
基于“剪枝+并行”FP-Growth算法的密切接触人员快速追踪技术的研究
2023-06-22 21:08:10刘聪
现代信息科技 2023年2期
关键词:关联性

摘 要:利用“剪枝+并行”式FP-Growth優化算法,通过提升计算精度和速度的方式对疫情发生地区确诊患者的密接人员、次密接人员和同时空关联人员实行快速精准的排查。与传统的FP-Growth算法相比,“剪枝+并行”式FP-Growth算法的计算性能得到显著提升。通过对某地区测试者7天内行迹及相关联人员信息进行时间和准确方面的测试比较发现,计算时长缩短了近30%,准确率由82%提升至91%。实验表明,利用优化后的FP-Growth算法能够较好地满足疫情发生地区快速精准确定相关联人员的要求。
关键词:FP-Growth算法;关联性;快速精准
中图分类号:TP311.1 文献标识码:A 文章编号:2096-4706(2023)02-0034-05
Research on Fast Tracking Technology of Close Contacts Based on “Pruning + Parallel” FP-Growth Algorithm
LIU Cong
(Weifang Vocational College, Weifang 261041, China)
Abstract: The “pruning + parallel” FP-Growth optimization algorithm is used to quickly and accurately check the close contact personnel, sub close contact personnel and simultaneous air contact personnel of the confirmed patients in the epidemic area by the ways of improving the calculation accuracy and speed. Compared with the traditional FP-Growth algorithm, the computational performance of the “pruning + parallel” FP-Growth algorithm has been significantly improved. Through testing and comparing the time and accuracy of testers' tracks and related personnel information within 7 days in a certain area, it is found that the calculation time is shortened by nearly 30%, and the accuracy rate is improved from 82% to 91%. The experiment shows that the optimized FP-Growth algorithm can better meet the requirements of quickly and accurately determining the relevant personnel in the epidemic area.
Keywords: FP-Growth algorithm; relevance; fast and accurate
0 引 言
截至2022年8月,国内疫情仍处于低水平波动状态,日均确诊病例200人以上,无症状感染者1 000人以上,且变种病毒层出不穷,给地区疫情防控和经济发展造成极大麻烦。思考如何利用现代化分析技术快速有效追踪密切接触者,成为后疫情时代防控疫情、推动经济社会稳定发展的关键点。
基于以上,本文提出利用改进的“剪枝+并行”式FP-Growth优化算法对疫情发生区域确诊人员的密接关联人员情况进行快速准确定位,从而实现疫情地区的精准快速防控,及时有效切断疫情传播链,将疫情影响本地生产生活降低到最小[1-6]。
