
基于包簇映射的云计算资源分配策略探究
2023-06-22 23:36冯政军
无线互联科技 2023年4期
冯政军


摘要:随着社会经济的蓬勃发展,云计算领域也在逐渐扩张,其规模也在日益壮大,而越来越多的资源分配与管理方面等问题也凸显出来.与此同时,国内大多数云计算企业的数据管理资源部门通常以虚拟设备为工作中心,为客户提供所需的设备个数和匹配资源,包括储存卡、显示器等,甚至可能还要包含外显设施.因此,云计算企业应当在满足自身需求的同时,减少资源的浪费,利用现代计算模式重新评估云计算资源分配过程中的服务成本,以达到云计算行业绿色、节能的最终目标。据此,针对当下时代发展的要求,文章以云计算资源发展与分配现状为出发点,浅析了当前包簇映射框架,阐述了基于包簇框架的云计算资源分配策略,希望为未来云计算资源分配策略探究提供新方向。
关键词:云计算:资源分配:包簇映射分析
中图分类号:TP39
文献标志码:A
0 引言
传统的云计算资源分配管理通常以数据为重点,通过扁平化的资源模式对整体数据信息进行管理,而这种精细化的管理模式将导致后续出现的问题既复杂又数量庞大,因此,基于传统虚拟数据的云计算资源分配方式不利于现代社会的进步与发展。此外,由于网络技术的飞速发展和受众群体类别的不断变化.互联网领域不仅需要拥有适应云计算系统的强大能力,还应使企业既能满足客户的服务条件,又能实现资源的有效利用。云计算资源的高效发展既可考虑到实际分配的动态模式以应对当代行业变化,还可进行虚拟化技术的开发,改良资源稀少、经费开支较高等负面现象。
1 云计算资源发展与分配现状
1.1 发展现状
当代云计算资源规模的日益增加,以往的资源管理模式难以适应目前企业对互联网计算的实际需要,同时可扩展性、灵活性等方面问题逐渐凸显。一方面,灵活性主要包括计算机用户在进入互联网时必须对云计算中心的资源管理进行优化,并提出对整体资源的实际要求。当计算机使用者通过集中的方法进行计算机资源的输出时,如果市场统一对资源进行共享,则对每个使用者而言就没有独立的网络管理[1]。另一方面,云计算的可扩展性主要包括互联网中的资源管理展现到服务器时需要大量维护,而市场中的网络流量模型、数据拓扑模型以及管理中心的共享模式都会影响到云计算资源的可扩展性。
1.2 资源分配
新时代云计算系统中的资源分配管理主要与多目标升级问题有关,且与装箱问题相似,例如如何使资源分配的管理高效、安全,或者判断云计算环境的负载能力和具体性能。此外,云计算的启发式仿生算法可以模拟生物的成长历程,并在无数模拟解法中,准确找到最优解,这种算法比以往算法更加科学、实用,有着无法超越的高效性,即使面对消费者的更多需求,云计算的资源分配也可以在满足客户要求的情况下,更多地减少企业的成本。由此可见,完善云计算资源分配的管理模式,降低企业的成本,杜绝浪费现象,已经成为当前社会的云计算专家重点研究的方向。
与此同时,有学者提出一种基于蚁群活动模式的资源分配,并命名为蚁群算法,此算法通过模拟蚁群的活动模式,运用至云计算环境中,最终得到一种最优的资源分配方法,其算法如图1所示。
通过蚁群算法的仿真实验,证明了云计算资源分配模式可以帮助使用者享有极速的响应时间和高效的运行质量,但由于相关技术还在持续更新进步,导致其资源分配速度较慢[2]。众多国内外学者为达到理想的实用效果,提高云计算资源的服务质量和资源利用率,并构建以此为目标的多目标优化模型,同时融合现代流行的神经网络,幫助蚁群算法等众多优秀算法对云资源分配资源模式实现理想模式,但神经网络结构的设计也对算法的精准性造成了约束与影响。
2 包簇映射框架
2.1 包的定义
包的定义在于云环境下针对子包的集合,它也是一个层级含义,例如一层级的包可以由无数个二层级的包构成,同时单个二级包也可由无数个三级包构成,或者由不同的虚拟数据构成。由此可见,包的定义在于其可以集中并实现包内云环境间的资源分配与共享,所以这种模式的制定只能使客户自身通过层级化的结构来保证自身的资源要求。
