
计算文献学的概念、范畴及前景
2023-06-18 06:15李斌王东波
图书与情报 2023年1期
李斌 王东波

摘 要:在人工智能和信息技术飞速发展的今天,无论是古典文献的版本、目录、校勘,还是现代文献的管理与研究,都发生着重大变革。纸质文献数字化内容的计量与可视化分析,已经产生了数字文献学和文献计量学的研究范式,而借助自然语言处理技术,文献内容的标注与自动分析也日益丰富。以数字化形态为基本载体,以计算模型为技术手段的文献管理与研究已经成为学界业界的新趋势、新常态。文章提出“计算文献学”这一术语,以统称信息智能时代的新型文献学研究方法与范式。进而以古典文献为对象,提出以人工智能技术进行字符识别、自动断句、标点、标引,版本自动比对、征引,智能排版,形成全数字化整理出版流程,大大加快古籍的整理出版工作。在高质量数字化底本的基础上,建设古典文献知识库,以大数据的知识服务方法,发挥古典文献的社会服务功能。通过多学科协同,培养新时代的文献整理研究的文理复合型人才。
关键词:计算文献学;文献学;古籍数字化;计算人文;数字人文
中图分类号:G256 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2023004
Abstract Today, with the rapid development of artificial intelligence and information technology, major changes have taken place in the editions, catalogs, and collations of classical documents, as well as in the management and research of modern documents. The quantitative and visual analysis of digital content of paper documents has produced the research paradigm of digital bibliology and bibliometrics, and with the help of natural language processing technology, the annotation and automatic analysis of document content are also increasingly enriched. Document management and research with digital forms as the basic carrier and computational models as technical means has become a new trend and new normal state in the academic world. This paper proposes the concept of "computational bibliography" to name the new research method and paradigms of philology in the era of information and intelligence. Taking classical literature, we propose to use artificial intelligence technology for OCR, automatic sentence segmentation, punctuation, indexing, edition comparison, citation, and intelligent typesetting to perform a whole digital emendation and publishing process, which will greatly speed up the