
源代码检测分析技术与应用研究
2023-06-26 18:22:49孙丽
无线互联科技 2023年8期
关键词:网络安全
孙丽
摘要:随着近几年的实战攻防演练的强度增加以及拍打力度的增强,源代码检测技术迄今为止仍是有待解决的重要问题。不同于软件缺陷,源代码漏洞更加难以识别和修复。文章从源代码安全的必要性、软件供应链安全的安全风险和不可控风险出发,重点阐述了源代码检测的技术原理、技术难点以及目前国产源代码的技术突破,同时对“安全左移”的具体落实提出建设性意见。
关键词:源代码安全;网络安全;软件供应链安全;源代码检测技术;安全左移
中图分类号:TP 399 文献标志码:A
0 引言
随着近几年国家对网络安全的重视及《中华人民共和国网络安全法》的发布,伴随着各种攻防演练、护网行动的开展,等级保护测评工作、密码测评工作、风险评估工作的落实,网络“安全左移”已是志在必行。源代码安全已成为网络安全中不可或缺的一分子。研究源代码检测分析技术与应用的问题随之呈现。源代码检测分析技术可以实现对程序本身的缺陷进行检测,从而提高软件的安全性。本文從研究源代码检测技术的目的——源代码安全的必要性出发,分析了源代码因软件供应链问题而存在的安全风险,进而对源代码检测的技术要点和技术难点进行探讨,对“安全左移”提出建设性意见。
1 关注源代码安全的必要性
1.1 法律法规驱动
《中华人民共和国网络安全法》中第二十一条国家实行网络安全等级保护制度,第二十六条开展网络安全认证、检测、风险评估等活动,向社会发布系统漏洞、计算机病毒、网络攻击、网络侵入等网络安全信息,应当遵守国家有关规定。《中华人民共和国网络安全法》于2016年11月7日发布,2017年6月1日起施行,共7章、79条,对企事业单位来说,有38条明确规范义务。《GB/T 28448—2019 信息安全技术网络安全等级保护测评要求》中安全建设管理在软件开发过程中对安全性进行测试、软件安装前对可能存在的恶意代码进行检测;外包软件开发应保证开发单位提供软件源代码,审查软件中可能存在的后门和隐蔽信道。随着法规、政策的完善,“安全左移”刻不容缓。
1.2 内部需求驱动
随着近几年的实战攻防演练的强度增加以及拍打力度的增强,对开发单位的系统健全性的要求越来越高。其主要分为以下两个方面:(1)提升开发过程安全性。在软件开发生命周期全程对安全缺陷进行管控,从而提升软件本身的安全能力,减轻应用上线后给安全运行带来的压力。(2)加强实战对抗能力。当前安全形势对快速响应漏洞的发现及修补提出了更高要求。在系统上线前解决漏洞问题,系统才具备更好的健全性及实战对抗能力。
1.3 管理成本驱动
美国国家标准与技术研究院NIST曾发布“系统建设不同阶段问题处理成本”模型,需求分析及设计阶段的问题成本为1,编码阶段为5,集成测试阶段为10,系统验收测试阶段为15,发布阶段为30。显而易见,从节省人员成本和提升工作效率的角度,源代码的安全值得关注。
2 关注软件供应链安全是源代码安全的基础
据美国Synopsys公司《2021年开源安全和风险分析报告》统计:98%的代码库包中含开源代码,73%的代码由开源代码构成,84%的代码库至少有一个漏洞,65%的代码库存在许可证冲突。开源软件已成为软件开发的核心要素,但也引入了多种风险。同时,部分公司在一些开源软件的基础上进行简单“加工”而形成所谓自主可控的产品,并不清楚其产品涵盖哪些源代码。软件开发者缺少攻击者的思维方式,对核心代码的维护能力极低。如果此类产品应用于一些关键领域,那么会带来安全隐患,从而对“自主可控”造成威胁。
2021年7月,著名IT管理软件供应商Kaseya发生供应链攻击,攻击者利用了Kaseya的虚拟系统管理员 (VSA) 技术中的3个漏洞。许多托管服务提供商 (MSPs) 都会使用这种技术来管理其客户网络。这导致攻击者在托管服务提供商下游客户的数千个系统上分发勒索软件。此事件波及17个国家上千家企业和机构的上百万台设备被加密,索要赎金高达7 000万美元,是迄今为止规模最大的供应链事件。
