
用于不平衡节点分类的集成图神经网络模型
2023-06-22 12:19:13郭梦昕
现代信息科技 2023年3期
关键词:集成学习

摘 要:为解决图神经网络(GNN)上不平衡节点的分类问题,提出一种Bagging集成模型,该模型使用图卷积网络(GCN)作为基分类器。在该模型中,先对若干基分类器进行并行训练,然后使用多数投票的方式对这些基分类器的预测结果进行集成,最终完成分类任务。实验结果表明,该文提出的模型显著优于其他现有基线方法,验证了其在不平衡节点分类中的有效性。
关键词:图神经网络;不平衡节点分类;集成学习
中图分类号:TP183 文献标识码:A 文章編号:2096-4706(2023)03-0029-04
Ensemble Graph Neural Network Model for Imbalanced Node Classification
GUO Mengxin
(Taiyuan Normal University, Jinzhong 030619, China)
Abstract: To solve the classification problem of unbalanced nodes on graph neural network (GNN), a Bagging ensemble model is proposed, which uses GCN as the base classifier. In this model, several base classifiers are trained in parallel, and then the prediction results of these base classifiers are integrated by majority voting to complete the classification task finally. Experimental results show that the proposed model in this paper is significantly superior to other existing baseline methods, and its effectiveness in unbalanced node classification is verified.
Keywords: graph neural network; imbalanced node classification; ensemble learning
0 引 言
近年来,随着图神经网络(Graph Neural Network, GNN)的发展,在图学习方面取得了很大的进步。一个典型的任务是半监督节点分类,GNN展现了其优异的性能,并正在迅速发展,例如,图卷积网络(Graph Convolutional Network, GCN)[1]通过使用简化的一阶近似有效地利用谱域中的特征;GraphSage[2]利用了空域中的特征,并且能更好地适应不同的图形拓扑。尽管取得了这些进展,但现有的工作还是主要集中在平衡的节点分类上。
在许多实际应用中,我们经常面临不平衡节点分类问题。因为我们只得到了有限的标记数据,这使得有标签的少数类样本非常少,所以半监督设置就会进一步放大类不平衡问题。而多数类可能会主导GNN的损失函数,使得训练的GNN对这些多数类进行过度分类,无法准确预测少数类样本,所以不平衡节点分类给现有的GNN带来了挑战,这一问题导致许多具有不平衡类分布的实际应用无法采用GNN,因此,开发用于类不平衡节点分类的GNN是非常重要的。
在机器学习领域,传统的类不平衡问题得到了广泛的研究。主要有三种方法:数据级方法、算法级方法和混合方法。然而,节点之间的关系是图数据中的关键信息,传统的机器学习技术则假设样本是独立同分布的,因此,传统的不平衡学习算法并不适用于图数据。
虽然对传统数据的不平衡分类进行了很好的研究,但对类不平衡问题的图神经网络算法研究还比较有限。DRGCN[3]是解决图上类不平衡问题的先驱工作,该方法提出了一个类条件对抗正则化器和一个潜在N分布对齐正则化器,但不能扩展到大型图;GraphSMOTE[4]通过预训练边生成器,从而将SMOTE推广到图域,从而为来自SMOTE的新合成节点添加关系信息。然而,计算所有节点对之间的相似度和预训练边生成器的任务非常繁重。
由于单个模型很难准确预测不平衡数据集上的罕见点和少数点,总体性能有限,而集成学习可以聚合多个基分类器从而提高分类器泛化性能。所以,我们提出了一种图卷积网络集成学习模型来处理不平衡节点分类问题。具体来讲,将Bagging[5]算法与GCN相结合,通过并行化训练GCN分类器,并根据多数投票方式来确定最终分类结果,从而提高GCN在不平衡节点分类的性能。
实验结果表明,与现有的不平衡节点分类方法相比,本文提出的集成模型显著优于其他基线方法,能更有效地解决不平衡节点分类问题。
1 相关工作
1.1 类不平衡问题
