
考虑综合需求响应的电-气-热综合能源系统低碳经济调度
2023-06-10 09:55:20王海鑫周夕然杨俊友
华北电力大学学报(自然科学版) 2023年3期
董 健, 王海鑫, 周夕然, 高 柳, 杨俊友
(沈阳工业大学 电气工程学院,辽宁 沈阳 110870)
0 引 言
综合能源系统(integrated energy system,IES)作为能源互联网发展的重要载体,对于多种能源协同运行、提高能源利用效率和实现低碳运行起到关键作用[1]。但随着多种能源耦合加深、风光出力的波动性以及多能源需求的不确定性,综合能源系统优化运行面临巨大挑战[2]。综合能源的经济调度问题是发展综合能源系统、提高能源效率的基础[3,4]。
目前国内外对于综合能源系统经济调度已有一定研究。文献[5]针对区域电热综合能源系统,利用电锅炉、储热罐和蓄电池建立考虑网络传输特性的协调模型,采用双λ迭代算法求解。文献[6]考虑多种类型发电和储能约束,建立可再生能源和多能源需求优化模型,实现多能源需求综合利用和协同优化。文献[7]提出一种基于模型预测控制(model predictive control, MPC)动态时间间隔的IES调度方法。利用MPC中的轨迹偏差、能量及成本控制框架处理调度时间间隔内的需求和约束。上述文献主要通过建立综合能源系统物理模型,对优化目标函数求解,在一定程度上解决了综合能源系统优化调度问题。但上述方法局限于固定日前调度计划,不能根据新能源出力与负荷需求的实时动态变化进行调整。
在综合能源系统的低碳运行方面,文献[8]提出基于碳交易机制的优化调度模型,发电厂在碳交易市场可自由购买或出售碳配额。结果表明,考虑碳交易可降低综合能源系统的运行成本。文献[9]提出一种考虑电、热、冷负荷不确定性的低碳电力系统经济调度方法。文献[10]建立微型燃气轮机(micro turbine,MT)和电转气(power to gas,P2G)机组联合使用的优化调度模型,通过场景生成和场景缩减技术获得典型负载场景,提高风电消纳,减少二氧化碳排放。上述文献虽然能够实现系统的低碳运行,但没有考虑负荷侧的柔性资源。
近年来,强化学习(reinforcement learning,RL)在电力系统的优化控制中越来越受到重视[11,12]。文献[13]提出基于深度强化学习的微电网实时能量管理系统,微电网能源管理被建模为一个马尔可夫决策过程(MDP),以最小化日常运营成本为目标。同时加入深度前馈神经网络来逼近最优动作值函数,并采用深度Q网络(deep Q network,DQN)算法训练神经网络。文献[14]提出了一种基于深度确定性策略梯度(deep deterministic policy gradient,DDPG)的综合能源系统的优化调度方法,该方法能够解决连续动作控制问题,但在求解时容易出现估计值过高问题。上述文献为深度强化学习方法在综合能源系统的应用提供研究基础,通过离散能源系统中连续的动作进行控制,但控制精度不准确。
