空组合以及多头组合均可获得显著的正收益,并且在月度收益率、风险调整后的收益率与显著性上皆优于OLS模型。
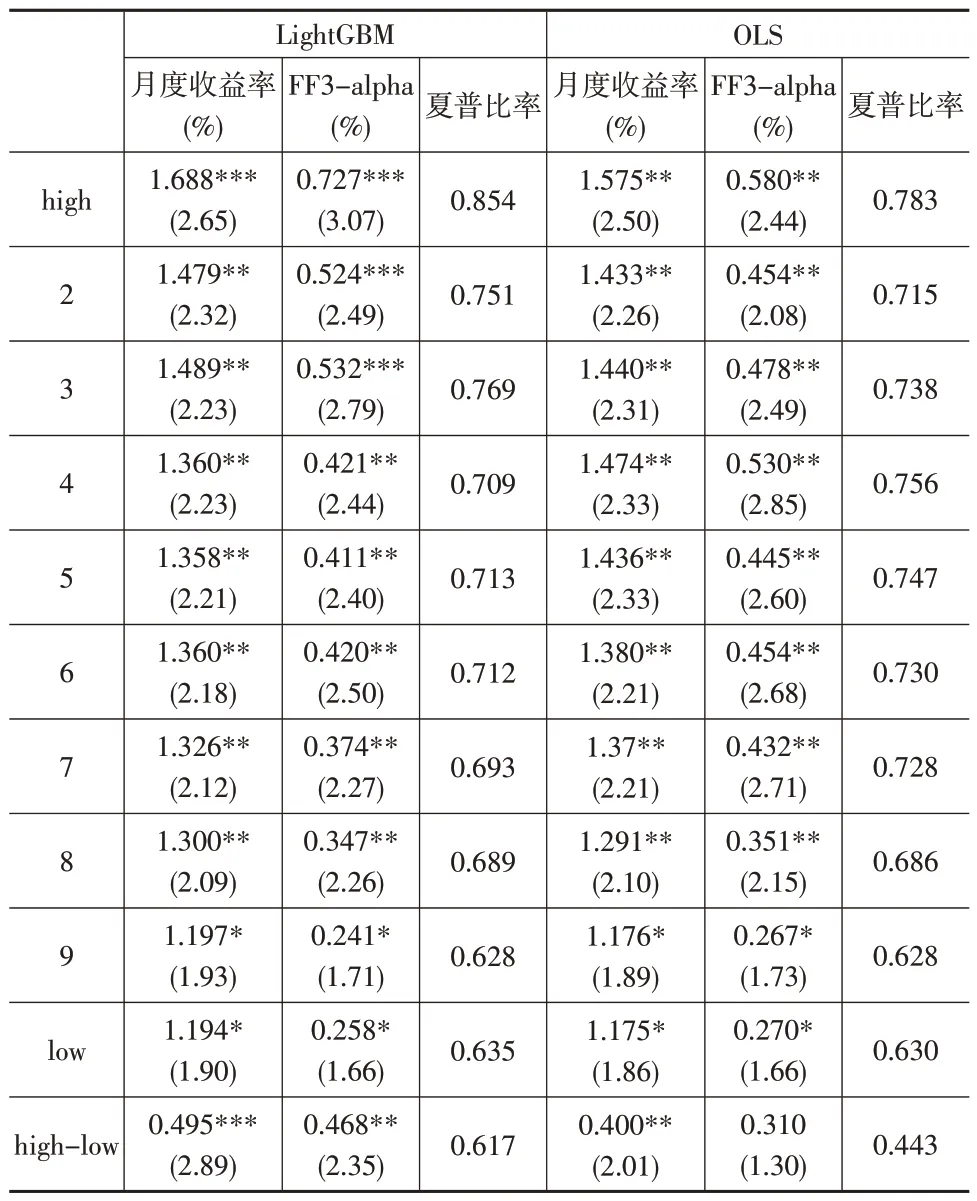
表2 基金投资组合表现
观察表2多空组合表现,LightGBM模型的月度收益率为0.495%(NW-t=2.89),年化收益率为5.94%;OLS 模型的月度收益率为0.400%(NW-t=2.01),年化收益率为4.8%,前者相较后者的提升幅度为23.8%。通过比较风险调整后的收益情况来看,LightGBM 模型的alpha 同样优于OLS模型。LightGBM模型的alpha 为0.727%(NW-t=3.07),OLS 模型的alpha 为0.580%(NW-t=2.44),前者相较后者的提升幅度为25.3%。
鉴于基金市场无法做空,多空组合仅能反映模型是否具备较强的预测能力,而多头组合相对更具备投资指导意义。观察表2多头组合表现,LightGBM模型的月度收益率为1.688%(NW-t=2.65),年化收益率为20.256%,风险调整后收益率为0.727%;OLS 模型的月度收益率为1.575%(NW-t=2.50),年化收益率为18.9%,风险调整后收益率为0.580%。前者相较后者在收益上提升幅度为7.17%,风险调整后收益提升幅度为25.3%。此外,LightGBM模型的收益率与alpha 均在1%的水平上显著,而OLS 模型仅在5%的水平上显著。
2.2 Fama-Macbeth回归检验
