
Python编程语言在大数据分析中的运用策略
2023-06-26 13:11:54黄素青
无线互联科技 2023年8期
黄素青

摘要:在当今信息技术的发展中,大数据分析技术发挥着显著优势。在进行大数据分析的过程中,Python编程语言的合理运用也至关重要。为实现Python编程语言的合理运用,促进大数据分析效率和质量的提升,文章基于Python编程语言在大数据分析过程中的运用策略进行分析,将Python编程语言中的Numpy库用作基础的数据分析工具,Pandas库用作专用的数据分析库,Matplotlib库用作可视化数据工具,将Scikit-learn库用于数据分析。文章的分析可为Python编程语言的应用和大数据分析技术的融合提供科学参考。
关鍵词:大数据分析;Python编程语言;运用策略
中图分类号:TP311 文献标志码:A
0 引言
随着云时代的来临,数据资源爆炸式增长,要挖掘出数据中有价值的信息,关键技术在于数据的加工和分析。目前,大数据领域有许多大数据分析的工具,Python和R语言等都是非常受欢迎的开发语言。近几年,Python的用户数量不断增多,在大数据分析领域的用户量已经超过了R语言。Python以其丰富的功能库,使软件设计人员能够更高效地完成工作。
1 Python编程语言与大数据分析概述
1.1 Python编程语言
Python是一种面向对象的解释型程序设计语言,广泛应用于Web应用开发、数据分析、科学计算和图像处理等众多领域。此种语言语法简洁、简单易学,代码量只有其他语言的1/5~1/10。Python是一种免费的开源软件,用户可以自由地发布该软件的拷贝和修改源代码,而不需要承担任何费用且不涉及版权。它不仅具有良好的跨平台性能,同时也能轻松地将其他语言(如C,C++等)开发的模块连接进来。Python的标准库拥有几百个类、函数库和图库,此外,还可以加载第三方函数库,在快速开发时展现其强大优势。随着大数据市场的不断壮大,Python以其自身的优势,成为最受欢迎的程序设计语言之一。凭借这些优势与特征,Python编程语言在当今的软件设计与大数据分析中得到了非常广泛的应用。
1.2 大数据分析
所谓大数据分析,就是对具有巨大规模的数据进行分析。具体分析中,其主要的目标有3个:(1)需要实现大量的数据交互;(2)需要对数据进行探索性计算;(3)需要获得可视化的数据分析结果。在当今的信息化时代中,大数据分析已经成为各个领域信息数据管理与应用的关键。在使用Python编程语言进行大数据分析的过程中,为使Python编程语言达到良好的应用效果,开发人员要明确大数据分析所使用的相关功能库,然后以此为依据,结合大数据分析的实际需求,对Python编程语言加以合理应用。
2 大数据分析中的Python编程语言应用策略分析
2.1 将Python编程语言中的Numpy库用作基础的数据分析工具
在Python编程语言中,Numpy库属于一种科学计算库,同时也是Python编程语言进行矢量运算以及数据组处理的一个重要工具包。在通过Python编程语言进行大数据分析的过程中,Numpy是数据分析和高性能计算的基础。对于大数据分析,Numpy库不仅会实现多个便捷性矢量运算接口的提供,同时也可以实现Python编程语言数据组运算效率的显著提升[2]。因此,在通过Python编程语言进行大数据分析的过程中,可将Numpy库用作基础的数据分析工具,以此来为数据分析工具的良好应用提供足够帮助。
2.2 将Python编程语言中的Pandas库用作专用的数据分析库
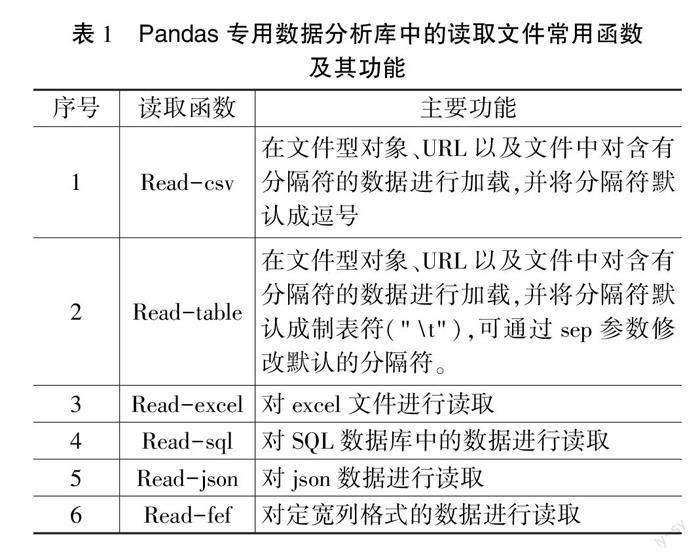
在Python编程语言的具体应用中,Pandas是以Numpy库为基础所构建的一种高性能数据分析库,通过该数据分析库的应用,可实现数据的归并、分组以及排序等各项操作,同时也可以对数据进行标准方差、极值求解以及求和等统计计算。基于此,在通过Python编程语言进行大数据分析的过程中,可将Pandas用作专用的数据分析库,以此来实现数据的结构化处理。在大数据分析中,第一个环节就是数据的采集,而Pandas则可以实现多种I/O形式的API函数提供,同时也可以对txt,csv,SQL Server以及xlsx等多种类型的数据文件进行读取[3]。通过这样的方式,便可为大数据分析奠定良好的技术基础。如表1所示为Pandas专用数据分析库中的读取文件常用函数及其功能情况。
2.3 将Python编程语言中的Matplotlib库用作可视化数据工具
在Python编程语言中,Matplotlib库属于最著名的一个绘图库,将Matplotlib库与Numpy模块相配合,便可让大数据分析结果得以可视化显示。因此,在通过Python编程语言进行大数据分析的过程中,研究者和技术人员可将其中的Matplotlib库用作可视化数据工具。在此过程中,需要通过Matplotlib中的liot工具包进行绘图,这个工具包所提供的绘图API和Matlab相似,技术人员只需要调用模块提供的函数,便可实现柱形图、散点图以及直方图等二维、三维图形的高质高效绘制。通过这样的方式,便可让大数据分析结果实现科学、准确的可视化显示,从而让Python编程语言在大数据分析可视化显示中发挥出充分的应用优势[4]。比如,在对某个智商数据直方图进行随机绘制的过程中,规定其分布形式为正态分布,数量为10万个,sigam(罕见西格玛,即高智慧)为20,mu(智慧系数)为100,如图1所示为通过Matplotlib绘制出的智商数据正态分布。