综上所述,本文提出一种基于A3C的电-气-热综合能源系统优化调度方法。首先,考虑综合能源系统中电-热-气网的运行约束以及能源供需侧的多种不确定性因素,充分利用负荷侧柔性资源,研究在不需建立系统复杂物理模型的情况下综合能源系统的低碳经济调度问题。其次,将优化问题描述为马尔科夫决策过程,建立综合能源系统环境模型,设计智能体的动作空间、状态空间和奖励机制。最后,通过仿真算例分析该方法的收敛能力和稳定性,验证该方法在综合能源系统低碳经济调度时的有效性。
1 综合能源系统模型与问题描述
综合能源系统运行优化的首要目标是在满足系统安全运行的约束下提升系统经济效益,即在满足用户负荷需求的前提下,以最优经济运行为目标,有效调度各设备在每个时段的出力[15]。本文研究的IES结构如图1所示。综合能源系统中主要包括可再生能源(renewable energy,RE)、MT、P2G、电热锅炉(electric boiler,EB)、蓄电池(electricity storage,ES)、储热罐(heat storage,HS)和储气罐(gas storage,GS)。
1.1 综合能源系统数学模型
(1)燃气轮机
以天然气为动力的燃气轮机是热电联产系统的关键设备。燃气轮机数学模型如下式所示:
PMT,t=GMT,t·ηMT
(1)
HMT,t=GMT,t·(1-ηMT-ηloss)
(2)
式中:PMT,t和HMT,t分别为燃气轮机在时段t的电功率和热功率;GMT,t为燃气轮机在时段t天然气的消耗功率;ηMT为燃气轮机的发电效率;ηloss为燃气轮机的能量损失系数。
(2)P2G数学模型
电转气设备产生的天然气量与消耗电功率关系如式(3)所示:
GP2G,t=ηP2G·PP2G,t
(3)
式中:GP2G,t为P2G设备在t时刻天然气输出功率;ηP2G为P2G设备转化效率;PP2G,t为P2G设备在t时刻消耗的电功率。
(3)电热锅炉
电热锅炉将电能转化为热能,把水加热至有压力的热水或蒸汽(饱和蒸汽),用于补充燃气轮机供热不足时剩余热负荷需求。其消耗电功率与产生的热量关系由式(4)表示。
HEB,t=ηEB·(1-μLoss)·PEB,t
(4)
式中:HEB,t表示电热锅炉t时刻输出的热功率;PEB,t表示电热锅炉t时刻的耗电功率;ηEB表示电热转换效率;μLoss表示电热锅炉热损失率。
(4)储能设备模型
在综合能源系统中加入各类的储能设备可缓解风光出力不确定性、平稳负荷波动,增加系统运行经济性。储能设备数学模型如式(5)所示,储能设备采取放能操作如式(6)~(7)所示。
(5)
ax,ch,t,ax,disch,t={0,1},∀t∈T
(6)
ax,ch,t,ax,disch,t=0,∀t∈T
(7)
式中:x为能源类别,其中ES表示蓄电池,GS表示储气罐,HS表示储热罐;Sx,t+1和Sx,t分别为储能设备x在t和t+1时刻的存储能量;Px,ch,t和Px,disch,t为储能设备x在t时刻的充能和放能功率(Px,ch,t≥0,Px,disch,t≤0);Qx为储能设备x容量;ηx,ch和ηx,disch是指储能设备x的充能和放能效率;Δt为时间间隔;T为调度总时段;ax,ch,t和ax,disch,t分别为充能和放能的状态参数,ax,ch,t=1表示在t时刻储能设备采取充能操作,ax,disch,t=1表示在t时刻储能设备采取放能操作。
