
Clementine数据挖掘工具在大学生心理健康预测中的应用
2023-06-25 07:42薄启欣高学东潘莹雪
现代信息科技 2023年7期
薄启欣 高学东 潘莹雪
摘 要:利用C5.0算法构建大学生心理健康预测的决策树模型和分类规则,利用SPSS Clementine数据挖掘工具对大学生心理卫生测评数据进行分析,以此对大学生心理健康状态进行了预测。研究发现:大学生的心理健康普遍存在一定的问题,应针对不同症状采取不同的干预措施;强迫症状、精神病性、抑郁、焦虑和人际关系敏感五个属性在大学生心理健康问题中占有较大的比重。
关键词:数据挖掘;SPSS Clementine;决策树;C5.0算法;心理健康预测
中图分类号:TP39 文献标识码:A 文章编号:2096-4706(2023)07-0127-04
Abstract: Using C5.0 algorithm to construct a decision tree model and classification rules for college students' mental health prediction, SPSS Clementine data mining tool is used to analyze college students' mental health evaluation data, so that the mental health status of college students is predicted. The study found that there are some common problems in college students' mental health, and different interventions should be taken for different symptoms; The five attributes of obsessive compulsive symptoms, psychosis, depression, anxiety, and interpersonal sensitivity account for a large proportion in college students' mental health problems.
Keywords: data mining; SPSS Clementine; decision tree; C5.0 algorithm; mental health prediction
0 引 言
随着我国高等教育由精英教育向大众化教育的不断转变,以及生活节奏的不断加快和社会竞争的日益激烈,大学生群体面临着学业、生活、情感、就业等压力明显增大,由此产生的心理健康问题也日益突出,一项针对全国12.6万名大学生的调查表明,大学生中有心理健康问题的约占20.3%[1]。大学阶段是人生的重要转折时期,大学生既需要适应生理上的变化,也面临着心理上的逐步发展和成熟[2]。大学生中存在焦虑、抑郁、强迫、人格障碍等心理问题或心理障碍的约占16%~30%[3]。《2020中国大学生健康调查报告》显示,仅有近1/3的大学生认为自己心理健康状态非常好。大量的调查发现,大学生的心理健康不但影响着大学生自身的健康成长,而且也关系着校园的安全稳定和社会的和谐发展。2018年,中共教育部党组印发的《高等学校学生心理健康教育指导纲要》明确提出,心理健康教育是思想政治工作“十大育人体系”之一[4]。近年来,因心理健康问题引发的大学生自杀、恶性犯罪等事件逐年增多,大学生心理健康问题也因此成为全社会普遍关注的焦点。