总体来说,软件供应链的安全风险和不可控风险并存,安全风险分为软件漏洞、软件后门、恶意篡改、信息泄露、供应链劫持5点;不可控风险分为服务停止、技术出口管制、开源变闭源3点。
2.1 软件自身漏洞
在软件产品原生开发过程中产生的及次开发从上游继承的软件漏洞,主要是开发能力、管理水平不足引发的。2021年12月披露的Apache Log4i远程代码执行漏洞,存在递归解析功能。攻击者可直接构造恶意请求,触发远程代码执行该漏洞。2021年12月,log4j2JndiRCECVE-2021-44228漏洞被爆出。当程序将用户输入的数据进行日志记录时,即可触发此漏洞。攻击者利用此漏洞可以在目标服务器上执行任意代码。该漏洞影响多达60 644个开源软件,涉及相关版本软件包高达340 657个。本次漏洞的触发模式简单且成本极低,是一场Java生态的浩劫。
2.2 人为恶意代码植入
人为恶意代码植入是指为达到某种目的对正常软件功能进行修改的行为。该行为包括3种类型:源代码植入、开发工具植入、供应信息篡改。2020年,GitHub发现其平台上26个Java集成开发环境相关开源代码库被植入恶意代码。代码随开发者下载使用激活后窃取平台技术秘密。
2.3 软件恶意后门
供方出于软件维护的目的在软件产品中预置后门,或为满足国家的需要,为国家安全部门预留一些“接口”,方便获取用户敏感数据、控制用户系统运行等,如被曝光的“棱镜门”。
2.4 供应链劫持
供应链劫持是普遍存在的供应链污染,涵盖整个软件开发生命周期,包括需求设计阶段、编码阶段、集成测试阶段、系统验收阶段、系统运行维护升级阶段。供应链劫持安全风险突出,涉及捆绑恶意代码、下载劫持、网络劫持、物流链劫持、升级劫持等。
2.5 开源许可证违规使用
軟件产品发布时缺少开源许可证类型,或软件产品发布时不符合相应许可协议的规范和要求。使用开源软件,应当遵守其许可证的要求,否则视为违规使用开源软件。
2.6 上游供应中断
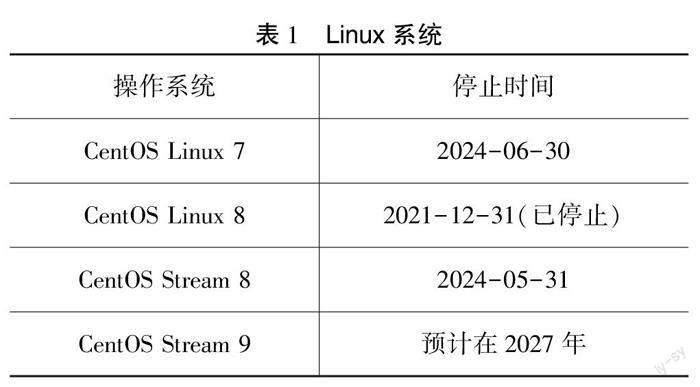
(1)技术出口管制导致开源软件相关服务被禁,开源代码托管平台被禁。2021年8月13日,Docker声明禁止“禁运国家”和被列入美国“实体清单”的组织和个人使用遵循该服务协议的公共镜像存储服务DockerHub。2022年3月2日,GitHub 官方称将遵守美国政府的相关规定,严格限制俄罗斯通过GitHub获得其维持军事能力所需的技术和其他物品。(2)开源变闭源。开源软件在某版本后不再提供开源代码,或者由于缺少投入,维护不及时、不到位,开源项目不能稳定发展甚至终止。(3)停服风险。巨头企业为其利益改变既定开源规则或商业模式,导致开源项目停止更新维护。Linux系统如表1所示。
2.7 敏感信息泄露
软件供应链信息被有意或无意地泄露在用户不知情的情况下,软件产品产生的数据、流程等全部或部分被泄露到用户可控范围外。网络地下黑产猖獗,当前各行业部门和企事业单位大量收集存储公民个人信息、地理位置等数据,但在数据使用上重收集、轻防护,导致其大量外泄。网络数据黑市几乎囊括了吃穿住行等方方面面。近期,南京公安机关侦破的一起侵犯公民个人信息案中,犯罪分子在云盘存储上百亿条公民个人信息,其中包括银行账户余额等高隐私信息。
2.8 建立开源软件应用规则的急迫性
软件供应链的安全风险和不可控风险是并存的,这就体现了建立开源软件应用规则的重要性。在开源技术引入前期,对其进行全面、详尽、科学的风险检查与评估,符合规定的才能被企业引入,为开发所用,不符合的需要杜绝,从源头上降低风险引入。
企业需要全面建设DevSecOps能力,在传统的安全左移基础之上增强软件成分分析能力,具备组件文件、代码片段等不同粒度的分析、溯源、风险检查能力,更需把开源技术的八大类风险均实现左移。