类不平衡问题在实际应用中很常见,长期以来一直是机器学习领域的经典研究方向。针对该问题的传统方法通常可分为三类,即数据级、算法级和混合型。数据级方法通过过采样少数类或欠采样多数类来平衡训练实例,如随机欠采样和SMOTE[6]过采样等。而算法级方法通过为每个类别分配不同的权重来缓解类不平衡问题,如重加权。混合型方法是将上述一个或两个类别的多个算法结合起来,如SMOTEBoost和UnderOverBagging等。此外,研究人员引入了一些新方法,如度量学习、元学习,还有基于神经网络的不平衡数据学习方法,然而,我们的目标是解决图结构上的类不平衡问题,所以这些算法并不适用。
最近,人们提出了一些不平衡网络嵌入方法来解决图结构数据的不平衡学习问题[7-10]。如RECT[11]在学习类级语义嵌入之上提出了两个正则化术语,以解决极端情况下的不平衡学习,DRGCN提出了两种正则化方法来解决不平衡网络嵌入问题,GraphSMote使用GNN编码器学习节点嵌入,并使用额外的边生成器生成连接合成少数节点的边。
1.2 图神经网络
近年来,随着对非欧几里得空间学习和样本间丰富关系信息建模需求的增加,GNN受到了越来越多的关注,并得到了快速发展。GNN将卷积神经网络推广到图结构數据,并在图结构数据建模方面显示出了强大的能力。一般来说,现有的GNN框架可以分为两类,即基于谱域的和基于空域的。基于谱域的图卷积网络通过计算图的拉普拉斯特征分解来定义傅里叶变换中的卷积运算,如GCN,它是目前使用最广泛的GNN之一。基于空域的图卷积网络直接定义在图上,对目标节点及其拓扑邻居进行操作,从而实现对图结构的聚合,如GraphSage。
尽管各种GNN都取得了成功,但是这些方法没有考虑类不平衡问题,由于这一问题广泛存在于现实应用中,可能会降低GNN的性能,因此不适用于不平衡节点分类问题。
2 模型方法
2.1 问题描述
在本文中,我们使用G={V, A, F}表示一个属性网络,其中V={v1,…,vn}是n个节点的集合,A∈Rn×n是G的邻接矩阵,F∈Rn×d表示节点的属性矩阵,其中F[ j,:]1×d是节点j的节点属性,d是节点属性的维度。训练集中,VL代表有标签的节点,YL是其对应的标签,VU代表无标签的节点,YU是其对应的标签,共有m个类别,{C1,…,Cm},|Ci|是第i类的大小,指属于该类别的样本数量,我们使用不平衡率 来衡量类不平衡的程度。给定节点类不平衡的属性网络G,以及节点VL子集的标签,我们的目标是学习一个对多数类节点和少数类节点都有效的分类器f,即f (V, A, F)→Y。
2.2 GCN模型
输入无向图G={V, A, F},其对应的邻接矩阵A∈Rn×n是一个描述其边的n×n稀疏矩阵,如果i和j之间有边,则(i, j)项等于1,否则为0。度矩阵D是对角线矩阵,其中对角线上的值等于每个顶点的度,可以计算为di=∑jaij。每个节点与一个F维特征向量相关联,X∈Rn×F表示所有节点的特征矩阵。我们使用具有两层的半监督分类GCN模型作为基分类器,每层的计算变换为:
(1)
其中, 是通过 获得的归一化邻接矩阵,W(l)是各层的可训练权重。σ(·)表示激活函数(通常为ReLU), 是第L隐藏层的输入激活矩阵,其中每行表示dl维节点表示向量。初始节点表示仅为原始输入特征:
H(0)=X (2)
两层GCN模型可以根据顶点特征X和 定义为:
(3)
GCN通过反向传播学习算法进行训练。最后一层使用softmax函数进行分类,我们求所有标记节点的交叉熵损失值:
(4)
2.3 图神经网络集成模型(Bagging-GCN)
本文结合随机采样和并行集成方法来构造不平衡节点的集成分类学习模型,多个弱分类器与Bagging技术相结合,形成一个强分类器。在训练M个基分类器之后,对M个基分类器的结果进行多数投票,可以预测输入样本的类别,过程如图1所示。
集成模型中的基分类器虽然所用样本数据属于同一个训练集,但是在训练过程中对样本数据的采样与训练是相互独立的,只是对其输出结果进行多数投票。主要原理是利用不同基分类器之间的差异性,通过各分类器的投票结果来降低分类错误,提高模型的泛化能力。具体实现过程如下:
(1)构建单个基分类器:按照实验规定对每一类训练样本进行抽取,结合这些被抽取的所有样本构建基分类器。
(2)形成集成学习系统:对训练集重复执行步骤来构建一组基分类器,并将获取的基分类器用于Bagging集成学习。
(3)结合所有基分类器的预测值,由相对多数投票决定最终的分类结果。
在训练学习的每次迭代中,用相应的训练数据来训练基分类器,M个基分类器经过并行训练之后,根据多数投票原则来确定集成模型的输出。集成模型的伪代码如下:
输入:数据集D={(x1, y1),(x2, y2),(x3, y3),…,(xn, yn)}
基分类器GCN
迭代次数m
步骤:forM=1 to m
DM=bootstrap(D) //使用训练集进行M次采样
GM=GCN(DM) //采样集DM训练第M个分类器
end for
输出:
3 实验结果及分析
3.1 数据集
我们对两个广泛使用于节点分类的数据集Cora和BlogCatalog进行了实验,这两个数据集的详细介绍如下:
Cora是一个引文网络数据集,包含来自7个领域的2 708篇论文,每个节点都有一个1 433维的属性向量,该图中总共有5 429个引用链接。在这个数据集中,类分布是相对平衡的,所以我们使用了一个模拟的不平衡设置:选取三个随机类作为少数类,并对其进行欠采样。所有多数类都有20个节点作为训练集,每个少数类的训练节点数为20乘以不平衡率,不平衡率默认为0.5。选取500个节点作为验证集,并在1 000个标记节点的测试集上进行预测和评估。
BlogCatalog是一个社交网络数据集,共有来自38个类别的10 312名博主和333 983条友谊边缘,数据集不包含节点属性。然后,使用从Deepwalk获得的64维嵌入向量对每个节点进行属性化。此数据集中的类遵循真正的不平衡分布,14个类小于100,8个类大于500。对于此数据集,使用每个类25%的样本进行训练,25%用于验证,其余50%用于测试。
3.2 实验设置
在我们提出的模型中,使用了7个基分类器,所有基分类器都是两层的GCN,学习率为0.01,权重衰减为5×10-4(L2正则化),隐藏单元数为16,dropout设置为0.5,我们采用ADAM优化算法对所有模型进行训练,所有模型都经过训练直到收敛,最大训练周期为5 000,此外,所有实验都是在一台机器上进行的,在Pytorch和Python 3.6中实现。
3.3 评价指标
我们采用了两个评价指标:准确率(ACC)和Macro-F1。ACC同时对所有测试节点进行计算,代表了整体分类的准确率,Macro-F1值常用于不平衡节点分类,能更好地反映不平衡节点分类模型的好坏,每一类的Macro-F1值都是单独计算,然后对其进行非加权平均。
3.4 实验对比模型
为了证明我们提出模型的有效性,我们将其与其他8个基线进行了比较:
Origin:原始实现。
Over-Sampling:直接从少数样本中重复抽样。
Re-weight:将较高的损失权重分配给少数类样本。
SMOTE:通过在输入空间内插值来生成样本。
Embed-SMOTE:通过在嵌入空间内插值对SMOTE进行扩展。
RECT:在学习类级语义嵌入之上提出了两个正则化术语。
DRGCN:通过使用对抗训练范式鼓励潜在嵌入空间中的类之间的分离来解决类不平衡问题。
GraphSMOTE:构造了一个嵌入空间来编码节点之间的相似性,在此空间合成新样本以确保真实性,同时训练边生成器来建模关系信息,并将其提供给这些新样本。
3.5 实验结果
3.5.1 与基线方法的比较结果
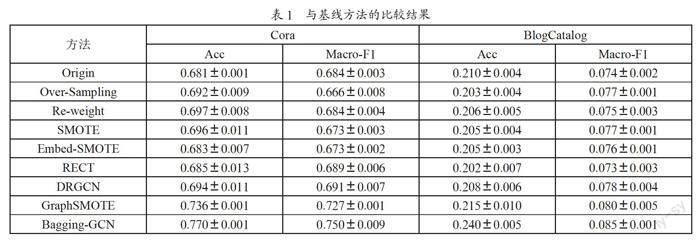
为了评估我们提出的模型在类不平衡节点分类任务中的有效性,我们在上述两个数据集上将其与其他八个基线进行了比较。每个实验进行5次,以减轻随机性。从表1中,我们可以看出,与其他分类模型相比,该模型的表现优于其他所有基线,例如,与GraphSMOTE相比,我们提出的模型在Cora数据集上的Acc值和Macro-F1值分別提高了3.4%和2.3%,这些结果验证了所提出框架的有效性。
3.5.2 基分类器数量的影响
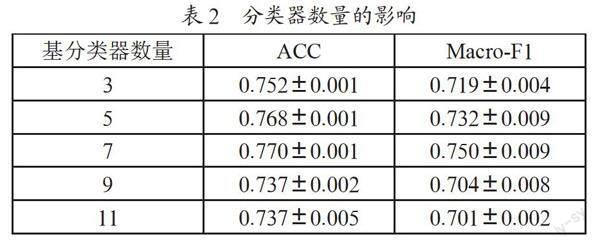
我们改变了基分类器的数量,用不同的评价指标检验了我们提出的模型在Cora数据集上的分类性能。基分类器的数量从3个增加到11个,训练集、验证集和测试集的划分采取前面的方式。我们分别进行了10次实验,每个基分类器分别训练了200个周期,表2显示了实验的平均结果。实验结果表明,当基分类器数量较少时,分类性能随着基分类器数量的增加而提高,当基分类器的数目达到一定程度时,由于过拟合,各项指标都会降低。
4 结 论
在本文中,为了解决图中节点的类不平衡问题,我们提出了一种图神经网络集成学习模型。在所提出的模型中,采用Bagging集成学习方法,多个GCN被用作基分类器,用每个基分类器对数据特征进行提取和学习,所有基分类器并行训练,最后对这些模型训练所得结果进行多数投票确定最终结果。在两个数据集上的实验结果表明,本文提出的方法在不平衡节点分类任务上优于其他基线。在之后的研究中,我们希望将该模型扩展到更多的应用领域。
参考文献:
[1] KIPF T N,WELLING M. Semi-Supervised Classification with Graph Convolutional Networks [J/OL].arXiv: 1609.02907 [cs.LG].[2022-09-26].https://arxiv.org/abs/1609.02907v3.
[2] HAMILTON W L,YING R,LESKOVEC J. Inductive representation learning on large graphs [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates Inc.,2017:1025–1035.