emendation and publishing of ancient books. Then, it is urgent to build knowledge bases of classical literature based on high-quality digital documents, and to apply the knowledge service method of big data to classical literature. Finally, through multidisciplinary collaboration, more interdisciplinary students need to be educated in the new era.
Key words computational bibliography; bibliography; ancient book digitization; computational humanities; digital humanities
文獻学是对文献的研究,主要包括中国传统的以版本、目录、校勘为核心的历史文献学,以及从西方引入的以图书情报领域的现代文献学[1]。前者致力于对纸质文献进行内容上的考证与整理,后者更注重利用数学方法进行文献的归类整理与计量研究。随着电子信息技术和人工智能技术的发展,文献学已经发展出了“数字文献学”[2]、“文献计量学”[3]、“E考据”[4]、“人文计算”[5]等新的研究方法和研究范式,给文献学带来了新的活力。本文在梳理这一发展趋势的基础上,指出文献电子化之后除了保存文献内容之外,更重要的是对文献内容的分析和利用。数学计算方法是现代文献学进行数字化、计量分析和计算分析的基础,也是促进传统文献进行数字化考证和活化利用的支撑。但一直缺乏一个比较合适的术语来命名这种新的文献研究方法。因此,本文明确提出“计算文献学”这一学科术语,并论证这一新的技术方法的研究范式和应用价值。
1 从数字文献学到文献计量学
作为现代文献学的数字化转型,数字文献学和文献计量学相继出现。我们可以将二者看作相互依存的两个层面:第一个层面,即数字文献学或电子文献学,主要指用数字化技术来承载和转换传统文献的研究;第二个层面,即文献计量学,主要采用统计方法来挖掘海量文献中隐藏的各种知识。
1.1 数字文献学
数字文献学是随着电子计算机的广泛应用,以文献的电子化为主要研究任务和方法的学科。国际上,在20世纪60年代制定了计算机字符编码标准之后,如1963年的ASCII(美国信息交换标准代码),以手工录入为主的电子文献和目录逐步出现。1964-1969年,美国教育部就建设了教育资源信息中心(ERIC),这是一个教育引文、摘要和文本的数据库[6]。伴随着70、80年代数据库技术的不断发展,又产生了代表性的电子文献目录库 OPAC(在线公共访问目录)[7]。90年代之后,随着互联网的崛起和广泛使用,电子文本开始了爆发式增长。同时,光学字符识别技术(OCR)的兴起,也使得传统的纸质文献得以快速扫描和识别为文字,形成电子文献。国内外的文献电子化研究和整理工作都不断展开[2]。在这种趋势下,2006年,郑永晓明确提出了数字文献(digital document)学,指出数字文献学就是对数字文献的产生、发展、演变、整理、制作、校对、使用、流通、管理等各个流程和环境进行研究的一门新兴学科[8]。
从主要研究内容来看,数字文献学就是用数字化技术,将纸质为主的文献转化为计算机可以存储和处理的数字文献,并用数据库技术进行保存和管理。这是文献的数字化工作,也是用计算技术和统计方法对文献进行分析研究的基础。
1.2 文献计量学