DevSecOps主要的目标是建设一套自动化风险检查、评估与智能管理系统。该系统需要贯穿软件开发的全生命周期,包括技术选型、软件开发、软件测试、软件上线运维以及软件停服下线等阶段。本设计在不同阶段,给企业提供不同能力,做到全面的风险左移、可知可控。
3 国产源代码检测新技术特点
3.1 传统的检测手段
传统的代码检测分析技术其实就是静态漏洞检测技术,用来分析代码在运行过程当中的词法、语法以及语义,这是一个常见的检测手段。同时,它会配合数据流的分析和污点分析等技术,也就是常说的污点追踪。当一个数据进来后,此技术可能要对其进行持续的跟踪,研究其最终是否被利用。技术人员会对程序代码进行抽象和建模,最终抽象成一个数据结构,从而对其中的缺陷进行分析,主要分析程序中的数据依赖(数值等应用)、控制依赖(条件控制)、变量受污染的状态信息。此技术通过内置的安全规则或是模式匹配等方式来挖掘程序代码中存在的漏洞。这种技术是非常常见的,也是目前主流的商业工具中比较常用的一种手段,其一是算法相对比较成熟,其二是在检速率、可控性方面比较优异。
3.2 新型的检测手段
随着人工智能的发展,机器学习在代码检测的应用过程中变得越来越广泛。机器学习在代码检测过程中主要是对代码进行解析,把代码看成是一种文本,或者把代码进行程序切片,从而保留与代码漏洞检测相关的信息,把无关的代码信息全部剔除;采用词嵌入等技术将源代码的中间表示或是切片映射到具体的向量空间;此技术借助机器学习或深度学习模型中强大的大数据挖掘能力,学习源代码所蕴含的各类信息,包括控制依赖和数据依赖的信息,进而实现漏洞检测。可把传统静态检测方法中提取源代码污点变量的传播情况、净化函数的有效性等信息应用到机器学习中,丰富模型学习的知识空间,从而获得性能更好的检测模型。
机器学习在学术研究中可能有较多涉及,而在实际的生产过程中,其仅在几类特定的缺陷或某类特定的语言中效果甚佳。在大规模的语言还有海量的数据方面,由于数据及语言特性的限制,机器学习还处于研究中。目前,机器学习的商业化产品最典型的是美国一家公司所研发的DeepCode,但其一期的能力仅局限于规范的检测,对于这种深度的缺陷挖掘,其能力不够成熟。
3.3 基于代码检测分析技术目标不同的分类
代码检测分析技术的目标通常是分为两类:(1)检测目标为源代码。面向源代码的静态分析以程序的源代码作为输入,将其转换为某种特定形式的中间表示,也就是子法UR分析,构建语法树,再遍历语法树从而升迁成中间代码结构,基于该中间结构进行分析。因为此分析基于源代码进行,所以能够捕获丰富的代码结构、语义和逻辑等信息。常见的基于源代码分析的技术如Fortify,CheckMarx,Coverity等。(2)检测目标为二进制代码。面向二进制代码的静态分析是以经过反汇编等手段处理后的二进制代码作为输入,设法恢复程序信息,运用模式匹配或补丁对比等方式实现漏洞检测。相比源代码,二进制代码缺乏与代码相关的高级语义信息,以二进制代码形式表示的漏洞模式更为复杂,大部分的二进制带份检测分析以漏洞挖掘为主,制作此类成品化、批量显示的代码检测分析产品挑战性较高。目前,较为常见的就是美国国土安全局发布的Ghidra,这是一款用Java语言编写的代码检测工具,其功能非常强大。
3.4 代码检测分析技术的四大难点
3.4.1 前端解析
如果该代码依赖编译,那么只需做好符号信息捕获和提取。在编译过程中提取符号详细信息,虽然无需专门的前端处理器,但是存在相对应的挑战。如果编译过程中存在元素缺失,编译会立即失败,代码检测分析也随之失败。如果该代码为非编译类型,通过预编译的方式,采用容错机制,则不会遇到语法或者编译错误等障碍。预编译就是写一份前端解析,随着目标代码语法更新,需要升级调整预编译处理器。