接下来,本文通过Fama-Macbeth 回归方法进行检验。将机器学习模型在各个滑动窗口验证集的预测结果作为解释变量,将下一期的基金收益作为被解释变量,参考冯旭南和李心愉(2013)[20]、罗荣华和田正磊(2020)[15]以及Doshi 等(2015)[9]的研究,选取了基金年限Age、基金规模Size、资金流Flow、换手率Turnover、近12 个月累计收益率Return、收益波动率Volatility、主动权重Active Weight、交易差Return Gap作为控制变量,具体表达式如下:
其中,Returni,t为基金i 在t 期的收益率,为模型在t-1期对基金i的预测收益率,Xj,t-1为控制变量j在t期的数值。
后文表3 展示了基于不同控制变量的Fama-Macbeth回归的检验结果。LightGBM模型的预测值对基金未来收益的解释性并未因受到三组控制变量的影响而减弱。观察LightGBM 预测收益在三组控制变量下的回归系数,其NW-t 值分别为3.36、3.37 以及3.35,均显著。作为对比,OLS 模型的预测值在显著性上要明显弱于LightGBM 模型,其回归系数的NW-t值在三组控制变量组合中分别为1.76、1.76 以及1.78,仅在10%的水平上显著。由此可见,机器学习模型的预测效果并没有受到基金年限、基金规模以及基金资金流等控制变量的影响,在统计学意义上仍然具备显著的预测能力。
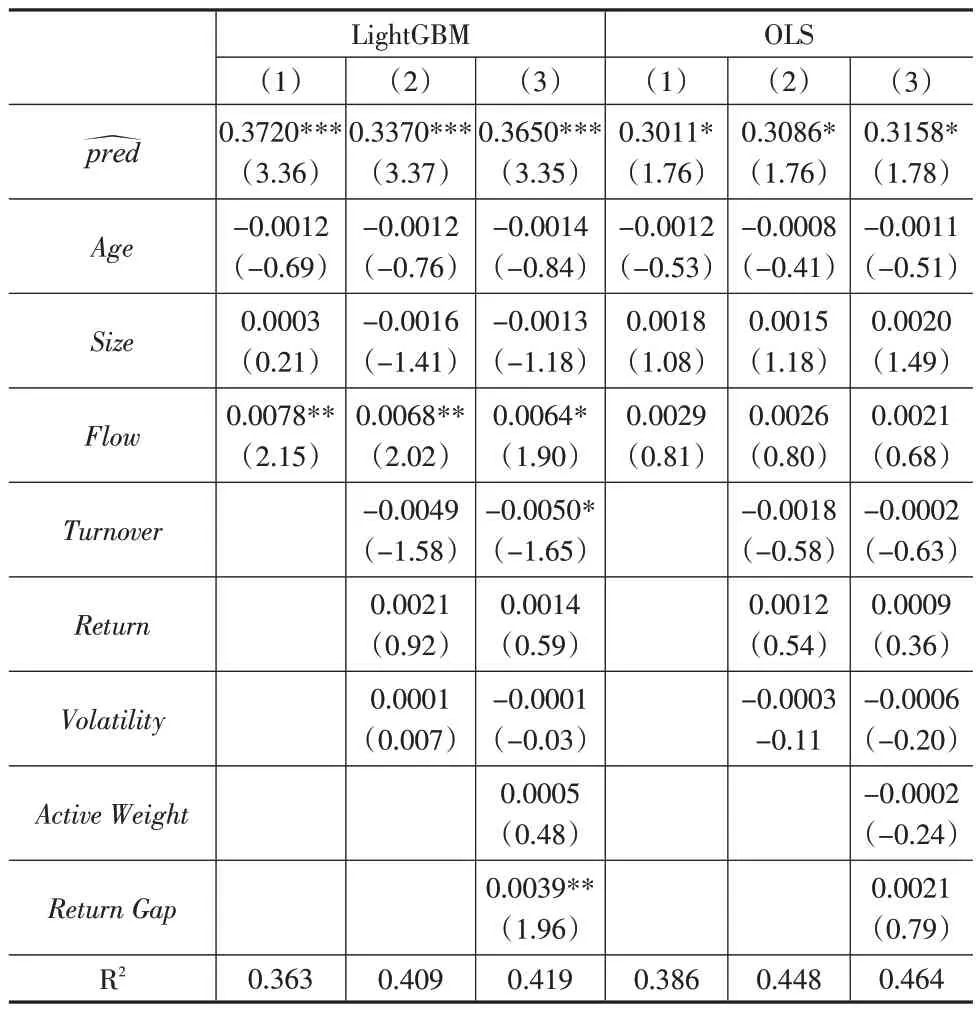