1 决策树算法及数据挖掘工具SPSS Clementine
1.1 决策树算法
数据挖掘是指从大量的、随机的实际应用数据中提取隐藏的有价值的信息的过程,它是一种深层次的数据分析方法[5],也是当前较为流行的数据分析技术之一,能够分析处理海量数据,目前在教育、商业等诸多领域都有所应用。决策树(Decision Tree)算法是数据挖掘应用中一种典型的解决数据分类任务的方法。它由决策结点、分支和叶子结点组成,由于其分析结果的展示方式类似于流程圖的树结构而得名。按照研究问题的不同,决策树可分为回归决策树和分类决策树,二者的主要区别是训练样本数据的类别属性的值是否是连续的。如果类别属性的值是连续的,那么用该样本数据训练得到的决策树则为回归决策树,否则则为分类决策树[6,7]。本研究主要是解决对大学生按心理健康进行分类的问题,而决策树算法是数据挖掘研究中应用广泛且解决分类问题最有效的方法[8,9]。鉴于大学生的心理特征相对固定,且不需要进行实时分类,因此在大学生心理健康预测中采用决策树算法比较适合,常用的决策树算法有ID3、C4.5、C5.0、CHAID算法等。
1.2 SPSS Clementine平台
SPSS Clementine是ISL(Integral Solutions Limited)公司开发的一个开放式数据挖掘工具平台,曾两次获得英国政府SMART创新奖。该工具平台完全遵循“跨行业数据挖掘过程标准”(CRISP-DM),其具有界面友好、操作简单、分析速度快、结果直观易懂等特点[10]。操作使用Clementine的目标:建立数据流,即根据数据挖掘的实际需要,选择节点,依次连接节点建立数据流,不断修改和调整流中节点的参数,执行数据流,最终完成数据挖掘任务[11]。该软件具有分类、预测、关联等数据分析方法,本研究主要分析经典的C5.0决策树算法在大学生心理健康预测中的应用。
2 Clementine在大学生心理健康预测中的应用
本研究的数据来源于某高校3 490名学生入校后所做的大学生症状自评量表(SCL-90)测试数据,被测学生涵盖了工、理、管、文、经、法等多学科专业。症状自评量表(SCL-90)共有90个自我评定项目,可划分为10个因子:躯体化、强迫症状、抑郁、焦虑、人际关系敏感、敌对、恐怖、偏执、精神病性、睡眠饮食[12,13]。本研究利用Clementine 12中的C5.0算法对大学生的心理健康测试数据进行数据挖掘,通过构建决策树并形成分类规则,为高校心理咨询中心或学生管理人员提供决策支持信息,使得大学生心理健康教育与辅导工作更具有针对性和方向性。
2.1 模型数据流的建立
经过数据预处理,共丢弃症状自评量表数据300條,实际有效的症状自评量表数据3 190条。因此,所采集的数据集中共有3 190条有效记录,每条有效记录代表着每一位被测试者的10项因子得分及整体的心理健康状况总分。再经过数据转换,预处理后得到的研究所用数据存放在文件某高校本科生SCL-90预处理数据.csv中。文件一共包含3 190个样本,10个属性。只有在Clementine中建立挖掘数据流,经过执行数据流后方可生成决策树模型。
2.2 模型的建立及评估
2.2.1 模型的建立