3.4.2 编程语言的差异化
当前的研究大多針对用某一特定类型语言Java编写的软件程序展开。虽然已有的检测方法在特定的应用场景下表现不错,但是在对编程语言的多样性和迭代更新快等特性的适应性问题处理上仍存在不足。因此,改善漏洞分析方法的通用性,提高分析模型的适配能力是当前静态分析中的关键问题。
3.4.3 机器学习技术应用的合理性
机器学习技术在解决某些问题上表现突出,但是其对海量数据和计算机资源的高度需求是不容忽视的。对于基于学习的静态分析,由于漏洞数据集稀缺、数据集所包含漏洞样本的覆盖面缺乏广度,导致训练出的深度学习模型存在过拟合问题。在面对代码高速迭代更新的大环境时,模型的性能往往与实验结果相差较大。如何选择和构建合理的学习模型来理解和学习源代码表示的信息是基于学习的静态分析的关键问题。
3.4.4 误报和漏报的问题
源代码检测技术存在较高的误报和漏报,降低了检测的准确度。工具的实用性和有效性显著降低无法有效提高软件开发效率和软件质量。误报产生的原因:一方面受限于工具采用的算法技术,另一方面也存在部分主观因素,如缺陷模型的认可、代码上下文的关联。漏报往往是因为规则的缺失,工具可扩展性受限。这些都是技术人员在现在和未来需要解决的问题。在生产过程中,技术人员一般会通过调研、配置策略、预打靶摸底等方式,与客户达成共识,再通过缺陷类型的调整、增补、白名单、黑名单,不断地去保证漏报和误报在可控的范围内。
3.5 国产源代码检测的关键技术突破
随着“安全左移”的落实,对软件的成分分析、开源安全漏洞、开源许可合规分析的能力要求均上升到源代码片段级别,赋能企业安全合规能力,助力企业自主可控,保障软件供应链安全迫在眉睫。目前,可以通过市面上一些国产源代码检测产品,快速、准确地识别源代码中所使用到的第三方开源组件,护航企业网络安全。
以下是国产源代码检测几项关键技术的突破:(1)源代码结构化特征提取技术。此技术根据语法规范进行源代码文件的结构化处理,消除特定词法的噪声。(2)组件依赖分析技术。此技术通过研究不同包管理的包管理机制,进行组件信息特征提取与识别,通过组件坐标进行组件依赖的识别与定位。(3)安全漏洞关联分析技术。此技术构建安全漏洞与开源软件、开源组件间的知识图谱,依托关联分析技术,间接识别相关开源项目、开源组件的安全漏洞。(4)许可证、版权识别技术。此技术研究并分析许可证、版权声明的方式与特征,基于文本的规则匹配和特征识别技术分别识别源代码文件中的许可证和版权信息。(5)数据压缩及特征提取技术。此技术通过特征提取与压缩技术,从海量的源代码文件中进行代码片段级别的特征提取并自建索引,实现海量数据的存储与单机部署。(6)基于大数据的开源项目溯源技术。此技术通过大数据并行计算技术,对代码片段之间的海量匹配关系进行特征匹配、分组、合并、排序等相关操作,分别实现文件之间的同源分析以及开源项目的溯源分析。
4 结语
本文从发掘源代码安全的必要性出发,通过各项数据证明软件供应链的安全与源代码安全息息相关,重点阐述软件供应链的安全风险和不可控风险,以此为基础分析源代码检测的技术原理、技术难点及目前国产源代码的技术突破。坚决落实《中华人民共和国网络安全法》,实现“安全左移”,在源代码安全层面上,首先需要构建软件物料清单,有效识别软件供应链风险;其次需要建立开源软件应用规则,明确符合不同规则开源代码不同的使用地点,同时也要引导国内软件开发供应商、第三方机构高度重视软件供应链安全防护。通过对软件成分分析、开源安全分析、开源合规分析、威胁情报分析,赋能企业安全合规能力,助力企业自主可控,保障软件供应链安全。增强网络安全意识,筑牢信息网络安全防线,笔者有理由相信源代码检测分析技术在现在乃至未来,都是落实网络安全工作的一个重要研究领域。
参考文献
[1]邓枭,叶蔚,谢睿,等.基于深度学习的源代码缺陷检测研究综述[J].软件学报,2023(2):625-654.