以国内某中外合资企业的内部结构为例,其部门结构和管理级别层层划分,管理中心设立在北京,并在湖南、上海、深圳和南京等大型城市分别设立分部试行逐级管理[3]。并依据企业的实际需求,针对包的结构定义,构建出至少数量为5的企业二级管理部门,每个地区都设有4个二级包,分别囊括了人事部、销售部、管理部和工程部,以满足企业的资源分配需要,这4个分部门也都拥有多个三级或以下层级包,保证每个包之间的企业资源都达到互利共享。
2.2 簇的定义
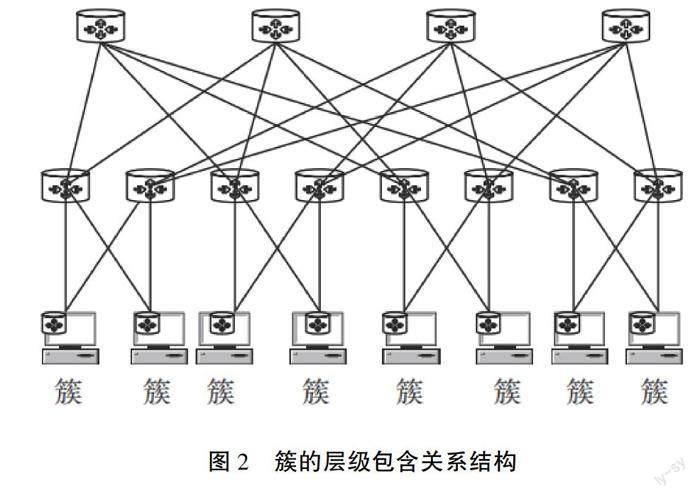
簇就是指数据核心拓扑中位置靠近服务器或者更低级别的虚拟账户的总和。而簇所持有的数据总和就是组成簇整体的各部分资源和。依照簇的定义可得到,每个互联网中的服务器可表示成一个簇,同时当低层级的簇向上合并成为高层级的簇后,可再次向上帮助进一步的合并,所以不同的层级包含关系可以融合出各种不同的簇结构,其结构关系如图2所示。
由此可见,簇和包在云计算中的应用,使数据资源分配管理的复杂度大幅下降。可将同种问题假设成多维装箱题材,即将资源共享的虚拟机组合成的包假设为装入的物品,包中所囊括的资源分配数量就是物品的个数,而箱子则代表簇,其容量大小代表了簇整体的使用阈值,云计算的资源种类数量代表了装箱过程中的维数,同时其目标是使点数达到最小,资源利用率呈最大值。
2.3 包簇框架模型
包簇框架模型是指通过各层级的抽象模型来解决问题的模型,并将顶层的包对应着顶层的簇,使每一个簇都有其所匹配的包,同时将模型下一层级的包接着对应到下一级别的簇,将此过程反复进行,直到整体数据匹配到服务器接受客户访问。所以,包簇框架模型可以将一个烦琐复杂的问题简化,并肢解成多部分较小程度的子问题,这些子问题又可通过云计算的各个算法逐一击破而得到充分解决[4]。因此,云环境的资源管理分配问题就被转换成多层级、可分开解决且易于整理的问题,并可通过资源中心系统性的监控体系,结合企业的资源需要和性能进行约束,完成从高层级的包簇到低级包簇匹配的联系过程。综上所述,现代资源管理中心的分配问题可被包簇框架模型分解成多个独立的子问题,这些子问题相互独立且解决方式简单,因此,可通过固定资源分配处理器对其进行快速计算,以提升资源分配的实际效率。
3 基于包簇框架的云计算资源分配策略
3.1 多目标包部署算法的编码概况
3.1.1 物品编码
多目标包部署算法将对物品进行预先编码,其中需编码资源主要包含CPU、内存等。然后对固定时间内的各个包进行提取,并充分整理与分析,将包的初始生成过程设定为先随机输入一定量的虚拟内存,并记录其输入与输出的数据量,再锁定当前包,将所有包中的资源整体进行统一并做规范化处理,即计算出当前包中的每一种资源占据当前簇的比重[5]。如此,每个包就可以通过当前簇的比重找到匹配的包,并且保障各匹配资源的运行量小于簇的门阈值。
3.1.2 组编码
组编码的制定对资源分配的影响十分关键,同时组编码的实际运作就是资源问题的解决方案到服务器之间的对应关系。将其类比于基因的发展过程,资源管理的包到簇之间的组编码可称为染色体,并将4个包分成两个组,其对应的染色体则存在两个基因,同时每个基因囊括一组包和簇,所以基因既可以表达成物品也可以表达成箱子。由此可见,组编码可类比遗传算法对染色体的具体操作,其内容部分以资源编码的形式展现。由于编码节点放置的包个数不统一,导致同类型的包会被安置到不同的节点上,因此,组编码要处理不同长度的包簇模型。
3.2遗传算法与蚂蚁算法的融合
为了解决多目标包部署算法在云计算后期的乏力,相继使用了遗传算法与蚂蚁算法。但由于遗传算法进行了大量的无用迭代,且蚂蚁算法在运行初期存在缺少信息素导致进化缓慢的弊端,因此,企业将遗传算法与蚂蚁算法进行即时的融合与改进,组成新型算法命名为融合改进算法。融合改进算法的主要特点是结合遗传算法和蚂蚁算法的各自优势,减少其各自存在的缺点,相互补充,扬长避短。在融合改进算法执行任务且进行云计算的资源分配任务时,对任务中可能发生的各种情况使用染色体编码方式进行编码,并将可能存在的各种资源分配方案进行染色体组合及编码,将其用来展现包到资源簇之前的匹配、对应关系,即将每条染色体设为云计算分配问题中的一个可行解法,再运用融合改进算法在可行解法中找到最优解,实现云计算资源分配与管理问题的高效解决[6-7]。
