
基于注意力和上下文的多尺度图像背景下的小目标检测方法
2023-06-22 23:00李容光杨梦龙
现代信息科技 2023年5期
关键词:目标检测
李容光 杨梦龙


摘 要:在多尺度多目标的背景下,小目标由于像素少、提取特征困难,其检测精度远远低于大中目标。文章通过使用离散自注意力提取跨尺度的全局的上下文背景信息,使用跨尺度通道注意力和尺度注意力来增强模型的尺度敏感性,捕捉到更多不同的、更丰富的物体-物体、背景-物体信息,使得每一层特征层都是一个跨空间和跨尺度的拥有更丰富特征信息的特征层,从而提高在多尺度背景下小目标检测的效果。在COCO数据集上,本算法的APs高于基准retinanet最高达2.9,在DIOR数据集上mAP能够达到69.0,优于该数据集上最优算法,同时能够维持自己单阶段的速度。
关键词:目标检测;小目标检测;离散自注意力;跨尺度注意力
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)05-0001-07
Small Object Detection Method under the Background of Multi-Scale Image
Based on Attention and Context
LI Rongguang, YANG Menglong
(School of Aeronautics and Astronautics, Sichuan University, Chengdu 610065, China)
Abstract: Under the background of multi-scale and multi-target, the detection accuracy of small targets is far lower than that of large and medium targets due to fewer pixels and difficulty in feature extraction. Through using discrete self-attention to extract cross-scale global context information, and using cross-scale channel attention and scale attention to enhance the scale sensitivity of the model, this paper captures more different and richer object-Object and background-object information, so that each feature layer is a feature layer with richer feature information across space and scale, thereby improving the effect of small target detection under the background of multi-scale. On the COCO data set, the APs of this algorithm are higher than the benchmark retinanet by up to 2.9, and the mAP on the DIOR data set can reach 69.0, which is better than the optimal algorithm on this data set, while maintaining its own single-stage speed.
Keywords: object detection; small object detection; discrete self-attention; cross-scale attention
0 引 言
隨着深度学习的发展,目标检测迎来了新的发展,相比较于传统的目标检测,其精度和速度都上了一个大的阶梯,被广泛地应用到自动驾驶、视觉导航、工业检测、航空航天和救援等诸多的领域。然而,在很多应用场景中,存在着大量的小目标对象,这些对象与其他大尺度的对象共存于待检测的图中,这些小目标由于像素少,信噪比低和在多层下采样导致的大感受野中占比极小,导致检测的效果很难满足实际的需要,所以,提升小目标的检测效果有很大的实际意义。
