
基于自适应聚类过采样的软件缺陷预测研究*
2023-07-03 00:47贾燕华李英梅
哈尔滨师范大学自然科学学报 2023年2期
贾燕华,李英梅
(哈尔滨师范大学)
0 引言
在软件的开发研究过程中,由于需求分析不清晰、接口参数传递不匹配等因素的影响,会使得软件不可避免地产生各种缺陷.它的存在会降低软件使用过程中的可维护性,而且缺陷数量会随着软件规模和复杂度的增加而随之增加.软件缺陷预测技术通过对已有程序模块的可度量特征及出现规律的认知,挖掘软件历史仓库构建缺陷数据集并预处理,构建缺陷预测模型预测待检程序模块的缺陷分布[1-2].及早地预测缺陷可以帮助软件测试人员有的放矢地进行软件测试,提高软件质量的可靠性.
当某些类的样本数量明显大于其他类样本数量时,就会引发数据集类不平衡问题.类不平衡问题广泛存在于各种实际工作领域中,如医学诊断[3]、网络入侵检测[4]、信贷欺诈[5]等.由于缺陷预测数据集中无缺陷样本(即多数类)比有缺陷样本(即少数类)要多得多,且80%的缺陷集中分布于20%的程序模块内,这说明在软件缺陷预测领域中也普遍存在类不平衡问题.传统的分类方法通常为确保得到较高的整体分类性能会倾向于多数类样本,导致分类器性能产生偏差,少数类样本被错误分类[6].同样地,使用传统分类方法构建的软件缺陷预测模型,其结果将趋向于无缺陷数据,从而影响软件正常运行,致使软件产生故障甚至失效,带来巨大的经济损失.该文所提出的LDKMAS 算法是在数据级层面对不平衡数据进行过采样处理,该算法使模型的最终预测结果不再偏向于无缺陷数据,经过实验验证该法较之流行、经典的过采样方法效果更优异.
1 相关研究
1.1 软件缺陷预测研究
根据软件缺陷倾向性分类结果,可以将其当作一个二分类问题,其结果为有缺陷倾向性和无缺陷模块倾向性两类.典型的软件缺陷预测模型构造和预测过程如图1所示.
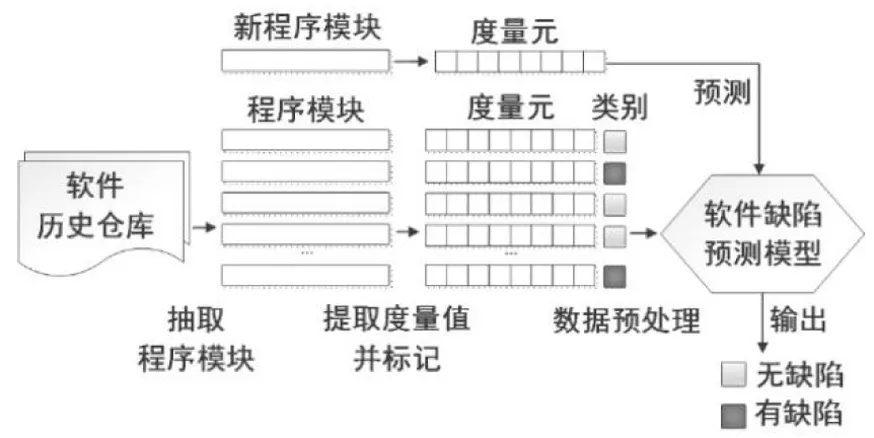
图1 软件缺陷预测过程
该过程主要包括4个阶段:
(1)构建缺陷预测数据集.从软件历史仓库抽取程序模块,根据提取程序模块的度量元和缺陷类别,构建软件缺陷预测数据集.
(2)数据预处理.由于构建的数据集质量欠佳,需采用有效方法预处理数据,目前主要采用特征工程、数据采样等方法.
(3)建立预测模型.经过必要的数据预处理后,借助特定的建模方法构建缺陷预测模型,并使用数据集对预测模型进行训练.
(4)预测新程序模块.基于度量元取值和缺陷预测模型判断被测项目内新程序模块的缺陷类别(有缺陷或者无缺陷).