1 改进FP-Growth算法实现关联数据挖掘
由于本文中存在大量的数据处理和分析工作,过去传统的FP-Growth算法已经无法满足大规模数据下的数据处理和分析。因此,根据前端特征数据采集设备所采集数据的特征,本文对传统的FP-Growth算法进行优化改进,利用MapReduce编程模型,对FP-Growth算法的各个步骤使用“剪枝+并行”法处理,优化后的算法在计算效率上可提高约30%,运行内存降低近40%,精准度提高10个百分点[7]。
1.1 FP-Growth算法和关联规则算法原理
FP-Growth算法主要是通过利用和获取构建的树形结构图中的相关事件集,来进行关联性分析,每个事件都会在树形结构图中以路径的形式标出,出现叠加的路径越多,说明在使用FP-Growth算法的优势越明显。FP-Growth算法的实现需要经过两个过程,一是构建FP-Tree,二是对FP-Tree进行关联性数据挖掘。
关联规则在数学方面很容易理解,即某事件X和事件Y的关系,在其关联算法中的应用规则相类似,事件X看作关联规则的前导项,事件Y看作关联规则的后续项,可用公式表示为:X—>Y,其中在关系规则中有两个关键度,即一个是支持度(support),另一个是置信度(confidence)[8]。
支持度,主要是指前导事件X和后续事件Y的共同事件在总事件Z中所占的比例,可以用数学公式表示为:P(X∪Y )=(X∪Y )/Z。
置信度,主要指是在总事件中前导事件X和后续事件Y共同出現与只包含X事件或Y事件的比例,可以用数学公式表示为:
P(X |Y )=P(X∩Y )/P(X )或者P(Y |X )=P(X∩Y )/P(Y )。
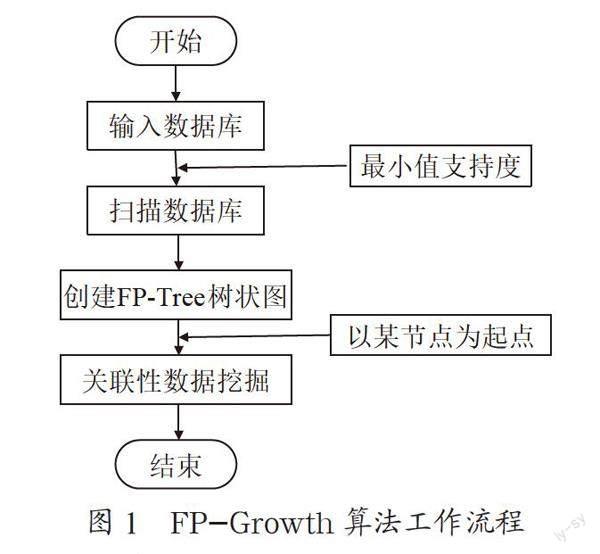
关联规则的产生主要来源于购物方面的相关联性分析,即在更好的服务购物者的同时加大商品的销量。在关联规则中有两个值较为关键,一是支持度事件值,另一个是置信度事件值,如果这两个值的最小支持度(Min_support)和最小置信度(Min_confidence)都能够达到自定义的阈值,那么系统在数据分析上就认为运用关联规则是有意义的[9]。关联规则在数据挖掘的整个过程中,需要经历两步:一是要从原始数据信息中寻找出现频率较高的事件集,即必须要大于等于最小支持度的阈值;二是要利用这些频率较高的事件集来确定相关的关联规则,即必须要满足大于等于最小置信度的阈值。FP-Growth算法整体工作流程图如图1所示。
1.1.1 构建FP-Tree树
第一步:首先需要对总数据集进行一次检索,找出每个事件字符所出现的频次,然后依据支持度的最小阈值,假设Min_support=3,测试中使用列表1进行试验分析,排除小于最小阈值的事件字符,从而得到新的列表,如表2所示。
第二步:再一次对新的数据集列表2进行一次检索,设根节点为root,根据数列集中的事件字符依次以树状图的形式下顺,每次出现重复的字符就进行加1操作,最终得到完整地FP-Tree,具体执行过程如图2所示。
1.1.2 对FP-Tree进行关联性数据挖掘
在构建FP-Tree结束后,选择树状图中固定节点字符,然后从树状图中找出与固定节点字符相关联的路径,以s为例,可以看出从根节点root开始依次查找到与s相关的路径分别为h{1}—>f{1}—>d{1}—>u{1},h{1}—>f{1}—>d{1}和f{1}—>e{1},然后按照上面的第二步操作重新进行建立树状图,可以得到一个关于s的关联性的项fs{3}。
以上就是关于FP-Growth算法实现关联性的整个过程,该算法在查看本系统中的相关监测人员的密切度方面有极大帮助。但是随着数据量的增加,单一的FP-Growth算法在运算方面就比较吃力,为此,在设计无线管控系统时,考虑到了对FP-Growth算法进行一定优化处理,采用并行+剪枝+FP-Growth的算法达到实际系统高效运算的目的。
1.2 优化改进FP-Growth算法
1.2.1 树枝合并化改进
首先,根据需求设定一个定义,假如构建的FP-Tree的树状图中的路径M中含有非频繁的事件r,路径N中也包含非频繁事件r,同时满足M∈N,那么就可以把N中的事件r去掉,然后合并到较短的路径M中,合并前的树状图如图3所示,合并后的树状图如图4所示。