目标检测的主要任务是从给定的图像中定位物体的位置和识别物体的类别。根据阶段的数量,可以将目标检测分为单阶段和双阶段模型。单阶段模型是将定位和分类一步到位,其优势是速度快,代表性的框架有YOLO[1]系列、fcos[2]和ssd[3]等一阶段目标检测模型;双阶段模型先通过rpn(region proposal network)网络或者其他算法生成proposal,第二阶段再对proposal进行位置的修正和分类,所以双阶段网络的检测准确率比单阶段网络高很多,代表性的网络有rcnn[4]系列网络。此外还可以按照有无anchor分类,分为anchor-based和anchor-free,其中anchor-based方法需要提前在特征图上面铺设anchor,并设置一系列的超参数,如长宽比、尺度大小、anchor数量。模型检测结果对这些超参数都比较敏感。而像fcos[2]和centerne[5]类的anchor-free方法,在检测上达到了与单阶段anchor-based方法接近的效果,且减少了anchor相关的超参数,使得训练和调节超参数变得简单。小目标的检测,也是使用的是目标检测的框架,其固有的下采样特性对小目标不友好。
小目标的定义[6]主要有两种,一种是COCO数据集规定的按照绝对尺寸大小来进行划分,像素值小于32×32即为小目标;第二种是按照相对尺寸来进行划分,检测目标与图像面积之比在1%以下的为小目标。在过去的几年里,众多学者已经做了很多关于小目标检测的研究,这些研究主要是根据导致小目标检测困难的原因进行的研究。小目标检测的一个难点在于像素点少,针对这个原因,有学者采用超像素[7]的方法,在检测前,先对图像通过超像素网络生成高像素的图片,再进行检测,但是这种办法增加了检测的时间;也有学者使用GAN来单独针对小目标生成与大目标分布类似的特征[8],再进行检测;深度学习模型中多次下采样会导致小目标信息丢失严重,为了减少深度学习模型对小目标的影响,有学者采用了下采样倍数比较小的浅层特征图[9]进行识别,这种方式对资源的需求比较大;针对存在多尺度物体的图像中,小尺度的物体检测效果不好,有学者采用图像金字塔[10],将多个尺度的图像输入到模型分别进行训练,但是这会导致训练时间增加,显存占用也极大;为了解决图像金字塔存在的问题,有学者提出了特征金字塔[3],在每个不同尺度的特征层进行检测,能够有效地避免大的计算量和显存占用;为了解决小尺度特征层上语义信息不足,有学者在特征金字塔上使用特征融合[11],丰富底层的特征的语义信息和高层特征的空间信息;除了上述的使用特征金字塔进行多尺度物体的检测以外,有人提出了专门针对多尺度检测的训练方法[12]来增加检测性能,还通过采用不同感受野大小的filter[13]进行提取特征,再进行检测。此外大部分基于anchor的模型,其本身对小目标是不友好的,因为小目标的检测对anchor的大小、密集程度等超参数的变化很敏感,因此在训练的时候,会根据小目标的数量进行anchor大小和密集程度进行调节。针对现有IoU匹配方法对小目标不友好的问题,有学者提出了新的专门针对小目标的匹配方法[14]。虽然针对小目标,大家提出了很多的解决办法,然而小目标的检测指标相对于大中目标还是相差甚远。
根据小目标携带的特征信息较少,缺乏将其与背景或类似物体区分开的有效外观信息的特征,本文提出了在自然场景下的目标检测任务中融入目标周围甚至全局的跨尺度上下文信息的方法和跨尺度特征融合的方法,来丰富特征信息的表达,提升模型对小目标的检测效果。即通过跨尺度离散注意力的方法来进行跨尺度上下文信息的提取,通过跨尺度通道注意力和尺度注意力模块来进行实现跨尺度的特征融合。
1 模型和方法
1.1 注意力机制
人类的视觉机制可以对重点区域重点关注,将有限的注意力集中在重点信息上,分配更多的注意力,同时减少对其他区域的关注。在计算机视觉中,利用类似的机制,可以显著地降低模型的计算量,同时可以定位到感兴趣的信息,抑制无用信息,而实现重点关注和非重点关注的方法就是使用权重进行加权。注意力的作用对象可以使用一个序列att={att1, att2,…, attN}来表示,其中atti∈RD,D表示维度,其中N表示代处理对象的个数,这里的处理对象在空间注意力可能会是特征图上不同的像素点,在通道注意力上,是特征图的每个通道。注意力主要做的事就是在每个时刻t计算出针对每个对象atti的权重at, i,计算公式为:
Mt,i=fa(att1,att2,…attN)
Mt,i表示中间变量,j表示对象下标,fa(·)表示关系建模的操作,可以表示一个子网络,也可以表示内积,余弦相似度等方法。计算出权重以后,Φ(·)就可以使用上面的权重通过某种方法对对象进行选择,得到新的对象的表示。如软注意力使用线性加权函数,比较有名的工作有SEnet[15]和CBAM[16];硬注意力使用离散选取的方式,图像裁剪即是一种硬注意力。本文方法都启发于注意力机制。
1.2 离散自注意力
从自然语言处理领域迁移过来的自注意力模型[17]是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。可以用来编码全局信息,建模物体与物体间的关系,增强目标的特征表示。但是其训练收敛慢,且需要大量的数据才能收敛。经过研究发现,自注意力机制的注意力矩阵一开始是一个比较均匀的密集矩阵,经过训练以后的矩阵是稀疏矩阵,这意味着特征图里里面的每个点q不是与全局中的每个k都有关,而只是与几个点有关,所以可以让注意力矩阵一开始就是离散的,受到上述启发,改进了自注意力,提出了离散自注意力,具体如下:
如图1所示,使用q经过一个位置偏移预测网络预测出q与图上哪些点有关,然后将这些点与q进行自注意力的操作,使用公式描述过程如下:
posi=netselect(q)
上述的q为自注意力機制中的Query,netselect(·)为一个预测位置的多层感知机网络,输出的结果为相关点的坐标偏移,其中参考点为q点,每个预测的相关的k点的偏移坐标都是相对于q点的,k为自注意力中的Key,v为Value,加了posi下标的符号表示是从预测的位置提取出的k和v。q′为新的结合了最相关的全局上下文信息的q的表示。其中netselect预测的坐标点个数是一个超参数,太大会增加模型的计算和引入过多的不必要的信息,导致收敛的速度变慢,太少使得该点需要的背景没有被充分的加入进去,本文通过大量的实验,发现最好的效果的值为12。离散自注意力可以用来捕获非局部的特征,以实现较远空间内的特征交互。
1.3 跨尺度背景上下文提取
目标检测的主流框架是采用多尺度预测,即每层特征图预测不同尺度的物体,小物体在比较低的特征层下识别,大的物体在更高的特征层识别。然而这种情况下,会产生上下文信息和目标对象特征之间的矛盾:需要融合的上下文信息与目标对象的特征不属于同一特征层。比如区分电脑显示器和电视的一个背景因素是鼠标,然而负责预测鼠标的层跟负责预测电脑和电视的层不一样,就会导致矛盾。大目标和小目标大小相差太大,在相同尺度下特征信息相差太大,所以非局部交互应该是在目标相应的尺度上,而不是一个统一的尺度,即大物体与小物体的交互应该是负责识别大物体的特征层上的有关大物体的特征和负责识别小物体的特征层上的有关小物体的信息进行交互。
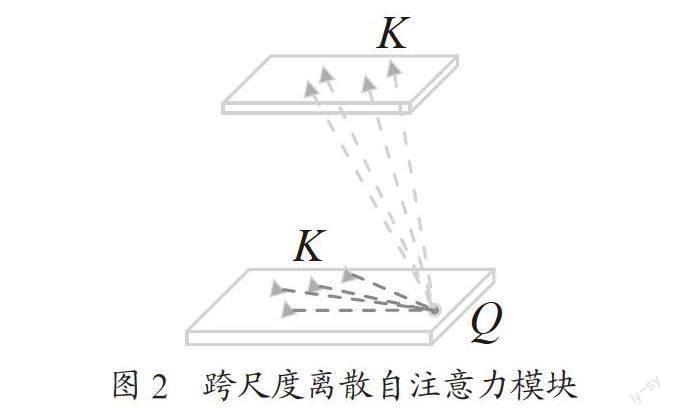
综上所述,需要一种能够提取尺度内的全局背景信息和跨尺度提取上下文信息的方法,而1.2小节提到的离散自注意力能够有效地在同一层进行局部特征与全局特征的交互,生成关于每个点的全局上下文信息,只需要稍微改进,就可以拥有跨尺度交互的能力。为了能够更好地使得不同尺度的信息进行交互,得到更利于识别的特征,这里通过改进离散自注意力加入了跨尺度交互的自注意力,如图2所示,与1.2小节的尺度内交互的自注意力操作类似,只是k点的选取除了在同尺度内,还会在相邻的高层特征图进行选取,整个结构的计算方向,是自底向上的方式,通过这样的操作进行跨尺度上下文的提取,能够丰富每个特征的表示,进一步提升小目标的检测效果。
1.4 跨尺度特征融合
1.4.1 跨尺度通道注意力特征融合
常规的卷积神经网络通过backbone的最后一个特征图的特征来进行识别,这对于小目标而言是有害的,因为分辨率较低的特征图容易忽视小的目标,一种解决方案为使用特征金字塔,对于较大的目标,在深层特征图中预测,对于较小的目标,使用浅层的特征图预测。但是这种预测方式在实验的过程中仍然有一些问题,原因在于低层特征图因为没有进行后续的卷积特征提取,使得该特征层缺少足够的语义信息,而语义信息对物体的类别识别有很重要的作用,一个解决方案是将上层的特征图与下层的特征图进行一个融合,使得空间信息和语义信息都更加充足。
