
基于LOF-SMOTE算法的地下水影响下矿山岩溶塌陷风险预测研究
2023-06-29 06:44盛建龙乔宇王平俞栋华张彦文
有色金属科学与工程 2023年3期
盛建龙, 乔宇, 王平, 俞栋华, 张彦文
(1.武汉科技大学资源与环境工程学院,武汉 430081; 2.湖北工建科技有限公司,武汉 430076)
岩溶塌陷是矿山地表塌陷的原因之一,是一种常见的矿山地质灾害[1]。岩溶塌陷不但影响企业效益及生态环境,更对相关领域工作人员生命安全带来威胁,因此,准确预测岩溶塌陷现象具有极大的实际意义。
为对岩溶塌陷进行准确预测,首先需要了解岩溶发育和塌陷的影响因素。有关岩溶发育机理及影响因素的多项研究[2-11]表明,岩溶主要由可溶岩与地下水相互作用而产生,其主要原理是水、二氧化碳与可溶岩中的碳酸成分发生的化学反应。岩溶塌陷是岩溶结构导致的塌陷现象,是多因素叠加的结果[12-16]。岩溶塌陷一般发展过程是,地下水对可溶性基岩侵蚀产生岩溶构造,岩溶构造上的覆盖土由于受地下水的动力影响产生土洞,随着土洞不断扩大,地表随之塌陷。石树静等[17]认为岩溶塌陷是多种不良因素共同作用的产物,其致塌因素主要包括特殊的“水-土-岩”组合及人为活动;也有研究表明地下和地表水体对土层的潜蚀作用导致岩溶地面塌陷[18-22]。结合土的本质作用,根据不同类型的覆盖层,可将塌陷分为土洞型、沙漏型和泥流型3种塌陷机制[23-24]。因此,预测模型中的评价指标应以相关影响因素为参考进行选取。
研究者采用多种方法实现岩溶塌陷的预测。例如,使用模糊综合评价法预测岩溶塌陷[25-26],但模型在指标权值的确定过程中,不同程度地使用了专家打分法,理论上仍具有一定的主观性。PERRIN等[27]根据塌陷发育的影响因素及过程,分析权重后建立了岩溶塌陷敏感性模型,具有一定的效果,但在具体应用中,对于岩溶塌陷不集中区域仍有20%无法预测,在这类区域中的预测效果差强人意。YAU等[28]结合数值模拟方法提出了一种概率模型预测岩溶空腔分布,取得了预期结果,但模型在建立和运行时比较耗时。综上可知,因实际工程中的现象是复杂的,在使用传统评价方法时难以避免繁琐且带有一定主观性的过程,导致传统评价方法在一些工程条件下具有一定的局限性。
神经网络模型能够根据训练样本自动调整结构参数,改变映射关系,具有较强的自适应性,可实现多种非线性映射,较好地解决了传统方法中主观性大的问题,提高评估精确性,简化过程。BP神经网络是一种经典的神经网络模型,已被证实在岩溶塌陷预测问题中具有一定的实用性[29-32],并且在部分工程中也取得了较好的效果。但是,神经网络预测模型在使用时对样本数量具有一定的要求,工程数据数量主要由工程需求决定,样本数量过少会过拟合,导致预测效果不良,并且受环境、人员等因素影响,使得样本数量及质量无法满足模型学习需求,达不到预期的效果。
LOF(Local Outlier Factor)算法可将样本数据中异常(离群)数据检测并剔除,SMOTE(Synthetic Minority Oversampling Technique)算法可合成新的少数类样本,均衡样本种类。在类似的工程问题中,谭文侃等[33]采用LOF算法和SMOTE算法组合对强烈岩爆进行了预测,结果表明,经过改进方法处理后,有效且可靠地提高了机器学习的岩爆预测模型准确率。本文采用LOF算法及SMOTE算法对工程数据进行预处理,依据岩溶塌陷机理建立BP(Back Propagation)神经网络岩溶塌陷风险预测模型。
1 模型基本原理
1.1 LOF算法
LOF算法[34]是一种基于密度无监督的局部离群点检测方法,可计算数据点相对于其邻域的局部密度偏差,通过对比确定数据对象的离群值。其主要步骤如下:
1)k距离邻域
数据点p的邻域Nk(p) 是到数据点p的距离小于等于点p第k距离的点的集合,即:
当dk(p)=d(p,o)时需满足:
① 数据集D中至少有不包括p的k个点o′∈C{p},满足d(p,o′)≤d(p,o);
② 数据集D中至多有不包括p的k-1 个点o′∈C{p},满足d(p,o′)<d(p,o)。
2)可达距离
点o至点p第k可达距离rdk(p,o)是点o的第k距离与点p、o间的距离的最大值,即:
图1所示为当k=5时,rd5(p1,o)=d(p1,o);图2所示为当k=5时,rd5(p2,o)=d5(o)
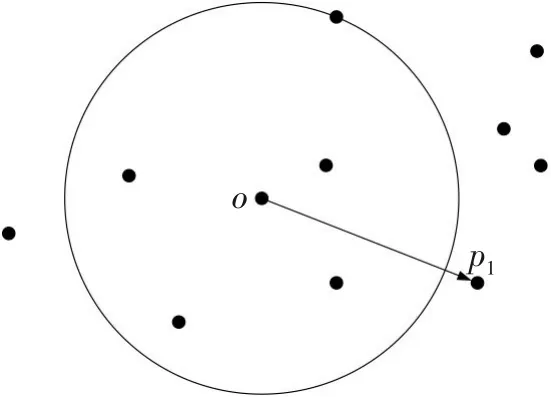
图1 当k=5时,点o至点p1的可达距离示意Fig.1 Schematic diagram of accessible distance from point o to point p1 when k=5