1.2 综合需求响应模型
在综合能源系统中加入综合需求响应有利于实现系统经济运行,提高系统运行的可靠性。用户参与综合需求侧响应(integrated demand response,IDR)后通过消减、转换能源供给方式将负荷高峰时期的能源需求转移到低负荷用电时段,通过较低电价满足高峰时期的负荷需求,提高系统运行经济性。
可转移负荷的需求响应方式主要为用电高峰时段的电负荷转移到其他时段,转移负荷总量在调度周期内保持不变,如式(8)所示。
(8)
式中:P′Load,t和P′Load,t+υ分别为t时刻和t+υ时刻转移后的电负荷;PLoad,t和PLoad,t+υ分别为t时刻和t+υ时刻转移前的电负荷;PTra,t为从t时刻向t+υ时刻转移的电负荷。
可中断负荷需满足的运行条件如式(9)所示。
P′Load,t=PLoad,t-PInt,t
(9)
式中:PInt,t为t时刻中断的电负荷。
可转换负荷在用电高峰时期将用电需求转为其他能源种类。负荷转换模型如式(10)所示。
PCon,t=φPGGCon,t
(10)
式中:PCon,ta为电网在t时刻转换后减少的电负荷;GCon,ta为气网在t时刻转换后增加的气负荷;φPG为负荷转系数。
1.3 目标函数
本文所提综合能源系统的优化调度是在保证系统安全运行的条件下,通过协调能源转换设备与储能设备的出力,充分利用负荷侧资源。在满足系统负荷需求的同时减少能源购买成本,节约系统运行成本。优化目标函数如式(11)所示。
F=min(CP+CG+CIDR+CC)
(11)
式中:CP是系统的购电成本;CG是系统的购气成本;CIDR是IDR的调用成本;CC为系统碳交易成本。其中,系统的购电成本CP如式(12)所示。
(12)
式中:σP,t为t时刻电价;PE,t为t时刻购电功率。
系统购气成本CG如式(13)所示。
(13)
式中:σG,t为t时刻购买天然气的单位热值价格;GG,t为t时刻的购气功率。
IDR调用成本CIDR如式(14)所示:
(14)
式中:aTra、aInt、aCon分别可转移负荷、可中断负荷和可转换负荷的成本系数。
碳交易成本CC如式(15)所示。
CC=σCO2(MP,t-MS,t)Δt
(15)
式中:σCO2为碳交易成本系数;MP,t为综合能源系统在t时段的碳排放量;MS,t为综合能源系统在t时段的碳配额。其中,MP,t由式(16)计算。
MP,t=(γE,CO2PE,t+γMT,CO2PMT,t)Δt
(16)
式中:γE,CO2和γMT,CO2分别为电网购电和燃气轮机的碳排放系数。
1.4 约束条件
(1)系统平衡约束
为满足运行时各时段电-气-热负荷需求,系统平衡约束需满足以下约束,如式(17)~(19)所示。
(17)
GG,t+GPtG,t+PGS,disch,t-GCHP,t-PGS,ch,t=
GLoad,t+GCon,t
(18)
HCHP,t+HEB,t+PHS,disch,t-PHS,ch,t=HLoad,t
(19)
