
基于改进YOLOv5的火龙果成熟度识别方法
2023-07-03 07:13:48马瑞峻何浣冬赖宇豪
沈阳农业大学学报 2023年2期
马瑞峻,何浣冬,陈 瑜,赖宇豪,焦 锐,唐 昊
(华南农业大学工程学院,广州 510642)
近年来,我国火龙果种植面积快速增长,达到约6 万hm2。随着种植规模的扩大,实现果园的自动化和智能化管理是生产规模化的重要环节[1-2]。果园智能化管理中成熟度识别可以帮助果园管理者更加准确地掌握果实的生长和成熟情况,优化果实采摘时间,从而提高果园生产效率。在果园管理中坐果偏多的茎条需要进行疏果,从而提升火龙果果实的甜度,对未成熟果实进行套袋处理[3-4],避免果实在生长过程中受到伤害,有利于果实表皮着色更加均匀,成熟后需要对火龙果适时采摘,如果错过最佳采摘时机,可能导致果实内部的营养流失,影响果实的口感。由于火龙果每年结果最高可达14 个批次[5],目前对火龙果生长状态的监测以人工为主,缺乏系统的管理。因此,通过目标检测算法监测提供火龙果不同成熟度的分布信息成为合理安排劳动力适时疏果、套袋和采摘的必要方法。
国内外的果实识别和不同成熟度分类等研究已取得了一定进展。在传统目标检测方法上,邓子青等[6]通过Otsu算法与形态学处理的方法实现对成熟火龙果的识别,KURTULMUS 等[7]通过颜色特征与Gabor滤波处理对未成熟的绿色柑橘进行检测。这些方法大多基于阈值分割[8-9]、颜色空间转换[10-12]和形态学方法[13-14]相结合对果实进行检测,往往过于依赖人工提取的特征,导致在自然的环境下的鲁棒性和泛化性比较差。
近年来,深度学习技术发展迅速,基于深度学习的目标检测算法愈发成熟,在农业应用中自然环境复杂多变,基于深度学习的目标检测算法通过不断训练自动从图像中提取目标的抽象特征,与传统检测算法相比,显著提高了目标检测算法的泛化能力和鲁棒性[15-17]。一般来说,基于深度学习的目标检测算法中可分为两类,一类是生成可能包含目标的区域,再进行分类和回归[18],具有代表性的算法有:R-CNN[19]、Faster R-CNN[20]、Mask R-CNN[21];另一类是基于回归的算法,模型是同时预测目标的坐标和类别,具有代表性的算法有:SSD[22]、YOLO[23]、CornerNet[24]等。
YOLO 是基于回归的算法,自提出以来因网络结构简单和检测速度极快得到广泛地使用,且经过多次迭代后,YOLO 算法的检测精度也得到了很大的改善。2020 年LI 等[25]提出一种改进YOLOv3 网络结构检测识别成熟火龙果,该模型基于轻量化骨干网络的MobileNet 的网络结构,通过堆叠深层可分离卷积块的设计减少了计算量,该方法的F1 值为78.6%,平均耗时4.7 ms,但该方法存在对遮挡果实是否能有效识别的问题。JUNOS等[26]提出使用DenseNet 骨干网络改进YOLOv3 模型,在各种自然条件下准确检测油棕松散果实,结果表明,该模型平均精度为99.76%,平均检测耗时为34.06 ms,比YOLOv3平均检测时间快6 ms且平均精度没有下降。