
基于FPGA的目标检测系统与加速器设计
2023-06-25 07:42吴昱昊
现代信息科技 2023年7期
摘 要:目标检测作为计算机视觉技术的基础任务,在智慧医疗、智能交通等生活场景中应用广泛。深度学习具有高类别检测精度、高精度定位的优势,是当前目标检测的研究重点。由于卷积神经网络计算复杂度高、内存要求高,使用CPU实现的设计方案已经难以满足实际应用的需求。现场可编程逻辑门阵列(FPGA)具有可重构、高能效、低延迟的特点。研究围绕FPAG硬件设计,选取了YOLOv2算法,并针对该算法设计了对应的硬件加速器,实现了基于FPGA的目标检测。
关键词:YOLO;FPGA;目标检测;深度学习
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)07-0101-04
Abstract: As a basic task of computer vision technology, object detection is widely used in smart medicine, intelligent transportation and other life scenes. Deep Learning nowadays becomes the research focus of object detection for its advantages of high precision in class detection and positioning. Due to the great computational complexity and memory requirements, the design scheme implemented by using the CPU has been difficult to meet the needs of practical application. FPGA has the characteristics of reconfigurability, high energy efficiency and low latency. The research focuses on the FPGA hardware design, selects the YOLOv2 algorithm, designs the corresponding hardware accelerator in terms of the algorithm, and realizes the object detection based on FPGA.
Keywords: YOLO; FPGA; object detection; Deep Learning
0 引 言
目標检测技术是计算级视觉任务中的关键技术,不仅需要对目标物体进行分类,同时需要准确定位目标物体,一般用红框标注[1]。
机器学习技术在目标检测中的广泛应用大大提高了计算精度。深度学习方法相比传统算法优势明显,为目标检测算法的研究开辟了新的路径。目前检测技术主要分为两种。One-stage的方法对于输入的网络能够直接回归得出目标的位置和类别,但可能会损失部分精度。Two-stage的方法是首先在图像上画出目标框即目标物体的候选区域,再计算得到分类与定位[2]。本研究使用的YOLOv2[3]算法是一种One-stage的方法。
随着深度学习技术研究的浪潮,复杂、抽象的问题和大量的数据使得深度学习的网络结构变得更加复杂,带来了巨大的计算量和极高的内存需求[4,5]。在这种情况下,如何在保持低功耗的同时使算法实际应用中具有高速度,逐渐成为研究和讨论的热点。目前,GPU、ASIC和FPGA是深度学习算法加速设计的主流研究方向[3]。GPU在深度学习算法中的加速优势已得到广泛验证,但功耗非常高。ASIC芯片功耗低,但在实际应用中机器学习任务有很多变化,ASIC相应的研发成本非常高。FPGA的功耗比GPU低几十倍甚至数百倍。在FPGA上部署深度学习算法可以在毫秒级更新逻辑,其灵活性更适合迭代深度学习算法,以节省开发成本。FPGA是深度学习的理想硬件加速选择[6,7]。
1 YOLO算法
传统的目标检测算法[1]主要包括以下三步:区域选择、特征提取、分类。区域的确定一般使用滑动窗口的方法,因此这一步骤产生大量冗余窗口,对算法的效率有一定影响。特征将会从所产生的候选区域中被提取,在深度学习算法被广泛应用之前,这一步骤往往由手工进行设计。常用的深度学习算法R-CNN主要使用了卷积神经网络来进行特征提取,并且能够利用图片的颜色、纹理、形状等减少候选区域。使用这些能够被计算机识别的特征,选择合适的分类器,将得到物体的分类结果。