式中:PE,t为t时刻从电网的购电功率;GG,t为t时刻从气网的购气功率;PLoad,t、GLoad,t和HLoad,t分别为t时刻的电负荷、气负荷和热负荷。
(2)设备运行约束
燃气轮机需满足功率约束和爬坡约束如式(20)~(21)所示。
(20)
(21)
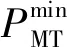
P2G需满足功率约束和爬坡约束如式(22)~(23)所示。
(22)
(23)
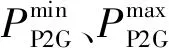
电加热炉所满足的运行约束如式(24)所示。
(24)
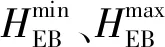
储能设备需要满足充放电功率约束以及容量约束由式(25)~(28)表示。
(25)
(26)
(27)
Sx,1=Sx,T
(28)
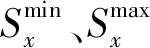
可转移负荷需满足约束由式(29)表示。
(29)
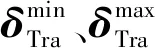
可中断负荷需满足约束由式(30)表示。
(30)
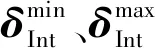
可转换负荷需满足约束由式(31)表示。
(31)

2 电-气-热综合系统优化调度的深度强化学习模型
本节首先将综合能源系统的优化调度问题转换为马尔科夫决策过程,然后阐述基于Actor-Critic架构A3C算法的原理以及训练过程。本文采用基于深度强化学习的方法,主要通过数据驱动的方式解决了综合能源能源系统调度中的不确定性问题,同时可以准确适应系统源荷动态变化,实现快速求解。
具体的调度过程为,在每一优化调度时刻,Agent得到当前时刻的状态变量主要包括电池的荷电状态SES,t、储气罐的容量SGS,t、储热罐的储热量SHS,t、风机发电量Pwind,t、光伏发电量PPV,t、电负荷PLoad,t、气负荷GLoad,t、热负荷HLoad,t以及时刻t,然后Agent计算得到采取当前动作时下一时刻状态的转移概率和获得的奖励。因为Agent得到了不同场景下的大量训练,所以可以做出当前时刻下更优的调度决策。
2.1 马尔科夫过程转换
RL主要通过智能体与环境之间的交互学习策略达到控制目的,其学习过程本质为MDP[21]。MDP的5个基本要素为状态空间Σ、动作空间Α、转移函数Τ、奖励函数Ρ和折扣系数γ。其中,转移函数描述了给定动作下智能体由状态st转变为st+1的概率:T:S×A×S→[0,1],其中S为状态st的集合,A为动作at的集合。在本文中,智能体通过调节综合能源系统源荷出力进行最优调度决策。在每个优化时刻t,智能体根据当前状态st以及策略函数π在可能的动作集合A中选择对应的动作at,智能体接收到下一个状态信息st+1以及奖励值Rt,然后重复上述步骤直到优化结束。
(1)状态空间
状态空间st主要由智能体的观测状态组成,如式(32)所示。状态空间主要包括储能电池的荷电状态SES,t、储气罐的容量SGS,t、储热罐的储热量SHS,t、风机发电量Pwind,t、光伏发电量PPV,t、电负荷PLoad,t、气负荷GLoad,t、热负荷HLoad,t以及时刻t。