图2 当k=5时,点o至点p2的可达距离示意Fig.2 Schematic diagram of accessible distance from point o to point p2 when k=5
3)局部可达密度
局部可达密度可由点p的第k邻域内点到p的平均可达距离的倒数表示,密度越低,离群点的可能性越大,表达式如下:
4)局部离群因子
局部离群因子是点p的邻域内所有点的平均局部可达密度与点p本身的局部可达密度之比的平均值,表达式如下:
若局部离群因子的值越大于1,说明p的密度越小于邻域的平均密度,该点可能是一个离群点。
1.2 SMOTE算法
SMOTE算法的主要思路是以少数类样本为基础合成新的样本[35],在此过程中不但可以控制新样本的数量,还可以限制新样本的分布区域[36]。以图3样本示意图为例,其中,圆形代表多数类样本,星形代表少数类样本。

图3 样本示意(其中星形为少数类样本)Fig.3 Schematic diagram of sample (the stellate ones are a minority of class samples)
对于少数类样本,以欧式距离为标准计算其到同类样本的距离,得到k近邻。少数类样本中选择一个点xo,从其k近邻随机选择某点xp,根据式(6)得到新样本x′。图4中方形为星形合成的新样本。

图4 新样本示意(其中方形为新合成样本)Fig.4 Schematic diagram of new sample (the square ones are new synthetic samples)
1.3 BP经网络
BP神经网络是一种输入信号正向传播,误差反向传播的神经网络模型。通过学习训练对某项结果进行预测,根据预测结果与预期结果的误差修改权值和阈值,进一步调整使其与预期结果一致。图5所示为BP神经网络示意图,BP神经网络由输入层、隐含层和输出层组成。

