
基于血清标志物的机器学习模型对肝癌诊断的价值评估*
2023-06-04 11:30:12韩冰遆亚楠王蓉仇丽霞张缭云山西医科大学公共卫生学院卫生统计教研室太原03000山西医科大学第一医院感染病科太原03000
临床检验杂志 2023年3期
韩冰,遆亚楠,王蓉,仇丽霞,张缭云(.山西医科大学公共卫生学院卫生统计教研室,太原 03000;.山西医科大学第一医院感染病科,太原 03000)
肝癌是当前世界上最常见的恶性肿瘤之一,我国每年肝癌新发病例数约占全世界的50%,对我国公共卫生安全构成了严重威胁[1]。原发性肝癌(primary liver cancer,PLC)起病隐匿,早发现肝癌是降低患者死亡率的关键,因此提高肝癌鉴别诊断能力对无症状患者的早期诊断具有重要意义。目前我国诊疗规范推荐对肝癌高危人群至少6个月借助超声检查和血清甲胎蛋白(alpha fetoprotein, AFP)进行筛查[2]。近年来日本肝病学会和中华肝病学分会均推荐使用“肝癌三联检”,即采用AFP、异常凝血酶原(des-gamma-carboxy prothrombin,DCP)、甲胎蛋白异质体(lens culinaris agglutinin-reactive fraction of AFP,AFP-L3)联合影像学检查对肝癌高风险人群进行监测[3-4]。
大数据时代,随着数据挖掘、云计算和人工智能的快速发展,机器学习(machine learning,ML)算法能够分析处理患者病史信息和临床指标来构建预测模型,成为疾病预测、诊断治疗和预后工作的便捷工具[5]。既往研究表明,ML模型在PLC辅助诊断过程中可显著提高(约提升了15%~25%)诊断的准确性[6]。笔者拟从AFP、AFP-L3和DCP出发,评估各项标志物结合ML模型对肝癌的诊断准确性,以期选择合适的模型,从而提高对HCC诊断价值。
1 材料与方法
1.1研究对象 采用回顾性研究方法,收集2021年9月至2022年6月在山西医科大学第一医院感染病科住院患者273例,其中PLC组为经临床确诊为肝癌的患者83例,男67例,女16例,年龄(57.6±11.5)岁,其中乙型肝炎相关肝癌76例,丙型肝炎相关肝癌2例,酒精性肝病相关肝癌2例,原发性胆汁性肝硬化相关肝癌1例,病因不明者2例。良性肝病(benign liver disease,BLD)组为同期住院且排除肝癌的肝病及肝硬化患者190例,男127例,女63例,年龄(51.6±13.3)岁,其中乙型肝炎肝硬化122例,酒精性肝炎及肝硬化19例,丙型肝炎及肝硬化9例,原发性胆汁性肝硬化8例,不明原因肝病患者32例。纳入标准: PLC患者均符合《原发性肝癌诊疗规范(2019年版)》,即具备下列任何一条:(1)病灶>2 cm或AFP≥400 ng/mL,并在动态增强CT/MRI扫描、钆塞酸二钠增强MRI或超声造影4种影像学检查之一表现出典型的肝癌影像学特征。(2)病灶≤2 cm并在以上两种影像学检查中表现出肝癌特征。(3)不能确诊但仍高度怀疑肝癌的患者进行肝脏穿刺和病理学检查。BLD组为临床推荐进行定期肝癌监测的慢性肝病及肝硬化患者。所有入选患者既往未曾接受过肝癌系统治疗。排除标准:(1)同时合并其他恶性肿瘤疾病的患者;(2)妊娠期或哺乳期女性;(3)使用维生素K及维生素K拮抗剂类药物的患者。选择同期体检健康者25例作为健康人对照组,男18例,女7例,年龄(49.1±15.9)岁。
