
一种基于BEGAN 改进的残缺人脸图像修复算法*
2023-06-04 06:24雷新意
计算机与数字工程 2023年2期
雷新意 吴 陈
(江苏科技大学计算机学院 镇江 212100)
1 引言
残缺人脸图像修复,是对给定的一张存在局部区域残缺的人脸图片进行修复填充,目前已有一些如Photoshop 的图像处理软件能够对残缺人脸图像进行修复,然而,修复效果较大程度的依赖于个人对软件使用的熟练程度,此外,由于人脸图像的拓扑结构相对特殊,通常的图像修复技术应用于残缺人脸图像修复难以取得令人满意的效果,因此,残缺人脸图像修复是一项极高挑战性的项目,相关研究人员已对此提出多种修复方法,可分为传统方法和深度学习方法。
传统方法又可分为变分法、实例法。变分法利用了扩散思想,将局部残缺区域周围的已知区域扩散至残缺区域[1~2],之所以称之为变分法是因为可以通过变分原理等价推导得出。Bertalmio 等学者首先建立了BSCB 模型[3],该模型在选择要修复的区域后会自动进行填充,对拓扑结构没有任何限制,但该模型存在运算速度慢的问题,学者Chan 等人受到BSCB 模型的启发,提出了全变分模型和曲率驱动扩散模型[4~5],收敛速度和伪噪声去除效果有所提升,此后又有一些高阶图像修复模型提出并取得了更好的修复效果,但对于面积较大残缺图像修复效果不佳[6-7]。实例法通过获取纹理信息实现对残缺人脸图像的修复,有Bornard 提出的基于纹理合成的修复算法[8],Criminisi 提出的基于样本块的修复算法[9],Martmez-Noriega 和Roumy 提出的构建先验修复算法[10],实例法相对于变分法更加关注图像的纹理结构,且修复效果受到相似度匹配、图像块选取、先验知识等因素影响。如今,深度学习技术越来越多的被应用在图像修复领域,Google DeepMind 团队提出的PixelRNNs 网络结构可看作是深度学习在图像修复领域应用的先例[11],Context Encoder 是首个利用深度生成网络处理残缺图像的模型,该模型利用自动编码器的预测能力,根据残缺图像中已知图像信息来预测残缺图像的内容[12]。然而,目前基于深度学习的修复算法还处于初始阶段的监督学习或半监督学习,受到较多因素的限制,因此,Goodfellow等学者提出了利用生成对抗网络GAN 进行图像的修复[13],这为无监督学习提供了新的思路,此后多种基于GAN 的图像修复方法提出,效果相对于传统算法得到了很大的优化,但仍然存在难以平衡判别器和生成器收敛速度、梯度易消失问题,且修复图像虽真实但和原图像身份特征差异较大的问题,针对此状况,本文在生成对抗网络基础上提出了一种基于BEGAN边界均衡生成对抗网络改进的残缺人脸图像修复算法,主要内容包括:
1)生成器:采用类似U-net 编解码器网络结构,在U-net 结构中简单跳跃连接基础上引入嵌套、密集的跳跃连接以增强不同尺度特征图的语义结合;
2)判别器:采用全局和局部双重判别模型,优化区域不协调以及语义不一致问题;