根据所建立的模型数据流,通过“执行”操作,即可生成决策树模型,并显示在管理器窗口的“模型”标签下。右击该模型,在快捷菜单中选择“浏览”命令,即可查看生成的决策树。通过“查看器”标签,则可以树的形式来显示决策树。将“C5.0综合症状”节点中的输出类型改为规则集,其余设置的信息不变,共生成了5个用于症状A的规则,12个用于症状B的规则,9个用于症状C规则,3个用于症状D的规则,而这些规则将为今后高校心理咨询师、辅导员等人员提供更加简单、易于理解的大学生心理健康状况的预测。
2.2.2 模型的评估
对预测模型进行评价可以从两个方面进行,即对模型预测准确率的分析和对模型增益、响应等方面的评估。此时,在数据流的“输出”标签下选择“分析”节点,在“图形”标签下选择“评估”节点,并分别与“C5.0综合症状”模型节点建立连接。
2.2.2.1 模型预测准确率分析
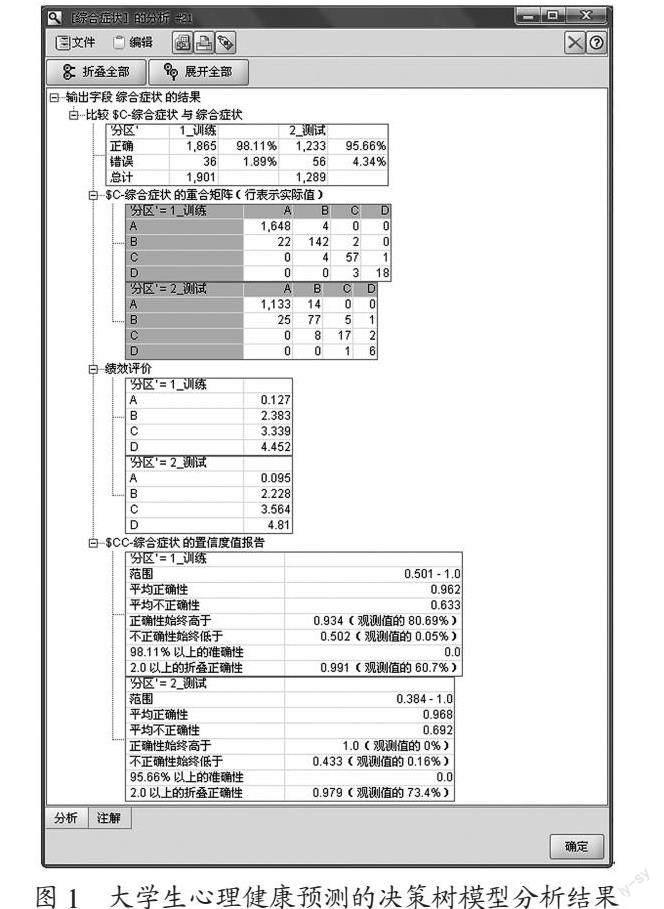
首先,需要对“分析”节点的属性中符合矩阵、绩效评价、置信度图等信息进行设置。其次,通过“执行”操作后,得到了分别以训练集和测试集对模型的预测准确率和置信度的分析结果,如图1所示。
由图1可以得出,训练集和测度集的分类准确率均超过了95%,表明整体的分析结果较为理想,其他结论如下:
1)训练集。由图1可知,训练集的分类准确率达到了98.11%,错误率为1.89%;平均正确性置信度为0.962,平均不正确性置信度为0.633;始终正确的置信度高于0.934,精确度是训练集2倍的置信度为0.991。
2)测试集。由图可知,测试集的分类准确率达到了95.66%,错误率为4.34%;平均正确性置信度为0.968,平均不正确性置信度为0.692;始终正确的置信度高于1.0,精确度是测试集2倍的置信度为0.979。虽然,测试集的分类准确率较训练集的分类准确率低2.45%,但是整体的分类准确率均能达到预期目标,对实际中的预测应用已经较为理想。
2.2.2.2 模型预测的评估分析
评估图展示了大学生心理健康预测模型在预测某些结果时是如何执行的,是以预测值和对预测的可信度为基础来为记录分类,将记录划分为同样大小的组,然后由高到低地为每个分位点绘制商业标准的变量值。具体如下:
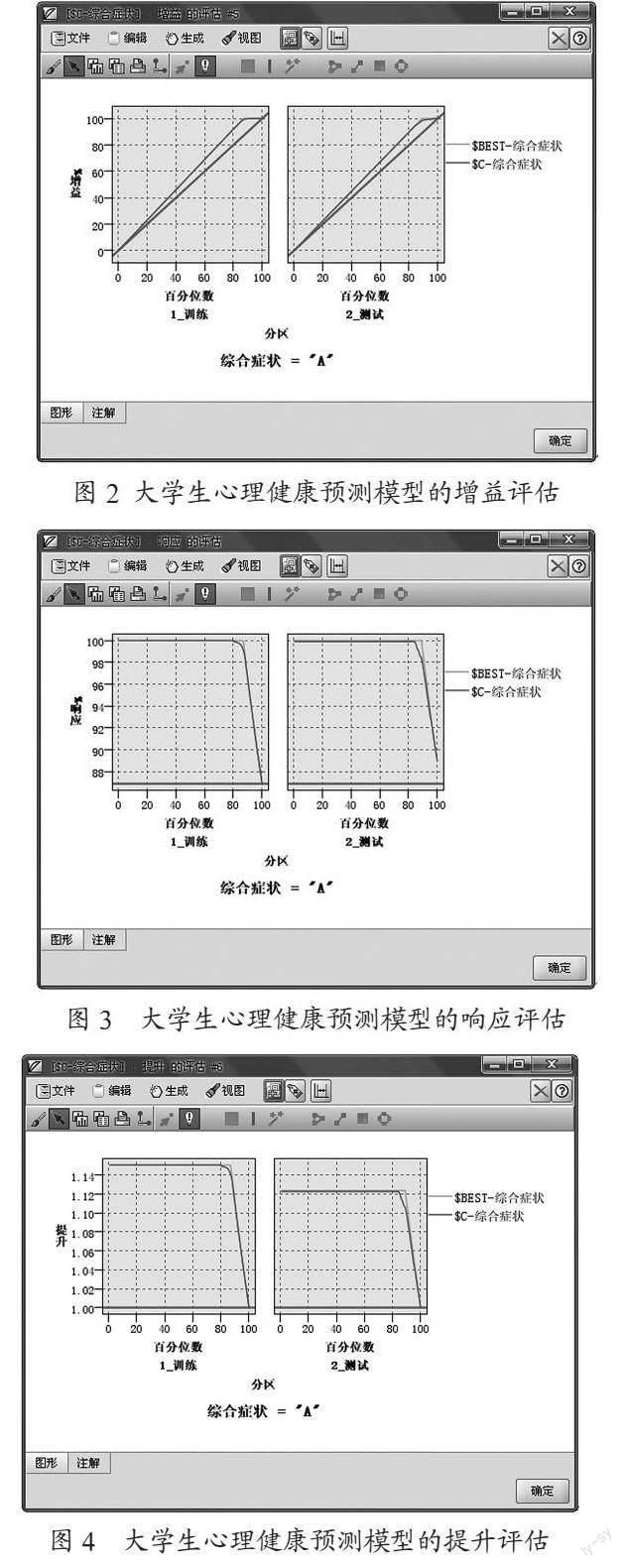
1)大学生心理健康预测模型的增益评估。如图2所示,增益被定义为每个分位点上的成功记录数占总的成功记录数的百分比。从大学生心理健康预测模型的增益评估结果可知,训练集的“$BEST-综合症状”曲线和“$C-综合症状”曲线完全吻合,均是从前部分的0%陡然提升至100%,后部分保持水平。而测试集“$BEST-综合症状”曲线和“$C-综合症状”曲线基本吻合,主要体现在前部分“$C-综合症状”曲线较“$BEST-综合症状”曲线更快达到了100%,后部分均保持水平。因此,训练集和测试集的增益曲线均与理想曲线吻合,整体看来大学生心理健康预测模型取得了较大的增益效果。
2)大学生心理健康预测模型的响应评估。如图3所示,响应就是分位点上的成功数占分位点上记录数的百分比。从大学生心理健康预测模型的响应评估结果可知,训练集的“$BEST-综合症状”曲线和“$C-综合症状”曲线基本吻合,均是从前部分的100%开始保持水平,后部分又陡然下降至某一百分数。虽然,“$C-综合症状”曲线开始下降时的百分位数较“$BEST-综合症状”曲线开始下降时的百分位数大,但是很快又与理想模型的响应曲线重合。而测试集“$BEST-综合症状”曲线和“$C-综合症状”曲线也基本吻合,主要有差异体现在“$BEST-综合症状”曲线开始下降时的百分位数较“$C-综合症状”曲线开始下降时的百分位数小,并且出现了迅速下降的情况。此外,测试集“$BEST-综合症状”曲线和“$C-综合症状”曲线降至最低点时所对应的响应百分数高于训练集。因此,训练集和测试集的增益曲线均与理想曲线基本吻合,整体看来大学生心理健康预测模型取得了较大的响应效果。
