
基于ConvNeXt网络的交通标志识别算法
2023-06-25 12:28:14李伟娟千凯琦付昱伍晨俊刘保山
现代信息科技 2023年8期
李伟娟 千凯琦 付昱 伍晨俊 刘保山

摘 要:交通标志的识别对于自动驾驶与智能导航具有重要意义,针对已有深度学习网络识别率不高的问题,提出一种基于ConvNeXt网络模型的交通标志智能识别算法。该网络以纯粹的CNN模型为特点,具有更优的图像分类及检测分割任务的性能。文中使用GTSRB数据集进行实验,与MobileNet、ResNet等网络进行对比测试,测试结果表明,ConvNeXt网络收敛速度最快并且稳定,最终交通标志的识别准确率达99%以上。实验结果表明,该算法准确率高,具有一定的工程应用意义。
关键词:ConvNeXt网络;交通标志识别;CNN模型
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)08-0075-04
Abstract: Traffic sign recognition is of great significance for automatic driving and intelligent navigation, and an intelligent recognition algorithm of traffic signs based on ConvNeXt network model is proposed to solve the problem that the recognition rate of existing deep learning networks is not high. The network features a pure CNN model with better performance for image classification and detection segmentation tasks. In this paper, GTSRB data sets are used for experiments and compared with MobileNet, ResNet, and other networks. The test results show that the ConvNeXt network has the fastest convergence speed and is stable, and the final traffic sign recognition accuracy rate reaches over 99%. Experimental results show that the algorithm has high accuracy and has certain engineering application significance.
Keywords: ConvNeXt network; traffic sign recognition; CNN model
0 引 言
交通标志的检测识别是视觉辅助导航领域不可或缺的一部分,视障人群需要借助外部工具感知周围复杂的环境以及时了解周围的指示灯、方向牌、机动车道标志、人行道标志等交通标志,通过交通标志的识别可以为视障人群提供交通指引,从而方便其出行。在现实场景中,交通标志在城市交通中易受恶劣天气、交通拥堵等影响而导致识别率低的问题[1]不可避免。因此,对于如何构建一个具有应变复杂场景以及恶劣天气,同时具有高准确率的实时检测交通标志的系统具有重大的研究意义。
