
融合级联注意力和多任务学习的语音情感识别*
2023-06-04 06:24杨京宝高恩录王庆越夏玉琦
计算机与数字工程 2023年2期
杨京宝 高恩录 刘 扬 陈 庚 王庆越 夏玉琦 赵 振
(1.青岛淄柴博洋柴油机股份有限公司 青岛 266701)(2.青岛科技大学信息科学技术学院 青岛 266061)
1 引言
语音信号是人类生活中认知沟通的重要信息载体,它不仅包含语义信息,还携带着说话者的情感状态。随着计算机处理能力的进一步提高和对智能生活需求的增长,语音情感识别(Speech Emotion Recognition,SER)已成为人们生活中不可或缺的一部分[1],具有广泛的应用场景,包括人工服务[2]、远程教育[3]和医疗援助[4]等。然而,由于语音的多样性和情感表达的复杂性,提高情感识别准确度仍是一个亟待解决的难题。
基于传统机器学习方法的语音情感识别模型,如隐马尔可夫模型[5]、高斯混合模型[6]和决策树[7]等,在以往的研究中被广泛用于情感识别的特征提取。然而,传统的情感识别方法面对规模庞大的训练据集时难以实施,且由于语音中包含多种情感状态,从而导致模型训练计算量大,情感状态分类困难,最终导致整体识别率较低。
近年来,深度神经网络在SER的特征提取方面表现出了突出的性能。与传统的语音情感识别方法相比,深度神经网络能够通过监督学习从大量的训练样本中提取语音情感的高级特征表示,例如Tursunov[8]等采用卷积神经网络(Convolutional Neural Network,CNN)从语谱图中学习的语音情感特征,并在基准测试数据集上取得了优异的语音情感识别效果;卢艳[9]等采用递归神经网络(Long Short-Term Memory Network,LSTM)提取了语音情感特征的随机时间关系和情感特征的不确定性,从而显著提高了SER的准确性;梁宗林[10]等引入卷积递归神经网络(Convolutional Recurrent Neural Network,CRNN)捕获原始音频中上下文情感特征的最优表示,在IEMOCAP 数据集上取得了良好的识别效果。尽管深度神经网络在SER 领域取得了巨大的成功,然而上述模型均使用个性化特征作为输入,对于特定的说话者取得了良好的语音情感识别效果,但是忽略了不同说话人、说话内容和环境中的共同情绪信息。此外,由于性别差异,语音情感特征在变化过程中所体现出的情感信息也不尽相同[11]。上述问题阻碍了SER 技术在说话者独立环境中的实际应用。
因此本文提出了一种融合级联注意力机制(Cascading Attention Mechanisms,CAM)和多任务学习(Multi-task Learning,MTL)语音情感识别方法。首先,提取Log-Mel 特征及其一阶差分和二阶差分特征,并进一步提取时频方向的非个性化情感特征,以学习语音情感的变化过程;然后,通过由通道注意力、空间注意力和自注意力组成的级联注意力网络筛选显著的情感特征,并学习情感特征之间的相互依赖关系,同时关注情感特征对通道和空间的不同贡献。最后,引入了一种多任务学习策略[12~16],将说话人性别识别(Speech Gender Recognition,SGR)与语音情感识别任务相结合,减少了由于性别的差异对情感识别的影响。实验结果表明,本文方法在IEMOCAP 数据集上的加权精度(Weighted Accuracy,WA)和非加权精度(Unweighted Accuracy,UA)分别达到79.39%和76.76%。