数字化的文献,为“文献计量学”提供了大量的研究资料。在计算机出现以前,已经有了一些使用计算方法对文献进行统计分析的工作,但是过程非常艰辛,大多是依靠手工做卡片和统计。这种纯人工方法,费时费力,效率低下,但是数理统计之后,依然得到了许多值得称道的研究成果,挖掘出了文献中的量化信息。如学界一般将1917年Cole和Eales对300多年的解剖学文献进行的统计分析作为文献计量学的开创性研究[9]。1922年,英国学者Hulme使用了“statistical bibliography(统计文献学)”术语[10]。但受限于效率问题,这些纯手工的文献统计研究一直没有大规模展开,直到20世纪60年代之后,随着计算机的快速发展,一方面电子文献的数量不断增长,另一方面计算机的算力不断增强,使计量研究有了计算机的强力支撑,效率大幅提高,文献的计量研究正式进入了发展期。1969年,英国学者Alan Pritchard提出了新的术语Bibliometrics,意为“Biblio(图书)+metry(计量)+cs(学)”,一般被翻译为“文献计量学”[11]。美国学者Eugene Garfield于1955年在美国《科学》杂志发表《引文索引用于科学》的重要论文[12],系统地提出了用引文索引检索科技文献的新方法,从而打破了分类法和主题法在检索方法中的垄断地位,60年代-80年代,逐步以手工、磁带、软盘、光盘、网络等方式,发布学术文献索引SCI、SSCI、ISTP等,并基于引文索引进行了大量的计量研究。
2 计算文献学
2.1 基于计算的文献数字化
自20世纪90年代以来,基于计算技术的文献学就已经产生。特别是在计算语言学和数字人文领域,展开了文字识别、词法分析、文本风格分析的研究工作。以文字识别技术为例,OCR(Optical Character Recognition,光学字符识别)可以将文献进行光学扫描后,从图片形式转化为字符形式。该技术改变了过去以人工录入为主的文献数字化模式,大大加快了紙质、金石、木刻等载体的文献数字化进程[13]。而在数字化之后,就可以加工为数据库,进行基于字符串的全文检索,从而使得文献可以被更快捷地检索和利用。文本的检索技术,实际上利用的也是计算技术,而且涉及到大量的自然语言处理技术。如词法分析技术,主要可以进行英文单词的词形还原,从而保证检索的完整性。具体来说,检索“buy”这个单词的时候,需要考虑“buys”“bought”等不同的形式。而在汉语中,虽然不需要词形还原,却需要进行自动分词,以保证检索的准确性。如检索“和尚”时,如果文献没有经过词语的切分处理,就会检索出“和-尚未”“和-尚且”等大量的错误干扰项。在国际上,基于字符串和词串的检索技术也已经在搜索引擎和各种检索平台上广泛应用。
因此,在进行汉字文献的电子化、检索与计量分析时,“计算”已经成了必不可少的技术和流程。但是,汉字文献没有词语边界,如果不进行词语的切分,只能做基于字和字符串的统计,这对于基于词和概念的很多研究来说是非常不便的。在汉字文献的检索上,想实现基于“词”的检索,就必须采用自然语言处理的计算技术进行自动分词[14]。OCR、词法分析、索引和检索技术已经成了制作检索平台的基础。因此,在国内外的许多研究论文中,都出现了“基于人工智能”“基于计算”“智能分析”“计算分析”“数智”等字样的文献学研究[15],一个新的术语呼之欲出。
2.2 基于计算的文献计量学
20世纪90年代之后,电子文本呈爆发式增长,计算机的算力也迅速提升。文献计量学,也从简单的数据统计、引文分析,进一步发展为对文本的词频进行分析,观察出现的作家、作品、词语的频次与相关关系,挖掘代表人物、代表作品、研究热点与前沿,还用于学术热点追踪,学科评价等,近年来也逐步拓展到医学文献、法律文献等领域知识的挖掘[16]。
可以看出,文献计量学已经越来越多地使用计算机来进行海量电子文献的计量分析,而超越统计方法的人工智能领域的技术,诸如机器学习的分类、聚类,自然语言处理的文本自动分析、情感分析、自动摘要、机器翻译,复杂网络分析与可视化技术等,都不断地被应用到文献内容的挖掘与分析中。在这种趋势下,已经催生出了基于“计算”的新型文献学,但始终没有一个合适的术语指称。
2.3 计算文献学的提出
基于在数字时代文献学自身的发展,和文献内容深度研究的科学需求,本文提出“计算文献学(Computational Bibliography)”的术语。这个新术语主要强调采用计算技术,进行文献的扫描、录入、数据化、索引、检索、自动标引、自动分词、统计分析、可视化交互、智能应用等新型的文献学研究技术和研究范式。