表3 Fama-Macbeth回归检验
2.3 稳健性检验
为了验证机器学习模型是否能够获取稳定的超额收益并且优于传统线性回归模型,本文还进行了一系列稳健性检验。本文选取另一种机器学习方法——随机森林算法(Random Forest,RF)作为稳健性检验的模型。随机森林属于Bagging算法的一种,它的基本单元是决策树,通过集成学习的思想将多棵树的结果进行集成从而得到最终结果。Leippold等(2021)[21]、Gu等(2020)[22]发现,随机森林模型可以有效捕捉股票特征与未来收益之间的非线性关系,从而获得具有较强预测能力的模型。
观察表4 可以发现,通过随机森林模型所构建的多头与多空基金组合同样可获得显著为正的月度收益率。具体来看,随机森林模型多空组合的月度收益率为0.421%(NW-t=2.20),年化收益率为5.05%,相较于OLS模型的提升幅度为5.2%;其多头组合的月度收益率为1.641%(NW-t=2.62),证明了机器学习模型预测基金收益的稳健性。
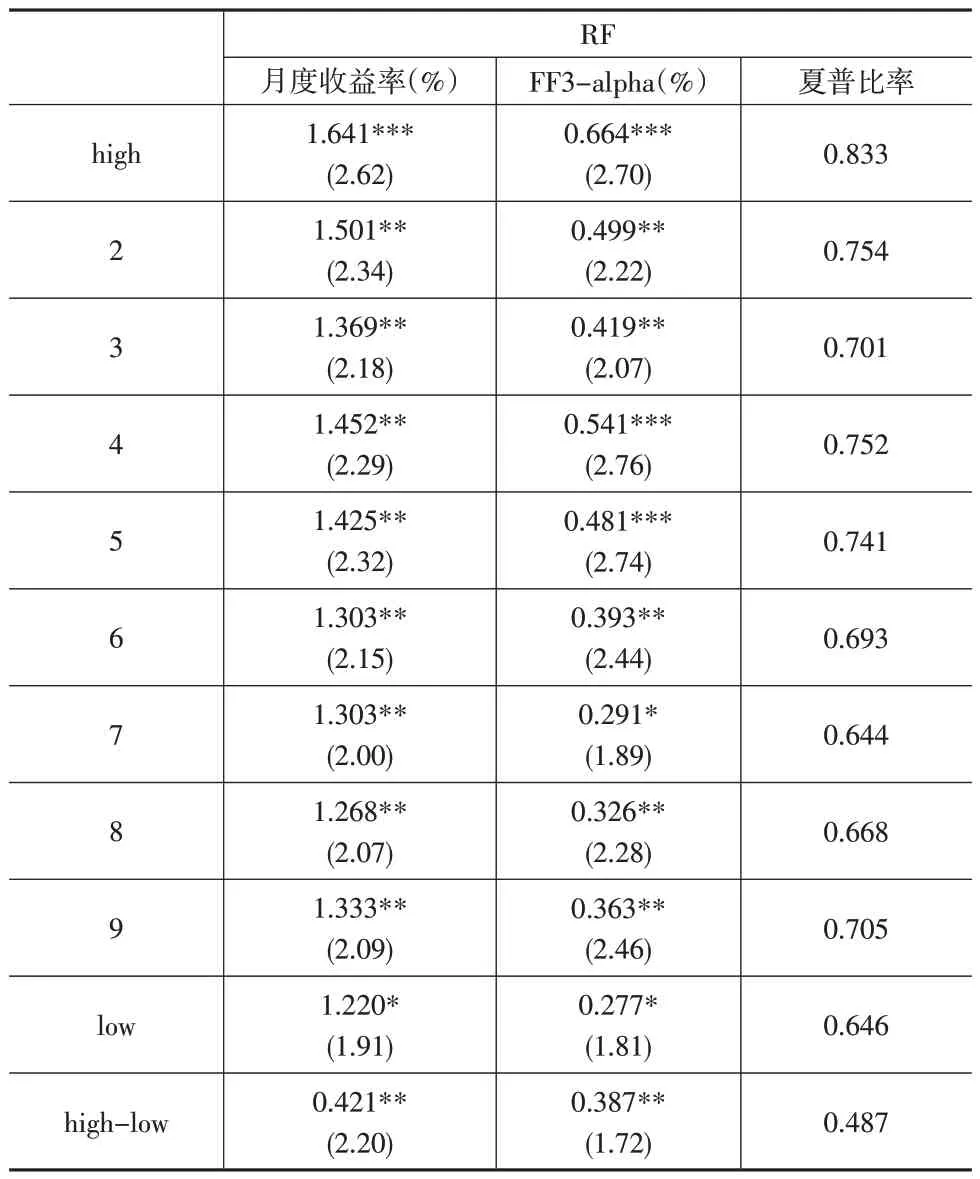
表4 随机森林组合表现
此外,由于基金存在规模报酬递减的情况,规模较大的基金相对规模较小的基金更难获得超额收益。因此本文还检验了LightGBM 模型根据基金规模加权所构建的基金组合在收益与统计显著性方面的表现。如下页表5所示,相对等权构建组合,LightGBM 与OLS 模型根据基金规模加权构建组合的收益表现均有所下降,但LightGBM模型在多头组合与多空组合的业绩表现仍然优于OLS模型。
