
基于深度学习的黑眼圈检测研究
2023-07-10 15:24:13张青青施浩
计算机应用文摘·触控 2023年11期
张青青 施浩

关键词:黑眼圈;识别;数据集;DETR
中图法分类号:TP391 文献标识码:A
1引言
黑眼圈是一个复杂的眼部美容问题,用来描述眼睛的黑暗状态,大多数人认为睡眠不足为引起黑眼圈的主要原因,但睡眠质量并不是引起黑眼圈的重要因素。我们看出一个人具有黑眼圈很简单,但若要知道属于哪类,人眼来看还是较为困难。此时,需要借助医学上的专业仪器进行黑眼圈种类识别。在医学界还没有能够精确识别黑眼圈种类的灵敏机器,本文提出了一种基于深度学习的黑眼圈识别模型,能够达到较好识别目标的目的。
2黑眼圈的分类
造成黑眼圈的原因有很多。根据其病因,可将黑眼圈类型大致分为3种类型,即色素型、血管型和结构型。同时具备上述3种黑眼圈类型的被称为混合型黑眼圈。
2.1色素型黑眼圈
这是黑眼圈中比较常见的一种类型。在组织学上,引起这类黑眼圈的原因是黑素细胞增多引起黑色素在真皮过多积压,导致色素型黑眼圈。也可能是因为过敏性色素沉积引起的炎症,导致皮肤炎或者水肿。很多环境因素也会导致色素型黑眼圈,其中包括日照、摄入药物、怀孕、哺乳、眼科手术和创伤等。还有各种原因引起的水肿会增加皮肤层的厚度,从而增加色素的漫反射率,也将导致眼睛的下眼睑颜色加深,形成我们不喜欢的黑眼圈。因为水肿程度的改变,导致眼下黑眼圈灰度的改变。
2.2血管型黑眼圈
这是受熬夜影响的一种类型,这种血管型可以影响整个下眼睑区域。它的特点是眼睑处的皮肤薄而透明,皮下的脂肪很少甚至根本没有,与黑眼圈有关的组织和血管透过下眼睑的皮肤呈现出一种灰暗的外观,在医学上表现为青紫色,蓝色血管明显,尤其是下眼睑内侧。对于女生来说,在月经期间这种颜色可能加重,使得黑眼圈表现明显。
这类黑眼圈的下眼睑皮肤被人为拉伸时,随之这片皮肤的区域也会被拉伸,通常我们会认为皮肤拉伸之后皮肤颜色会变浅。但是,这种黑眼圈皮肤被拉伸之后,不仅皮肤颜色没有变浅,而且会导致黑眼圈颜色加重。产生这种现象的最直接原因是下眼睑皮肤在被拉伸之后,皮肤内部的血管会显现出来,使得我们看到的颜色会更深,这种方法可以用来诊断血管是否增多的症状。
2.3结构型黑眼圈
结构型也称阴影型黑眼圈,这种症状的黑眼圈可能是先天产生的,也可能是由于后天的种种原因形成的,两者导致结构型黑眼圈的原因有所不同。泪槽形成的阴影是属于先天性的,后天性产生的原因一般是上下睑肌肉的下垂、眼眶脂肪突出和水肿所产生的阴影。二者产生这种黑眼圈的机理虽然不同,但是造成的结果是一样的。
3基于DETR模型的黑眼圈识别
DETR是FAIR提出的目标检测方法,没有NMS后处理步骤,也没有锚。2018年,Taehoon等[3]首次将Transformer应用于图像生成。2020年,Carion等将CNN与Transformer结合,提出了一个基于端到端的目标检测框架DETR.也是第一次將Transformer应用到目标检测中。朱永宁等提出的基于Faster R-CNN的果实成熟识别技术,用于本次实验做对比,其效果与Faster RCNN在coco数据集上的效果相当,并且DETR可以很容易地迁移其他任务,如全景分割。DETR的基本思想是将检测作为一个集合预测问题来处理,并使用Transformer来预测集合,DETR过程大大简化,可归纳为:“Backbone→Transformer→detect header”。
在现在生活中会发现越来越多的人关注自己的黑眼圈,很多人会买各种护肤品和化妆品试图消除或者遮盖自己的黑眼圈,以达到被人看不出的效果,但这些办法都不能让黑眼圈消失。若要让它彻底消失,则最好选择去医院进行医学治疗,不同的类型有不同的治疗方法,因为难以判断其类型导致很多人不知道如何治疗。深度学习领域也没有关于黑眼圈识别的研究,这无疑对本文的研究非常不利。由于缺乏足够的黑眼圈数据集,只能自行收集一些零散的黑眼圈图片,用黑眼圈的范围来标记这些图片,然后生成相应的文件,再用代码将上述文件转换成可以被DETR模型识别的文件。前期的准备工作已经完成。数据增强的具体步骤如下。