YOLO[3](you only look once)算法和R-CNN的主要不同点在于这是一种基于回归的方法,只使用一个卷积神经网络就可以得到类别和位置,即在获得候选区域中的Bounding Box时也同时给出了包含对象的类别。目前,YOLO算法共发布了7个版本。YOLOv1是整个系列的核心和基石,后续版本是基于此版本的改进。和YOLOv1相比,YOLOv2使用了全卷积网络,并且使用了Anchorbox机制。它的卷积层增加了Batch Normalization层,对每层输入的数据做批归一化处理。卷积层从线性卷积与激活函数改进为后来常用的线性卷积、BN层和激活函数。这些改进使得该算法的检测速度、精度、召回率有了明显的提高。作者相较第一版本,设计了新的backbone网络,包含19个卷积层,被命名为DarkNet19。YOLOv3和YOLOv2的基本思想是一样的,其检测精度虽然得到了提高,但损失了一定的计算速度。YOLOv4、YOLOv5网络分支更多,在FPGA上实现有一定难度。考虑实际场景应用,YOLOv2在实时目标检测方面更有优势,并且已在智慧交通、智能家居等领域取得了良好的应用效果,本研究选择了YOLOv2算法。
2 针对YOLOv2的加速器设计
2.1 YOLOv2网络加速框架设计
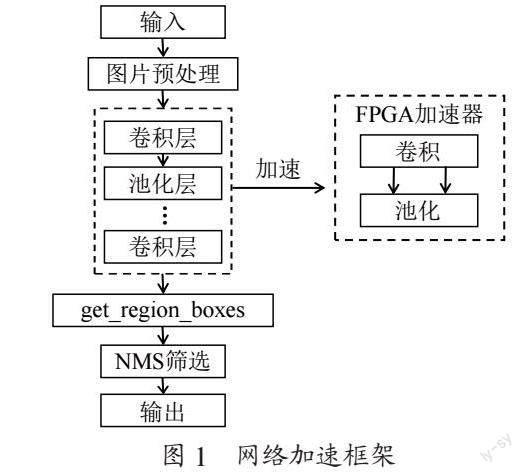
根据YOLOv2[3]网络特点,设计了如图1所示的加速器框架。该目标检测系统包含从图像输入到结果输出的完整流程,由PC和FPGA共同组成,其中FPGA主要负责对神经网络计算部分的加速。
如图所示,图片的输入、预处理及输出部分对于计算的要求较低,这三部分均在PC端实现。Get_region_box 主要用于保存候选框Bounding Box的概率信息和坐标信息,YOLOv2s使用了NMS非极大值抑制算法对这些Bounding Box进行筛选后现实。结合整体计算量考虑,这两部也在PC端实现。
YOLO网络结构中卷积层和池化层交替设置,其中卷积计算中主要包含3×3标准卷积和1×1point-wise卷积,占网络总体计算量的90%以上。因此卷积层的计算是FPGA实现加速的重点环节。YOLOv2在池化层使用的是最大值池化方式,包括上采样、下采样、concat操作在内的这些计算是一些轻量级的计算,因此池化层考虑在FPGA上仅做简单实现。加速器的设计核心是卷积计算加速。
2.2 加速器硬件结构
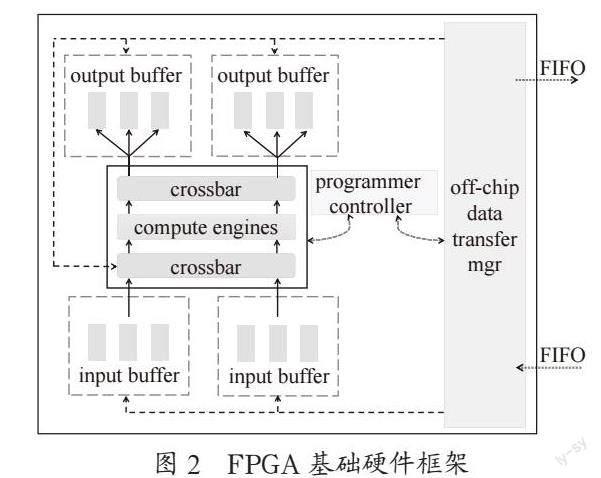
参考文献[8],FPGA的硬件结构设计如图2所示。这种结构的设计主要是应对卷积神经网络计算吞吐和内存带宽不匹配的问题。在数据传输部分,针对YOLOv2模型和FPGA的有限资源,权重及参数可以存储在片外存储器上[9,10]。对于输入和输出分别设置了双缓冲区(Ping Pong FIFO),使用“乒一乓”的数据传输机制提高数据的传输效率。和一个缓冲区不同,一个缓冲区通常是是读取当前部分后才可以继续传输下一部分,以避免读取的错误。“乒一乓”传输对于输入输出的分区能够实现一边传输一边读取计算,因此也可以用计算时间覆盖数据传输时间,减少整体的程序执行时间。在计算部分使用了多个计算引擎(computeengines)并行执行,不同的引擎可以用于计算不同的卷积。单个引擎的内部是一个并行乘法单元和一个加法树。加法树的最下层为乘法单元,其余为多层加法器,分别用于并行计算卷积操作中的乘法运算求和运算。由此加速了网络程序的计算速度,一定程度上缓解了内存带宽和计算吞吐不匹配的问题。
2.3 卷积计算
YOLOv2以卷积神经网络为基础,在卷积階段涉及了大量的乘法和加法的计算,该部分计算复杂度高,占了总计算量的90%以上。针对卷积计算,因为片上的计算资源(DSP等)和存储资源(BRAM等)的有限性,主要考虑采用循环分块、循环展开技术实现并行计算,在循环的设计中,重点考虑了数据的复用,以提高加速器的性能。
针对1×1卷积,实际上是一个矩阵乘法,使用通用矩阵乘(GEMM)算法优化加速,按照分块矩阵乘法进行设计。一个正常的矩阵乘法的时间复杂度是O(n3),最内重循环每次需要访问内存4次。而使用GEMM算法,虽然不能够减少计算量,但是能够大大减少访存次数,从而达到加速的效果。
直接使用暴力矩阵乘法及一次优化的伪代码如下。矩阵C为矩阵A、矩阵B的乘积,M、N、K分别是A、B矩阵的维度及其对应的三层循环执行次数。直接使用暴力乘法,内存访问操作总数为4 MNK,一次优化后内存访问操作总数为2 MNK+2 MN。从伪代码中,可以看出,主要原因是将C[m][n]放到了循环外面,计算了全部累和之后再对C赋值,从而减少了对C的访存。
暴力乘法:
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
for (int k = 0; k < K; k++) {