3)大学生心理健康预测模型的提升评估。如图4所示,提升是将每个分位点上的成功数占记录的百分比与训练数据中成功数所占百分比做比较。从大学生心理健康预测模型的提升评估结果可知,训练集的“$BEST-综合症状”曲线和“$C-综合症状”曲线基本吻合,起点约为1.15,均是以高于1.0为起点先保持水平,后又迅速下降至1.0。虽然,“$C-综合症状”曲线开始下降时的百分位数较“$BEST-综合症状”曲线开始下降时的百分位数大,但是很快又与理想模型的响应曲线重合。而测试集“$BEST-综合症状”曲线和“$C-综合症状”曲线也基本吻合,主要有差异体现在起点低于训练集,起点值约为1.12,“$BEST-综合症状”曲线开始下降时的百分位数较“$C-综合症状”曲线开始下降时的百分位数小,并且出现了迅速下降的情况。因此,训练集和测试集的提升曲线均与理想曲线基本吻合,被评估模型在两个分区数据集中都符合“$BEST-综合症状”理想提升曲线的规律。虽然,训练集与测试集存在一定的差异,但从整体来看,大学生心理健康预测模型取得了较大的提升效果。
2.3 模型规则提取
本研究采用C5.0决策树算法对大学生心理健康状况进行数据挖掘,并得到了大学生心理健康预测模型和分类规则,根据分类规则集提取以下一些重要的规则:在大学生心理健康预测模型的构建过程中,强迫症状、精神病性、抑郁、焦虑和人际关系敏感五个属性在大学生心理健康问题中起比较重要的决定作用。当学生的抑郁的属性达到中度层次时,学生的心理症状可能表现为很明显或比较严重,这就需要及时进行心理干预。当学生的抑郁的属性处于轻度层次时,精神病性、人际关系敏感和焦虑对学生心理症状表现起一定的决定作用,在这种情况下,当精神病性处于中度层次时,学生可能存在很明显或是比较严重的心理症状;当精神病性处于轻度层次时,人际关系敏感属性的取值对最后结果起判定作用,人际关系敏感属性为轻度时,表示需要对学生进一步检查,人际关系敏感属性为中度时,表示具有很明显的心理症状;当抑郁、精神病性、人际关系敏感三个属性均处于轻度层次时,一旦焦虑属性表现出非健康状态,学生将可能存在很明显或是比较严重的心理症状。综上,高校教育管理工作者应重点关注焦虑、抑郁、人际关系敏感和精神病性等属性的项目得分情况。
3 结 论
大学生的心理健康普遍存在一定的症状,有些症状虽然属于轻度的心理问题,不至于影响健康,但如果不能及时疏导和调适,就可能引发心理障碍,进而演变成心理疾病。心理疾病会严重影响学生自身的学习和生活,同时也可能引发恶性事件的出现。因此,结合本研究的数据挖掘建模结论和工作实际,提出了以下心理健康干预策略:
1)对于心理健康症状认定为“进一步检查”的同学,要通过学生干部与该生进行深入沟通与日常帮扶。充分调动班集体的力量,带动该生积极融入班集体、积极参加文体活动;充分发挥朋辈力量,积极对该生存在的心理困惑予以疏导。国内外研究表明,朋辈辅导是一种易于为人们所接受的心理健康教育方式。通过上述方案,来达到缓解该生心理健康症状表现,直到症状消失。
2)对于心理健康症状认定为“很明显”的同学,辅导员要第一时间对该生进行深度辅导,对学生心理健康症状进行综合评估,并与学生家长进行沟通反馈,商讨解决方案。同时,也要充分调动班集体的力量,带动该生积极融入班集体、积极参加文体活动;充分发挥朋辈力量,积极对该生存在的心理困惑予以疏导。通过上述方案,来达到缓解该生心理健康症状表现。
