
基于YOLOv5和多尺度特征融合的学生行为研究
2023-06-25 15:31张小妮张真真
现代信息科技 2023年8期
关键词:目标检测
张小妮 张真真
摘 要:近年來,智慧教育发展迅速,与之相关的学生课堂行为识别随之得到重视。针对课堂环境复杂、学生目标密集、遮挡严重等问题,提出一种基于YOLOv5目标检测算法的学生课堂行为识别方法。首先,建立学生课堂行为数据集,为研究提供数据来源;其次,针对学生目标密集等问题提出一种多尺度特征融合的学生课堂行为识别方法。多次实验结果表明,所提方法有效地提高了学生课堂行为识别的精度。学生课堂行为的智能化识别为教师掌握学生学情、改进授课策略提供了重要依据。
关键词:YOLOv5;学生行为;行为识别;目标检测;特征融合
中图分类号:TP183 文献标识码:A 文章编号:2096-4706(2023)08-0096-04
Abstract: In recent years, with the rapid development of smart education, students' classroom behavior recognition related to it has received attention. Aiming at the problems of complex classroom environment, dense student targets, and severe occlusion, a method for student classroom behavior recognition based on YOLOv5 target detection algorithm is proposed. Firstly, establish a dataset of student classroom behavior to provide data sources for research; Secondly, a multiscale feature fusion method for student classroom behavior recognition is proposed to solve the problem of dense student targets. Several experimental results show that the proposed method effectively improves the accuracy of students' classroom behavior recognition. The intelligent identification of students' classroom behavior provides an important basis for teachers to master students' learning situation and improve teaching strategies.
Keywords: YOLOv5; student behavior; behavior recognition; object detection; feature fusion
0 引 言
将智能化行为识别应用于教育行业,能够有效解决早期课堂老师获取学生学情的不足,帮助老师提高授课效率,同时帮助学生及时发现学业中的问题,帮助家长随时掌握孩子上课情况。