在计算的视角下,文献的数字化、计量分析、可视化,都是计算文献学的研究内容,从而把基于计算的文献学纳入到一个整体的框架中,避免条块分割。数字文献学、E考据、文献计量学、计量风格学、文献可视化、文献内容挖掘、文献元宇宙等,实际上运用了大量计算技术和方法的研究,也都可以归入计算文献学的范畴中,不仅便于学术界和业界的指称和交流,还可以将研究聚焦于计算技术,加强计算技术与方法的研究、教学和应用。所以计算文献学对文献学新形式的概念释义,更是将古典文献学和现代文献学在计算框架下融合与发展的自然产物。
计算文献学是一门以计算机科学和文献学等多学科进行交叉研究的学科,以文献特别是数字化文献为研究对象,以传统的人文学科和文献研究法为指导,以数学模型、计算技术为代表的新方法技术为支撑,服务于信息化、智能化时代对文献数字化、文献内容的结构化、知识化、多模态化,满足学术研究、知识服务等社会需求(计算文献学的基本架构见图1)。
计算人文以计算方法与技术对更广阔的人文领域进行体系化、深入化和精细化的计算研究。计算文献学是在新时代信息智能的条件下和计算人文的整体框架下针对海量的典籍文献展开的一系列计算研究,在学科定位上更加专注,符合现有古典文献、图书情报等相关学科的研究、教学及未来发展。作为一门新兴交叉学科,计算文献学既可以作为图书情报学、文献学和计算机应用技术的子学科,从细分学科上也可以作为计算人文的分支学科内容。
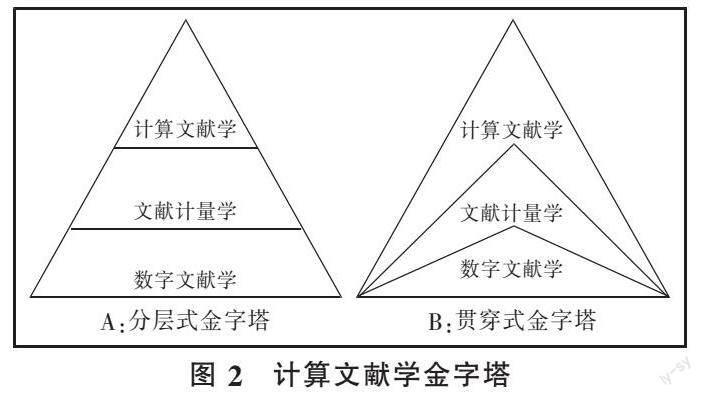
3 计算文献学的金字塔
我们可以把计算文献学看作数字文献学和文献计量学之后的第三个层面。一般来说,计算文献学是在文献计量学之后,更注重采用计算技术、人工智能、复杂网络与可视化的高技术层面。三个层面形成一个典型的金字塔结构(见图2-A)。然而,三者现实的关系应该是贯穿式金字塔(见图2-B)。
首先,数字文献学提供了数字化的文献,是计量和计算的基础;其次,文献计量学可以在电子文献的基础上,开展各种统计分析研究。但是,文献计量的研究成果,也可以服务于数字文献学,是可以下探到底层的。如对异体字的字频和词频的统计分析,可以对古籍文献的电子化进行规范,尽可能处理好正体字和异体字的关系,以满足全文检索的需求。
计算文献学则贯穿了前面两者。一方面,以OCR和文本纠错技术为代表的计算技术,在文献数字化的过程中作用巨大,可以大大提升速度与质量,大大减少人工的录入和校对工作;另一方面,以自动分词、自动标引、文本挖掘为代表的计算技术,大大拓展了文献计量学的研究方法和技术,可以统计出比字面信息更多更深入的信息。甚至可以说,计算文献学占据了整个金字塔,为数字文献学和文献计量学提供了基础的技术支持和研究方法。
这个金字塔,也可以用三句话来解读,文献数字化需要计算技术,文献计量与内容挖掘需要计算技术,文献可视化与应用需要计算技术。
4 计算文献学的特点与发展前景
4.1 计算文献学的两大特色:大数据和计算
(1)大数据。在当前数字化社会的发展趋势下,新的文献爆炸式增长,每天都有数以亿计的电子文献在互联网上涌现。而古籍文献数字化的不断推进,每年也会扫描和整理上亿字的古籍。大数据是事实,是现状,也是未来的常態。
(2)计算。计算是指的计算能力和计算模型。首先,海量的数据,靠个人的力量,是无法阅读、整理、掌握和分析的。大数据离开计算技术,也只是一堆无用的存储。数据越大,越需要新的算法模型作为支撑,强大的软硬件算力作为基础;其次,目前深度学习技术已经在OCR、自动分词、标引等方面取得了突破性进展,将来还会有更多的智能计算技术涌现出来,不断增强文献的内容分析与智能应用性能;最后,量变很可能产生质变,在超大数据规模和智能算法的加持下,易于在宏观的时空尺度上,发现语言、社会、文化的历时演化和隐秘的关联,也可以在微观层面上挖掘出以往不为人们关注到的现象,从量化分析得出新的定性认识和结论。
4.2 计算文献学的交叉性
计算文献学,既需要传统文科的知识体系作为定性研究的支撑,又需要各种新技术作为定量与建模计算分析的基础,因此是一门综合性、交叉性非常强的学科。