[3] SHI M,TANG Y F,ZHU X Q,et al. Multi-Class Imbalanced Graph Convolutional Network Learning [C]//Proceedings of the 29th International Joint Conference on Artificial Intelligence.Yokohama:[s.n.],2021:2862-2868.
[4] ZHAO T X,ZHANG X,WANG S H. GraphSMOTE:Imbalanced Node Classification on Graphs with Graph Neural Networks [J/OL].arXiv: 2103.08826 [cs.LG].[2022-09-20].https://arxiv.org/abs/2103.08826.
[5] BREIMAN L. Bagging Predictors [J].Machine learning,1996,24(2):123-140.
[6] FERN?NDEZ A,GARCIA S,HERRERA F,et al. SMOTE for Learning from Imbalanced Data:Progress and Challenges,Marking the 15-year Anniversary [J].The Journal of Artificial Intelligence Research,2018,61:863-905.
[7] CHEN D L,LIN Y K,ZHAO G X,et al.Topology-Imbalance Learning for Semi-Supervised Node Classification [J/OL].arXiv: 2110.04099 [cs.LG].[2022-09-20].https://arxiv.org/abs/2110.04099.
[8] WU L R,LIN H T,GAO Z Y,et al. GraphMixup:Improving Class-Imbalanced Node Classification on Graphs by Self-supervised Context Prediction [J/OL].arXiv: 2106.11133 [cs.LG].[2022-09-20].https://arxiv.org/abs/2106.11133.
[9] WANG Y,AGGARWAL C,DERR T.Distance-wise Prototypical Graph Neural Network in Node Imbalance Classification [J/OL]. arXiv: 2110.12035 [cs.LG].[2022-09-20].https://arxiv.org/abs/2110.12035v1.
[10] LIU Y,AO X,QIN Z D,et al. Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection [C]//Proceedings of the Web Conference 2021.Ljubljana:Association for Computing Machinery.2021:3168-3177.
[11] WANG Z,YE X J,WANG C K,et al. Network Embedding With Completely-Imbalanced Labels [J].IEEE Transactions on Knowledge and Data Engineering,2021,33(11):3634-3647.
作者簡介:郭梦昕(1996—),女,汉族,山西吕梁人,硕士研究生在读,研究方向:智能数据开发与应用。
收稿日期:2022-10-07
猜你喜欢
软件导刊(2018年8期)2018-10-29 11:09:14
电子技术与软件工程(2018年24期)2018-05-10 05:10:32
电子技术与软件工程(2018年15期)2018-02-26 07:53:50
电子技术与软件工程(2018年9期)2018-02-25 06:21:08
时代金融(2018年3期)2018-02-07 09:40:23
电脑知识与技术(2017年29期)2017-11-14 16:36:28
科教导刊·电子版(2017年22期)2017-09-20 17:34:04
时代金融(2016年36期)2017-03-31 05:44:10
科技创新与应用(2017年6期)2017-03-23 20:57:00
现代电子技术(2017年1期)2017-02-16 11:32:52