宋怀波等[27]提出了一种利用视觉注意力机制改进YOLOv4 网络的YOLOv4-SENL 模型,该模型的平均精度为98.3%,结果表明SE-NL 注意力模块合适地融入网络结构中,能有效提升了自然环境下苹果幼果的检测精度。ZHENG 等[28]针对果园中的绿色柑橘提出使用加权双向特征金字塔网络,通过融合多层特征的提高目标检测的准确度,结果表明,该模型平均精度为91.55%,比使用特征金字塔网络平均精度高3.39%。TIAN 等[29]使用YOLOv3 模型研究在自然环境下检测对不同成长阶段的苹果,该模型通过添加密集连接网络来增强特征传递能力,从而提高了模型的检测精度。ZHANG 等[30]使用多种优化方法对YOLOv5 模型改进,该研究通过将DenseNet、SE 注意力模块和Bi-FPN 相结合来检测田间未开放的棉铃,该方法在检测精度、计算量、模型大小和速度等方面均优于多种检测模型。WANG 等[31]使用改进的YOLOv5模型检测将SAM 和Bi-FPN 相结合,并提出使用DIoU 作为模型的损失函数,准确检测小目标蘑菇的产量和种类,该模型的平均精度达到99.24%,检测性能明显优于未改进前的YOLOv5模型。
为了能够准确并快速地在果园中检测火龙果的成熟度,本研究在YOLOv5检测模型的基础上进行改进,提出一种轻量化网络PITAYA-YOLOv5。PITAYA-YOLOv5 采用PPLCNet[32]替换YOLOv5 的骨干网络来大幅减少模型的参数量,在骨干网络中融合注意力模块加强对特征的提取,引入加权双向特征金字塔网络结构弥补网络轻量化带来的准确性降低,并引入αDIoU[33]进行对网络损失函数优化。本研究通过对YOLOv5 网络进行改进,并在自然的环境下进行火龙果目标检测试验,对改进后的方法进行准确性与实时性验证。
1 基于YOLOv5模型的改进
1.1 PPLCNet轻量级骨干网络
YOLOv5 目标检测模型采用跨阶段局部网络(cross stage partial darknetwork,CSPDarkNet)和空间金字塔池池化(spatial pyramid pooling,SPP)结构组成的骨干网络进行特征提取[34],与其他轻量级网络相比,CSPDarkNet的参数量较大,需要更多的存储空间和计算资源,为了在基本不影响准确率的前提下,降低该网络的参数量并且提升检测速度,本研究以PPLCNet 为灵感,将骨干网络CSPDarkNet 替换成PPLCNet,然后根据火龙果目标的特点进行优化设计。
PPLCNet 是基于百度开源深度学习框架PaddlePaddle 开发的检测网络,相较于常用的识别检测网络,PPLCNet 的参数量小且更注重不同优化策略的结合,提高准确性和检测速度。本研究将PPLCNet 设计为YOLOv5的骨干网络,其设计思想包括两部分:(1)通过堆叠模块构建了一个类似MobileNet的骨干网络,使用深度可分离卷积(Depthwise separable convolution,DepthSepConv)代替标准卷积提取特征信息,并且这些模块没有特征图相加额外操作,加快了模型的推理速度。