1.2方法
1.2.1标本采集及肝癌标志物检测 采集各研究对象治疗前(体检健康者于体检时检测)空腹静脉血5 mL,3 000 r/min离心15 min,分离血清,采用磁微粒化学发光检测法,按照MQ60 plus全自动化学发光免疫分析仪及配套的AFP、AFP-L3、DCP检测试剂盒(北京热景生物技术公司)说明书操作进行检测。阳性判断标准:AFP≥7 ng/mL、DCP≥40 mAU/mL、AFP-L3%≥10%,联合3种标志物进行肝癌检测时,任何一项检测结果显示阳性即判断为并联检测阳性,3项指标所有检测显示阳性为串联检测阳性。
1.2.2临床资料收集 根据医院电子病历系统收集入选患者的病史资料和血清学检查资料,病史资料包括:性别、年龄、高血压病史、糖尿病史、吸烟史、饮酒史、乙肝感染史、影像学表现;血清学检查资料包括:三酰甘油、总蛋白、球蛋白、总胆红素、直接胆红素、碱性磷酸酶、天门冬氨酸氨基转移酶/丙氨酸氨基转移酶、r-谷氨酰转移酶(r-GT)、凝血酶原时间、红细胞、白细胞、血小板、中性粒细胞。
1.2.3机器学习模型的建立 以PLC作为肝癌组,BLD组和体检健康者作为非肝癌组,单因素分析肝癌组与非肝癌组患者之间的检查资料,将P<0.05的变量进行多因素分析,以筛选出的变量构建模型。使用SPSS 26.0软件构建3种机器学习模型,采用向前LR法构建Logistic回归(Logistic regression,LR)模型,入选变量检验标准α=0.05,剔除变量标准为α=0.10。使用多层感知器(multi-layer perceptron,MLP)构建人工神经网络(artificial neural network,ANN)模型[7],使用决策树卡方自动交互检测算法(CHAID)构建决策树(decision tree,DT)模型[8]。为避免模型过拟合,在构建DT和ANN时使用交叉验证,以预测概率表示3种模型输出结果,其范围皆在0~1之间。

2 结果
2.13组人群中血清AFP、AFP-L3%、DCP水平 AFP、AFP-L3%、DCP水平在PLC组、BLD组及健康人对照组间的差异均有统计学意义(P<0.01)。进一步进行组间两两比较结果发现,PLC组血清AFP、AFP-L3%、DCP水平均显著高于BLD组和健康人对照组(P<0.01),但BLD组与健康人对照组AFP、AFP-L3%、DCP之间的差异均无统计学意义。见表1。

表1 AFP、AFP-L3%及DCP在3组人群血清中的表达水平[M(P25,P75)]
2.2AFP、AFP-L3%、DCP单独及联合检测对肝癌的诊断效能 在以试剂盒设定的阈值对肝癌患者进行检测时,DCP的敏感性最高,AFP-L3%的特异性最高,但敏感性最低。联合检测时,并联检测的敏感性高于串联检测,而串联检测的特异性高于并联检测(表2)。肿瘤标志物中以DCP对肝癌的预测价值(AUCROC)最优,其余标志物单独及联合检测对肝癌的AUCROC排序依次为:串联检测>并联检测>AFP-L3%>AFP。