(1)文献内容涉及各类学科,需要大量不同领域的知识。由于文献的基本载体是语言文字,文献的内容包罗万象,本身就涉及人类知识的方方面面。如传统的人文科学,包括文学、语言、历史、哲学、艺术、法律、教育等,都涉及其中。如果是科技类文献,自然也包括数学、物理、化学、地理、生物、计算机等。计算文献学自然也要以传统文献学和现代文献学已有的方法为基本的指导,解决文献学的传统问题。
(2)文献的数字化和计量需要各种计算技术。如前所述,数学、计算机、人工智能技术都在文献的数字化和计量研究中扮演了重要角色。具体来说,数学中的计算数学、数学建模、微积分、线性代数、数理统计、离散数学、复杂网络等都是基本的数学工具。计算机科学与技术中的人工智能技术(如机器学习、自然语言处理、图像文字识别技术、知识工程、知识图谱等)、信息检索技术(如全文检索、词检索、多模态检索等)、程序设计(如C、PYTHON、JS等)、数据库技术(如网络数据库、数据安全、多模态数据库等)、人机交互技术(如可视化技术、用户界面设计、用户画像等)、虚拟技术(如VR、AR、元宇宙等)、互联网技术(如多终端联动等)则是进行统计、计算和网络检索与可视化服务的支撑。
(3)研究方法与研究人员的交叉性。要分析和处理某个领域的文献,既需要这个领域的专家学者,根据其专业领域的知识体系进行研究,还需要与计算技术的专家共同合作,根据具体的问题,以计算建模的方式进行定量研究,形成定性的结论和知识服务。而能够通晓专业领域与计算技术的复合型人才,往往能更加得心应手地进行这种交叉研究。计算文献学本身,就是给与传统的文献管理和研究以计算技术的加持,培养这种掌握计算技术的新型文献学人才,已经是图书情报学界正在开展的事业。传统文献学则因为要掌握大量的古代语言和文史知识,在培养文理兼通的人才方面难度较大,是将来值得发展的方向[17]。
4.3 计算文献学的发展前景
计算文献学需要处理超大规模文献数据,运用前沿科技,与诸多学科协同研究,其发展前景也充满了多样性。
对于传统文献学来说,可以开拓新的研究领域,将传统的古籍进行数字化,进而计算分析与利用,还可以将古籍版本、字词考证、点校等工作进行智能化技术升级,下一章详述;对图情学来说,计算文献学对计算技术的倚重,可以更好地在文献数字化、量化分析与智能应用方面发挥作用。特别是知识图谱构建和知识服务领域,很可能出现诸多新的算法和应用,推进文献内容的知识库构建与个性化知识服务;对于语言、文学、历史、哲学等倚重文本内容的学科来说,计算文献学可以为之提供更为丰富的文献数据库、高度结构化的文史数据、文本内容智能分析技术和各种可视化分析呈现。
服务于定量与定性研究。过去人们对大数据有一种误解,即大数据只能做定量分析,难以做定性研究。随着回归分析、假设检验、自动聚类、自动分类、复杂网络分析等方面的算法不断完善,在文献大数据上进行定性研究已经成了新的趋势[18]。如利用语言数据和贝叶斯模型来研究原始汉藏语系,已经获得了初步的研究成果[19]。将来人们掌握了中国及周边国家地区的多语言文献数据,形成大规模数据库,在计算文献学方法指导下,可以对中国的历史、语言、文化,以及多文化、多语言、多民族的交流历史,在数千年的大尺度框架下,通过分类、聚类、复杂网络等分析技术,来形成新的认识和结论。
除了学术服务之外,还可以产生较大的经济效益和社会效益。高校和企业联合开发,可以产生多样的学术性、商业化文献知识服务平台和应用。未来的文献内容服务,将不只是字符级别的全文检索,而是基于内容的知识检索和知识服务。借助ChatGPT①这样的个性化问答服务技术,加之越来越大的文献数据,可以进一步开发个性化的知识学习系统、文献管理助手、实时知识获取与分析等应用,让海量的文献更好地为人服务。
5 基于计算文献学的中国古籍活化利用
中国古典文献浩如烟海,是一笔取之不尽、用之不竭的文化财富。然而,古典文献的整理工作无比艰巨,不仅包括标点、校勘、注释等工作,还需要编制书目、索引、辞书等。我国古典文献总数迄今尚无定论,总量估计超过20万种、20亿字。根据《古籍整理图书目录(1949-1991)》记载,1978-1990年,我国共整理出版古典文献4360种。若全部以人力来进行古典文献的整理工作,那将花费数百年时间。拥有大量汉字古籍的日本已经展开了文献数字化的整理工作,在技术加持下形成了诸多古籍文献数据库[20]。