2 融合CAM-MTL的网络模型
如图1 所示,本文提出的融合CAM-MTL 的语音情感识别模型主要处理流程如下。首先,提取非个性化特征,以反映情感特征在时频方向上的变化过程。然后,引入级联注意力网络,获得非个性化特征中最显著的情感特征。最后,采用多任务学习策略减少对不同说话者性别的感知差异的影响。

图1 融合级联注意力机制的多任务语音情感识别的模型结构
2.1 非个性化特征提取
为了有效地学习语音情感发生变化的过程,本文在时频方向上提取了非个性化特征,如图1 所示。首先,对给定的语音信号进行零均值和单位方差的归一化操作,并按照25 ms 的帧移和10 ms 的帧长进行分帧操作;然后,利用离散傅里叶变换(Discrete Fourier Transform,DFT)计算每一帧语音信号的功率谱;之后,通过Mel 滤波器组计算获得输出pi,其中i为Mel滤波器组的序号;最后,通过式(1)~(3)获得Log-Mel特征mi、一阶差分特征mdi和二阶差分特征,并按照通道方向组合形成三维特征表示(3D Log-Mels)。
式中,N是用于计算3D Log-Mels 特征的连续帧数,n为时间帧的长度。
进一步,使用时间方向卷积滤波器(Conv1a)从3D Log-Mels 中提取特征Ftime,减少时间跨度对语音情感的影响。同时,通过频率方向的滤波器(Conv1b)提取特征Ffreq,减少频率跨度对语音情感的影响。然后,将Ftime和Ffreq沿通道方向合并,得到三维时频特征Fin,如式(4)所示。最后,将Fin输入CNN 层,提取目标非个性化语音情感特征Fout∈RC*H*W,其中,C、H和W分别表示信道数、频率采样点数和帧数。具体计算过程如下:
式中:Concat是沿着通道方向的川里操作。f表示卷积操作。Wk和bk是的第k个卷积滤波器的可训练参数。
2.2 级联注意力网络
为了能从复杂的语音中区分出有效的目标特征,需要聚焦语音中的关键情感特征,从而增加不同情感特征之间的判别性。因此,本文引入级联注意力网络,采用通道注意力及空间注意力实现语音情感特征的定位,利用CNN-BLSTM 提取语音的句子级情感特征,使用自注意力有效应对不同通道语音情感变化的影响,减少对外部信息的依赖。
通道注意力:通道注意力通过压缩和聚合操作,提取出每个通道中最显著的语音情感特征。
首先,通过全局平均池化aPoolsp和全局最大池化mPoolsp生成压缩通道平均描述符和通道最大描述符。然后,通过MLP 对和进行聚合计算。最后,将和映射到原始信道上,通过两个全连接层获得通道权重输出FM'∈RC*1*1。通道注意力计算方式如下:
式中:σ为sigmod 函数,W0和W1∈RC*C为权重参数。最终,通道注意力的输出表示如下:
空间注意力:空间注意力作为通道注意力的补充,能够使得具有强烈情感特征的通道更为突出而抑制情感无关通道。
首先,通过平均池化和最大池化从FM'∈RC*1*1中提取空间平均特征描述符和空间最大特征描述符,有效地建立特征与空间之间的映射关系。然后,对和按照通道方向合并后,采用卷积核f大小为7×7进行卷积计算生成空间特征描述符。最后,通过sigmod函数处理获得情感特征。空间注意力的计算方法如下:
式中:σ为sigmod 函数,aPool和mPool为平均池化和最大池化,f7×7表示与滤波器大小为7×7的卷积操作。最终,空间注意力的输出表示如下:
CNN-BLSTM:语音情感的当前状态不仅与过去的状态有关,而且还与未来的状态有关。因此,本文使用CNN-BLSTM 学习句子级别的情感。首先,为了保持显著的情感信息,减少语音序列的长度,采用尺寸为1×n卷积核对空间时间注意的输出进行卷积计算,其中1 是步幅大小,n是窗口大小,并生成一个向量序列Hcnn=,其中ℎclnn∈Rcnn。其次,为了从语音序列中提取全局上下文信息,以Hcnn作为BLSTM 的输入,输出一系列隐藏状态Hblstm=,其中Hblstm∈Rl*d为第l个前向隐藏状态和第l个后向隐藏状态。l为帧的序列号,d为BLSTM隐藏层的大小。
自注意力:为了有效地应对不同通道语音情感变化的影响,减少对外部信息的依赖,首先输入隐藏状态Hblstm,接着计算注意力权值α。最后,将加权后的特征值连接,得到最终的编码向量Oself=[oemotion,ogender],其中,oemotion∈R1*4为情感类别任务输出的编码向量,ogender∈R1*2为性别分类任务输出的编码向量。具体计算过程如下:
式中:Wl和bl为可训练的参数。
2.3 多任务输出
本文将性别分类与情感分类任务融合,通过并行学习使结果相互影响。两个任务共享输入层和隐藏层的全部参数,通过两个输出层分别输出情感和性别分类结果,并通过以下目标函数对模型进行训练:
式中:yemotion和ygender分别为情感分类与性别分类的标签的编码向量。
3 实验设置
3.1 数据集介绍
为了评估出的模型的性能,本文在交互式情感二元运动捕获数据库(IEMOCAP)[17]上开展了验证实验。该语音数据集包括五个部分,每个部分由一对演讲者(女性和男性)以脚本和即兴的场景录制,样本平均持续时间为4.5s,采样率为16kHz。
本文实验使用了四种情感类别的5531 个句子:快乐(1636 个句子,与兴奋合并)、愤怒(1103 个句子)、悲伤(1084个句子)和中性(1708个句子)。
3.2 参数设置
本实验优化器采用Adam,学习率初始设置为0.001,在第80、120、160 轮分别减小10 倍,batchsize设置为32,epoch 设置为200,训练集、测试集及验证集的比例为8∶1∶1。
对于简单的索赔事项,监理工程师一般在收到报告的1个月之内给出处理意见。但在实际施工中,难免会有个别索赔出现争议。索赔发生争议时,当事人双方应本着合作共赢的态度去协商谈判,不要急于采用诉讼或仲裁的方式。在该案中,承包商考虑到未来还要在当地长期发展,需要维护自己的商业信誉,所以一直坚持采用协商的方式解决索赔,多次谈判之后,承包商在费用方面作出了一些让步,最终以76万元了结了该争议。
训练集和测试集通过训练集的全局平均值和标准差进行归一化,在特征提取步骤中,样本按照帧长25ms 和帧移10ms 进行统一分帧。为了更好地进行并行加速,本文将有帧的样本分割成300 帧等长片段,对于少于300 帧的片段进行零填充。经过分割后,语音片段总数为14521 个,如表1 和表2所示。

表1 不同情感的分割前后的句子数量
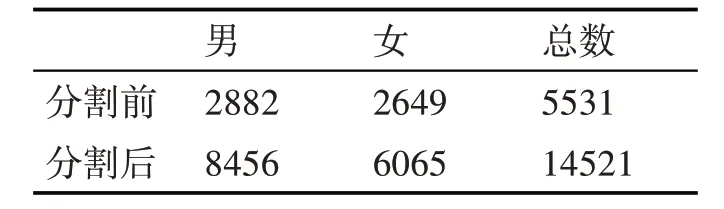