表2 AFP、AFP-L3%、DCP及联合检测对肝癌的诊断效能
2.3模型变量筛选 对纳入研究的患者信息进行单因素分析,发现肝癌组与非肝癌组在性别、年龄、病因(乙肝/非乙肝)、吸烟史、影像结节表现、AFP、AFP-L3%、DCP、串联、并联检测和三酰甘油、天门冬氨酸氨基转移酶/丙氨酸氨基转移酶、球蛋白、碱性磷酸酶、γ-GT、中性粒细胞、血小板等指标间比较,差异有统计学意义(P<0.05)。多因素Logistic回归分析筛选出同时纳入3种ML模型的变量分别为年龄、影像结节表现、病因(乙肝/非乙肝)、DCP、肝癌三联检(串联)和γ-GT(表3~5)。

表3 2组患者病史信息对比[n(%)]
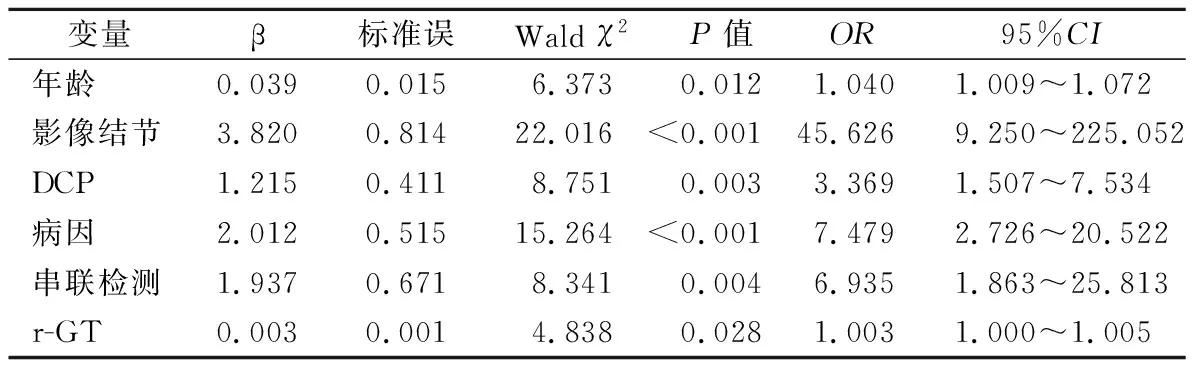
表4 机器学习模型入选变量分析

表5 2组患者临床检查指标对比[n(%)]
2.4各预测模型的诊断效能 按照约登指数选取ML模型的阳性截断值,ANN的敏感性和特异性分别为86.7%和80.4%,LR的敏感性和特异性分别为85.5%和82.8%,DT的敏感性和特异性分别为63.9%和86.5%,3种ML模型均具有较高的预测价值,其AUCROC排序依次为ANN(0.908)、LR(0.903)、DT(0.827)。其中,经Delong检验,ANN与DT之间(Z=3.916,P<0.001)、DT与LR之间(Z=4.625,P<0.001)差异有统计学意义,而ANN与LR之间(Z=0.826,P=0.409)差异无统计学意义。3种肝癌标志物的ROC曲线分析结果见图1~3。

图2 3种肝癌标志物联合检测的ROC曲线
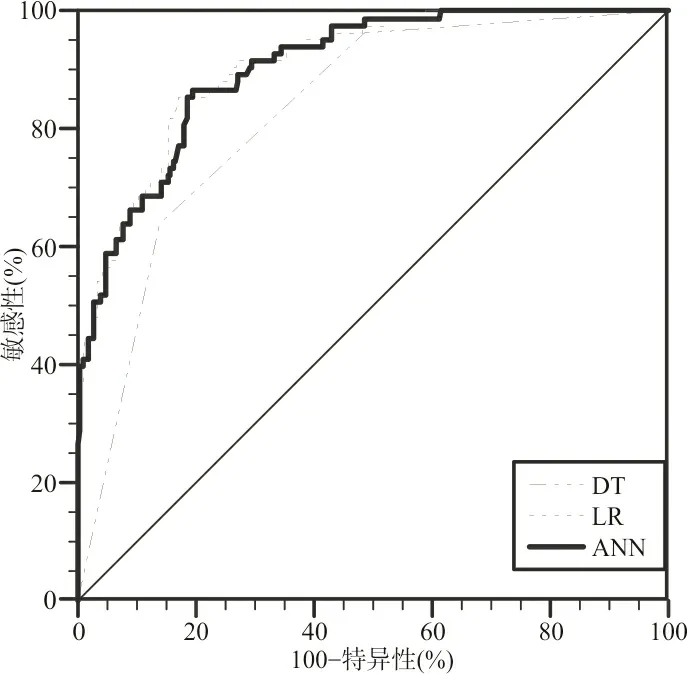
图3 3种ML模型的ROC曲线
3 讨论
由于HCC起病隐匿、病情进展速度快且恶性程度较高,因此肝癌早期发现对于提高肝癌根治率和患者长期生存率十分重要,在肝癌检测中应首先考虑提升敏感性[9]。血清学肿瘤标志物检验具有易获取、操作简便和客观性强的优点,能较影像学检查提前3~28个月预警肝癌发生[10]。本次研究中PLC组患者的AFP、AFP-L3%和DCP水平均显著高于BLD组和健康人群,证实3种肿瘤标志物在肝癌诊断中具有重要作用。通过进一步研究结果显示,DCP的敏感性高于AFP和AFP-L3%,提示DCP有较强地发现肝癌患者的能力。联合使用肿瘤标志物是肝癌筛查诊断的重要方向,但夏一帆等[11]提出联合肿瘤标志物的诊断精度相较于单一标志物提高不大,本研究在联合使用3种肝癌标志物时其并、串联检测的AUCROC均低于DCP,提示联合多个标志物可能会导致诊断价值下降。