C[m][n]+= A[m][k] * B[k][n];
}}}
一次优化:
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
float temp = C[m][n];
for (int k = 0; k < K; k++) {
temp += A[m][k] * B[k][n];
}
C[m][n] = temp;
}}
继续将输出的C矩阵在N维度拆分,如拆成1×4的小块,即使用A矩阵的一行和B矩阵的4列相乘,二次优化伪代码如下。因为在循环最内侧计算使用的矩阵A的元素是一致的,所以可以将A[m][k]读取到寄存器中,实现4次数据复用。同理可以继续拆解输出的M维度,继续减少输入数据的访存。
二次优化:
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n += 4) {
float temp_m0n0 = C[m][n + 0];
float temp_m0n1 = C[m][n + 1];
float temp_m0n2 = C[m][n + 2];
float temp_m0n3 = C[m][n + 3];
for (int k = 0; k < K; k++) {
float temp = A[m][k];
temp_m0n0 += temp * B[k][n + 0];
temp_m0n1 += temp * B[k][n + 1];
temp_m0n2 += temp * B[k][n + 2];
temp_m0n3 += temp * B[k][n + 3];
}
C[m][n + 0] = temp_m0n0;
C[m][n + 1] = temp_m0n1;
C[m][n + 2] = temp_m0n2;
C[m][n + 3] = temp_m0n3;
}}
针对3×3标准卷积,主要考虑了输入输出通道的并行。输入通道并行计算特征图和权重,输出通道并行计算输出的的结果或者部分和假设并行度为tn,tm,3×3标准卷积层及展开后的伪代码如下:
卷积层伪代码:
for(r=0;r<R;r++) {
for(c=0;c<C;c++) {
for(to=0;to<M;to++) {
for(ti=0;ti<N;ti++) {
for(i=0;i<K;i++) {
for(j=0;i<K;j++){
outpu_fm[to][r][c]+=
weights[to][ti][i][j]*
input_fm[ti][S*r+i][S*c+j];
} } } } } }
循环展开后伪代码:
for(r=0;r<R;r++=tr) {
for(c=0;c<C;c++=tc) {
for(to=0;to<M;to++=tm) {
for(ti=0;ti<N;ti++=tn) {
for(tile_r=r;tile_r<min(r+tr,R);tile_r++) {
for(tile_c=c;tile_c<min(c+tc,C);tile_c++){
for(tile_to=to;tile_to<min(to+tm,M);tile_to++){
for(tile_ti=ti;tile_ti<min(ti+tn,N);tile_ti++){
for(i=0;i<K;i++) {
for(j=0;i<K;j++){
outpu_fm[to][r][c]+=
weights[to][ti][i][j]*
input_fm[ti][S*r+i][S*cl+j];
} } } } } } } } } }
2.4 池化计算
YOLOv2的池化层使用的池化方法是最大池化(Max-Pooling),主要目的是通过仅保留主要原特征来减少神经网络的训练参数。因此在精度损失可接受的范围内能够减少网络的训练时间。设置步长2,大小2×2的窗口滑动,选取窗口中的最大值。最大池化层的计算与卷积层计算的循环结构是类似的,但是卷积层中的乘法及加法运算在池化层中是比较运算,因此池化层计算量相较于卷积层大大减少。在加速器设计中,对池化层仅做简单设计。该部分逐行从上层的特征图中读取数据,等到缓存区填满数据后,做并行化池化操作。
3 实验及分析
3.1 模型训练
研究选择YOLOv2网络对加速器进行性能测试。在测试前,首先基于YOLOv2网络训练得到了的口罩檢测模型,主要功能为判别人脸是否佩戴口罩。该模型使用了YOLOv2预训练的权重文件,结合补充的口罩数据集(2 000张),在GPU上进行二次训练得到。补充数据集使用了labeling标注的VOC格式数据集用于训练,标注范围为整个头部及少量肩膀上部分。该模型对于人脸的检测准确率为95%,对于佩戴口罩的人脸检测准确率为81%。
3.2 实施过程