图5 BP神经网络示意Fig.5 Schematic diagram of BP neural network
BP神经网络训练步骤主要有以下步骤:
① 确定输入输出值,输入、隐含、输出节点数,初始化不同层间权值ωji、νkj。
② 计算隐含层输出,计算公式如式(7)所示,其中,θj为隐含层节点,j为隐含层节点数,f为传递函数。
③计算输出层输出,计算公式如式(8)所示,其中,φk为输出层阈值(k为输出层节点数)。
④根据Ok及y计算网络预测误差e。
⑤根据误差e使用式(9)和式(10)调整权值,使用式(11)和式(12)调整阈值。
⑥检验目标误差。
2 模型建立
2.1 评价指标的确定
杨彪[37]根据某矿山岩溶地表塌陷实测数据,确定了地下水、水文地质参数、覆盖层、环境、岩性这5个方面岩溶塌陷影响因素,以及12个显著影响岩溶地表塌陷的子因素,因研究区基岩地层均为壶天群含水层,因此不考虑地层岩性的影响,所以选取11个因子作为评价指标,分别为地下水位(x1)、地下水位波动幅度(x2)、给水度(x3)、横向渗透系数(x4)、纵向渗透系数(x5)、贮水系数(x6)、覆盖层厚度(x7)、人工抽水强度(x8)、河流和湖泊(x9)、降雨量(x10)和井下涌水点含沙率(x11)。同时,将5个方面的因素按照对岩溶地表的影响不同程度的进行了量化分级, 如表1—表6所列,以此为基础将最终预测期望输出参数分为5级,如表7所列。本文将采用该文献确定的指标、数据及分级。

表1 地下水影响量化分级表Table 1 Quantified grading table of groundwater impact

表2 覆盖层影响量化分级表Table 2 Quantitative grading table of overburden impact

表3 降雨量影响量化分级表Table 3 Quantitative grading table of rainfall impact

表4 河流湖泊影响量化分级表Table 4 Quantitative grading table of river and lake impact

表5 矿坑涌水量影响量化分级表Table 5 Quantitative classification table of mine water inflow effect

表6 井下涌水点含沙率影响量化分级表Table 6 Quantitative grading table of influence of sand content at underground water gushing point

表7 期望输出参数分级Table 7 Expected output parameter grading
地下水对岩溶地表塌陷的影响主要体现在地下水位和地下水位波动幅度两个因素上。依据矿山工程实际进行量化分级,如表1所列。
研究区地表覆盖着第四系粉质黏土和粉土夹砂砾石厚度为10~30 m,含水性能弱,降雨通过覆盖层进入含水层。覆盖层厚度是影响地表塌陷的重要因素,依据矿山工程实际进行量化分级,如表2所列。
该矿曾为了消除地下水对井下开采的影响,建设了截流疏干系统,降低了整个地区的水位,形成较大水力坡度。通过监测矿坑涌水量和井下涌水点含沙量反映抽水强度对塌陷的影响,因此根据矿山工程实际进行量化分级,如表3—表6所列。
2.2 训练及预测
采用Python语言对样本进行预处理,采用LOF算法对岩溶塌陷数据集进行检测,剔除离群点,之后由SMOTE算法过采样,各类样本总数由原21组增加到436组,并从原数据及新合成数据中分层抽样后增加训练集与测试集。表8所示为原训练样本,表9所示为原预测样本。

表8 原训练样本Table 8 Original training samples

表9 原预测样本Table 9 Original prediction samples
根据预处理后的训练集与测试集,建立BP神经网络预测模型,其中,参数设置中目标误差0.0001,步数2000,输入节点11个,学习率为0.01。在训练和预测时,采取随机10组的结果求平均值的方法减少样本误差。图6(a)、图6(b)、图6(c)为节选3组预测结果,图6(d)为10组平均预测结果,表10为预测结果。

表10 预处理后实际输出与预测结果对比Table 10 Comparison between the actual output results after pretreatment and predicted results