3)对于心理健康症状认定为“比较严重”的同学,要第一时间向学校心理咨询部门上报,并立即邀请心理咨询师对该生进行心理咨询评估。如果评估结果“严重”,可以转入相关精神科医疗机构进行治疗;如果评估结果“比较严重”,可以对该生进行定期的心理咨询与辅导。通过上述方案,来达到缓解该生心理健康症状表现的目的。此外,还需要学生家长、辅导员、学生干部对该生进行日常关注与帮扶,避免新的症状表现出现。
参考文献:
[1] 曾洪发,刘芳,周紫微.大学生练习中国传统导引术的心理体验与功效 [J].体育科技文献通报,2021(7):130-133+183.
[2] 张元洪.高校开展大学生朋辈心理辅导工作的理论与实践探讨 [J].思想政治教育研究,2015,31(6):121-123.
[3] 刘建中.近20年大学生心理健康研究进展综述 [J].职业时空,2009,5(10):168-169.
[4] 张锐.系统论视域下青少年心理健康服务体系的构建 [J].教育理论与实践,2021,41(12):32-34.
[5] 薛薇,陈欢歌.Clementine数据挖掘方法及应用 [M].北京:电子工业出版社,2013.
[6] QUINLAN J R. Induction of Decision Trees [J].Machine Learning,1986,1(1):81-106.
[7] QUINLAN J R. C4.5:Programs for Machine Learning [M].San Francisco:California,1993.
[8] 张琳,陈燕,李桃迎,等.决策树分类算法研究 [J].计算机工程,2011,37(13):66-67+70.
[9] DUNHAM M H. Data Mining:Introductory and Advanced Topics [M].Upper Saddle River,NJ:Prentice Hall PTR,2002.
[10] 张雪英.国外先进数据挖掘工具的比较分析 [J].计算机工程,2003(16):1-3.
[11] 杜松江.基于Clementine的数据挖掘模型评估 [J].计算机光盘软件与应用,2013,16(8):263+265.
[12] 晉争,赵凯宾,于欢,等.症状自评量表(SCL-90)河南省青少年区域性常模的建立和心理测量特性验证 [J].精神医学杂志,2022,35(2):113-118.
[13] 张明园.精神科评定量表手册 第2版 [M].长沙:湖南科学技术出版社,1998:17-19.
作者简介:薄启欣(1989—),男,汉族,黑龙江伊春人,讲师,主要研究方向:教育管理、管理过程优化;高学东(1963—),男,汉族,河北唐山人,教授,博士生导师,博士,主要研究方向:管理过程优化;通讯作者:潘莹雪(1994—),女,汉族,山东德州人,博士研究生在读,主要研究方向:大学生就业管理、管理过程优化研究。
猜你喜欢
核科学与工程(2021年4期)2022-01-12
大众投资指南(2021年35期)2021-02-16
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
计算机应用(2018年5期)2018-07-25
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
轴承(2015年2期)2015-07-25
郑州大学学报(医学版)(2015年1期)2015-02-27