软件缺陷预测的研究内容主要包括设计与缺陷强相关的度量元、研究数据集的预处理技术和改进软件缺陷预测模型.该文将关注由缺陷类样本和无缺陷类样本之间的不平衡分布引起的数据集质量问题.
1.2 不平衡数据过采样研究
目前解决不平衡数据的方法主要分为两类:数据级方法、算法级方法.算法级方法侧重于引入成本敏感因素[7]、集成学习[8]等,使分类器偏向于少数类.数据级方法通过一些重采样技术来寻求类别的平衡分布.与算法级方法相比,数据级方法能真实反映研究对象的性质,因其独立于分类器的灵活性和实现的简易性显示出无限潜力[9].
过采样技术是通过复制现有少数样本或生成新的少数样本来平衡不平衡数据.随机过采样是最简单的平衡数据集过采样方法,即通过随机复制少数样本合成新样本,但因重复样本过多容易过拟合.Chawla等人提出合成少数类过采样技术SMOTE,该方法是通过对随机选择的少数类样本及其k 近邻样本进行线性插值而生成新样本,而不是仅复制现有样本[10].但是,SMOTE 将所有少数类样本视为同等重要,忽略了样本的分布信息而导致采样具有盲目性[11].为了消除其缺点,许多学者采用安全区域采样或边界区域采样的策略来选择样本进行合成.
边界区域采样:根据支持向量机(SVM)的原理,样本越靠近决策边界区域其包含的重要信息就越多[12],因此许多研究者强调对边界区域样本采样并提出相应算法.Borderline Smote[13]和ADASYN[14]是边界区域采样中较为常用的两种方法,但因其强调边界区域则不可避免的会容易产生大量噪声,降低数据集质量.
安全区域采样:避免引入新的重叠或噪声样本,分布较为密集的样本被采样的几率更大.Bunkhumpornpat等人根据少数类样本K 近邻样本中同类样本占比识别安全样本,提出了Safe-Level SMOTE,以此生成较为安全的新样本[15].Douzas等人提出了K-Means SMOTE 算法,该算法应用K-Means 算法对整体数据进行聚类,依据簇中异类样本数占比选择安全子簇进行过采样来减少噪声的影响[16].
为避免产生噪声和离群点,该文采取安全区域采样策略使得平衡后数据集分布更集中.首先为缺陷数据聚类,然后根据聚类后各子簇密度自适应确定各子簇采样量.较于小子簇和稀疏簇,大子簇、密集簇中的样本更可能处于安全区域,因此越大越密集的子簇所获采样量越多.
2 算法介绍
LDKMAS算法包含三个步骤:K-Means++聚类、[17]、局部密度计算以及自适应采样.首先利用K-Means++聚类将缺陷数据划分成k个子簇;然后计算各子簇中样本的局部密度,合计为子簇密度;最后根据子簇密度识别子簇重要性自适应插值过采样.LDKMAS算法框架如图2所示.

图2 LDKMAS算法框架
2.1 K-Means++聚类
为避免K-Means算法随机选取初始聚类中心点导致聚类结果有所差异,K-Means++算法对此进行了优化调整.该算法要求初始的k个聚类中心之间的相互距离要尽可能的远,即逐个选取k个聚类中心,离已选聚类中心越远的样本点越有可能被选为下一个聚类中心.


2.2 局部密度
该文局部密度结合样本分布特点计算,可估算当前样本的潜在价值,提高样本合成质量.样本i的局部密度计算方式如下:
其中KNN(i)为样本i的Kn个近邻样本构成的集合,dij为样本i,j间的欧式距离.由式(1)可知,样本点i到其Kn近邻的距离越小,其密度值ρi越大.该文采用样本i的Kn近邻信息定义样本i的局部密度ρi更能反映数据集样本的真实分布信息.
假设缺陷数据类被分为k个子簇Cminj,j =1,2,…,k,每个子簇Cminj的密度SDminj定义如下:
其中,|Cminj|表示的是子簇Cminj的大小,ρi表示属于子簇Cminj各样本的局部密度.由式(2)可知,子簇密度数值与该子簇所包含样本的数量和局部密度成正相关.