图6 预测结果:(a)、(b)、(c)为节选的3组预测结果;(d)为10组平均预测结果Fig.6 Prediction results: (a), (b) and (c) are three prediction groups of results excerpted;(d) is the average prediction result of ten groups
2.3 预测分析
参考文献[38]根据本文中预处理前的原始数据,使用PCA-PSO-SVM方法对矿山岩溶塌陷进行预测,取得了较好的预测效果见表10。表11将本文模型预测误差与文献[38]的模型误差做对比,本文模型的预测相对误差分别0.20%、-0.41%、-0.20%、-2.26%、-0.90%,均优于SVM预测模型的8.93%、10.00%、-3.40%、3.20%、5.20%,基本优于PCA-PSO-SVM预测模型的2.00%、3.07%、-1.10%、0.13%、4.27%,结合样本回归情况(图7),其中,回归值R表示实际与预测之间的相关性,R越接近1表示关系越密切,可以看出各类数据都呈现出较好的回归性,进一步说明了在相对满足神经网络对于样本数量的需求下,LOF-SMOTE-BPNN预测模型对于预测岩溶塌陷问题具有较高的使用价值。

表11 3种预测模型误差对比Table 11 Error comparison of three prediction models

图7 样本回归情况(回归值R表示实际与预测之间的相关性,越接近1表示关系越密切)Fig.7 Sample regression( the regression value R represents the correlation between actual and forecast, and the closer it is to 1, the closer the relationship is)
2.4 应用案例
本文根据某矿山工程实例建立了LOF-SMOTEBPNN模型,并与同工程条件下其他预测模型的效果进行了对比,取得了较好的预测效果。因模型基于岩溶塌陷原理,所以其不但适用于矿山岩溶塌陷预测,还可用于其他岩溶塌陷工程预测。根据桂林市内岩溶塌陷问题[31],应用LOF-SMOTE-BPNN模型进行预测,并与实际结果作对比,验证模型的准确性与实用性。
文献[31]统计了桂林市40余年发生的200余起岩溶地面塌陷,从近200个岩溶塌陷的实例中抽出14个样本,根据岩溶地面塌陷的诱发因素,选取了岩性系数(RQC)、岩体结构系数(RMSC)、地下水系数(GWC)、覆盖层系数(SSC)、地形地貌系数(LPC)、环境条件系数(ECC)6个评价因素,将岩溶地面塌陷程度由稳定到很易塌陷分为A、B、C、D、E五级状态。将五级状态赋予阈值1~5进行预测[39],根据其中的训练预测样本中C级样本,验证模型可靠性。表12为C级样本评价指标。

表12 C级样本评价指标Table 12 Evaluation indexes of grade C samples
表13为C级3号样本未预处理与预处理后预测结果对比,由于原始数据中C级样本数量较少,训练不够充分,预测结果为B级与实际情况不相符,经过预处理后的预测结果为C级与实际情况一致,模型对小样本C级预测效果显著提升。

表13 C级3号样本未预处理与预处理后预测结果对比Table 13 Comparison between the prediction results of grade C No.3 sample without pretreatment and after pretreatment
3 结论
1)本文采用LOF与SMOTE算法,对矿山地表岩溶塌陷原始数据进行预处理,剔除了离群数据后增加了少数类样本,基本满足了神经网络模型对于样本数量的要求,提高了模型预测效果。
2)数据预处理后的BP神经网络模型,预测相对误差分别为0.20%、-0.41%、-0.20%、-2.26%、-0.90%,精度较高,具有较好的预测能力,因此LOFSMOTE-BPNN可为小样本矿山岩溶塌陷预测提供思路,并为矿山岩溶塌陷治理提供依据。
3)以桂林岩溶地面塌陷实例中C级岩溶塌陷程度为例,对模型进行验证,预测结果与实际情况一致,进一步证明了模型的可行性。
猜你喜欢
湖南水利水电(2021年6期)2022-01-18
中华建设(2019年2期)2019-08-01
制导与引信(2017年3期)2017-11-02
水利科技与经济(2016年9期)2016-04-22
工业设计(2016年11期)2016-04-16
中国房地产业(2016年9期)2016-03-01
环境科技(2015年6期)2015-11-08
作文评点报·低幼版(2015年5期)2015-05-30
电网与清洁能源(2015年2期)2015-02-28
西安交通大学学报(2014年8期)2014-04-16