而卷积操作中对卷积核的大小比较敏感,且卷积核大小往往影响模型的最终检测能力,所以模型对浅层信息使用3×3的卷积核进行深度可分离卷积特征提取,而对于深层信息,使用5×5的卷积核进行深度可分离卷积特征提取,使用更大的卷积核是为了模型能获取更大的感受野的同时,保证模型的推理速度。图1中为本研究使用的轻量级的深度可分离卷积模块。(2)SE 注意力模块可以使神经网络保留更多的特征信息并确保模型的表达能力,从而提高模型的性能,本研究将其引入PPLCNet骨干网络中,以提高火龙果重要特征的权重。SE 注意力模块包含两个分支(图2),第一个分支进行压缩和激活输入特征图的每个通道。首先对输入特征使用全局平均池化来进行压缩,对每个特征层求平均值,用平均值表示特征层的特征。特征图经过压缩后需要进行激活,各特征图的平均值进行非线性处理,并与另一个残差分支重新加权特征映射。SE 注意力模块通过构建出模型不同通道上的依赖关系从而提升网络的性能。然而盲目增加SE模块会增加推理时间[35],所以本研究将仅引入一个SE注意力模块到骨干网络中。

图1 深度可分离单元结构示意图Figure 1 Schematic diagram of DepthSepConv block
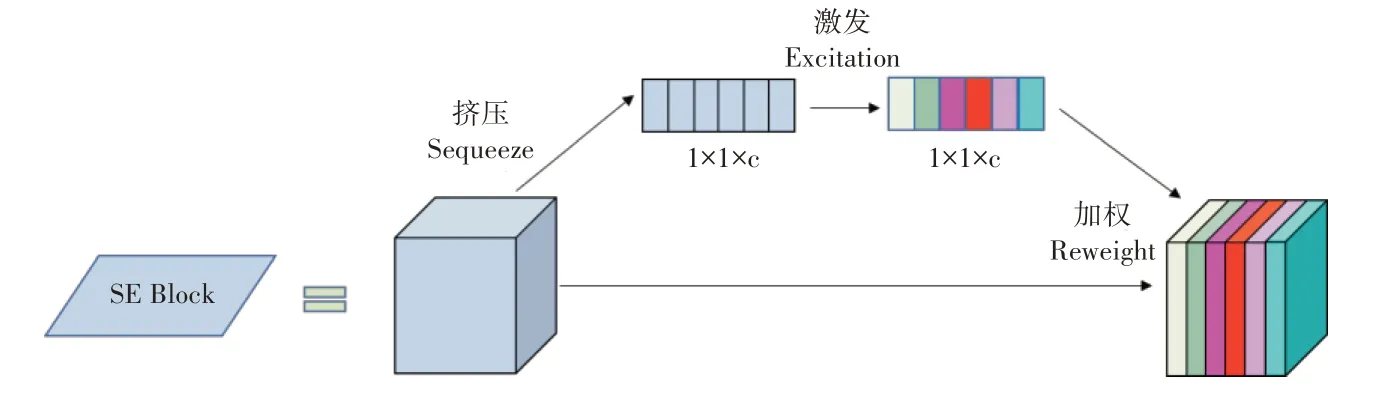
图2 SE注意力模块示意图Figure 2 Schematic diagram of SE block
1.2 k-means++聚类算法与检测层
锚框是一组预定义的边界框,用于在图像中生成候选框,YOLOv5 模型是采用k-means 聚类算法基于COCO数据集真实框的尺寸训练出9个不同尺寸的锚框。
k-means 聚类算法在初始化过程中是将数据集划分成k个互不相交的子集,即簇,然后随机选取了k个点作为聚类的簇中心,最后计算每个簇与簇中心之间的距离,把每个对象分配给距离它最近的蔟中心[36]。由于k-means 算法受初始点选取的影响,这种方法容易导致聚类结果收敛到局部最优解,因此本研究将使用kmeans++算法。k-means++算法是基于k-means算法在初始化过程中改进的聚类算法,通过点之间的距离相似度将数据分为损失最小的k个簇,这种方法能够更好地保证初始簇中心的分布性,避免了随机选择带来的负面影响,从而使得聚类结果更加准确、稳定和快速收敛[37]。
本研究对火龙果数据集进行k-means++算法生成锚框(图3)。当簇中心数量为9 之后重叠率趋于平稳(图3a)。为平衡模型复杂度与高召回率,因此将簇中心数量设定为9,此时的锚框尺寸分别为(19,15)、(42,37)、(82,69)、(89,141)、(158,121)、(173,259)、(253,187)、(215,498)、(372,309)(图3b)。将聚类结果按照大小顺序分配到20×20,40×40,80×80共3个预测尺度,对各个尺度分配3个锚框。

图3 平均重叠率与聚类锚框尺寸Figure 3 Average overlap rate and cluster anchor size
1.3 阿尔法损失函数