依据此假设,对本文在优化改进FP-Growth算法方面得到以下启示:在面对多事件路径时,对于路径中存在的某些非频繁的事件项,可以采用合并事件集路径的方法,对FP-Growth算法进行升级改造,通过减少数据挖掘过程中的检索路径数量,来达到提高运算效率的目的[10]。
1.2.2 数据挖掘并行化改进
依据前面的“剪枝”可以得知,主要是在构建FP-Tree树状图时进行路径优化处理,但是在后续对FP-Tree进行关联性数据挖掘时,仍需继续改进提速。因为在对数据进行挖掘时,对于不同事件集的挖掘,所对应的频繁项集是不同的,它决定着FP-Tree的复杂程度,同时FP-tree又主要作用于内存中,所以FP-Tree的复杂程度越高,占用的内存就越大,对于运行速率方面有一定影响。为此,本文继续提出了把FP-Growth算法传统的串行法变为并行法的设计,解决数据量规模较大的问题,在运算效率上得到进一步提高,并行法的结构图如图5所示。
FP-Growth算法实行并行法的设计思路主要有以下几步:
第一步:先对原始的数据信息求出其频繁事件项集,然后对其不同事件出现的频率由高到低进行编码处理,最后把编写好的列表文件传送到指定的执行文件中,编码列表如表3所示。
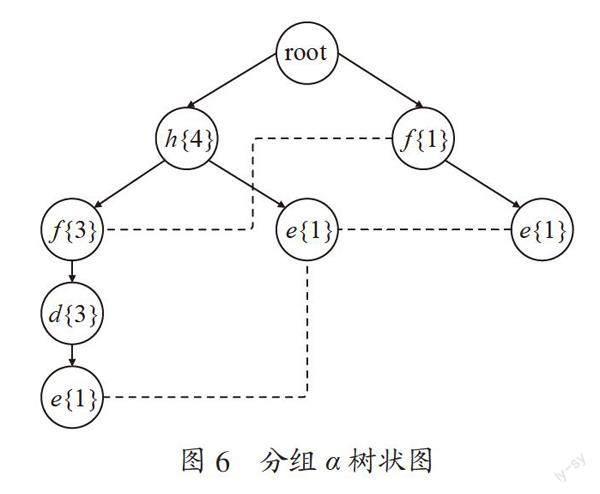
第二步:对原始数据进行分组,把初始事件组转换为编码的事件组,然后对所有的事件进行分组划分,设定分为α组和β组,事件项集合{h,f,d,e,u,v}包含分组α{h,f,d,e}和分组β{e,u,v},若初始事组中的某一事件项既包含在α组中,又包含在β组中,那么这一事件项就要输出到两个分组中,具体分组情况如表4所示。
第三步:对上述分组结果,分别对每组的事件项进行建立树状图的操作,具体的执行步骤如上节对原始数据的树状图操纵类似,新建的树状图α和β分别如图6和图7所示。
第四步:对新建的树状图进行分别进行关联性数据挖掘处理,一个map()函数对应一个分组进行挖掘操作,生成每个分组的频繁事件项集,然后通过reduce()函数操作,把分散的频繁事件项集合并成一个大的整体,最后根据支持度和置信度得出数据关联性挖掘的最终结果,具体操作如图8所示。
1.3 关联性数据挖掘的实现
客户端在点击执行关联性查询时,发送运行改进的FP-Growth算法的请求,程序端在接收到命令请求时会连同关联性参数一起发送给FP-Growth_action函数进行处理,FP-Growth_action函数会启动一个改进的FP-Growth算法线程,通过FP-Growth_monitor函数进行实时刷新监控,就可以获取到改进的FP-Growth算法运行后的实时数据信息[11],具体调用改进的FP-Growth算法的流程图如图9所示。
2 测试性能与结果分析
本文主要从单机数据处理和多节点性能测试两方面对改进的FP-Growth算法和传统的FP-Growth算法在性能方面进行差异化性能测试。
2.1 单机处理对比
在保证实验硬件、数据量等方面一致的前提下,通过植入两种不同的算法,对运算性能进行测验,同时为了保证实验测验的可靠性,减小误差,分别对每组实验数据进行100次以上的重复测验,最后取其均值作为测验结果进行分析。测试的方法主要是看折线图中数据量和平均时间的比值大小,比例系数越小说明运算的效率越高,反之越低,具体的测试结果图如图10所示。
从测验的结果中可以得出:当数据量较小时,传统的FP-Growth算法在工作效率方面具有一定的优势,但是随着数据量的增加,改进的FP-Growth算法就逐渐地显示出其自身的优势。因此,把合并分支路径和并行运算整体运用到FP-Growth算法中,能够实现在数据量不断扩大的前提下,使运行的效率不至于出现急剧的下滑,大大地提高了关联性数据挖掘的速率。
2.2 多节点性能测试
为了进一步测验优化改进的FP-Growth算法性能,实验中又设计了另外一组对比实验,在集群的环境下测试该算法的性能。本实验中采用主从式架构,一共包含10个节点,其中1个节点作为服务节点,另外的9个节点作为数据节点,其他配置均相同。测验中选择最小的支持度分别为10%和20%,同时从数据库中的相关存储文件中随机选取大量数据,构建三组大数据,分别标记为D1、D2、D3。图11至图14分别显示在最小支持度分别为10%和20%的情况下,三组不同的数据及9个任务节点执行传统FP-Growth算法和改进FP-Growth算法的时间对比。