2.3 自适应过采样
对缺陷类样本进行聚类和局部密度计算后,首先根据子簇密度值自适应计算每个子簇的采样量OSminj,其定义如下:
其中N是总过采样量,即无缺陷样本与缺陷样本的数量差,则子簇越大、越密集,其采样量越大.确定每个子簇采样量后,在子簇样本与其Kn近邻之间执行线性插值,直至达到该子簇采样量.插值公式如下:
其中a表示(0,1)之间的随机数,xij表示第i个子簇中的第j个样本,Knij表示样本xij的随机某个Kn近邻样本.


3 实验
为验证该文所提算法的有效性,该文实验将在AEEEM 数据集上使用不做处理的原始数据和六种经典的过采样算法作为实验对比组,以决策树为分类器进行10 次十折分层交叉验证,取平均值作为最终实验结果.
3.1 数据集
AEEEM数据集是由D’Ambros等人共同收集整理的开源数据集[18],包含61 个特征值,在软件缺陷预测领域具有真实可靠性,其基本信息见表1.
其中,设非缺陷数为N,缺陷数为Q,不平衡率(Imbalance Ratio,IR)为无缺陷模块数与有缺陷模块数的比值,计算如下:
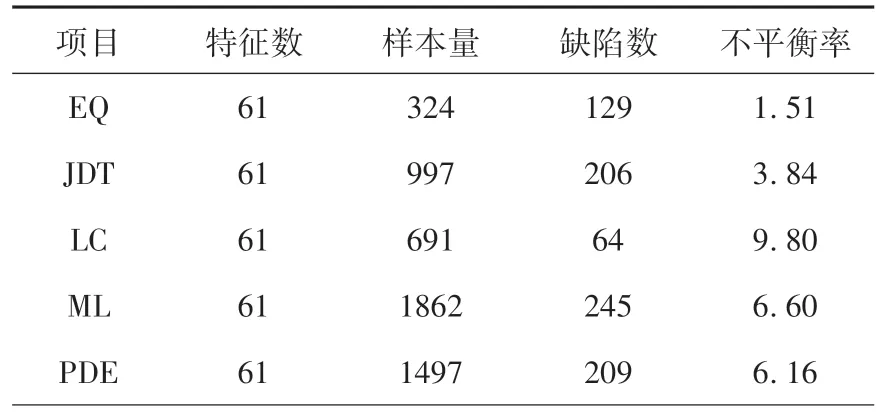
项目 特征数 样本量 缺陷数 不平衡率EQ 61 324 129 1.51 JDT 61 997 206 3.84 LC 61 691 64 9.80 ML 61 1862 245 6.60 PDE 61 1497 209 6.16
3.2 评价指标
对于不平衡数据,少数类的正确分类尤为重要,基于单一准确率的传统评估方法不再适用.因此,为了定量评估不平衡数据过采样后的分类性能,该文使用F1值和AUC值作为性能度量,比较不同的方法.这些性能指标通常取决于混淆矩阵,见表2.

预测值有缺陷模块 无缺陷模块真实值有缺陷模块 TP FN无缺陷模块 FP TN
(1)查准率:预测为有缺陷样本中真实类别为有缺陷所占的比例.
(2)召回率:预测为有缺陷样本的数量占真实有缺陷样本的比例.
(3)F1-score:Precision和Recall的加权和平均值.
(4)AUC:ROC 曲线下的面积.ROC 曲线是接受者工作特征曲线,其横坐标为假阳率,纵坐标为真阳率.
其中,TPrate为真阳率,其值等于召回率;FPrate为假阳率
3.3 实验结果
将多个经典的类不平衡过采样算法与LDKMAS算法进行比较,在AEEEM数据集上的原始数据和各个方法的实验结果见表3、表4 所示.其中OD、ROS、SMO、ADA、BLS、SLS、KMS、LKS分别为原始数据、随机过采样、SMOTE 过采样、ADASYN 过采样、Borderline Smote 过采样、Safe Level Smote过采样、K-Means Smote 过采样、LDKMAS过采样的简称.上述6 种对比过采样算法通过python 中的imblearn 工具包和Github中的somte-variants工具包调用,决策树分类器通过python中的sklearn工具包调用.