计算文献学可以为古典文献学研究带来新工具、新思路。中文OCR、自动标引、专名识别等技术的应用为古典文献的整理工作带来重大利好。古典文献全文库、知识库的建设大大满足了学术界、大众获取古典文献内容的需求。将现代科技应用到古典文献的整理工作中,将极大提高我国古典文献整理出版工作的效率,促进我国古典文献在新时期持续发挥价值。
5.1 以计算技术打通古典文献全数字化整理出版流程
古典文献整理工作往往依托历史和“三古”专业(即古代文学、古代汉语和古典文献学专业),主要工作有版本校勘、文字训诂、句读标点、注释等工作。直至目前,古典文献整理出版主体仍然集中在古籍出版社与高校。
目前,古籍OCR的识别正确率大幅提高,达到95%以上,自动句读、自动标点、专名识别等技术也都可以达到90%-95%的正确率。经过计算机的处理之后,只要辅以人工校正,整理效率就能实现巨大飞跃。除此以外,古文献的断句、标点、分词、词性标注、命名实体识别都达到了实用水平[21]。在第一届古汉语国际评测EvaHan2022上,分词准确率达到了96%以上,词性标注准确率达到了92%以上[22]。
在高校和出版社的探索下,目前古典文献整理工作已经实现了数字化工具整理、人工校对的半自动化流程,出现了一些古典文献整理平台辅助工作。成立于2015年的古联(北京)数字传媒科技有限公司是中华书局的全资子公司,它建设运营的国家级古籍整理出版资源平台“籍合网”①在2018年上线。“籍合网”中包含引文核查、专名识别、自动标点、繁简转换、OCR识别等服务,通过采用众包的方法,流程化、大规模开展古籍编校工作。2018-2022年,通过“籍合网”整理的古籍文本约为14亿字,极大推进了古典文献整理的进度。浙江大学的“智慧古籍平台”②集成了OCR识别、智能标点功能,采用众包机制,可使古籍整理者突破地域限制,高效地完成线上整理工作。这些数字化平台协助传统古典文献整理工作者完成基础的校对、标引等工作,大大减轻了劳动量[23]。
2022年10月,全国古籍整理出版规划领导小组发布《2021-2035年国家古籍工作规划》(以下简称《规划》),将国家古籍数字化工程作为重大工程,鼓励古籍数字化与古籍整理出版工作同步推进、紧密结合,推动古籍整理出版数字化资源库建设。在将来,学界和业界需投入到古典文献全数字化整理平台的建设中,搭建出从文本识别、标引、校对到编辑出版全数字化、智能化的整理流程。通过技术赋能,为我国古籍整理工作者减轻负担。如文献中包含有大量难以识别的罕用字、异体字等,未来古典文献汉字库建设完成后,将极大满足古典文獻整理与出版工作中的实际需求。
5.2 以知识工程技术建立新型古典文献知识库
古籍数字平台的演化不仅给古籍整理工作带来了重大转变,还推动了古典文献知识库的建立。传统古典文献整理工作的目的是将古典文献转化为便于当代人阅读的文本,不仅投入人力大、耗费时间长,而且由于大多数文献内容丰富、艰深,难以被普通大众接受。因此,传统的古典文献整理工作主要服务对象为学术研究者。若想使我国古典文献中蕴含的文化知识财富被普罗大众接受,就必须适应时代需求,转换古典文献整理的成果形态。古籍全文数据库和图文数据库,大多保留了古籍面貌,便于用户检索浏览。
近年来,随着人工智能与信息技术的进一步发展,古籍数字化工作有了新理念、新方法。古籍自动分词[14]、智能标引、专名识别[21]、地理信息[24]、知识工程和知识图谱[25]等技术,可以将古籍的文字转化为结构化的知识数据,构建新型的古典文献知识库。这样,蕴藏在古典文献中的深层知识可以用诸多算法技术挖掘出来,以可视化技术呈现在人们眼前。此外,知识库革新了知识的构建方式,改变了古籍知识纯文本的显示方式,将古典文献中的知识以可视化、可交互化的方式重组,不仅便于学术研究者更加直观、便利地获取古典文献中的知识,也可以增加大众读者对传统文献的接受度。