目前已经有很多针对交通标志的目标识别算法,比如宋青松等[2]提出一种聚类残差单次多盒检测算法(Single Shot multibox Detector, SSD),具有较好的交通标志识别效果;Cao等[3]在LeNet-5卷积神经网络模型基础上,采用Gabor作为初始核,选择Adam作为优化算法[4],能够以较高精度对不同交通标志进行识别;Girshick等[5]提出了基于候选区域的RCNN(Regions with convolutional neural network features)算法,能夠提取多层信息,精准定位目标[6]。虽然,当前的算法在交通目标识别方向取得了一定的成果,但由于或者是减少了目标框的回归,导致检测结果有较大的定位误差,存在检测精度上的劣势。或者是模型参数量与计算量过大,推理时间较长,不满足交通标志识别的实时性要求[7]。因此,为更精准快速在恶劣环境、实时交通场景中识别出目标,本文提出了一种基于卷积神经网络的交通目标识别系统,能够满足实时性、准确性较高的需求的同时,更具有鲁棒性。
1 相关工作
1.1 Faster RCNN算法
该算法主要是通过四个部分来实现目标检测的,主要包括用来提取特征的体征提取网络、判断目标是否存在以及进行预处理的区域候选网络、将上一级网络挑选的特征图提取出对应的语义信息用于送入下一级用于分类任务的兴趣域池化网络以及最后进行计算出具体类别的分类网络。该算法主要是基于卷积神经网络的一个端到端的目标检测模型。
1.2 VGGNet算法
该算法使用多个小卷积核构成的卷积层代替较大的卷积层,两个3×3卷积核的堆叠相当于5×5卷积核的视野,三个3×3卷积核的堆叠相当于7×7卷积核的视野。这种方式既减少了参数,同时也相当于进行了更多的非线性映射,增加了拟合能力,且更多的卷积核使得特征图的通道数增多,特征提取更全面。
1.3 MobileNet算法
该算法的基本单元是深度级可分离卷积,本质为一种可分解的卷积操作,其可以分解为两个更小的操作深度可分离卷积(depthwise convolution)和逐点卷积(pointwise convolution)。具体过程为首先采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,整体效果相当于标准卷积,但是大大减少计算量和模型参数量。保持模型性能的前提下降低模型大小、提升模型速度。
1.4 ResNet算法
该算法主要模块使用了残差连接的子模块,从而缓解了网络层数的加深会使梯度消失或者梯度爆炸造成的影响更加明显[8]的难题。该算法主要是应用了添加恒等映射,使得在残差模块中,输入数据可以通过残差连接更迅速地向前传播。如图1所示。
1.5 ConvNeXt算法
近年来,因为深度学习中Transformer网络的自注意力机制在计算机视觉中大量使用,并且效果比一般CNN算法更佳,因此,文献[9]提出了ConvNeXt网络,证明CNN网络依然具有潜力。ResNet是CNN中非常具有影响力的一种结构,如图2所示,本文的ConvNeXt网络是在ResNet50网络的基础上做出改进。与传统的残差神经网络不同,如图3所示,ConvNeXt模块采用的是两头细中间粗的结构,在输入时通道数为96,中间层通道数为384,最后输出时通道数不变仍为96,实现了整个网络在识别精度上明显优于ResNet50网络。
注意力机制作为捕捉特征图显著特征、提高卷积神经网络特征提取能力的新方法[10],其使用越来越频繁,在2020年提出了一种仅使用纯卷积的ConvNeXt网络,该网络主要是学习残差连接网络以及移动窗口自注意力网络进而改进出的纯卷积的神经网络。整个网络的实现全部使用现有的技术和方法,没有创新结构,但是使用先用架构模仿搭建移动窗口自注意力网络搭建出了更优化的模型。整个网络达到了更优的结果。本文提出的交通目标检测网络是以该纯卷积的神经网络为基础实现的。
如图4所示,网络首先对输入图像做非重叠卷积,然后送入4个ConvNeXt Block,其通道数Dim分别为96、192、384、768,逐次翻倍,并且每个模块后带一个下采样,最后通过全局池化和全连接输出识别结果。
2 特征提取ConvNext网络
2.1 非重叠卷积策略
一般的卷积神经网络都是由一个卷积核和最大池化构成的下采样模块,但基于移动窗口自注意力网络中直接采用一个很大的并且各个特征提取窗口不重叠的卷积核,本网络同样选择采用以卷积核大小为4步长为4的卷积核用于初始下采样模块。