本文依然采用了融合上层的语义信息来增强小目标的特征表示,同时增加了跨尺度的交互的部分。具体的操作如图3所示,通过对下层特征图的通道进行关系的建模,生成对应的通道权重(b,c,1,1),使用该权重加权上层特征图。该操作可以来提取下层特征图通道全局信息,然后使用这些信息来指导上层特征图的通道关系,使得下层的信息与上层的全局信息进行交互,同时通过此通道注意力抑制多余的信息,突出更有用的信息。通过跨尺度通道注意力得到的特征图,再进行2倍上采样,然后与其相邻的下层特征图进行特征融合。
1.4.2 尺度注意力特征融合
此处借鉴了PANET[18]的思想,PANET是先进行top-down的特征融合,然后进行bottle-up的特征融合,本篇文章采取不一样的融合方式,相当于同时进行了top-down和bottle-up的融合,而不是串行的方式。如图4所示,F1,F2,F3表示相邻的三个特征层,将F1上采样到F2的大小,然后将F3下采样到F1大小,再进行相加,这里相加不是直接相加,而是借鉴了通道注意力的思想,使用一个权重预测网络,来预测每个特征层的权重,使用权重加权对应的特征层,将加权后的特征图相加,得到新的特征图。此操作使每一层都能够获得来自上层的语义信息和来自下层的空间信息,同时加权的操作提升了模型的尺度敏感性,更能够适应多尺度背景下的检测。相比于尺度内的交互,跨尺度的交互能够捕捉到更多不同的、更丰富的物体-物体、背景-物体信息去帮助更好地去进行物体识别和检测,使得每一层都是一个跨空间和尺度交互的拥有更丰富特征信息的特征层。
1.5 整体架构
如图5所示,与retinanet[19]的模型一样,采用backbone输出的多层特征图进行预测,每两层特征图中间使用离散自注意力获取跨尺度和长距离的上下文信息,同时将跨尺度的上层语义信息通过跨尺度通道注意力提取出来,然后语义信息、上下文信息和特征图加起来得到信息更丰富的特征层。然后对最上层的特征层进行一个两倍下采样,生成的四层特征层作为操作3的输入。操作3为尺度注意力特征融合模块,具体的阐述在1.4小节。其中尺度注意力模块是可以叠加多个,经过实验,发现N=2的时候,达到的效果最好。圖5中操作1为1.3小节阐述的跨尺度离散自注意力模块,操作2为1.4小节的跨尺度通道注意力特征融合模块。
2 实 验
2.1 实验准备及实验设置
现有的用于检测多尺度情况下小目标检测的数据集分为两种,第1种是公共数据集,即COCO数据集;第2种是各个领域的应用数据集如遥感数据集、人脸数据集、行人数据集及交通标志和信号灯数据集等。本文实验所用的数据集为COCO数据集和DIOR[20]数据集,使用两个数据集配置的测试集进行测试。其中DIOR数据集类别信息和类别如图6所示,该数据集主要有以下两个特征:
一个是规模大,由23 463张图片组成,类别数为20,总实例数为192 472,图像大小为800×800。
另一个是尺度差异大,这里的尺度指的是实例的空间大小。DIOR数据集中,不仅类别间的实例尺度差异大,而且类内的实例尺度差异也比较大,物体尺度的多样性有利于与真实世界相关的任务,小尺度物体和大尺度物体的数量处于一个比较均衡的状态,这对检测的模型是一个挑战,因为整个数据集上面的物体尺度跨越比较大。
一般会采用两种方式来测试检测模型的效果。在IoU(交并比)为[0.5:0.95:0.5]这10个值上分别计算mAP,最后计算平均值,这是COCO数据集采用的测试指标;另外一种需要计算IoU=0.5时相应的精度和召回率,最后得到相应的mAP。显而易见,前者的多IoU评价方法能够更好地反应检测模型和算法的综合的性能,对算法和模型要求更高。
在此基础上,本文设计了消融实验和横向对比试验两组实验。消融实验主要是为了验证本文提出的各模块的有效性,为了能够比较精细地看到每个模块的作用,这一部分实验采用的是第一种评估方式,使用COCO数据集进行训练和测试。横向对比实验是为了对比文中提出的算法与其他的算法的优劣,为了提高实验的效率这里直接采用第二种评估方式来进行评估,使用DIOR数据集进行训练和测试。