目前学生行为识别方法大多基于深度学习技术,其中,闫兴亚等人[1]在Mobilenet V3的基础上提出了轻量级的姿态识别方法,提高了对人体行为的识别准确率。王泽杰等人[2]利用Open Pose算法提取学生姿态特征,融合YOLOv3算法提取学生行为的局部特征,最终成功识别出正坐、侧身、低头和举手四种学生课堂行为。董琪琪等人[3]提出一种改进的SSD算法,结合K-means聚类算法对数据进行聚类分析,最终在听讲、睡觉、举手、回答和写字五种学生课堂行为上提高了识别精度。林灿然等人[4]对学生的起立、端坐和举手三种行为进行研究,取得了较好的结果。柯斌等人[5]首先对课堂图像进行处理,利用Inception V3算法模型对学生六类课堂行为进行研究,认为模型对学生的单一动作识别率较高。
本文从学生课堂行为数据集入手,首先解决数据来源不足的问题,其次对模型提取学生行为特征的能力进行加强,构建一种有效的学生课堂行为识别模型,提高学生行为识别的准确率。
1 学生行为识别
1.1 学生行为识别数据集
在目标检测领域中,ImageNet[6]、PASCAL Visual Object Classes (VOC)[7]和Microsoft's Common Objects in Context (COCO)[8]等数据集都是众所周知的基准数据集,但这些数据集并没有包含行为的标签,不能为学生课堂行为的研究提供帮助,因此,我们构建了一个学生课堂行为数据集,为学生课堂行为的研究提供一个统一的衡量标准。
1.1.1 数据采集
数据的采集工作在河南某高校进行,拍摄的课堂视频均属于真实课堂中学生自发的行为,包括各个学生目标的行为状态变化。拍摄过程中,由于人数、科目、教室等因素的不同会对学生行为产生影响,我们对学生课堂进行多次拍摄,使得到的学生行为尽可能全面,并根据人数、遮挡情况、拍摄距离等因素将课堂场景划分为简单环境、一般环境和复杂环境。
1.1.2 数据处理
对采集到的学生课堂视频进行处理,截取具有代表性的高质量图像。由于行为具有连续性,相邻帧间的学生行为差异较小,为了得到不同的学生行为,每3秒采样一帧图像,最终得到1 903张学生课堂图像。
根据采集到的图像特点,对学生行为进行分类,最终将学生行为划分为抬头、低头、转头、玩手机、读写、睡觉、直立、趴着八个类别以及手机、书两种行为相关类别。
根据划分的学生课堂行为对采样图像进行标注,使用标注工具LabelImg生成模型可读的数据格式。标注工作完成后,共得到137 960个样本标签,按照3:1:1的比例把数据划分为训练集,验证集和测试集。其中,训练集里的数据用来模型训练,学习学生课堂行为特征;验证集里的数据用来模型调整参数;测试集里的数据用来测试学生课堂行为识别模型的泛化能力。图1显示了各学生课堂行为类别的样本数量,表1为数据集划分的详细说明。
1.2 多尺度特征融合
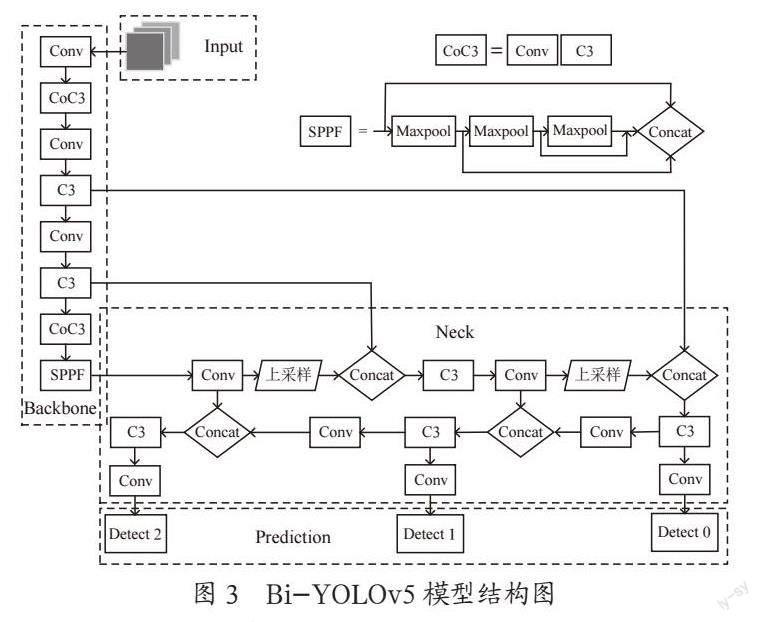
本文选用YOLOv5[9,10]目标检测模型作为基准模型,该模型由Input、Backbone、Neck、Prediction四部分组成,其中Input是输入端,负责向模型输入数据;Backbone主要负责特征的提取,Neck将特征进行融合,最后在Prediction进行目标预测。
在目标检测任务中,大多使用卷积神经网络通过逐层抽象的方式来提取目标特征。由于高层网络的感受野较大,语义信息表征能力强,但特征图的分辨率较低,几何信息的表征能力强;底层网络的感受野比较小,几何细节信息表征能力强,分辨率较高,但语义信息表征能力较弱。因此,将高层特征信息与底层特征信息进行融合,可以有效提高模型对目标的特征提取能力,所以,多尺度特征融合旨在对不同分辨率下的特征进行聚合,以获取更多信息。
在YOLOv5目标检测模型中,使用PANet网络进行特征融合,但该网络把所有特征对结果的影响视为同等重要,不能有效融合各类特征,大大降低了学生课堂行为识别的精度。不同的输入具有不同的分辨率,对融合的输出特征做出的贡献也不相同,为了解决这一问题,本文提出了一种双向特征金字塔网络(Bidirectional Feature Pyramid Network, BiFPN),引入可学习的权重来学习不同输入特征的重要性,同时反复应用自顶向下和自底向上的多尺度特征融合,提高模型对学生行为特征的提取能力和融合能力。图2分别为PANet网络和BiFPN网络的结构图。