为了在复杂的自然环境下获得精准的火龙果果实位置和类别信息,需要优化损失函数,平衡预测框定位、置信度、类别的训练误差,预测框与标定框之间定位损失由IoU(Intersection over Union)损失函数表示。IoU 由检测框与真实框的交集与并集之比构成,IoU和IoU损失函数(LIoU)计算公式为:
式中:Bgt为真实框的面积;B为预测框的面积。
然而,当预测框与真实框不相交时,IoU此时等于0,IoU损失函数不能继续优化,为了提升损失函数的性能,IoU需要增加非重合区域占比的惩罚函数。所以YOLOv5 预测框的回归损失函数默认采用基于IoU的DIoU,DIoU的损失函数LDIoU计算公式为:
式中:b和bgt为B和Bgt的中心点;ρ为欧几里得距离;c为B和Bgt之间的最小外接矩形的对角线距离。
本研究采用由IoU损失函数改进的αIoU作为定位的损失函数。αIoU由DIoU的基础上加入幂参数α,此处α=3。
与DIoU损失函数相比,αDIoU对小数据集和噪声的鲁棒性更强。采用αDIoU度量目标框和预测框的距离与重合程度,协调目标框与预测框之间的距离,重叠率、尺度以及惩罚项,使目标框回归变得更加稳定。
1.4 加权双向特征金字塔
EfficientDet[38]中使用的Bi-FPN 是一种简化的PANet(path aggregation network)结构(图4),相较于PANet 结构,由于特征提取的过程中高维特征层与低维特征层的结点没有进行特征融合,两个结点的提取的特征信息较少,对融合不同特征的特征网络的贡献就会更小,所以Bi-FPN 结构在PANet 结构的基础上移除了这两个结点,并且在中间的特征层加入残差边结构,在不增加太多计算成本的同时,融合了更多的特征信息。

图4 特征融合网络Figure 4 Feature fusion network
Bi-FPN结构针对融合的各个尺度特征增加了权重,通过训练以调节每个特征尺度的贡献权重。Bi-FPN通过快速归一化融合(fast normalized fusion),它比softmax的优化提高了更快的速度,快速归一化融合的公式为:
式中:ω为各特征层可训练的权重;Resize 为上采样或下采样操作后得到特征层相同的维度;Conv 为特征层融合后进行卷积操作。
Bi-FPN 结构最终将输出80×80,40×40,20×20 这3 个尺度的特征层作为预测头部,并通过PITAYA-YOLOv5的解码算法生成最后的检测框。
1.5 改进的YOLOv5目标检测模型
在当前的目标检测领域,虽然最先进的目标检测算法能够在高性能硬件设备上实现对火龙果的准确检测,但在一般嵌入式平台上无法实现实时检测。本研究中将基于YOLOv5模型对火龙果检测任务进一步优化,设计了一种平衡检测精度和速度的轻量级目标检测网络。网络结构如图5,网络结构由骨干网络、颈部网络和预测头部组成,首先,骨干网络中对输入特征图进行特征提取,其中由PPLCNet 将替换CSPDarkNet,其核心采用深度可分离卷积、批正则化和h-swish 激活函数提取特征,并在其基础上使用多个5×5 卷积核替换3×3 卷积核,在卷积过程中令特征图获得更大的感受野,不同于标准的卷积方法,该单元在保持较高的检测精度的同时,减少了计算量和网络参数,提高了模型的检测速度,在骨干网络最后一层深度可分离卷积层中引入SE注意力模块,通过对不同通道之间分配的权重,加强骨干网络对特征的提取能力和融合视觉特征的信息,增强了模型对受遮挡火龙果的关注度。