3)损失函数:结合BEGAN 对抗损失、重构损失、身份特征一致性损失作为联合损失函数以获得和原始图像身份特征更加一致的修复图像。
2 生成对抗网络(GAN)
GAN 由生成器G 和判别器D 组成,生成器G 将随机噪声z 生成近似服从真实数据分布Pdata uik的样本G(z),而判别器D用于判断输入样本是真实样本x 还是随机噪声的生成样本G(z)。GAN 的模型结构如图1 所示。
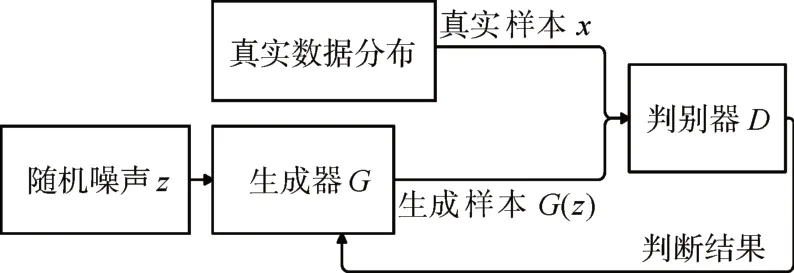
图1 生成对抗网络模型结构图
在模型训练过程中,生成器G 的作用是尽可能生成近似真实的图片去“欺骗”判别器D。而判别器D 的作用是尽可能将生成器G 生成的图片和真实的图片判别开,如此,生成器G 和判别器D 形成了一个动态的博弈过程。模型训练目标是生成器G 可以生成和真实数据分布相同的样本,使得判别器D 难以判定G(z)究竟是不是真实的,即D(G(z))=0.5。该过程用数学语言描述如下所示:
式中,D(x)表示判断真实图片是否真实的概率,而D(G(z))是判断G 生成的图片是否真实的概率。G让生成的样本越接近真实样本越好,即D(G(z))越接近1越好,这时V(D,G)会变小,而D 尽量使D(x)接近1,D(G(z))接近0,此时V(D,G)会增大。
虽然原始GAN 已经能够获得较好的生成、修复图像效果,但该模型往往难以训练,难以平衡判别器和生成器的收敛速度,极易造成模型崩溃问题,为了能够改善这些问题,学者Berthelot 等提出了BEGAN边界均衡生成对抗网络[14]。
3 边界均衡生成对抗网络(BEGAN)
BEGAN 是一种对GAN 的改进模型,该模型使用了新的评价生成器质量的方法,不需考虑上述模型崩溃和训练不平衡等问题。
GAN 以及其变种均是以生成器生成的数据分布尽可能接近真实数据分布为目标,而BEGAN 并不直接对生成数据分布与真实分布的差距进行估计,而是对各自分布损失的分布差距进行估计,只要分布之间的损失分布相近即可认为分布是相近的。
BEGANs 将一个自编码器作为分类器,通过基于Wasserstein 距离的损失来匹配自编码器的损失分布,自编码器在样本上的损失如下所示:
其中,D 为自编码器函数,η为目标准则,Nx为样本维度,L(v)表示真实图像v 和经过自编码网络D输出的D(v)的相似程度,值越小,表示v 和D(v)越相似,同样也可以得到生成图像的损失L(G(v) ),BEGAN 采用Wasserstein 距离计算D 在真实数据与生成数据损失分布之间的距离,而真实数据与生成数据损失分布近似服从正态分布[14]。
对于两个正态分布之间的Wasserstein 距离为
其中,m1,m2为两个正态分布均值,c1,c2为方差。
根据GAN 的对抗原则,D 的目标是最大化W,而G 则要最小化W,如果满足为常数,则W 与|m1-m2|的单调性相同,因此,令D 不断的最大化m2,最小化m1,而G 不断最小化m2,当m2接近m1时即认为模型训练完成,D 和G 的目标函数可表示为