表2 不同性别的分割前后的句子数量
为了验证本文模型的有效性,本文采用加权精度(WA)和未加权精度(UA)作为实验评价指标,对不同模型的实验结果进行评估。
4 实验结果与分析
4.1 多任务学习超参数实验
如图2 所示,为了验证式(13)中不同情感损失占比β对多任务学习结果的影响开展权重选择实验。随着情感损失的提高,WA 和UA 随之提高,并在情感损失占比为0.8时达到顶峰,当β超过0.8时,语音情感分类准确率重新归于平稳。因此本文中的β设置为0.8。
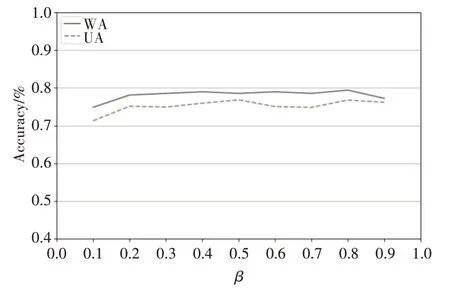
图2 不同β对WA和UA的影响
4.2 对比实验
如表3 所示,为了验证本文提出的方法的有效性,将其与目前IEMOCAP上的先进模型进行比较,对比方法的训练集和测试集配置与本文方法一致。
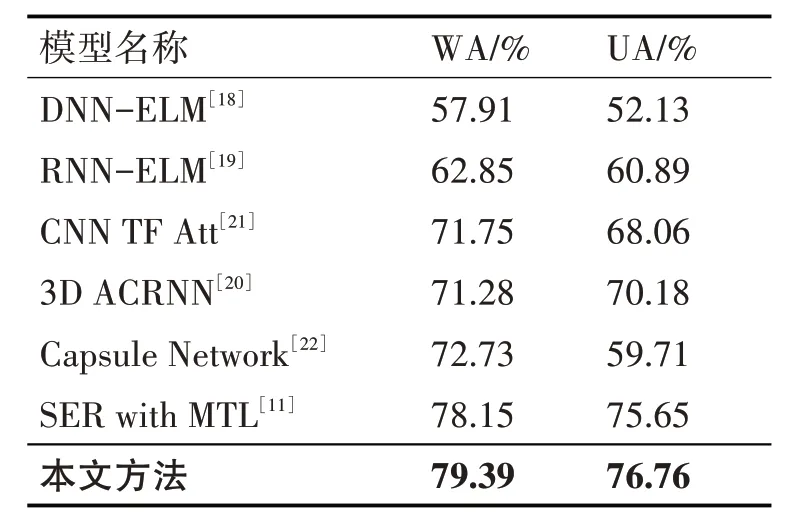
表3 本文方法与6种先进方法对比实验结果
Han[18]等通过DNN-ELM 网络提取了情感特征,然而此方法无法捕捉到情感特征的长时依赖关系和变化过程。为了解决这个问题,Lee[19]等提出RNN-ELM 网络学习语音情感特征的长期依赖关系。为了捕捉情感特征的变化过程,Chen[20]等提出了提3D ACRNN 网络,并使用了由Log-Mel 静态、Deltas和Deltas-Deltas组成的三维差分特征来有效反映情感的变化过程。Li[21]等使用了基于时间和频率方向的特征更有效地表达情绪特征。Wu[22]等为了获得不同空间中集中表达情感信息的位置,使用胶囊网络(Capsule Network)获得了有效的语音情感特征的空间信息表征。尽管如此,上述方法忽略了说话人性别造成的影响。Li[11]等利用基于自注意机制的SER框架,并将说话人性别识别作为一个辅助任务来调整情感识别以提高SER的准确性。
与性能最好的方法相比,本文提出的方法的WA 和UA 分别提高了1.24%和1.11%。本文方法通过将性别分类与情感分类任务融合,通过参数共享,能够有效地检测出高层次的辨别性表征,解决不同性别之间信号差异所带来的影响,从而提升了情感识别的准确率。
4.3 消融实验与分析
4.3.1 级联注意力消融实验
级联注意力消融实验的设置如下:(S1-1)本文方法;(S1-2)AM-MTL:将CAM 替换为空间注意力和自注意力的组合,以验证通道注意力对模型性能的贡献;(S1-3)CM-MTL:将CAM 替换为通道注意力和自注意力的组合,以验证空间注意力对模型性能的贡献;(S1-4)CA-MTL:将CAM 替换为通道空间注意力,以验证自注意力对模型性能的贡献。
首先,为了验证通道注意力在本文方法中的有效性,本文对比了S1-1 和S1-2。表4 的实验结果表明,S1-1 的WA 和UA 比S1-2 的分别提高了1.95%和1.88%。通道注意力作为特征选择器,实现通道内特征的筛选,提取更为重要的语音情感特征,能够显著地提高语音情感识别的效果。

表4 级联注意力消融实验结果
其次,为了验证空间注意力在本方法中的有效性,本文对比了S1-1 和S1-3。 表4 的实验结果表明,S1-1 的WA 和UA 分别比S1-3 提高了1.30%和2.21%。空间注意力通过对比不同通道特征,增强了不同通道特征之间的判别性,获取了通道所能表达的情感特征的优先级。