国际上古典文献知识库的建设自20世纪末便已经开始,“中国历代人文传记资料库(CBDB)”于20世纪90年代建立,是全球较早进行数据结构化的古籍知识资料库[26]。目前,国内对于古典文献知识库的建设已经有了部分探索性工作,主要包括图书目录数据库、专题知识库、专书知识库、综合性知识库等。古籍目录数据库主要收录图书的作者、年代、品级等信息,服务于题录检索,相对比较成熟[27];专题知识库主要有人物传记数据库和历史地理数据库,记录历史人物的生平、社交关系、古代历史电子地图等信息;专书知识库则专注于某部古籍,进行内容的深度标注与结构化。在这一方面的实践中,已经有了一些较为显著的成果,主要集中在高校的科研单位中。南京师范大学开发的“《资治通鉴》知识库检索平台”引入古籍自动分析技术和GIS技术,建设了数字人文知识库,解决了人名、地名的“异名同指”和“同名异指”问题,通过对文本进行深度加工和知识重组,提取相关信息并进行本体化处理,实现了基于语义的检索和阅读浏览功能[28]。北京大学数字人文中心开发的“《宋元学案》知识图谱系统”将书中的人物、时间、地点等要素及它们之间的复杂语义关系提取出来构建为知识图谱,并具备可视化展现、交互式浏览、语义查询等功能[26]。古典文献数据库从数字化到智能化的转变,意味其实现了功能性提升与结构性转变。
目前我国还缺少大而全的综合性古典文献知识库,这一工作在探索期过后便能提上建设议程,一旦建设完成,将会大大推动古典文献在大众层面的普及工作。目前已建立的古典文献知识库,已能够为古典文献研究者和整理工作者带来了思维方式和研究范畴的新变。一方面,以“知识库”形态为建设目标本身就是对传统古典文献整理工作的一次革新;另一方面,古典文献知识库能作为辅助研究工具,为相关研究者提供便利的知识获取途径。大数据带来的数据聚类化研究,也能便于对传统的知识进行验证与修正。因此,建立在古典文献数字化整理上的古典文献知识库,会成为信息化时代的古典文献研究、传播的新工具、新途径。
6 结语
在数字化高速发展的信息时代,我们面临着文献的爆炸式增长,海量的古籍文本也亟待数字化。本文梳理了国内外的研究发展趋势,得出无论是文献数字化,还是文献内容的结构化表示与内容分析挖掘,都需要计算技术和方法的基础性支撑,并从这一趋势出发,提出了“计算文献学”这一学科性的术语。计算文献学强调“计算”在当前和今后将成为文献学研究的重要技术和方法论,明确了该学科与“数字文献学”和“文献计量学”的贯穿式继承关系。本文还指出,计算文献学具有大数据和计算的两大特色,其学科交叉性也不只体现在学科知识和技术的交叉,更是研究方法与研究人员的交叉合作,可以将其置于“计算人文”的下位学科。最后,本文提出,要以计算文献学为框架,打通古籍数字化整理和出版的全流程,构建新型古籍知识库,从而活化利用中国的古代文献。
“计算文献学”这一术语的提出,仅仅是一个起点。我们希望这个术语能够促进文献学特别是传统文献学的技术方法升级,传承和发掘传统文献中的精华;在大数据的视野下对文献做出数千年的历时分析与国内外多语言文献的横向分析;吸引更多的年轻学者加入到这个领域中来,培养更多的复合型人才,助力民族伟大复兴。
致谢:冯志伟教授、郑永晓教授和审稿人的宝贵修改意见。
参考文献:
[1] 王余光,汪涛,陈幼华.中国文献学理论研究百年概述[J].图书与情报,1999(3):12-19.
[2] 杨清虎.数字文献学的概念与问题[J].黑龙江史志,2013(13):203.
[3] 趙蓉英,许丽敏.文献计量学发展演进与研究前沿的知识图谱探析[J].中国图书馆学报,2010,36(5):60-68.
[4] 黄一农.从E考据看避讳学的新机遇:以己卯本《石头记》为例[J].文史,2019(2):205-222.
[5] 黄水清.人文计算与数字人文:概念、问题、范式及关键环节[J].图书馆建设,2019(5):68-78.
[6] Ted Brandhorst.The Educational Resources Information Center(ERIC)[A].Allen Kent.Ed.Encyclopedia of Library and Information Science[C].New York:Marcel Dekker,Inc.,1993,51(S14):208-225.