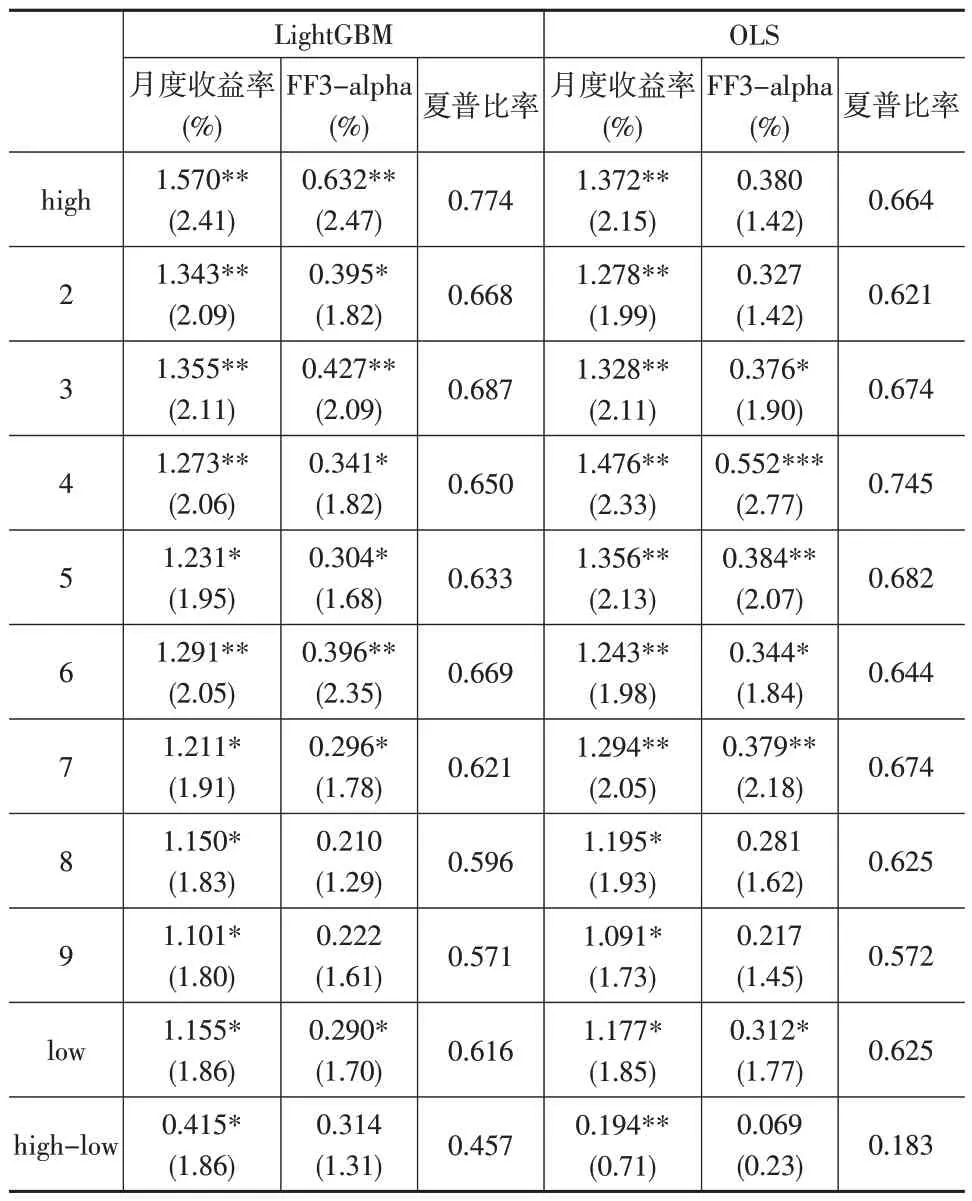
表5 规模加权基金投资组合
具体来看,LightGBM 模型与OLS 模型的多空组合平均月度收益率分别为0.415%(NW-t=1.86)与0.194%(NW-t=0.71),前者相较后者的提升幅度为113.9%;Light-GBM 模型与OLS 模型的多头组合月度收益率分别为1.570%(NW-t=2.41)与1.372%(NW-t=2.15),前者相较后者的提升幅度为14.4%。由此可见,通过机器学习模型构建的基金投资组合受到规模报酬递减效应的影响要远小于OLS模型,并且具备更加稳定的统计显著性。
本文的研究区间覆盖了受新冠肺炎疫情影响较为严重的2020—2021 年,为了排除特殊事件可能对研究结论带来的影响,本文采用2005—2019 年作为回测区间进行机器学习模型预测基金收益效果的检验。由于篇幅限制,本文未展示上述区间的排序分组检验与Fama-Macbeth回归检验结果,但检验结果均支持本文的主要结论。
3 结论与启示
本文选取2005—2021 年中国公募基金数据,通过30个基金异象因子证明了机器学习算法对中国公募基金的收益预测能力,完善了国内基金资产定价研究。本文采用LightGBM算法作为非线性机器学习模型的代表构建了基金收益预测模型,检验了机器学习模型在预测基金未来收益方面的能力。