提高诊断技术准确性的途径既包括探索更高价值的新型标志物,也包括利用既有技术设计诊断方法[12-13]。Johnson等[14]利用LR算法结合AFP、AFP-L3%、DCP开发了预测肝癌的GALAD模型,该模型在肝癌诊断中表现出良好效能。王运九等[15]基于AFP和CA199、CEA构建了用于肝癌诊断的ANN模型和LR模型,得出ANN模型较LR模型在肝癌诊断中更有效力的结论。周友乾等[16]的研究认为,DT模型能够提高AFP及超声检查在肝癌早期筛查的应用价值。LR、ANN及DT模型常用于数据的分类和回归,在癌症诊疗领域中应用广泛[17-18]。LR是经典概率统计分类模型,能够量化自变量对因变量的影响程度并描述二者的线性关系,已广泛应用于二分类因变量建模[19]。ANN以模拟生物神经元结构来实现人工智能的数学模型,具有较好的稳健性和容错性,在解决非线性问题时较为常用[20]。DT本质是1个递归划分过程,模型执行过程中无须过多计算且具有良好的可解释性,更符合临床的逻辑思维[21]。本研究将肝癌诊断作为1个二分类问题,基于AFP、AFP-L3%、DCP构建的并联、串联检测被视为简单的分类模型,但分类程序较为粗糙,而LR、DT及ANN这3种ML模型对肝癌诊断的AUCROC均>0.8,表明ML模型不仅具有较高的诊断价值,同时优于AFP、AFP-L3%、DCP单独及联合检测,与既往研究结论一致。ANN和LR的AUCROC分别为0.908和0.903,而DT的AUCROC仅为0.827,Delong检验结果显示,ANN和LR在肝癌诊断中的AUCROC显著高于DT,但ANN和LR的AUCROC之间的差异无统计学意义。尽管其他研究中ANN和DT的诊断价值优于LR模型[19],但本研究中ANN模型和LR模型诊断价值相近且优于DT模型,原因可能是DT更适合处理非数值型变量而不擅长处理连续性数据,降低了统计分析效能。
综上所述,单项肝癌标志物无法满足临床诊断需求,并联或串联检查无法发挥多个标志物联合使用的优势,利用机器学习构建诊断模型可以进一步提高血清标志物的诊断能力。另外本研究中LR模型的诊断价值优于DT模型,说明经典模型仍有优越之处,应根据临床实际情况选择诊断模型,而不能盲目信任决策树这类较高级的ML模型。本研究尚存在一定局限性,包括单中心小样本回顾性研究和参与比较的ML模型较少,未来还需要进行前瞻性研究以分析更多ML模型在肝癌高危人群中的诊断效能,选择最优诊断模型以提高原发性肝癌临床诊断效率。
猜你喜欢
故事作文·低年级(2023年11期)2023-12-05 06:39:56
故事作文·低年级(2023年12期)2023-03-24 14:16:52
天津医科大学学报(2019年3期)2019-08-13 06:53:08
中国环境监察(2016年7期)2016-10-23 05:36:30
中国现当代社会文化访谈录(2016年0期)2016-09-26 08:46:23
中华老年多器官疾病杂志(2016年9期)2016-04-28 08:52:44
肿瘤预防与治疗(2015年1期)2015-09-26 07:26:20
医学研究杂志(2015年7期)2015-06-22 11:01:10
中国当代医药(2015年16期)2015-03-01 02:03:11
癌变·畸变·突变(2015年4期)2015-02-27 06:15:25