3.3 实验分析
3.3.1 实验设置
为了验证融合改进算法的合理性、科学性以及可行性,实现基于包、簇映射云资源分配算法的高效性能,进行了仿真实验,实验软件使用Matlab,CloudSim等,同时设置任务数为600个,其资源簇为200个。实验人员构建成本评估模型,观察并分析资源簇节点的数量、执行时间和服务成本,最后展现基于包簇框架的改进多目标遗传算法的科学与合理之处。
3.3.2 实验过程
实验人员将所有的云计算资源抽象成为资源簇的概念,并将客户的实际需求设立为需求包,计算在同一需求条件下可以有效降低资源簇的个数,同时分别采用改进后算法和传统算法。通过大量实验证明,改进后的算法进行的簇个数明显要比传统算法部署的簇个数少很多,这是因为新算法融合了蚂蚁算法,使相较单一的传统算法能够获得更准确的解集[8]。此外,在相同任务数下,与传统算法相比较,改进后的算法完成时间较短,且在任务数小于100时,先进算法与传统算法的任务完成时间相近,但是,随着任务量的逐渐增加,新算法的任务完成时间仍然保持以往速度,而传统算法的任务完成时间还在大幅提升,其结果如表1所示。
由此可见,改进后的算法得益于蚂蚁算法的相互融合,以及遗传算法的大力帮助,得以展现出后期的快速求解能力,最后通过对比实验可以看出.改进后的算法能够高效地降低云计算资源的分配与管理时间。
3.3.3 结果分析
云环境用户在享受服务价值的同时,怎样降低服务成本,降低费用是客户通常关心的问题。对于云计算资源企业来讲,在提高服务价值的同时,减少服务成本也是应当改革的重点方向。因此,减少任务服务成本对消费者和企业来讲都是十分重要的。通过观察新算法和传统算法的执行过程,建立成本评价模型,展现各算法的特点及优劣情况,最后分析得到,在完成相同时间的条件下,融合改进算法的任务执行时间与成本更低,并在成本评价模型中展示,将任务效益采用倒数的形式反映,即计算结果越大,其任务结束时间和执行成本越少。
4 结语
为了实现云计算的资源分配,并将大数据环境中的计算资源以最小的使用成本通过弹性分配进行合理规划,充分利用编码的思想体系,将大量的、杂乱的云资源分配管理内容逐步分解,形成部分相对简单的问题,并通过递归循环的解决方法,帮助云环境的资源实现科学、合理的分配。本文以云计算资源发展与分配现状为基本点,阐述了当前包簇映射框架,并提出基于包簇框架的云计算资源分配策略,旨在为未来云计算资源分配策略探究提供理论基础。
参考文献
[1]梁慈,陈世平.基于包簇映射架构的包漂移策略研究[J].计算机与现代化.2019( 11):112-119.
[2]吕腾飞,陈世平.基于包簇映射的云计算资源分配策略[J].上海理工大学学报,2019(3):260-266.
[3]邱春红.云计算中虚拟机簇的优化分配[J].西南师范大学学报,2021(1):44-49.
[4]朱兵伟,陈世平.包簇框架云资源分配规划[J].计算机应用与软件,2018(9):252-257,287.
[5]王无恙.基于用户行为特征的云计算资源分配策略研究[J].数码世界,2017(11):383.
[6]孫凌宇,冷明.基于不同分配策略的云计算任务调度性能比较与分析[J].井冈山大学学报,2016(1):62-68,74.
[7]李天宇.基于强化学习的云计算资源调度策略研究[J].上海电力学院学报.2019(4):309-403.
[8]倪思源,扈红超,刘文彦,等.基于轮换策略的异构云资源分配算法[J].计算机工程,2021( 6):44 -51,67.
(编辑沈强)
猜你喜欢
英语文摘(2020年10期)2020-11-26
测控技术(2018年7期)2018-12-09
计算机系统应用(2018年7期)2018-07-18
计算机应用(2016年10期)2017-05-12
大学教育(2016年9期)2016-10-09
计算机工程(2014年6期)2014-02-28