从实证结果来看,LightGBM 模型所构建的多头组合具有20.256%的年化收益率,并且在风险调整后收益率以及夏普比率上要明显优于传统的线性模型。本文通过构建规模加权的基金组合,检验了LightGBM 模型面对不同规模的基金所构建的组合的收益情况。通过实证检验发现,LightGBM 模型在构建基金规模加权的多头组合时受到的负面影响要远小于线性模型,并且能够保证稳定的统计显著性。在基于OLS 模型所构建的Fama-Macbeth回归检验中,LightGBM模型预测值的β为正,且在1%的水平上显著。
综上所述,机器学习在基金市场的收益预测方面具备显著的优势,能够充分挖掘基金持仓股票维度以及基金自身维度的异象因子与基金收益间的非线性关系。与传统线性模型相比,机器学习模型具有更好的预测精度和更有利的投资组合效果。此外,本文还证明了在根据规模加权构建基金组合时,机器学习模型相对于传统线性模型的提升更加显著。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
今日农业(2020年20期)2020-12-15 15:53:19
电影(2018年8期)2018-09-21 08:00:06
金色年华(2016年1期)2016-02-28 01:38:19
IT时代周刊(2015年8期)2015-11-11 05:50:38
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
土木建筑工程信息技术(2013年4期)2013-10-17 02:27:50