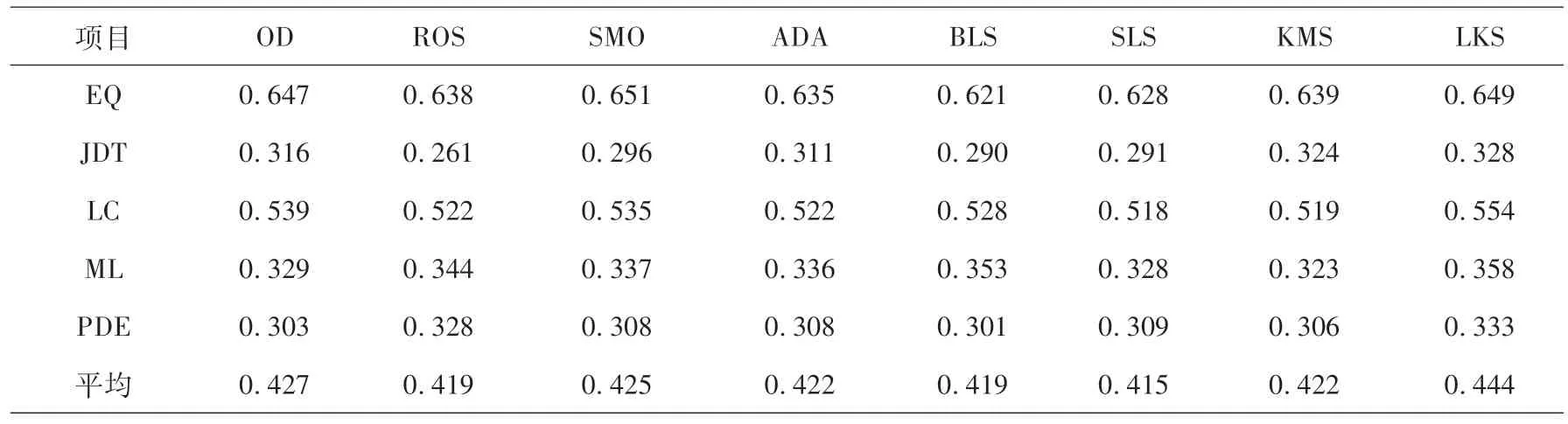
项目 OD ROS SMO ADA BLS SLS KMS LKS EQ 0.647 0.638 0.651 0.635 0.621 0.628 0.639 0.649 JDT 0.316 0.261 0.296 0.311 0.290 0.291 0.324 0.328 LC 0.539 0.522 0.535 0.522 0.528 0.518 0.519 0.554 ML 0.329 0.344 0.337 0.336 0.353 0.328 0.323 0.358 PDE 0.303 0.328 0.308 0.308 0.301 0.309 0.306 0.333平均 0.427 0.419 0.425 0.422 0.419 0.415 0.422 0.444
由表3和表4可看出,对数据集进行过采样预处理确实能够提升预测模型分类效果.进一步而言,不平衡率较低的数据集中SMOTE 过采样算法效果虽略胜于该文算法,但是LDKMAS 过采样在绝大多数的情况下表现更优.LDKMAS过采样较于不做处理的原始数据和其他6 种过采样算法平均提升了2%,且F1和AUC均值最高.上述结果证明了LDKMAS过采样在数据不平衡缺陷预测中的有效性,也说明利用子簇密度自适应判断过采样方法会提高模型的预测效果.
4 总结
为了解决类不平衡问题,该文采取安全区域采样思想,考虑样本分布特点,提出一种子簇密度自适应判断过采样方法.根据各子簇重要性自适应判断确定自身采样量,最大程度地利用样本的潜在价值,使平衡后的数据尽量能还原初始数据分布,有效减少过拟合,缓解类不平衡问题对缺陷预测模型性能的影响.选取了具有真实可靠性的AEEEM 数据集上进行实验,结果表明LDKMAS算法在F1值和AUC值指标上均得到了不同程度地提升,具有更好的缺陷预测性能.
该文只研究了软件缺陷预测中不平衡数据过采样方法,下一步将研究能与算法相匹配的提升数据集质量方法,如噪声处理、特征选择、重叠区清理等,结合高效的集成学习算法进一步提高模型的预测效果.
猜你喜欢
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子元器件与信息技术(2017年4期)2017-03-08
电子设计工程(2015年6期)2015-02-27