理想情况下肯定是m1=m2的时候是最好的,即,但此时,趋近于无穷,因此,模型加入了一个取值范围[0,1]的超参数,就相当于一个将均衡条件限制住了,这就是BEGAN名字的由来,最终的损失函数如下所示:
其中,t为训练步数,λk为k的学习率此外,BEGAN中还定义了一个可表示模型训练程度的变量如下:
Mglobal越小表示模型收敛程度越高,相反,收敛程度越低。
4 改进的BEGAN结构
4.1 生成器模型
原始BEGAN 的生成网络是解码器结构,仅适用于一维信号,由于本文算法的输入是二维的残缺图像,因此本文生成器采用了基于U-net 网络的改进结构,包括一个将图像背景提取成潜在特征表示的编码器和一个利用该特征表示生成残缺区域内容的解码器。
原始的U-net 网络通过下采样的方式对特征进行降维,没有从多尺度中获取足够的信息,提取出主要特征的同时存在着部分重要特征丢失的问题,致使深层的网络层相关性低,影响模型的表达能力,可能导致梯度弥散,增加了训练难度。因此,本文在U-net 的基础上提出采用全尺度跳跃连接(skip connection),全尺寸跳跃连接改变了编码器和解码器之间的互连,每个解码器层融合了编码器中的小尺度、同尺度以及解码器的大尺度特征图,这些特征图提取了全尺度下的细粒度和粗粒度语义,网络模型结构如图2所示。
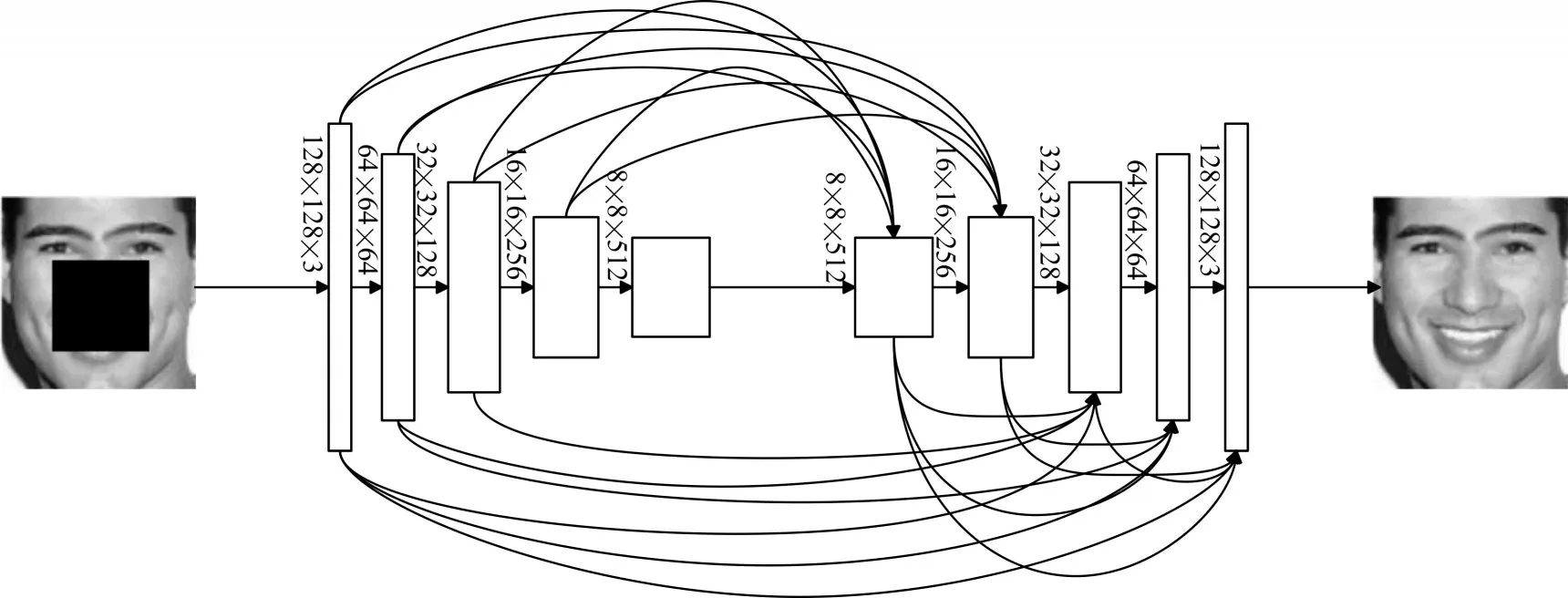
图2 生成器模型
网络的前半部分由多个编码器模块组成,每个编码器模块由一个卷积层、一个批归一化层、一个ReLU 层串联组成,采用步长为2 的卷积层进行特征下采样,这使得网络中特征的下采样方式可以通过训练学习得到最优,特别的是,第一个编码器模块不使用批归一化层。网络的后半部分由多个解码器模块组成,对于每个解码器模块由较小或相同尺度编码器模块进行池化下采样及较大尺度解码器模块进行双线性插值上采样并卷积后统一到当前解码器模块特征图分辨率和通道数后,采用FCN式逐点相加实现多尺度特征融合,并经批归一化层和激活函数LeakyReLU 层形成,特别的是,解码器最后一个模块不使用批归一化层。此外,本文模型在编码器和解码器的中间层使用逐通道全连接替代原始U-net的全连接方式。
本模型相对于U-net 结构,能够提高精度,防止网络层数增加而导致的梯度弥散问题与退化问题。
4.2 判别器模型
原始的BEGAN仅采用一个全局判别网络实现对抗优化,存在修复区域和其他区域不协调以及语义不一致等问题。针对此情况,本文添加了一个局部判别网络,根据BEGAN 的思想,全局、局部判别器均采用自编码器结构。全局判别器用于优化人脸残缺部分的结构信息和特征信息的生成,使修复的人脸图像结构的符合视觉认知;局部判别器用于优化人脸残缺部分的纹理信息生成,使修复的人脸图像和原始图像的皮肤纹理信息更加相像、逼真。判别器模型结构如图3所示。
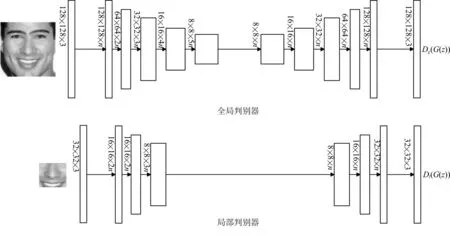