2.4 将Python编程语言中的Scikit-learn库用来进行数据分析
在通过Python编程语言进行大数据分析的过程中,Scikit-learn库也是一项关键的技术形式。Scikit-learn库是将Bumpy库、Scipy以及Matplotlib作为基础所构建的一个机器学习库。在Scikit-learn机器学习库中,所有的支持算法以及模型都已经得到了广泛验证。就目前来看,其主要支持算法和模型可按照3个大类进行划分,第一大类是分类,第二大类是回归,第三大类是聚类。同时,Scikit-learn机器学习库也可以为大数据分析提供科学的数据预处理、模型选择以及数据降维等功能。而在Scikit-learn机器学习库中,最为常用的一项大数据分析功能便是Logistic回归。
在通过Logistic回归法进行大数据分析的过程中,首先需要进行算法设计。因为Logistic回归属于一个广义形式的线性分析模型,其实质是通过回归的形式对分类问题加以解决。假设x是一个特征向量,在这个特征向量中,其属性值共有n个,则x与n之间的关系可表示为:x=(x1,x2,x3...xn),而所谓的线性分析模型,则是通过若干个属性进行线性组合,从而获得的预测函数[5],其公式为:
f(x)=w1x1+w2x2+w3x3+...+wnxn+b (1)
式(1)中的w代表權重,b代表偏值。如果按照向量的形式加以表示,则其公式可转变为:
f(x)=wTx+b (2)
式(2)中的T代表组合成线性分析模型的属性个数。而在线性模型中,其关键的算法便是w以及b的学习。在线性回归中,最主要的任务是借助于训练集来实现w以及b的学习和获得。通过这样的方式,才可以让训练集预测值及其真实回归目标值这两者之间具有最小的均方误差。如果给定了一个(x,y)样例数据点,对于这个样本点所具有的预测值f(x),如果其线性模型和真实值y相接近,线性回归模型便由此形成,也就是:
y=wTx+b(3)
线性回归模型主要表征的是输入值x和输出值y这两者之间所具有的一种线性关系。
通过Scikit-learn库中自带的iris数据集对大数据进行训练以及预测处理。在此过程中,如果并未将Python科学计算包安装在相应的大数据分析系统中,则最好对Anaconda进行合理的安装和利用。对于Python编程语言而言,Anaconda是一种十分优秀的集成化开发环境,其中关于数据科学方面的第三方包接近200个,可对大数据进行科学处理与预测分析,同时也可以对Python编程语言的发行版做出科学计算,可以将人工智能形式的开发环境构建在此基础上。其中的所有代码都可通过Anaconda进行调试。在通过Scikit-learn库中自带的iris数据集对大数据进行训练以及预测处理时,其主要的步骤包括以下3个。
第一,将所需模块导入。(1)将Numpy模块导入,此时可选择Numpy的别名import numpy as up #np;(2)将Scikit-learn库中的datasets以及linear-model模块导入,其代码是from sklearn import linear-model,datasets。
第二,将数据导入。使用Scikit-learn库提供的方法将导入的数据分为两类:训练数据和测试数据。与此同时,自动生成相应的案例数据,这些都可以在Python编程语言安装子目录中找到,从而为相应的数据访问提供专用接口,其核心代码如下:
iris=datasets.load_iris()
x=iris.data:
y=iris.target:
第三,选择合理的模型来实施大数据训练以及预测,在Scikit-learn库中,须借助于linear-model这一模块内的LogisticRegression类来实现Logistic的回归,以此来达到二分类效果。其核心代码为:
log_reg=linear_model.LongisticRegression()
lr=log_reg.fit(X_train,y_train)
log_reg.predict(X_test)
Scikit-learn库会将训练数据的结果存储在属性名结尾带下划线的属性里,如:系数或权重值w将会在coef_属性里保存,偏移值b将会在interecept_属性里保存,以此为用户区分提供便利。
3 结语