其次,骨干网络卷积运算后的特征映射输入到颈部网络,网络的核心是Bi-FPN模块,Bi-FPN作为颈部网络用于更高效的多尺度特征融合,它弥补了骨干网络卷积过程中的特征损失,进一步增强了模型对火龙果轮廓、颜色和纹理信息的提取。最后在预测头部输出3 种不同尺度(24×80×80)、(24×40×40)和(24×20×20)的特征层进行检测,提高了网络检测长距离、小体积的火龙果的检测性能。
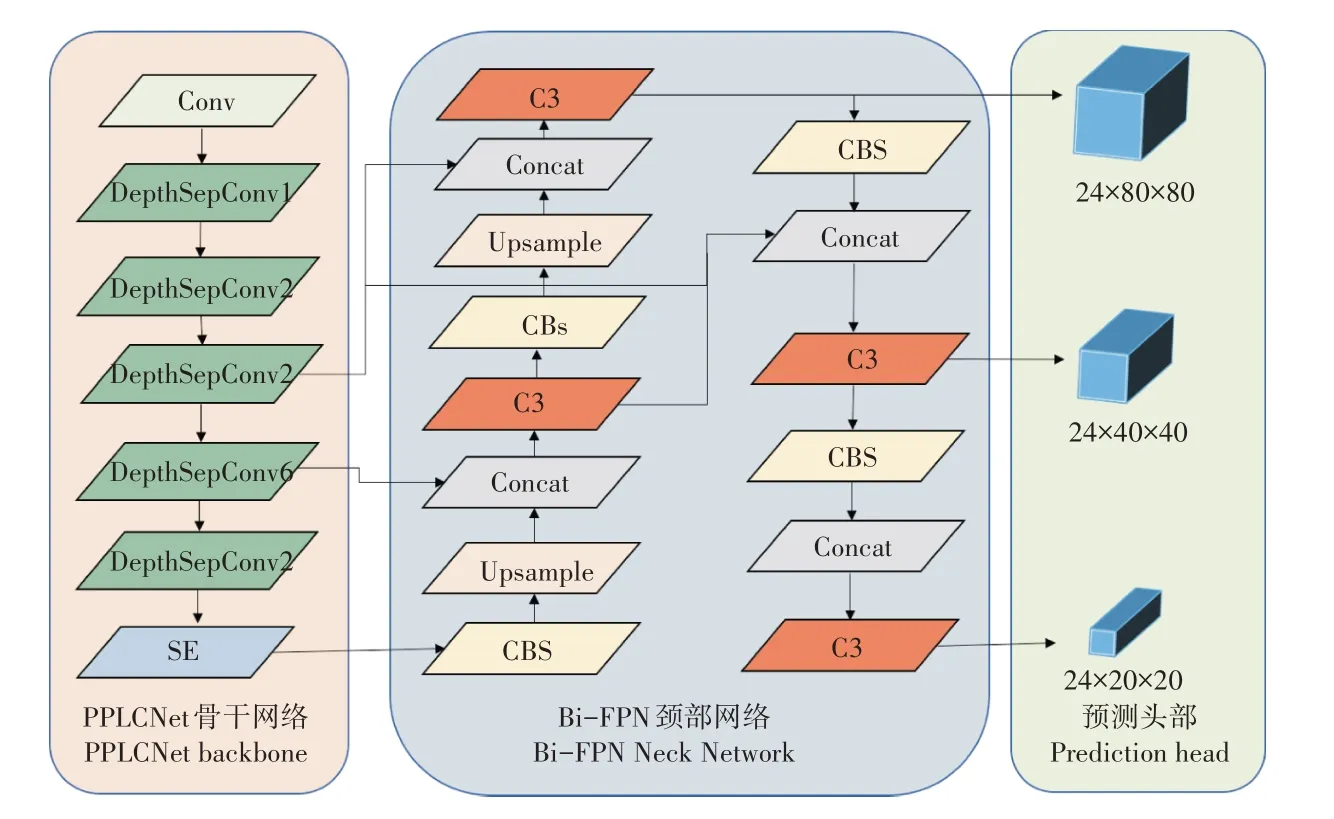
图5 PITAYA-YOLOv5结构示意图Figure 5 Schematic diagram of PITAYA-YOLOv5 structure
最后,本研究改进后的骨干网络细节如表1。在表1中,Convolution 表示标准卷积,DepthSepConv 表示深度可分离卷积,SE表示是否使用了注意力模块。
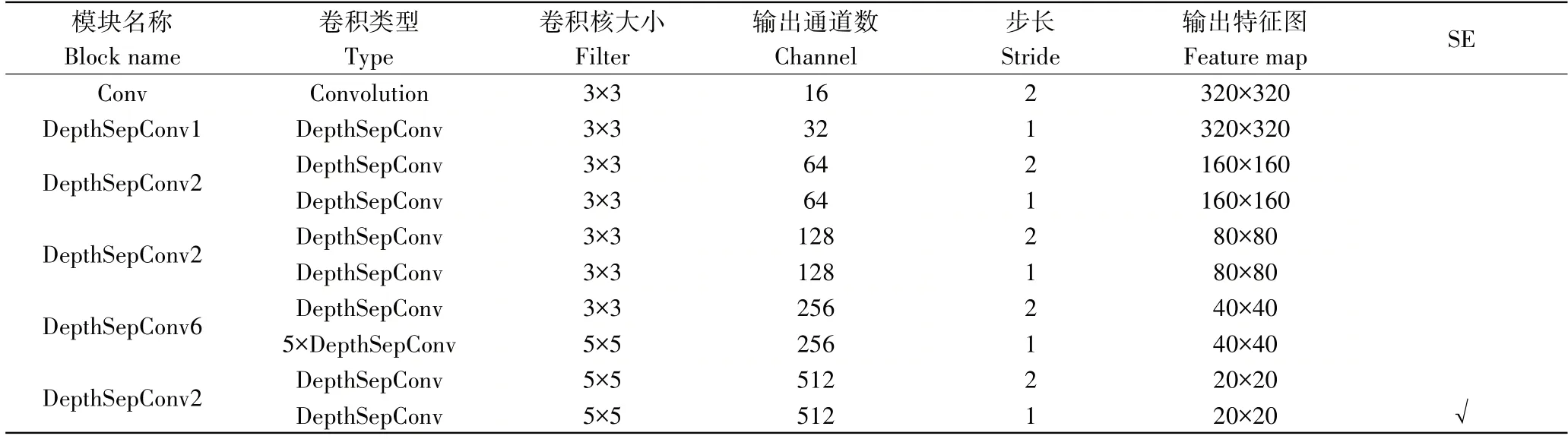
表1 骨干网络结构细节Table 1 Details of backbone network structure
2 试验与参数设置
2.1 数据集与数据增强
本研究中使用的图像拍摄于广州市从化区亿农火龙果采摘园,在果园中收集了800 张成熟火龙果、800 张着色期火龙果照片和800 张未成熟火龙果照片,采集的图像均在自然环境中拍摄,拍摄场景包括:不同光照条件和不同的遮挡类型。拍摄的图像分辨率为3 024×4 032,保存为JPEG格式,部分实验图像如图6。

图6 复杂环境下的火龙果图像Figure 6 Pitaya image in complex environment
对火龙果图像使用翻转、旋转、平移、增加噪声、改变亮度和对比度的方法随机组合以实现数据增强,防止在训练期间过拟合,共获得3 599张图片,其中2 510张作为训练集,689张作为验证集,400张作为测试集(表2)。本研究利用LabelImg 图像标注软件将图像中的目标果实所在区域人工标注成矩形框,采用PASCALVOC 的数据集格式进行存储,其中包含边框的位置和检测目标的类别信息。

表2 训练集、验证集与测试集样本数量Table 2 The number of training set,validation set and test set samples
2.2 训练环境与参数设置
硬件环境为GeForceRTX3090GPU,显存为64 GB,安装的NVIDA 显卡驱动为CUDA11.3。CUDA 是NVIDA推出的GPU 并行计算框架,该框架能够在GPU 上运行,满足复杂计算,软件运行环境选用Windows10 操作系统、OpenCV开源视觉库,PyTorch1.10框架,采用PyCharm进行编译。