[2]刘永志.一种基于语义切片的源代码缺陷检测系统的设计与实现[D].北京:北京大学,2022.
[3]李炯彬.源代码安全和质量缺陷静态检测技术研究[J].质量与认证,2021(8):66-68.
[4]王璐.软件源代码安全漏洞表示学习及检测技术研究与实现[D].北京:北京邮电大学,2021.
[5]张浩杰.基于深度学习的源代码漏洞检测技术研究[D].成都:电子科技大学,2021.
[6]毕艺菲.智能源代码漏洞检测技术应用研究[D].西安:西安电子科技大学,2021.
[7]李炯彬.源代码安全和质量缺陷静态检测技术研究[J].质量与认证,2021(8):66-68.
(编辑 王永超)
Source code detection and analysis technology and application
Sun Li英文作者
(Jiangsu Golden Shield Detection Technology Co., Ltd., Nanjing 210042, China)
Abstract: With the increase of the intensity of actual combat attack and defense drills in recent years and the strengthening of beating, source code detection technology is still an important problem to be solved so far. Different from bugs, vulnerabilities are more difficult to identify and repair. Starting from the necessity of source code security, security risk and uncontrollable risk of software supply chain security, this paper focuses on the technical principle and technical difficulties of source code detection, as well as the technical breakthrough of domestic source code at present, and puts forward constructive suggestions on the concrete implementation of “security left shift”.
Key words: source code security; network security; software supply chain security; source code detection technology; safe left shift
猜你喜欢
工会博览(2023年27期)2023-10-24 11:51:28
中国特种设备安全(2022年2期)2022-07-08 01:58:20
科学大众(中学)(2019年2期)2019-04-08 02:26:40
中国生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小学生必读(中年级版)(2018年4期)2018-07-05 06:00:48
湖北警官学院学报(2017年3期)2017-06-21 09:25:51
信息安全与通信保密(2016年3期)2016-08-23 01:23:32
互联网天地(2016年2期)2016-05-04 04:03:28
互联网天地(2016年1期)2016-05-04 04:03:20