st=(SES,t,SGS,t,SHS,t,PWind,t,PLoad,t,GLoad,t,
HLoad,t,t)
(32)
(2)动作空间
动作空间主要包括综合能源系统中智能体需要控制的状态变量。智能体的动作空间主要包括燃气轮机出力PMT,t、电转气设备消耗电功率PP2G,t、储能电池输出功率PES,t、储气罐输出气功率GGS,t、储热罐输出热功率HHS,t、电热锅炉消耗电功率PEB,t以及需求响应功率,如式(33)所示。
at=(PCHP,t,PPtG,t,PES,t,GGS,t,HHS,t,PEB,t,PTra,t,
PInt,t,Pcon,t)
(33)
(3)奖励函数
奖励函数为指导智能体在选择当前动作时获得累计的最大回报。因此本文的奖励函数包括综合能源系统购买能源成本、IDR调度成本。为加快RL算法收敛获得更优的控制效果,在奖励函数中加入智能体动作越限惩罚成本[16]。惩罚函数在智能体动作超过约束时产生惩罚成本,从而通过训练将智能体动作值约束在指定范围内。
智能体动作越限惩罚成本如式(34)所示。
(34)
式中:ζt为智能体在t时刻的动作惩罚成本;εur,i和εdr,i分别为智能体动作爬坡上限和下限惩罚系数;ai,ur,max、ai,dr,min分别为动作变化率的上、下变化限值;εua,i和εda,i分别为智能体动作爬坡上限和下限惩罚系数;ai,ua,max和ai,da,min为动作变化率的上、下变化限值。强化学习智能体奖励目标函数如式(35)所示。
Rt=-(CP+CG++CIDR+ζt)+r0
(35)
式中:r0为人工设定常数,保证智能体在学习过程中累积回报由负转正,提升模型训练的收敛速度和稳定性。
2.2 基于A3C算法的问题求解
相比传统Actor-critic算法,A3C算法引入异步学习机制[19,20]。各agent在运行前通过pull函数从Global Network获取网络参数,每个线程的agent单独与环境交互并更新参数,Global Network不需进行训练,只存储Actor-Critic结构参数。基于Actor-Critic架构的A3C算法主要包含策略函数(Actor)π(at|st;θ)和状态价值函数(Critic)V(st;ω)。利用神经网络拟合综合能源系统优化调度中的源荷不确定性,获得累计奖励最优策略。
通过A3C算法求解优化策略,在每个时刻t,actor根据策略函数采取动作at使环境状态从st转换为st+1,并获得奖励rt(at,st)。优化序列τ,表示为s1,a1,r1,s2,a2,r2,…st,at,rt,…,sT,aT,rT,序列τ所获得奖励为每个阶段所得奖励总和,由式(36)表示。
(36)
式中:γ为折扣系数,0≤γ≤1。
在策略为π的情况下,Actor所能获得期望奖励由式(37)表示。
(37)
由式(37)可知,通过策略梯度优化方法更新策略π,指导Actor采取动作,从而最大化获取期望奖励。因此通过求解网络参数θ梯度更新策略π。梯度求解过程如式(38)所示。