通过网络收集当今的原始数据集,由于用作训练的数据集必须有一个明确的分类,因此有必要寻找已经分类的图片。但这类数据集非常有限,为了得到更好的训练效果,选择通过数据增强对现有数据集进行扩展,主要包括图像水平翻转、垂直翻转、图像压缩和图像加噪。然后,用labelme给训练集添加标签,用矩形标签标注检测区域和类型。最后,它被转换成一个json文件,并输入到模型中进行训练。图1、图2分别为原始图像和增强数据集后的效果图。
在训练的过程中,模型通过推断得出固定大小的Ⅳ个预测集,其中Ⅳ被定义为较大于图像中的物体典型数量。在训练的过程中会遇到一些问题,需要根据已有的真值(grounp-truth)来预测目标对象的类别,以及它的位置和大小,通过真值(grounp-truth)进行评分,这是模型训练过程中遇到的最大的难题。在预测目标和ground-truth之间产生最佳的二分匹配,然后优化特定于物体(bounding box)的损失。
3.1 DETR架构
整个DETR架构如图3所示。它包含以下3个主要组件:提取紧凑特征表示的CNN主干(CNNbackbone)、编码器(encorder)-解码器(decoder)和进行最终检测预测的前馈网络(FFN)。
3.2 Backbone
3.3 Transformer
编码器和解码器都遵循Transformer的标准架构,其中的解码器是使用一个自身的注意力机制将Ⅳ个嵌入转换成大小为d,同时使用了编码器(encorder)-解码器(decoder)注意机制,二者协作进行嵌入转换。因为解码器(decoder)的特殊性质,我们又需要输出不同的结果,嵌入的N个输入要求也不能一样,才能得到最终的实验结果。如果N个输入相同,根据解码器的特点,可能会得到N个相同的结果。N个输入会被添加到每个注意层,作为注意层的输入,经过一系列流程将转变为输出,在这个转换过程中是由解码器(decoder)进行处理的,将这些输入转换成嵌入。接着便是前馈网络FFN(在3.4节中进行描述)将它们分别解码成包含类标签和框坐标,得到最后的目标结果。
3.4 FFN
FFN预测出的目标结果,在预测过程中,它是用一个三层感知器算出来的,在这个感知器中,它包含ReLU激活函数、看不到的维度和线性投影层。
4实验结果
为了获得最佳的识别效果,我们分别使用了Faster R-CNN和DETR模型来训练黑眼圈数据集,在语义特征提取、任务综合特征提取和计算能力以及运行效率等方面,DETR模型相较于Faster R-CNN都表现出较好的识别效果。
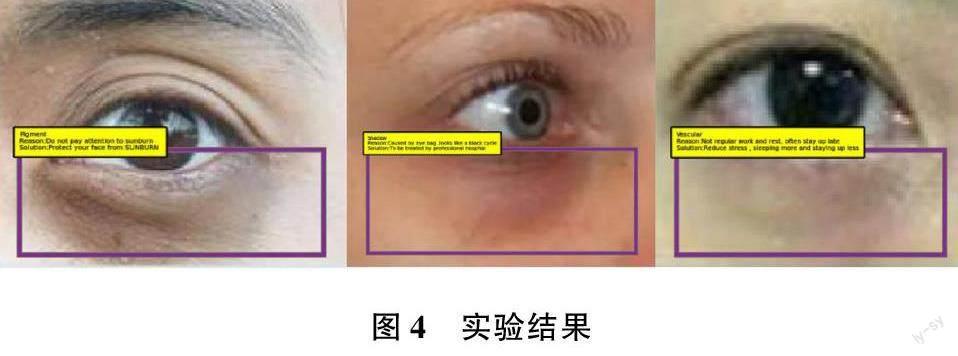
经过比较发现,在目标检测数据集上对比DETR和Faster R-CNN基线方法,发现DETR在大目标上比Faster R-CNN有更好的检测性能,对于小目标检测效果不佳的问题,DETR使用了多尺度可变形注意力机制,从而提高了小目标检测效果。另外,Faster R-CNN无法准确定位图片中黑眼圈的位置,从而无法准确获取黑眼圈的特征进行训练,使得识别率极低。DETR完美地克服了这个缺点,DETR对黑眼圈类型的识别效果会更好,检测效果图如图4所示。
5结束语
使用DETR来检测黑眼圈类型,最终得到实验目标结果,但由于数据集不充分,加上各类黑眼圈区分不明显,甚至用人的眼睛都无法区分属于哪一类型,因此会存在精度不够的问题,在之后的工作中会收集更多的数据,以提高黑眼圈类型的识别速度和判断精度,从而在为解决这一难题做出贡献。
猜你喜欢
艺术启蒙(2022年9期)2022-10-08 01:33:26
红蜻蜓·低年级(2021年2期)2021-07-20 04:48:09
小天使·三年级语数英综合(2018年8期)2018-09-08 11:06:28
Coco薇(2017年3期)2017-04-25 03:00:27
东方法学(2016年6期)2016-11-28 08:06:55
中国科技博览(2016年22期)2016-11-01 15:37:02
中国科技博览(2016年18期)2016-10-19 11:32:09
现代园艺(2016年17期)2016-10-17 07:35:19
作文大王·低年级(2016年8期)2016-08-09 00:38:16
企业导报(2016年10期)2016-06-04 13:21:38