相比于PANet,BiFPN有以下特点和优势:1)删除只有一个输入边的节点。一个节点只有一个输入边,对于融合不同学生行为特征的贡献较小。2)处于同一级别的两个节点,额外添加一条从原始输入到输出节点的边,在不增加计算成本的情况下融合更多特征。3)将每个双向(自顶向下和自定向上)路径视为一个特征网络层,并多次重复同一层,便于更高级的特征融合。该网络能够方便、快速地进行多尺度特征融合,同时可以对主干网络、特征网络以及最后的预测网络的分辨率、深度和宽度进行均匀缩放,以一种更加直观和有原则的方式优化多尺度特征融合。
1.3 学生行为识别模型
在学生课堂行为识别模型构建的过程中,首先将课堂视频处理为模型需要的数据格式,然后利用卷积神经网络提取学生行为特征,接着用双向特征金字塔网络融合高层特征,然后用目标分类网络计算学生目标,边框回归网络计算学生目标位置,最后通过分类学习实现学生行为识别。本文将BiFPN与目标检测模型YOLOv5进行结合,构建新的学生行为识别模型——Bi-YOLOv5,利用YOLOv5快速检测的特点和优势,在保证对学生行为进行实时检测的同时,提高模型在复杂环境下对目标的特征的提取能力。图3为Bi-YOLOv5模型结构图。
2 实验结果
2.1 实验环境
2.1.1 实验环境
所有实验均在Windows 10操作系统上进行,编程语言为Python 3.9,框架技术为PyTorch,加速环境为CUDA 11.3,GPU为NVIDIA GeForce RTX 3060,顯存大小为6 GB。
2.1.2 模型参数
模型参数不同,最终的结果也会有一定差距,为了使学生行为识别模型对学生的课堂行为具有较好的识别率,我们在其他参数相同的条件下对各项参数逐一进行尝试,以寻求效果较好的参数组合。综合考虑实验硬件配置和模型效果,最终模型参数为:batchsize为16,学习率大小为0.001,权重衰减为0.000 5,Adam优化器。
2.1.3 实验步骤
具体实验步骤如下:
1)采集学生的10类典型课堂行为。
2)对数据进行处理,构建数据集。
3)将BiFPN网络与YOLOv5融合,构建新的模型——Bi-YOLOv5。
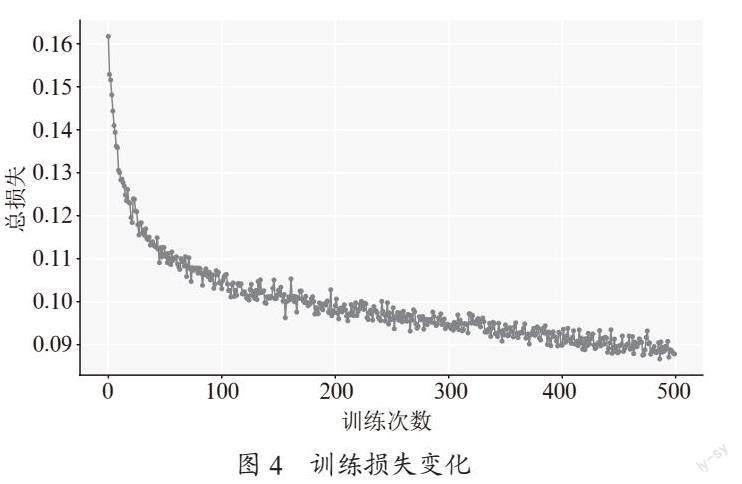
4)使用训练集和验证集进行模型训练,使用余弦退火算法更新学习率,设置训练轮数为500,训练过程中的损失函数变化如图4所示。
5)将训练好的模型对测试数据进行测试,评估模型性能。
2.2 实验结果和分析
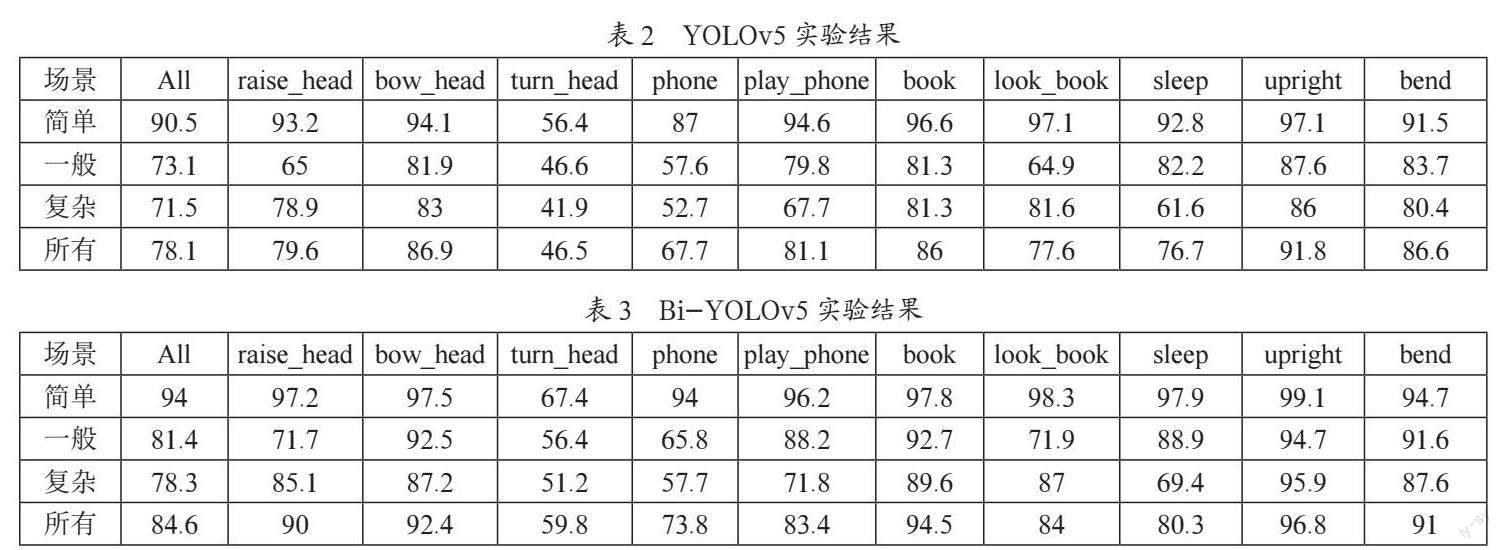
本文探索了改进前后的模型在不同教室环境下对学生课堂行为识别精度的影响,分别在简单环境、一般环境和复杂环境下对学生行为进行多次实验,在相同参数下对YOLOv5和Bi-YOLOv5的结果进行对比,YOLOv5原模型在数据集上的实验结果如表2所示,Bi-YOLOv5改进模型的实验结果如表3所示(简单代表简单环境,一般代表一般环境,复杂代表复杂环境,所有代表实验的所有数据)。其中,All对应所有类别精度的平均精度。为降低结果的偶然性和精度偏差,每组实验结果均取10次相同实验的平均精度。
从实验结果可以看出,随着课堂环境复杂程度的增加,YOLOv5和Bi-YOLOv5对学生课堂行为的检测精度逐渐降低。YOLOv5在简单环境、一般环境和复杂环境的精度分别为90.5%、73.1%和71.5%,相同条件下,改进后的模型比原模型的精度分别高了3.5%、7.3%和6.8%。对于整个数据集而言,YOLOv5达到了78.1%的精度,Bi-YOLOv5达到了84.6%的检测精度,比原模型高出6.5个百分点。