[7] Babu B Ramesh,Ann oBrien.Web OPAC interfaces: an overview[J].The electronic library,2000,18(5):316-330.
[8] 郑永晓.古籍数字化对学术的影响及其发展方向[J].社会科学管理与评论,2006(4):81-88.
[9] Cole F T,Eales N B.The History of Comparative Anatomy[J].Science Progress,1917(11):578-596.
[10] Hulme E W.Statistical bibliography in relation to the growth of modern civilization:two lectures delivered in the University of Cambridge in May,1922.author,1923.
[11] Pritchard Alan.Statistical Bibliography or Bibliometrics[J].Journal of Documentation,1969,25(4):248-349.
[12] Garfield,Eugene.Citation indexes for science:A new dimension in documentation through association of ideas[J].Science,1955,122(3159):108-111.
[13] 郭利敏,葛亮,刘悦如.卷积神经网络在古籍汉字识别中的应用实践[J].图书馆论坛,2019,39(10):142-148.
[14] 石民,李斌,陈小荷.基于CRF的先秦汉语分词标注一体化研究[J].中文信息学报,2010,24(2):39-45.
[15] 雷珏莹,侯西龙,王晓光.数智时代古籍数字化再造的逻辑与进路[J].数字人文研究,2022,2(2):46-56.
[16] 邱均平,段宇锋,陈敬全,等.我国文献计量学发展的回顾与展望[J].科学学研究,2003(2):143-148.
[17] 杨海峥,王军.对新时代古籍人才培养的思考[J].出版广角,2022(12):6-10,30.
[18] Mills Kathy A.Big data for qualitative research[J].Taylor & Francis,2019.
[19] Zhang M,Yan S,Pan W,et al.Phylogenetic evidence for Sino-Tibetan origin in northern China in the Late Neolithic[M].Nature,2019,569(7754):112-115.
[20] 郑永晓.传承与超越:数字文献学的未来发展刍议——兼论日本文献数字化对我国之启示[J].中国比较文学,2019(4):2-13.
[21] 黄水清,王东波.古文信息处理研究的现状及趋势[J].图书情报工作,2017,61(12):43-49.
[22] Bin Li,Yiguo Yuan,Jingya Lu,et al.The First International Ancient Chinese Word Segmentation and POS Tagging Bakeoff:Overview of the EvaHan 2022 Evaluation Campaign[A].In Proceedings of the Second Workshop on Language Technologies for Historical and Ancient Languages[C].Marseille,France.European Language Resources Association,2022:135-140.
[23] 刘石.文献学的数字化转向[J].文学遗产,2022(6):10-13.
[24] 张萍.地理信息系统(GIS)与中国历史研究[J].史学理论研究,2018(2):35-47,158.
[25] 楊海慈,王军.宋代学术师承知识图谱的构建与可视化[J].数据分析与知识发现,2019,3(6):109-116.
[26] 包弼德,王宏苏,傅君劢,等.“中国历代人物传记资料库”(CBDB)的历史、方法与未来[J].数字人文研究,2021,1(1):21-33.
[27] 李文琦,王凤翔,孙显斌,等.历代史志目录的数据集成与可视化[J].中国图书馆学报,2023,49(1):82-98.
[28] 常博林,万晨,李斌,等.基于词和实体标注的古籍数字人文知识库的构建与应用——以《资治通鉴·周秦汉纪》为例[J].图书情报工作,2021,65(22):134-142.
作者简介:李斌,男,南京师范大学文学院副教授;王东波,男,南京农业大学信息管理学院教授。
猜你喜欢
河南图书馆学刊(2017年6期)2017-06-30
河南图书馆学刊(2017年5期)2017-05-31
西夏研究(2017年2期)2017-05-16
大学图书馆学报(2017年1期)2017-03-25
大学图书馆学报(2016年5期)2017-02-18
大学图书馆学报(2016年5期)2017-02-18
大学图书馆学报(2016年3期)2016-12-29
西藏研究(2016年2期)2016-06-05
中医文献杂志(2014年6期)2014-02-28
河南理工大学学报(社会科学版)(2013年3期)2013-03-11