目标检测模型的网络输入维640×640,每次迭代的训练的图片样本数为64,对模型进行500 次迭代,训练时使用Warm up 预热方法对学习率进行优化,初始学习率为0.01,权重衰减系数为0.000 5,学习动量为0.8,模型每训练一次保存一次权重。
2.3 评价指标
目标检测模型的评价指标为准确率P(Precision,%)和召回率R(Recall,%),为了度量准确度和召回率在实际检测过程中的表现能力,本研究使用平均精度均值mAP(mean Average Precision,%)和调和平均值F1 作为评价模型效果的综合评估指标,计算公式为:
式中:TP(true positives)为模型检测正确目标的数量;FP(false positives)为模型检测错误目标的数量;FN(false negatives)为模型漏检目标的数量;N为检测目标的类别数量;i为某一具体的类别;AP为每一类火龙果的平均精度值;mAP为两类火龙果的平均精度的均值;F1 为准确率和召回率的调和平均值。
3 结果与分析
3.1 模型训练结果
迭代训练过程中的损失曲线和验证集中各项性能指标曲线如图7。在迭代训练的过程中前100 轮损失下降速度最快,100 轮之后验证总损失逐渐趋于稳定,表明模型已经达到拟合(图7a)。通过训练过程中的验证集的性能指标准确率P、召回率R、平均精度均值mAP和调和平均值F1 变化曲线可知,模型训练过程中在前100轮变化不断地快速上升,之后的训练过程指标缓慢上升(图7b)。由于mAP综合考虑3 个类别的火龙果的准确率和召回率,所以,本模型选取mAP最优轮数时的权重值作为模型权重,此时mAP为94.90%,P为93.34%,R为89.49%,F1值为91.37%。

图7 训练过程损失曲线与验证集的性能指标Figure 7 Training process loss curve and performance index of verification set
3.2 交并比试验对比
YOLOv5模型进行DIoU与αDIoU对比,从表3中可看出,随着置信度阈值的提高,mAP不断下降,所以模型的置信度阈值设定为0.5。在不同置信度阈值的情况下,αDIoU相比DIOU的mAP均有所提升,这表明αDIoU拥有更高的回归精度。

表3 不同置信度阈值下的ɑDIoU和DIoU的mAPTable 3 mAP values of ɑDIoU and DIoU under different confidence thresholds
3.3 PITAYA-YOLOv5消融试验结果
对PITAYA-YOLOv5模型进行了4组消融试验,各性能指标如表4消融试验结果所示。由消融试验结果可知,YOLOv5 骨干网络替换为PPLCNet 的mAP 为93.57%,F1 值为90.25%,第2 组试验在对比第1 组基础上引入SE 注意力模块,改进后的模型在mAP提升0.06 个百分点,F1 值提升0.35 个百分点,SE 注意力模块可对骨干网络的特征图进行通道上的信息进行融合,使模型对特征通道更加关注从而提升检测精度。第3 组试验在第2组的基础上使用加权双向特征金字塔改进颈部网络,mAP提升0.86 个百分点,F1 值提升了0.69 个百分点。