实验使用的配置与retinanet一致,使用相同的数据增强方法,输入设置为1 333×800;使用在Imagenet[21]上预训练的Resnet-50[22]作为消融实验的backbone,k设置为12。模型使用SGD训练12个epoch,momentum=0.9,weight_decay=0.000 1,学习率使用线性缩减策略,训练开始使用学习率为0.001,当训练到第9个epoch和第12个epoch时,将学习率降到0.000 1和0.000 01。消融实验使用的是COCO2017数据集,训练和测试集使用官方划分。对比实验采用的是DIOR数据集,按照1:2:7的比例划分验证集、测试集和训练集。实验环境为ubuntu 20.04,工具为pytorch,在2张Titan RTX显卡进行训练。
2.2 消融实验结果
消融实验的基准为retinanet,所用数据集为COCO。为了测试所提出的各模块的有效性,实验比较了加入不同模块模型的性能。Re_content指的是只加入了离散自注意力提取背景上下文的模型,Re_seme指的是只加入了跨尺度语义信息的模型,Re_scale指的是加入尺度注意力的模型,Re_all指的是加入上述所有操作的模型。实验结果如表1所示,每个模块都对小目标的检测,起到了积极的作用,re-all的AP相比于基准retinanet提高了2.1,APs提高了2.9,其他指标也都有显著的提高,可以看出本文提出的方法对小目标的检测有很大的提升。
2.3 对比实验结果
对比试验采用的数据集为DIOR数据集,训练方式与[20]一致,使用ci(i=0,1,…,20)来分别表示20个类别。
结果如表2所示,得益于retinanet本身优秀的算法设计以及经过本文提出的三个模块,re-a(ours)算法在检测精度上超过了DIOR数据集上大部分的检测算法,其mAP达到了最高69.0的性能,大部分类别的AP值相比于其他算法都是最优值,说明此算法在尺度差异比较大的数据集上起到了很好的效果。同时由于依然是单阶段模型,所以其速度也快于大部分的双阶段算法。所以本文提出的方法相比于现有方法具有很大的优越性,在对尺度差异比较大的数据集中,本文的改进算法具有很好的应用前景。
2.4 推理结果比较
图7展示了在相同的训练和推理参数设计下,部分retinanet和re-all的推理结果,总共两组图像,组1和组2。可以明显看到,每个图像中re-all模型对小目标的效果都要好于retinanet模型,retinanet在小目标极小和目标比较密集的时候,容易出现漏检和错检,如图7所示,retinanet在组1,组2每幅图上基本都有不同程度的漏检,在图7的组1和组2的第4幅图中,可以看到,Airplane类别由于与Wind mill类别特征比较相似经常被检测算法错误的检测,而在re-all算法中,由于提升了小目标的特征提取能力,其漏检和错检的目标要少得多,特别是很少混淆Airplane类与Wind mill类,可以明显感觉到加入背景上下文的方法起作用了。此外,从图7的组1的第1、3幅图和组2的第2幅图大尺度目标的置信度变化,以及组1第2幅图retinanet错检出大尺度目标,可以看出re-all算法不仅提高了小目标,也提高了大目标的检测效果。
3 结 论
本文提出了一种通过跨尺度非局部交互和同尺度非局部交互提取背景上下文的方式,同时也使用类似注意力的方式进行特征融合,通过上述两种方式捕捉到更多不同的、更丰富的物体-物体、背景-物体信息去帮助更好地去进行物体识别和检测,使得每一层都是一个跨空间和跨尺度的拥有更丰富特征信息的特征层,从而提高在多尺度背景下,对小目标检测的效果。在实验的过程中发现,本文的模型在单阶段模型中使用效果比较好,能够显著的提升小目标的检测的效果,但是将本文提出的模块用在多阶段目标检测的模型中时,效果不是很好,甚至出現了mAP值下降,所以下一阶段将会探索为什么此模块在多阶段模型中不起作用,研究适合多阶段模型使用的背景上下文提取和特征融合模块。
参考文献:
[1] BOCHKOVSKIY A,WANG C-Y,LIAO H-Y M. Yolov4:Optimal Speed and Accuracy of Object Detection [J/OL].arXiv:2004.10934 [cs.CV].(2020-04-23).https://arxiv.org/abs/2004.10934.
[2] Tian Z,Shen C H,Chen H,et al. FCOS:Fully Convolutional One-Stage Object Detection [C]//2019 IEEE/CVF International Conference on Computer Vision(ICCV).Seoul:IEEE,2019:9626-9635.