(38)
Critic网络用价值函数评估策略价值,用V(st;ω)表示,其中ω为Critic网络参数,由式(39)表示。
Vπ(st;ω)=E[R(τ)|st;ω]
(39)
动作价值函数Qπ(at,st;ω)通过估算每个状态-动作寻找最佳策略,如式(40)所示。
Qπ(at,st;ω)=E[R(τ)|at,st;ω]
(40)
优势函数(Advantage function)Aπ(at,st;ω)表示actor采取动作at时,与平均预期相比当前状态st的优劣程度。优势函数如式(41)所示。
Aπ(at,st;ω)=Qπ(at,st;ω)-Vπ(st;ω)
(41)
为加快学习过程,A3C算法采用了N步方法,其优势函数由式(42)表示。
(42)
式中:rt为st状态下采取行动时的即时奖励。
因此,critic网络参数ω训练过程如式(43)、(44)所示。
(43)
ωt+1=ωt+nω▽ωL(ω)
(44)
式中:nω为批评家网络学习率。
为保证智能体在决策过程中的广泛性,A3C算法加入策略交叉熵(policy cross entropy,PCE)H(π(at|st;θ))。策略函数的梯度更新如式(45)、(46)所示。
(45)
θt+1=θt+nθ▽θRθ
(46)
式中:β为正项权重因子;nθ为actor网络学习率。
图2为A3C算法的训练过程。训练开始时随机初始化Global Network参数,基于pull函数将Global Network的参数θ、ω同步到各线程中actor和critic network的参数θ′、ω′。然后初始化全局计步器T和本地线程计步器t,并在每个episode中优化系统设备的各时段出力,直到循环结束。
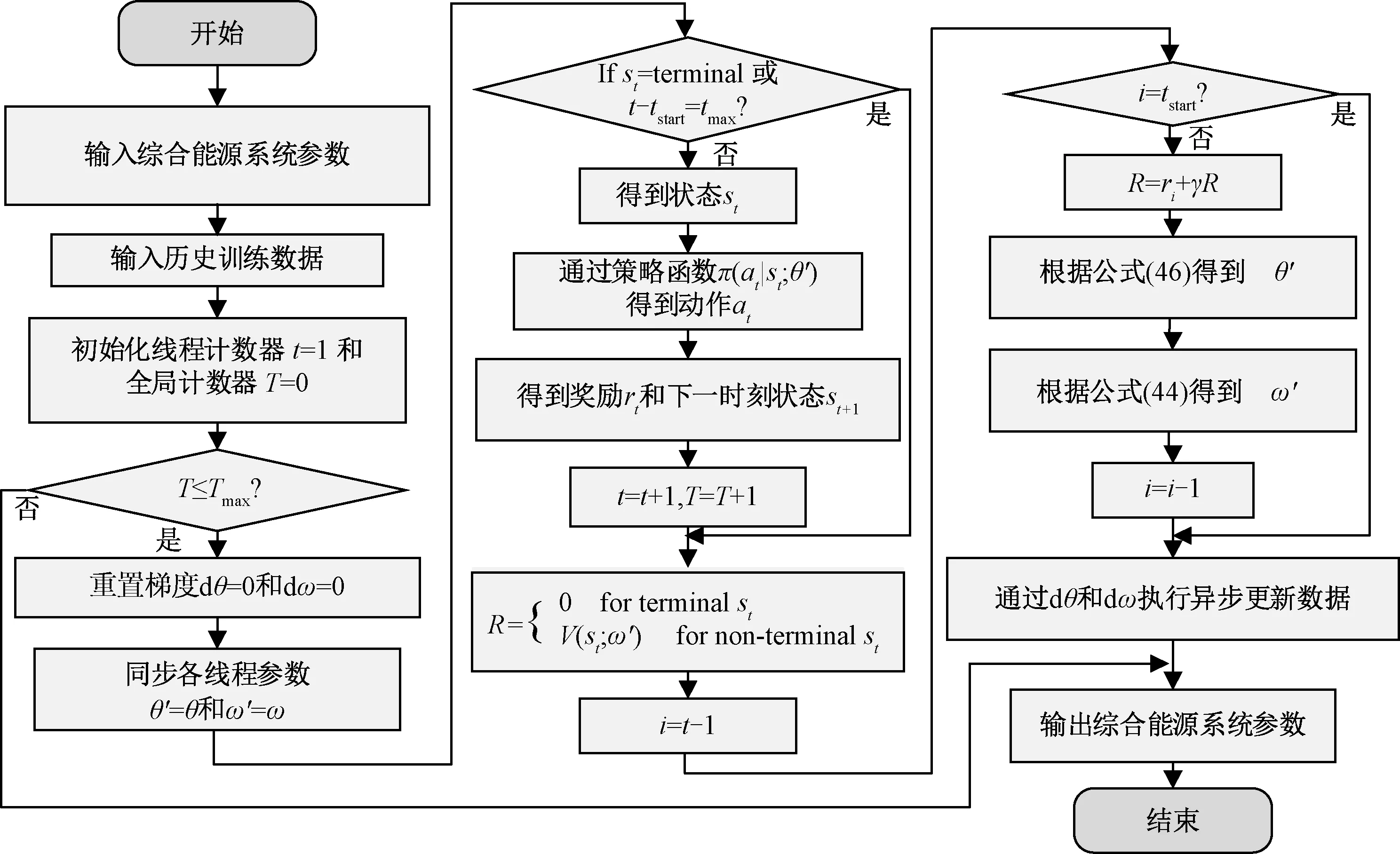
图2 A3C算法的训练过程Fig. 2 Training process of A3C algorithm
3 仿真及结果分析
本文利用Open AI的Gym工具包搭建仿真环境。计算机硬件配置为英特尔core i7-8700@3.20 GHz,6核12线程,内存32 GB,所研究综合能源系统仿真结构如图1所示,各设备参数如表1所示,分时电价参数见文献[15]。A3C算法中Actor网络输入为当前时刻的状态集合 ,输出为动作集合 ,隐层数为3,神经元个数分别200、200、100。Critic网络输入为状态集合 和动作集合 ,输出为动作价值 ,隐层数为3,神经元个数分别200,100,100,均采用ReLU激活函数。

表1 综合能源系统仿真参数Tab.1 Simulation parameters of integrated energy system
3.1 A3C训练过程
为验证本文所提方法有效性,以国网辽宁省电力有限公司实际运行数据(2021年1月1日至2021年3月31日)为例进行训练。将1月1日至2月28日数据作为训练集,3月1日至3月31日作为测试集。负荷数据训练结果如图3所示。
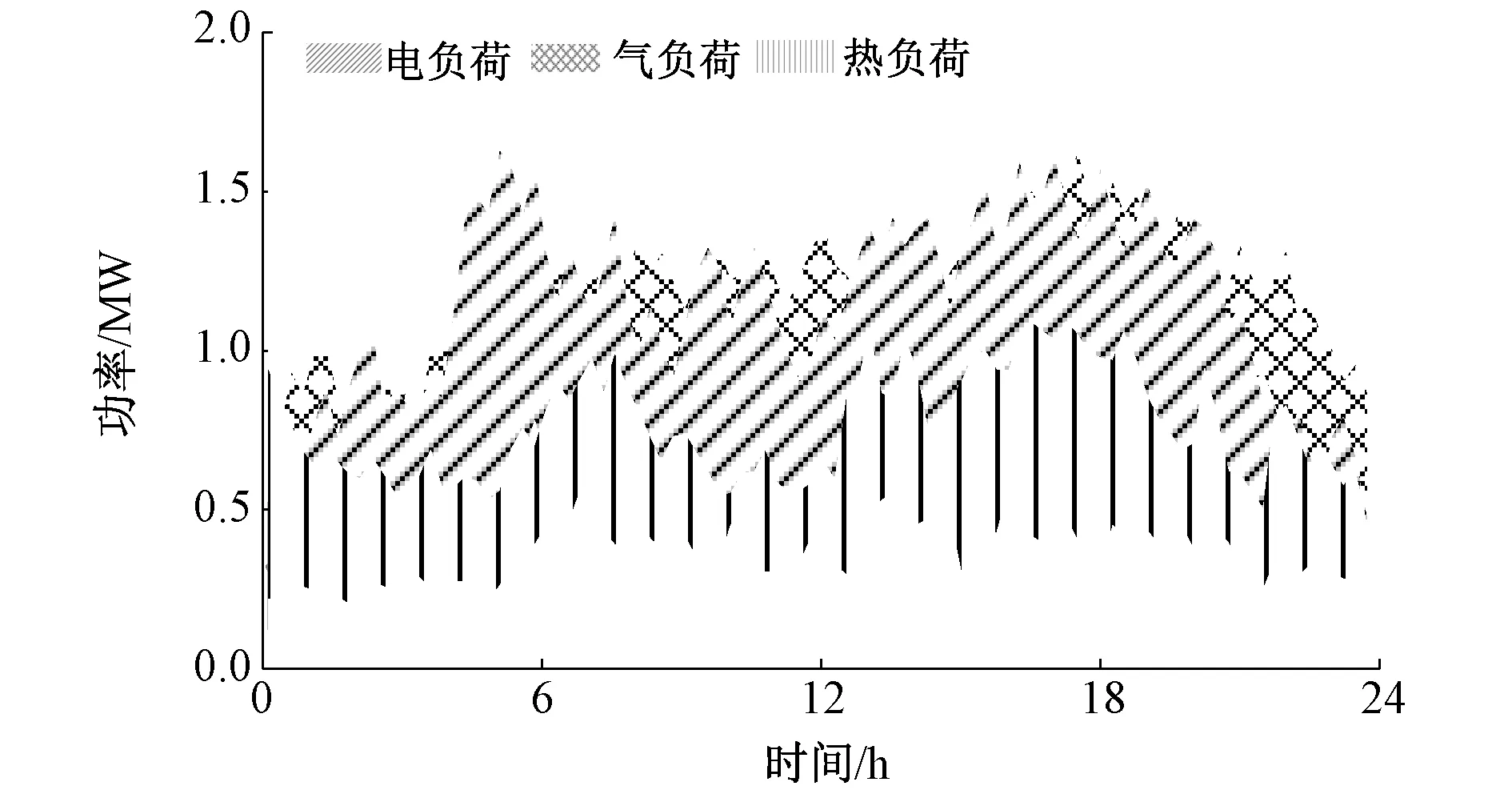