这是由于Bi-FPN加权双向特征金字塔提升了高维特征层与低维特征层特征融合的效率,提高了模型对不同尺度的特征提取能力。第4组试验在第3组的基础上使用aDIoU改进损失函数,模型的mAP提升0.43个百分点,F1值提升了0.1 个百分点,αDIoU对DIoU进行幂化,有助于提高目标框的回归精度。通过综合引入SE 注意力模块、Bi-FPN 加权双向特征金字塔和aDIoU损失函数后的模型比原始使用PPLCNet骨干网络的mAP提升了1.33个百分点,F1 值提升了1.12 个百分点。通过消融试验发现,三者配合使用可以对YOLOv5 目标检测模型的性能提升,综合使用3种方法得到的改进YOLOv5模型可以达到较好的检测效果。

表4 消融试验结果Table 4 Ablation experiment results
为了直观体现改进的有效性,使用表4 中第1 组与第4 组的PITAYA-YOLOv5 目标检测模型对不同光照、不同遮挡情况情况下不同成熟度的火龙果进行检测。测试结果如图8,其中不同光照程度下,检测火龙果的置信度两种算法差距不大,当检测的着色期和未成熟火龙果有枝条遮挡时,改进后PITAYA-YOLOv5识别的置信度为0.66 和0.87,高于改进前第1 组的置信度0.2 和0.56。置信度的提高表明模型获得了更丰富的语义信息,这是由于模型的加权双向特征金字塔对于高维特征与低维特征的有效融合,融合后的特征图能够使模型的检测效果变得更好。当检测成熟火龙果间遮挡和未成熟火龙果间遮挡时,第1 组的检测模型存在对两个火龙果识别为同一个目标的问题,而PITAYA-YOLOv5 并未出现漏检,这是因为SE 注意力模块对关注的区域特征选择性地对权重增大,所以当果实有重叠遮挡时,不同的果实因其高权重的区域特征得到保留,在一定程度上解决了重叠造成的漏检问题。

图8 PITAYA-YOLOv5改进前后对不同场景下的火龙果检测效果Figure 8 PITAYA-YOLOv5 test results of Pitaya under different scenes before and after improvement
3.4 不同的目标检测网络的综合对比
为了获得一个实时、准确、可靠和易于部署的火龙果检测模型,本研究使用6 种不同算法对同一火龙果数据集进行训练,统计各模型的指标性能并进行比较。本研究将使用同一火龙果数据集分别训练常用的目标检测算法,如Faster R-CNN、CenterNet、YOLOv3,YOLOv5以及轻量化骨干网络ShuffleNetv2。
各目标检测模型的性能指标统计结果如表5,检测结果的对比主要体现在检测性能、模型规模和检测速度3 个方面,可以发现:本研究的PITAYA-YOLOv5 的mAP、F1 值分别为94.9%、91.4%。其中检测精度最好的是YOLOv5s 的mAP和F1 值分别为96.0%和92.3%,其次是YOLOv3 的mAP和F1 值分别为95.3%和91.5%。