在当今的信息化时代中,大数据分析已经成为各个领域数据信息管理及其应用过程中的一项必要手段。而在大数据分析中,作为一种先进、简洁、高效的编程语言,Python编程语言已经得到了广泛应用,且发挥出了非常显著的应用优势。本文分析了Python编程语言在大数据处理分析环节的运用,使用Numpy库来提高数据分析效率,Pandas库用于快速分析数据,Matplotlib库作为数据的可视化工具以及将Scikit-learn库用来进行数据分析。在大数据分析技术的不断发展中,Python编程语言也会实现进一步的发展。相信在未来,Python编程语言将会得到进一步的简化,并能够在更多新开发和应用的系统中发挥出良好的兼容性,其大数据分析效率也会得到不断提升。通过Python编程语言的合理应用,将会让未来的大数据分析变得更加轻松、简单,从而为各个领域中的大数据信息应用和管理提供更多有利条件。
参考文献
[1]李天格,许鹏.大数据专业“Python程序设计”课程建设探究[J].计算机时代,2022(9):140-142.
[2]卢绍兵.基于Python的混合语言编程及其实现研究[J].科技资讯,2022(14):31-33.
[3]张雪莲.试析Python编程语言的特点及应用[J].电脑编程技巧与维护,2020(11):29-30,33.
[4]张娅莉,周予.基于大数据背景Python编程语言创新实践研究[J].数字技术与应用,2020(6):197-199.
[5]王亮,左文涛.大数据收集与分析中Python编程语言运用研究[J].计算机产品与流通,2020(1):22.
(编辑 李春燕)
Application strategy of the Python programming language in big data analysis
Huang Suqing
(Fujian Economic School, Fuzhou 350001, China)
Abstract: In the development of modern information technology, big data analysis has brought its superiority into full play. In the process of big data analysis, the proper use of Python programming language is also crucial. In order to realize the rational application of Python programming language and promote the improvement of the efficiency and quality of big data analysis, this paper analyzes the application strategy of the Python programming language in the process of big data analysis,including the application of the Numpy library in the Python programming language as a basic data analysis tool, the Pandas library as a dedicated data analysis library, the Matplotlib library as a visual data tool, and Scikit-learn library is used for data analysis. It is hoped that this analysis can provide scientific reference for the application of Python programming language and the development of big data analysis technology.
Key words: big data analytics; Python programming language; strategy of use
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
科普童话·学霸日记(2022年1期)2022-05-30 10:48:04
科普童话·学霸日记(2022年1期)2022-05-30 10:48:04
仪器仪表用户(2021年10期)2021-11-27 08:26:14
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
漳州职业技术学院学报(2019年1期)2019-11-16 08:45:58
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
电子制作(2018年1期)2018-04-04 01:48:36
物流技术与应用(2017年3期)2017-05-17 05:29:04
现代计算机(2016年12期)2016-02-28 18:35:25