图3 负荷训练数据Fig. 3 Load training data
A3C算法收敛特性如图4所示。智能体初始阶段奖励较低,综合能源系统优化策略处于学习过程,通过智能体的不断试错,根据回报学习更优的控制方法。由图4可知,加入惩罚奖励能够帮助智能体快速学习更优的控制策略,加速算法收敛。算法达到3 600 episode时基本收敛,相比于加入惩罚奖励前收敛速度提高了21%。
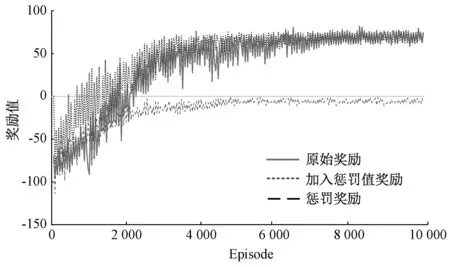
图4 A3C优化算法的训练曲线Fig. 4 Training curve of A3C optimization algorithm
3.2 综合能源系统优化控制效果
为进一步分析算法训练完后的控制效果,本文选取测试集中3月8日的数据进行分析。图5为不同方法下的综合能源系统各时段运行成本。考虑综合需求响应后,在07:00~09:00和17:00~20:00电价高峰时段的总成本明显减少,同时将部分用电需求转移到其他时段。
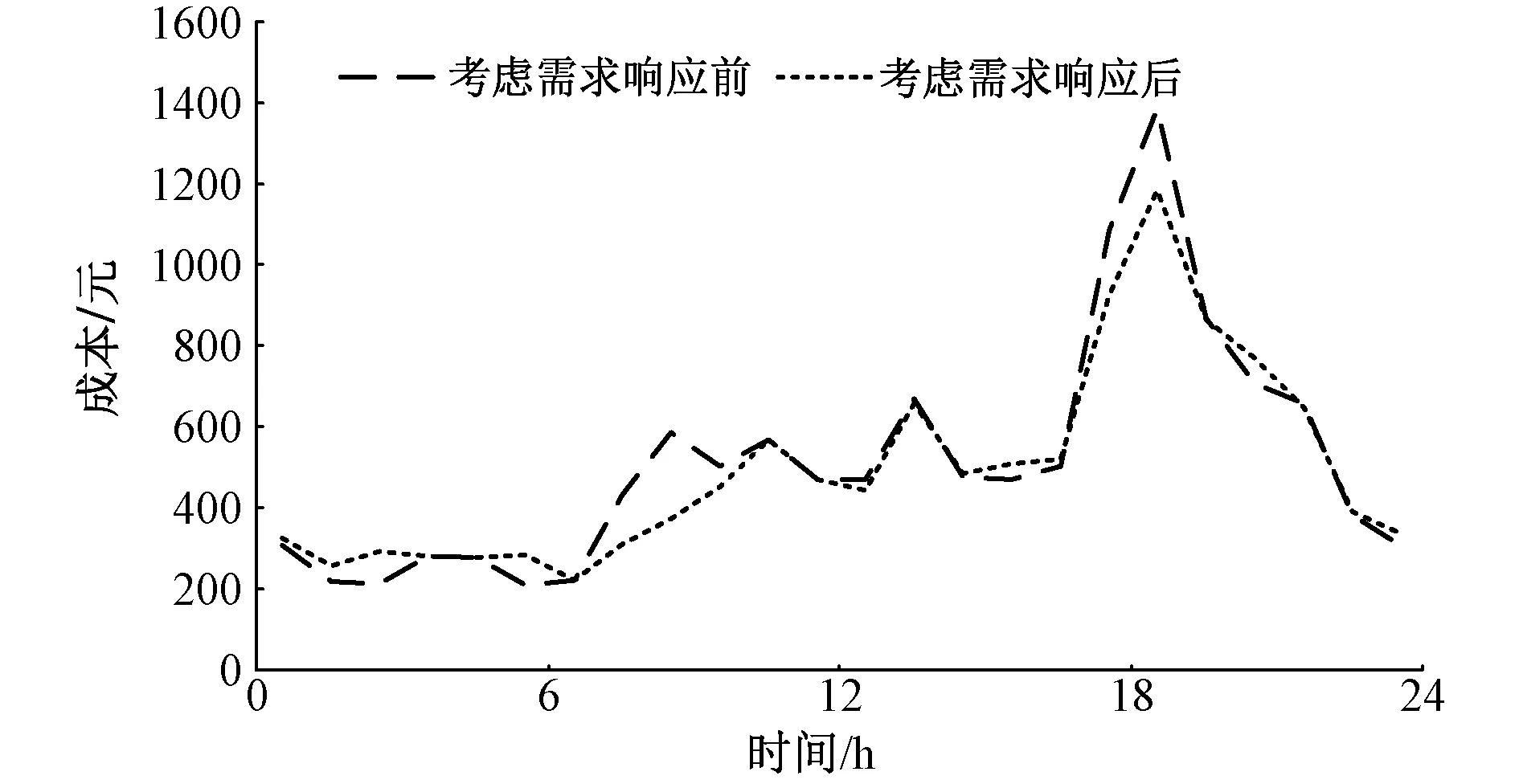
图5 综合能源系统各时段运行成本Fig. 5 Operating cost of integrated energy system
考虑综合需求响应前后系统的日运行成本如表2所示。可以看出,考虑综合需求响应后总成本减少了约5.6%,同时系统的够碳成本降低了8.6%。
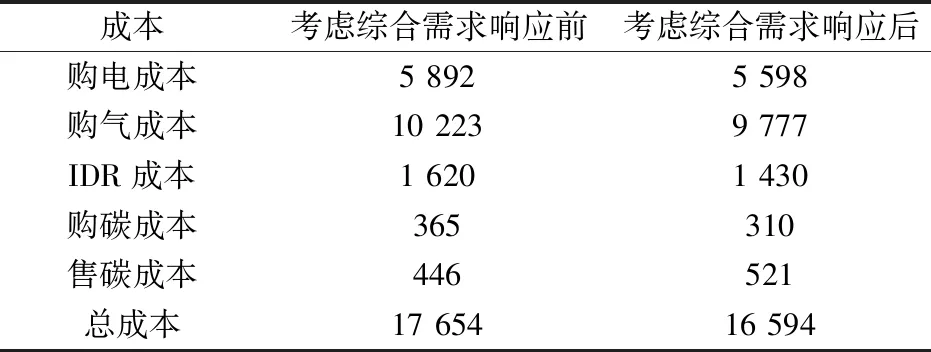
表2 综合能源系统日运行成本Tab.2 Daily operating cost of integrated energy system (元)
图6为采用本文所提基于A3C综合能源系统优化调度方法的各设备出力情况。如图5所示,23:00至05:00为电网谷电价时段,该时段风电出力较高,燃气轮机不运行。电网侧在满足电负荷的同时对蓄电池进行充电。在气网侧,通过P2G设备产生单位天然气比直接购气成本低,此时主要通过P2G设备支撑气负荷,当P2G供能不足时通过购气支撑。热网侧,由于燃气轮机停止工作,由电加热炉供给热负荷,同时储热罐储热。
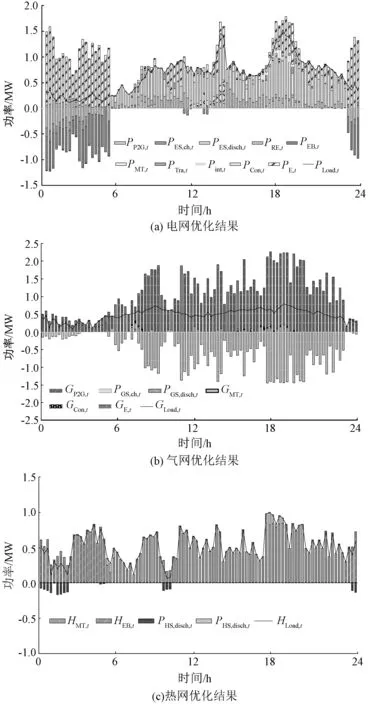
图6 综合能源系统优化调度结果Fig. 6 Scheduling results of integrated energy system optimization
在电网平电价时段(05:00~07:00、09:00~13:00、14:00~17:00和20:00~23:00),燃气轮机开始运行,并与风、光发电系统、以及外部电网购电满足电负荷需求,蓄电池根据当前环境采取充放电操作。例如14:00~17:00时段,该时段风光出力较高,蓄电池容量较低,采取充电操作。气网侧主要通过直接购气与燃气轮机满足气负荷需求。热网侧,燃气轮机采取以热定电模式,主要由燃气轮机和储热罐满足热负荷需求。