尽管改进后的PITAYA-YOLOv5 检测精度略低于YOLOv5s和YOLOv3,但它仍高于其他算法,且模型大小和浮点运算数为8.1 M 和8.2 M。在检测速度上,改进后的PITAYA-YOLOv5 有最快的检测速度,比检测精度最高的YOLOv5提升了约25%的速度,检测单张图片的仅需要20.2ms。较快的检测速度可以在检测火龙果时降低时间成本,同时考虑到移动端设备存储空间和计算能力有限,改进后的模型在保持较高的检测精度的前提下降低了部署难度,因此PITAYA-YOLOv5更适合移动端设备的部署并且能高效率地进行火龙果检测。

表5 不同的目标检测模型性能结果Table 5 Performance results of different target detection models
4 讨论与结论
本研究关注的是相对单一的区域,仅限于广州市从化区亿农火龙果采摘园,且对单一火龙果品种进行了研究,缺乏普遍性,还需要针对不同地区和火龙果品种进行研究。另外,下一步可设置农用无人车搭载高清相机和火龙果成熟度目标检测模型,设定巡查路线定时定点巡视。
本研究以火龙果为研究对象,对YOLOv5 目标检测网络进行改进,提出了一种改进的YOLOv5 目标检测模型(PITAYA-YOLOv5),并对不同成熟度的火龙果进行试验分析和评价。本研究在YOLOv5目标检测模型的基础上使用PPLCNet替换CSPDarkNet并引入SE注意力模块,使用Bi-FPN结构对原来的PANet特征金字塔改进,加强了高维特征层与低维特征层特征融合的效率,同时,使用αDIoU损失函数替代原本的DIoU损失函数,提高了目标的回归精度。改进后的PITAYA-YOLOv5模型mAP和F1值分别提升了1.33个百分点和1.12个百分点。检测效果表明,PITAYA-YOLOv5有利于提高火龙果的检测精度和正确检测相互重叠的火龙果。
本研究所提出的PITAYA-YOLOv5 在验证集下的mAP为94.9%,F1 值为91.4%,模型大小为8.1 M,平均检测时间为20.2 ms。通过不同的目标检测算法Faster R-CNN、CenterNet、YOLOv5s-ShuffleNetv2、YOLOv3 和YOLOv5s,本研究在保持较高的检测精度的前提下,降低了模型部署难度和检测时间,这使得该模型更适合移动端设备中进行高效率的火龙果检测。
猜你喜欢
发明与创新(2021年39期)2021-11-05 07:15:38
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
当代水产(2019年11期)2019-12-23 09:02:54
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
知识经济·中国直销(2017年5期)2017-06-15 20:28:19
小布老虎(2016年18期)2016-12-01 05:47:41
小主人报(2015年23期)2015-02-28 20:45:21
中国学校体育(2014年11期)2014-05-10 09:57:04
电视技术(2014年19期)2014-03-11 15:38:20