2.2 数据标准化
在研究交通标志识别网络时,对于数据的正则化一般会有批归一化和层归一化两种方式,这两种方式都是为了防止出现梯度消失或梯度爆炸现象使得网络当前隐藏层的稳定性下降。通常在自然语言处理领域,一般采用的是层归一化方式,在利用卷积神经网络做特征提取任务时,会采用批归一化的方式,但是在本网络中通过对比研究发现,采用层归一化结果优于批归一化结果。
2.3 减少归一化层
ResNet50网络使用了较多的归一化层,进行数据的归一化,缩小数据偏差值,但是移动窗口自注意力网络使用较少的归一化层,因此整个网络使用了较少的归一化层,仅仅在深度可分离卷积层后使用归一化层,使得整个网络在准确度上得到了优化。
2.4 下采样层
对于卷积神经网络而言,下采样层的作用就是降低整个网络的计算量,同时能够防止出现过拟合的问题以及可以增大感受野,从而使后面的卷积层可以学习到更多的信息。本特征提取网络采用了单独的下采样层,该下采样层是通过在层归一化之后添加一个卷积核大小为2,步长为2的卷积层构成的,从而实现降低特征图大小。如图5所示。
2.5 深度可分离卷积
为了降低计算量和参数量,本网络使用了深度可分离卷积。深度可分离卷积主要是通过保持输入和输出的维度相同,并且卷积在通道和空间维度上的可分离实现计算量的减少以及空间内信息的提取。通过卷积核与通道数量相等可以实现当输入一个三通道的RGB图片时,经过卷积运算之后得到对应通道的三个特征图。
2.6 激活函数
在卷积神经网络中,为了给整个网络添加非线性产生强大的拟合能力,通常会增加激活函数,一般使用ReLU函数(Rectified Linear Unit),而在本网络使用的是高斯误差线性单元——GELU函数(Gaussian Error Linear Unit),与常见的激活函数不同,高斯误差线性单元由于其在零点可微性,使得可以处理零均值数据以及整个网络性能更优化。
2.7 翻转瓶颈模块
与一般的瓶颈模块不同,为了与移动窗口自注意力网络中多层感知机模块相同,本网络采用了翻转的瓶颈结构,也就是中间粗两头细,通过翻转瓶颈结构实现本网络精度的提升。
3 数据集
本网络采用的是GTSRB(The German Traffic Sign Recognition Benchmark)数据集,属于德国交通标志数据集,数据集一共分为了43类交通标志,其中一共有训练集39 209张,测试集12 630张,图片大小范围在15×15到250×250像素之间[11]。由于实际环境中标志会受恶劣天气以及遮挡物的影響而导致实时检测交通标志类别时难度上升。在提供的样本中考虑到实际情况的不同提供的样本大小以及标志的区域大小都不相同,能够更好地适应实际情况。如图6所示。
4 交通目标识别结果
4.1 实验环境介绍
本次实验所使用的硬件设备环境CPU为AMD Ryzen 5800X 8-Core Processor,显卡为NVIDIA GeForce RTX 3080 Ti,使用Python 3.7为编程语言,使用交叉熵损失函数。本实验过程采用学习率为0.001进行训练,学习率设置思路来源于文献[12]。并且在实验数据处理阶段由于样本大小不一致以及并非正方形,将输入数据进行了大小重整为40×40,并经过了中心裁剪为32的正方形再进行训练。
4.2 实验结果
4.2.1 评价指标
在进行图像分类与识别任务时,大多数采用的是测试时的准确率来作为指标,进行模型的效果评价。本文也采用该评价指标作为模型效果判断,并且一般情况下,实验过程中该评价指标会随着迭代次数的增加进行增长,数值越大模型效果越好。
4.2.2 实验结果及分析
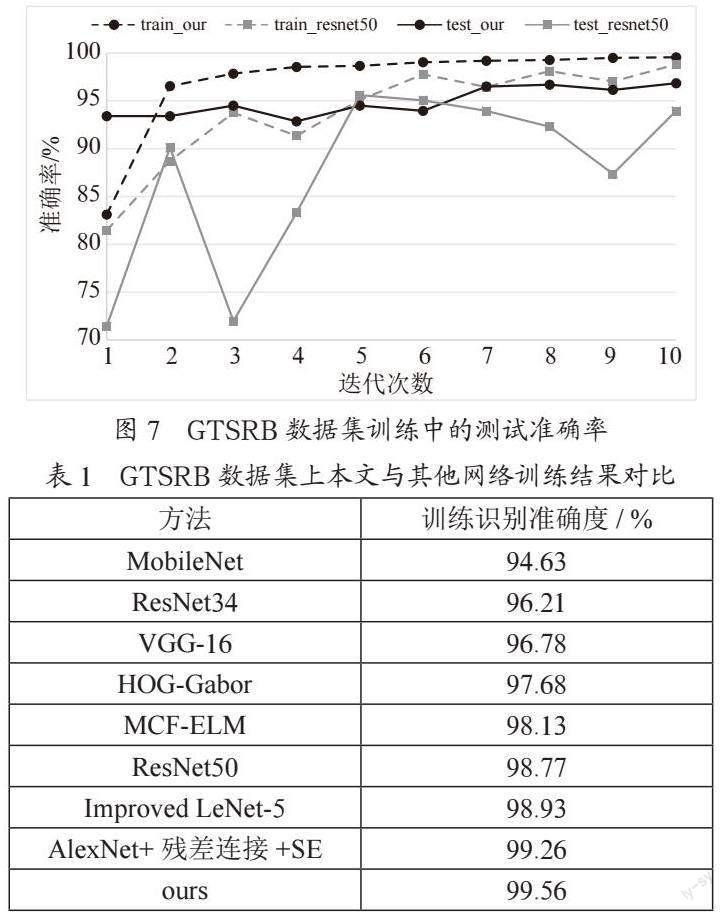
为了验证本文网络的性能,在GTSRB数据集上训练过程中,每一次迭代结束后都进行一次验证测试,观察网络模型的收敛速度。训练与测试的数据如图7所示。