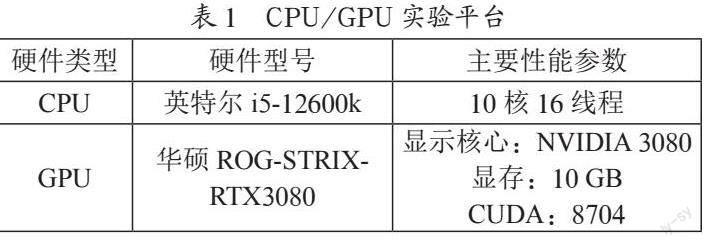
加速器测试平台使用xilinx的PYNQ-Z2开发版,以ZYNQ FPGA为核心。该系列集成了FPGA和ARM,顶层封装使用Python,支持Python进行SoC编程。因此本研究无需设计可编程逻辑电路,采用Jupyter Notebook直接编辑工程代码。CPU、GPU实验平台参数如表1所示。主要实现方法如下:首先使用xilinx vivado HLS(High Level Synthesis)将c代码转换为Verilog代码,生成IP核;其次在Vivado中导入IP核,生成bit流文件;使用Python语言操作输入输出、bit流文件的烧写等。
该目标检测系统的实现主要分为,图片预处理,网络检测(特征提取)以及图片预测(结果输出)。其中,图片预处理及图片预测部分在PC端实现,即由CPU完成。针对网络检测的加速部分,实验分别在FPGA及PC(CPU)上进了比较测试。
图片预处理主要包括三个步骤:统一图片大小、归一化RGB、压缩数据精度。由Python编写。对于输入的大小不一的图片,统一大小为416 px×416 px。归一化RGB值的主要目的是用两个字节表示一个像素值,消除像素受光照或阴影的影响。压缩数据精度主要将32位浮点数转换为16位定点数表达,损失了部分可以接受的精度,减少fpga片上存储(BRAM)压力。FPGA加速测试的网络检测部分由C语言编写,图片输入大小设置为416×416,由于YOLOV2是对整张图片进行处理,因此对图片进行分割,网格大小设置为13×13,因此输出cell数为13×13。由于FPGA片上存储资源有限,因此实验需要对输入数据进行分块,每次加载一块数据到片上缓存。依次读取tn×tm×batch像素对应的权重文件到片上缓存,特征计算,完成一张输出特征图的计算再进行输出,直至所有特征图全部输出。YOLO网络的计算结果即目标检测结果在Jupyter Notebook输出。
测试结果表面,在FPGA上,单张图片的前向推理时间为421.3 ms,相比PC(CPU0端1.44秒有明显的加速效果,可以满足目标检测的实时需求。
4 结 论
典型的深度学习目标检测算法计算量巨大,部署到资源有限的嵌入式系统中存在一定难度。YOLOv2算法在各个应用领域都有着良好的应用前景。研究首先介绍了YOLOv2算法,并针对该算法,设计了基于FPGA的加速器,并将模型部署到FPGA,得出了实验推理时间,证明了FPGA加速的有效性。
参考文献:
[1] FANG L,HANGJIANG H E,ZHOU G. Research overview of object detection methods [J].Computer Engineering and Applications,2018,54(13):11-18.
[2] 赵兴博,陶青川.适用于FPGA的轻量实时视频人脸检测 [J].现代计算机,2022,28(8):1-8.
[3] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016:779-778.
[4] 周飞燕,金林鹏,董军.卷积神经网络研究综述 [J].计算机学报,2017,40(6):1229-1251.
[5] 张珂,冯晓晗,郭玉荣,等.图像分类的深度卷积神经网络模型综述 [J].中国图象图形学报,2021,26(10):2305-2325.
[6] 吴艳霞,梁楷,刘颖,等.深度学习FPGA加速器的进展与趋势 [J].计算机学报,2019,42(11):2461-2480.
[7] 刘腾达,朱君文,张一闻.FPGA加速深度学习综述 [J].计算机科学与探索,2021,15(11):2093-2104.
[8] ZHANG C,LI P,SUN G,et al. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks [C]//the 2015 ACM/SIGDA International Symposium. Monterey:ACM,2015.
[9] 裴頌文,汪显荣.YOLO检测网络的FPGA加速计算模型的研究 [J].小型微型计算机系统,2022,43(8):1681-1686.
[10] 胡晶晶.基于FPGA的Faster-RCNN改进算法实现目标检测 [J].现代计算机,2021,27(30):82-87.
作者简介:吴昱昊(1996—),女,汉族,浙江上虞人,助教,硕士研究生,研究方向:深度学习、社会网络分析。
猜你喜欢
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科学与财富(2016年28期)2016-10-14
科技视界(2016年4期)2016-02-22