在电网峰电价时段(07:00~09:00、13:00~14:00和17:00~20:00),燃气轮机采取以电定热模式,此时电负荷主要由风光出力、燃气轮机和蓄电池提供,供电不足时向电网购电。由于本文考虑综合需求响应,由图6(a)可以看出,在17:00~20:00时段,通过采取转换、转移和中断的方式降低负荷需求,进一步减少峰时段购电成本。气网侧主要通过购气满足气负荷需求,储气罐主要作用为平稳气负荷波动。热网侧热负荷主要由燃气轮机提供,多余热量通过储热罐存储。
3.3 不同算法收敛速度及学习效果对比
为验证本文所提基于A3C调度策略的有效性,选用DDPG与DQN算法进行对比分析。DDPG算法中Actor与Critic网络隐层数均为2,神经元个数均为100,激活函数为ReLU。DDPG算法中,由于DQN不能对连续动作做出决策需进行离散化处理。将每个动作等分为5个固定值。DQN有两个隐层,每层神经元个数为200,隐层激活函数均为ReLU。
三种深度强化学习方法在学习过程中的奖励曲线如图7所示。由于DQN不能实现智能体动作的连续控制,其收敛时的奖励值低于DDPG和A3C算法。A3C算法中加入了策略交叉熵,能够较好描述概率分布的不确定性,具有更好的探索多样性,因此获得更高的奖励值。
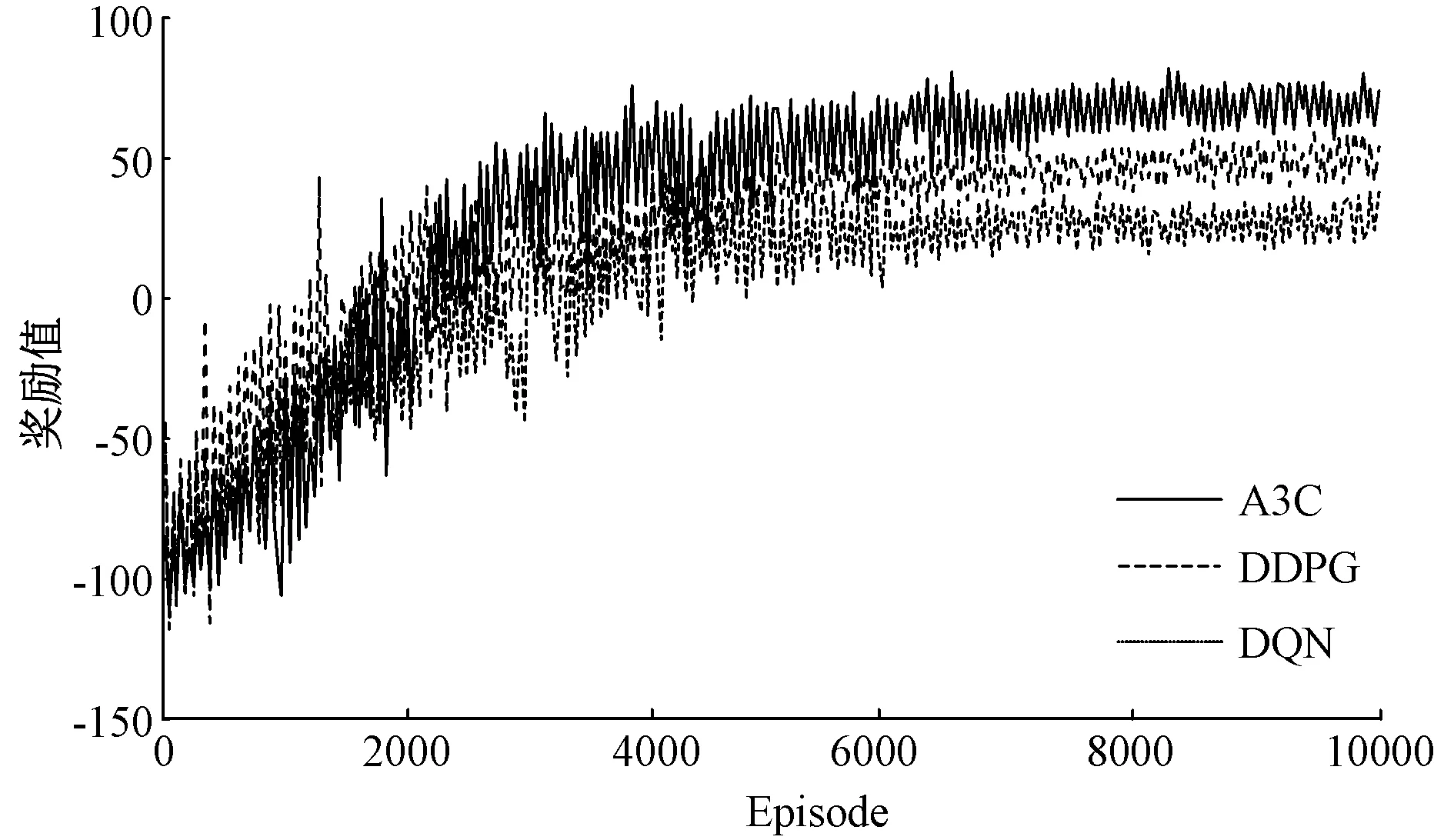
图7 不同算法的奖励曲线Fig. 7 Award curve of different algorithms
为进一步验证不同深度强化学习方法在解决综合能源系统经济调度时的稳定性以及泛化能力,从测试集中随机选取20日的数据进行测试。表3为不同算法的日运行成本,从表中可以看出,A3C算法在多天测试中始终保持较好的控制效果,相比于DQN和DDPG方法,日平均运行成本分别降低了8.7%和5.2%。
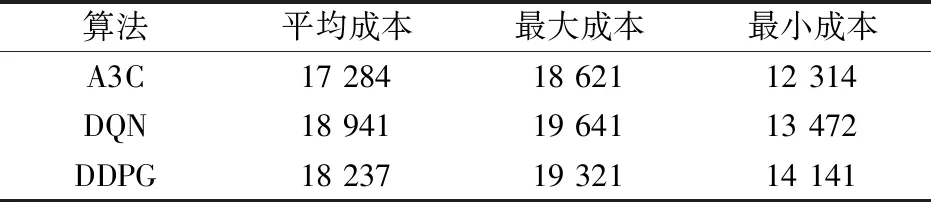
表3 不同算法的日运行成本Tab.3 Daily operating costs of different algorithms (元)
4 结 论
本文提出一种基于A3C综合能源系统优化调度策略。该策略不需要建立复杂的综合能源系统优化物理模型,基于马尔科夫决策过程实现综合能源系统优化调度。该方法可有效减少系统求解时间,更快速响应负荷波动,能满足系统实际运行不断调整的需求。同时考虑综合需求响应,有效减少了综合能源系统的运行成本,降低了综合能源系统的碳排放量。所提方法使各设备出力变化更加平稳,减小了由源、荷侧预测误差引起的系统功率波动,提高了系统运行的可靠性。仿真结果表明,相比于DQN和DDPG方法,日平均运行成本分别降低了8.7%和5.2%。
猜你喜欢
环球人物(2022年4期)2022-02-22 22:05:06
小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
爆笑show(2015年4期)2015-06-24 01:55:12
小学阅读指南·高年级版(2014年2期)2014-05-27 05:29:32
燃气轮机技术(2014年4期)2014-04-16 03:54:07
燃气轮机技术(2014年4期)2014-04-16 03:54:04
燃气轮机技术(2014年4期)2014-04-16 03:54:02