图3 判别器模型
全局判别器和局部判别器模型结构相似,均采用原始BEGAN 的判别器结构,不同的是输入图像的分辨率,全局判别器输入图像分辨率为128×128编码器,局部判别器输入图像分辨率为32×32,此外,解码器层数也相应不同。编码器除了第一个模块采用1个3×3 卷积层,其余均使用了2个3×3 卷积层和一个步长为2 的池化层,解码器除了最后一个模块采用1 个3×3 卷积层,其余均采用2 个3×3卷积层和一个双线性插值上采样层,编解码器中间层使用全连接方式映射。上图中,n 为通道基数,本文全局判别器中n=128,局部判别器中n=32。
4.3 损失函数
本文的损失函数由生成器部分的重构损失、全局及局部判别器损失、身份特征一致性损失组成。
重构损失Lrec采用L1范数,如下所示:
通过重构损失能够让生成图像更加逼近真实图像。
本文在研究不同修复方法的修复结果中发现尽管已有的多种方法都修复生成了比较真实的填充内容,但在身份特征的相似性上却有较大的差距。为了能够让修复结果尽可能修复丢失的身份识别特征,本文在损失函数中加入了人脸特征一致性损失,用来衡量修复的人脸图像和原始图像之间的面部特征之间的差异。该损失通过将修复的残缺人脸图像和原始图像分别输入人脸识别网络ResNet以提取各自的特征,并求两者间的余弦距离得到身份一致性损失Lcons。
重构损失、身份一致性损失结合全局、局部判别器损失函数得到最终的损失函数为
其中,Lg(x)为全局原始图像自编码器损失,Ll(x)为局部原始图像自编码器损失,为全局判别器自编码器损失,为局部判别器自编码器损失,Lg(G(z) )为全局生成数据自编码器损失,Ll(G(z))为局部生成数据自编码器损失,本文根据上述损失函数通过Adam 梯度优化算法更新模型参数,优化模型。
5 实验
本文实验平台是Windows 10 64 位操作系统,Python3.6 基于Tensorflow 框架的编程环境,Intel 3.8 GHz CPU,内存16GB。采用香港中文大学的开放数据CelebA数据集,总计202599张图片,每个图像均有多项属性注释。由于CelebA 数据集中图像分辨率为178×218,本文先将CelebA 数据集预处理为128×128 的图像,预处理后的数据集只包含人脸,使用其中100000 张图像训练,10000 张图像验证,10000 张图像测试,剩余的作为训练样本,总迭代次数为60,批大小为128,本文将残缺区域大小固定为32×32 而位置随机进行训练,通过比较不同的深度学习方法的修复效果以验证残缺图像的恢复效果。
5.1 不同修复方法主观比较
为了验证本文的残缺人脸图像修复方法较其他的深度学习方法具有更好的细节修复效果和身份特征相似性,将本文实验结果和DCGAN[15],PM[16],CA[17]算法修复效果进行对比,残缺区域选择左眼和左侧嘴部,比较结果如图4和图5所示。

图4 左眼残缺图不同修复方法效果对比