从以上两组测验对比图中的折线规律可以得出。在数据量一定的情况下,随着节点数的增加,通过优化改进的FP-Growth算法的相对运行时间在不断减少。出现这种状况的主要原因在于,节点数量的增加导致消耗通信时间的增加程度明显的小于计算时间所减少的程度。另外,相同的数据,会随着最小支持度的增加而相对应的运行时间有所减少,这是因为最小支持度变大后,频繁数据项集的数量和长度也会相应地减少,从而运行时间缩短[12]。
3 结 论
本文在研究FP-Growth算法的基础上,针对当前疫情区域人员信息数据量大、数据及时性高等特点和存在的问题,提出了一种基于“剪枝+并行”FP-Growth算法的密切接触人员快速追踪技术的方法,并在实地场景进行测验。但仍有改进的余地,下一步的研究工作主要有以下几个方面:
(1)目前还存在数据采集过程中断断续续不稳定的情况,数据的传输过程中如何提高丢包率是接下来需要考虑的因素之一。
(2)对算法进一步优化,减少在使用过程中算法训练所需的次数,使精度的提高更快。
(3)通过更多的实验,进一步精确算法的主要参数值,以尽可能提高算法性能。
参考文献:
[1] 秦雷.公安监控联手“数字城管”南岗公安分局新中心揭牌 [N].哈尔滨日报,2008-04-11(2).
[2] 汪明峰,顾成城.上海智慧城市建设中公共WLAN热点的空间分析与检讨 [J].地理科学进展,2015,34(4):438-447.
[3] 张峥嵘.浅谈公安网络监控系统的建设与管理 [J].中国公共安全,2013(13):130-133.
[4] 向庭勇,向庭波.用大数据技术构建公安Wi-Fi侦测系统的研究与应用 [J].中国公共安全,2016(13):75-81.
[5] 陈刚,羌铃铃.针对不同平台系统获取MAC地址的特定方法 [J].微计算机信息,2012,28(5):182—183+154.
[6] 公安监控网络集成系统为平安城市保驾护航 [J].中国公共安全,2015(7):127-128.
[7] 马月坤,刘鹏飞,张振友,等.改进的FP-Growth算法及其分布式并行实现 [J].哈尔滨理工大学学报,2016,21(2):20-27.
[8] 陆楠,王喆,周春光.基于FP-tree频集模式的FP-Growth算法对关联规则挖掘的影响 [J].吉林大学学报:理学版,2003(2):180-185.
[9] 张星,李蓓.FP-Growth关联规则挖掘的改進算法 [J].平顶山工学院学报,2008(1):21-24.
[10] 晏杰,亓文娟.基于Apriori&FP-Growth算法的研究 [J].计算机系统应用,2011,47(7):153-155.
[11] 何月顺.关联规则挖掘技术的研究及应用 [D].南京:南京航空航天大学,2010.
[12] 杨勇,王伟.一种基于MapReduce的并行FP-growth算法 [J].重庆邮电大学学报:自然科学版,2013,25(5):651-657+670.
作者简介:刘聪(1990—),男,汉族,山东潍坊人,助教,硕士研究生,研究方向:图像识别和算法研究。
收稿日期:2022-09-02
猜你喜欢
法大研究生(2020年2期)2020-01-19 01:42:12
中成药(2017年3期)2017-05-17 06:09:05
中国环境监察(2016年12期)2016-10-24 05:29:18
中国卫生标准管理(2015年16期)2016-01-20 09:26:29
中国卫生标准管理(2015年6期)2016-01-14 05:17:08
中国铸造装备与技术(2015年5期)2015-12-10 10:23:40
川北医学院学报(2015年5期)2015-12-05 08:22:39
创意与设计(2015年6期)2015-02-27 07:55:55
衡阳师范学院学报(2015年2期)2015-02-26 03:25:04
对外经贸(2014年1期)2014-03-20 13:58:07