图中虚线是训练准确率,实线是测试准确率,黑色是本文网络数据,橙色是ResNet50网络数据。从图中可知,本文网络迭代速率更快,第一轮训练后准确率就达到93%,高于ResNet的71%,并且稳定上升,最终保持在96.70%附近;而ResNet50网络最终识别的准确度保持在95.00%左右,并且有震荡起伏。通过测试结果可看出,本文网络训练时收敛速度更快,并且更加稳定,最终的准确率也更高。
4.2.3 与其他网络模型对比实验
為了检验本网络对于交通标志识别的准确率,选用了常见的ResNet、MobileNet等网络模型进行对比,在相同的GTSRB数据集下进行训练得到结果如表1所示。
通过表中数据可以得出,本网络数据集上训练的准确度达到99.56%,明显优于其他网络。
5 结 论
本文提出的网络是基于一个纯卷积的神经网络Convnext的交通标志分类识别网络,主要是在ResNet50网络和Swim-Transformer(Shifted windows Transformer)网络的基础上作出改进,并且与之相比,本网络引入了不重叠卷积结构、倒置瓶颈结构、层归一化结构以及深度可分离卷积结构等实现了网络计算量和参数量的减少以及分类准确度和速度的提升。研究表明,本网络可以实现较好准确率的实时识别交通标志为视障人群提供交通指引。接下来的工作主要是如何在于如何让本网络实现能够在复杂的环境下快速检测出交通标志并将其较为准确的识别出来。
参考文献:
[1] 郭继峰,孙文博,庞志奇,等.一种改进YOLOv4的交通标志识别算法 [J].小型微型计算机系统,2022,43(7):1471-1476.
[2] 宋青松,王兴莉,张超,等.用于交通标志检测的窗口大小聚类残差SSD模型 [J].湖南大学学报:自然科学版,2019,46(10):133-140.
[3] CAO J W,SONG C X,PENG S L,et al. Improved Traffic Sign Detection and Recognition Algorithm for Intelligent Vehicles [J].Sensors,2019,19(18):4021-4021.
[4] 林轶,陈琳,王国鹏,等.改进的YOLOv3交通标志识别算法 [J].科学技术与工程,2022,22(27):12030-12037.
[5] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[6] 郭朦,陈紫强,邓鑫,等.基于YOLOv5l和ViT的交通标志检测识别方法 [J].科学技术与工程,2022,22(27):12038-12044.
[7] 徐兢成,王丽华.基于AlexNet网络的交通标志识别方法 [J].无线电工程,2022,52(3):470-475.
[8] 张佳达,许学斌,路龙宾,等.基于深度残差网络的交通标志识别方法研究 [J].计算机仿真,2022,39(1):143-147.
[9] LIU Z ,MAO H Z,WU C Y,et al. A ConvNet for the 2020s [J/OL].arXiv:2201.03545 [cs.CV].[2022-10-02].https://arxiv.org/abs/2201.03545.
[10] 蒋博文.基于改进ResNet模型的图像分类方法 [J].现代信息科技,2022,6(12):83-85.
[11] 陈立潮,张倩茹,曹建芳,等.复杂场景下基于复合胶囊网络的交通标志识别 [J].计算机工程与设计,2021,42(9):2627-2633.
[12] 韩建鹏,王春生,巩梨.基于优化卷积神经网络的交通标志识别算法研究 [J].农业装备与车辆工程,2022,60(5):33-38.
作者简介:李伟娟(2001—),女,汉族,山东菏泽人,本科在读,研究方向:通信工程;千凯琦(2002—),男,汉族,河南焦作人,本科在读,研究方向:通信工程。