[3] LIU W,ANGUELOV D,ERHAN D,et al. SSD:Single Shot Multibox Detector [C]//European Conference on Computer Vision-ECCV 2016.Cham:Springer,2016:21-37.
[4] GIRSHICK R. Fast R-CNN [C]//2015 IEEE international conference on Computer Vision(ICCV).Santiago:IEEE,2015:1440-1448.
[5] DUAN K,BAI S,XIE L X,et al. CenterNet:Keypoint triplets for Object Detection [C]//2019 IEEE/CVF International Conference on Computer Vision(ICCV).Seoul:IEEE,2019:6568-6577.
[6] LIU Y,SUN P,WERGELES N,et al. A Survey and Performance Evaluation of Deep Learning Methods for Small Object Detection [J].Expert Systems with Applications,2021,172(4):114602.
[7] NOH J,BAE W,LEE W,et al. Better to Follow,Follow to be Better:Towards Precise Supervision of Feature Super-Resolution for Small Object Detection [C]//2019 IEEE/CVF International Conference on Computer Vision(ICCV).Seoul:IEEE,2019:9724-9733.
[8] RABBI J,RAY N,SCHUBERT M,et al. Small-Object Detection in Remote Sensing Images with End-To-End Edge-Enhanced GAN and Object Detector Network [J].Remote Sensing,2020,12(9):1432.
[9] HUANG H X,TANG X D,WEN F,et al. Small Object Detection Method with Shallow Feature Fusion Network for Chip Surface Defect Detection [J].Scientific Reports,2022,12(1):1-9.
[10] SINGH B,DAVIS L S. An Analysis of Scale Invariance in Object Detection-SNIP [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake:IEEE,2018:3578-3587.
[11] LIN T-Y,DOLL?R P,GIRSHICK R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:936-944.
[12] SINGH B,NAJIBI M,DAVIS L S. SNIPER:Efficient Multi-Scale Training [C]//NIPS'18:Proceedings of the 32nd International Conference on Neural Information Processing Systems.Montréal:Curran Associates,2018:9333-9343.
[13] LI Y H,CHEN Y T,WANG N Y,et al. Scale-Aware Trident Networks for Object Detection [C]//2019 IEEE/CVF International Conference on Computer Vision(ICCV).Seoul:IEEE,2019:6053-6062.
[14] WANG J W,XU C,YANG W,et al. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection [J/OL].arXiv:2110.13389 [cs.CV].(2021-10-26).https://arxiv.org/abs/2110.13389.
[15] HU J,SHEN L,SUN G. Squeeze-and-Excitation Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake:IEEE,2018:7132-7141.
[16] WOO S,PARK J,LEE J-Y,et al. CBAM:Convolutional Block Attention Module [C]//Proceedings of the European Conference on Computer Vision (ECCV).Munich:ECCV,2018:3-19.
[17] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you Need [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates,2017:6000-6010.
[18] WANG K X,LIEW J H,ZOU Y T,et al. PANet:Few-Shot Image Semantic Segmentation with Prototype Alignment [C]//2019 IEEE/CVF International Conference on Computer Vision(ICCV).Seoul:IEEE,2019:9196-9205.
[19] LIN T-Y,GOYAL P,GIRSHICK R,et al. Focal Loss for Dense Object Detection [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,42(2):318-327.
[20] LI K,WAN G,CHENG G,et al. Object Detection in Optical Remote Sensing Images:A Survey and a New Benchmark [J].ISPRS Journal of Photogrammetry and Remote Sensing,2020,159:296-307.
[21] DENG J,DONG W,SOCHER R,et al. ImageNet:A Large-Scale Hierarchical Image Database [C]//2009 IEEE Conference on Computer Vision and Pattern Recognition.Miami:IEEE,2009:248-255.
[22] HE K,ZHANG X,REN S,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:770-778.
作者簡介:李容光(1997—),男,汉族,四川巴中人,硕士研究生在读,研究方向:小目标检测;通讯作者:杨梦龙(1983—),男,汉族,四川成都人,副研究员,博士研究生,研究方向:计算机视觉,模式识别,图像处理。
收稿日期:2022-11-28
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