3 结 论
本文首先创建了学生课堂行为数据集,在目标检测模型YOLOv5的基础上,针对课堂环境复杂、人数多、遮挡严重等问题导致学生课堂行为识别率较低的问题,提出了一种融合双向特征金字塔网络的模型,该模型能有效提取学生课堂行为特征,使每类学生课堂行为的识别精度均得到有效提升。后期工作将会围绕增加学生课堂行为类别展开工作,进一步测试所提方法的有效性。
参考文献:
[1] 闫兴亚,匡娅茜,白光睿,等.基于深度学习的学生课堂行为识别方法 [J/OL].计算机工程,2022:1-8[2022-11-03].https://www.cnki.net/KCMS/detail/detail.aspx?dbcode=CAPJ&dbname=CAPJLAST&filename=JSJC20221012000&v=MTIzMTY2amg0VEF6bHEyQTBmTFQ3UjdxZFpPWnNGaS9sVWIvQkkxND1MejdCYmJHNEhOUE5yNDVIWk9zUFl3azd2QkFT.
[2] 王泽杰,沈超敏,赵春,等.融合人体姿态估计和目标检测的学生课堂行为识别 [J].华东师范大学学报:自然科学版,2022(2):55-66.
[3] 董琪琪,刘剑飞,郝禄国,等.基于改进SSD算法的学生课堂行为状态识别 [J].计算机工程与设计,2021,42(10):2924-2930.
[4] 林灿然.基于深度学习的课堂学生行为识别技术研究与分析系统设计 [D].广州:广东工业大学,2020.
[5] 柯斌,杨思林,曾睿,等.基于Inception V3的高校学生课堂行为识别研究 [J].电脑知识与技术,2021,17(6):13-15+29.
[6] KUZNETSOVA A,ROM H,ALLDRIN N,et al. The Open Images Dataset V4:Unified image classification,object detection,and visual relationship detection at scale [J].International Journal of Computer Vision,2020,128(7):1956-1981.
[7] THAKURDESAI N,TRIPATHI A,BUTANI D,et al. Vision:A Deep Learning Approach to provide walking assistance to the visually impaired [J/OL].arXiv:1911.08739 [cs.CV].[2022-11-03].https://arxiv.org/abs/1911.08739.
[8] LIN T Y,MAIRE M,BELONGIE S,et al. Microsoft COCO:Common Objects in Context [C]//Computer Vision–ECCV 2014.Zurich:Springer,2014:740-755.
[9] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:779-788.
[10] glenn-jocher. ultralytics/yolov5 [EB/OL].[2022-11-03].https://github.com/ultralytics/YOLOv5.
作者簡介:张小妮(1996—),女,汉族,河南周口人,硕士研究生在读,研究方向:大数据与云计算。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