图5 嘴部残缺图不同修复方法效果对比
在图4 和图5 中,第1 列为原始人脸图像,第2列为待修复的残缺图,第3 列为DCGAN 算法的修复效果图,第4 列为PM 算法的修复效果图,第5 列为CA 算法的修复效果图,第6 列本文修复算法的效果图。可以看到,DCGAN 算法由于难以平衡生成器和判别器的训练过程,稳定性差,且是简单的利用低分辨率特征反卷积得到高分辨图像,修复结果中的掩膜边界非常明显,不仅色彩上有较大差异,残缺区域的衔接也明显不协调,PM算法属于非训练方法,通过寻找最为相似的图像块实现修复,该算法匹配原始像素能力较强,但得到的修复效果图较为模糊,还原细节能力较差,CA 算法结合生成对抗网络和自注意力模块,恢复图像明显更加清晰,但仔细观察发现除了细节修复效果欠佳,不够真实,而本文修复算法引入了全尺度跳跃连接,生成器提取了全尺度下的细粒度和粗粒度语义,修复效果清晰,细节修复较CA算法有明显提升,几乎找不出缺陷的痕迹,并且损失函数引入身份特征一致性损失,使得修复图与原图身份特征信息几乎一致,修复结果和原图更像是同一个人。
5.2 不同修复方法客观比较
为修复方法的客观比较采用峰值信噪比PSNR和结构相似性标准SSIM 两个指标。PSNR 用来衡量图像之间的像素值差异,图像之间PSNR 值越大,表示越相似。SSIM 用于估计两张图像之间的整体相似性,SSIM 值越接近1,图像结构越相似。详细结果如表1和表2所示。

表1 左眼残缺图不同修复方法的PSNR和SSIM
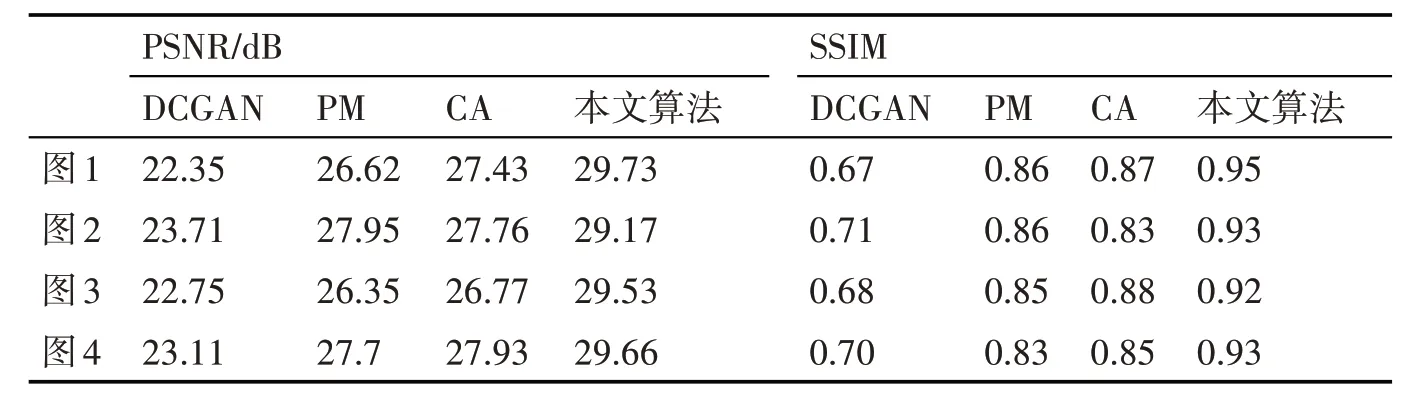
表2 嘴部残缺图不同修复方法的PSNR和SSIM
从表1、表2 可以看出对比GCGAN,PM,CA 算法,本文算法在CelebA 数据集上实验的残缺人脸图像修复结果无论是峰值信噪比还是结构相似度都更优。
6 结语
本文针对残缺人脸图像的修复,提出一种基于BEGAN 改进的人脸图像修复方法。其中,生成器采用类似U-net 编解码器网络结构,在U-net 结构中简单跳跃连接基础上引入嵌套、密集的跳跃连接以增强不同尺度特征图的语义结合,判别网络采用全局判别器和局部判别器的双重判别方式,优化区域不协调以及语义不一致问题,基于BEGAN 对抗损失、重构损失、身份特征一致性损失作为联合损失函数以获得和原始图像更相似的修复图像。对比PM、CA 算法在相同的人脸数据测试集上的修复结果,本文的修复结果的主客观评价效果都更好。
本文输入图像的残缺区域都是规则的方形,然而实际应用中,图像残缺区域形状都是随机的,因此,下一步将针对随机生成的不规则残缺区域来提高模型在实际应用中修复效果。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
动漫星空(2018年9期)2018-10-26
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
发明与创新(2015年33期)2015-02-27