最后,为了验证自注意力在本方法中有效性,本文对比S1-1 和S1-4。表4 的实验结果表明,S1-1 的WA 和UA 分别比S1-4 提高了1.75%和1.23%。自注意力能够对不同话语特征进行加权打分,有效应对不同通道语音情感变化的影响,减少对外部信息的依赖。
4.3.2 级联注意力特征可视化分析
为了直观地理解通道空间注意力的影响,本文随机选择了一个样本,并将其作为通道空间注意的特征图进行可视化展示。对于该样本,可视化了四种图片。图3(a)为原始Mel谱图;图3(b)为通过通道注意力的特征图;图3(c)为通过空间注意力的特征图;图3(d)为通过通道空间注意力的特征图。图3显示了语音情感特征可视化结果。

图3 级联注意力特征可视化结果
强调重要领域:将图3(b)和(c)与原始Mel 谱图(a)进行对比,通道注意力和空间注意力有效地突出存在隐藏情感信息的语音部分,如图中的共振峰区域。同时,与对应的原始Mel 谱图的相比较,共振峰之间的浅色区域基本被去除,使得情感信息丰富更加突出,通道空间注意力的融合增强了突出含有情感特征的语音表达的能力。
抑制其他区域:在日常生活环境中,语音录制过程中经常会出现突发噪声,如咳嗽、碰撞等噪声,这些噪声在语音Mel 谱上通常有很强的强度。将图3(d)与相应的原始语音Mel 谱图相比较,语音中的无声区域(图中的共振峰之间的浅色区域)基本被去除,而原始语音中情感较强的区域(图中的共振峰所在的深色区域)被保留。这证明了通道空间注意力可以极大地抑制与情感无关的区域。
4.3.3 多任务学习消融实验
多任务学习消融实验的设置如下:(S2-1)本文提出的方法;(S2-2)CAM:将说话人性别识别删除,验证多任务学习对模型性能的贡献。
对比S2-1 和S2-2 验证多任务学习在本方法中有效性,由表5 可知,在性别识别的辅助下,本文提出方法的WA 和UA 分别比S2-2提高了1.95%和2.08%。以性别识别作为情感识别的辅助任务,弱了不同性别在语音情感表达上的内在差异,减少了由于不同性别导致分类错误,因此提高了模型的情感分类能力。

表5 多任务学习消融实验结果
5 结语
本文提出了一种融合级联注意力机制的多任务语音情感识别方法解决非个性化特征提取问题。首先提取时频方向的3D Log-Mels特征以反映情感特征的变化过程,同时解决情感特征混淆问题;然后通过由通道注意力、空间注意力及自注意力组成的级联注意力网络,增强非个性化特征中情感显著区域,抑制情感无关区域,最后通过多任务学习策略,融合说话人性别识别任务辅助说话人情感识别任务,提升情感识别的准确率。实验结果表明,在IEMOCAP数据集中,本模型与最先进的方法相比WA 和UA 分别提高了1.24%和1.11%,能够有效地提升语音情感识别的准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中国生物医学工程学报(2019年6期)2019-07-16
传媒评论(2017年3期)2017-06-13
电子制作(2016年15期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2014年1期)2014-04-04
电测与仪表(2014年1期)2014-04-04
