
基于Fast Unfolding 算法的情感词典扩展方法研究*
2023-06-04 06:24黄树成
计算机与数字工程 2023年2期
陈 力 黄树成
(江苏科技大学计算机学院 镇江 212003)
1 引言
伴随着互联网体量的快速扩张,互联网技术也在飞速发展,在给人们的生活带来便利的同时,也改变着人们的生活习惯。越来越多的人会在社交平台上,针对某一事件发表自己的态度和看法,或者在网络购物平台上分享自己对某个产品或者服务的使用体验。这些网络评论里蕴含着网民的观点、态度、情感信息等。分析其中隐含的信息,挖掘出评论者的情感倾向[1],可以为政府了解民众对于某一政策的满意程度提供数据支撑,为消费者是否产生购买行为提供信息参考,还能对企业改进产品或者服务起到指导作用。
由于网络发展迅速,当前的语言文化日新月异,出现了很多新兴词汇,并且随着网络文化的不断发展,还会不断产生更多新事物。传统情感词典中包含了大量常用词语,具有一定的普适性。但是对于近年来网络上出现的新词汇,情感词典中都没有涉及,因此想要使用情感词典的方法进行情感倾向的判别,还需要在传统词典的基础上进行扩展。
为了提升情感词典的扩展效果。本文将SO-PMI 和Fast Unfolding 算法结合,提出FU-PMI算法。1)使用TF-IDF 改进传统SO-PMI 选取种子词的方法。2)结合PMI 和FU 算法的特点,提出FU-PMI 算法。 3)分别使用SO-PMI 算法和FU-PMI 算法扩展的词典进行情感倾向性分析,比较他们的效果。经实验结果证明,相较于传统的SO-PMI 算法,本文提出的算法可以有效地提高情感词典的扩展效果。
2 相关工作
基于情感词典方法是将构建好的情感词典作为判别工具,通过对原始语料的处理(分词、去停用词等)后得到的数据在情感词典中遍历,根据设定的规则给予不同词语单独的权重,最后计算出它们的得分,最后根据得分对它们进行分类。
1988年,Whissell[2]邀请148人使用若干个词语来对9 部情景剧的片段进行描述并打分,然后与常用的情感词进行配对,这是最早使用情感词典的案例。之后Whissell[3]又对原先的情感词典进行了修订,提高了单词的匹配率。由于中文情感词典的资源较少,考虑到国外情感词典发展较早,语料和词典较为丰富,李寿山等[4]使用机器翻译系统,在英文种子词典的基础上,构建出了中文情感词典。
阳爱民等[5]通过选取若干个种子词,利用搜索引擎返回的共现数来计算权值,构建情感词典。Rao等[6]提出了一种基于主题建模的方法来构建主题级别的词典。王志涛等[7]提出了基于词典和规则集的中文微博情感分析方法,根据不同规则进行了从词语到句子的多粒度情感计算[8]。周杰[9]通过改进C4.5 决策树分类算法,并在此基础上利用拉普拉斯平滑的SO-PMI 算法对词典进行扩展,提出一种新的基于情感词典和句型分类的中文微博分析方法。韩煦[10]等为解决中英文共同使用时但以中文词典无法解决的情况,提出了构建双语多类情感词典的分析方法。Vilares[11]未解决多语言极性分类问题,通过融合单语言资源,并引入带有情感标签的语料库,给出了在多语言数据集上训练的多语言模型。
对于基于机器学习的方法,国内外研究者也取得了很多成果。Sharma等[12]提出一种混合模型,该模型将SVM(支持向量机)与Boosting 结合,在在线评论分类上证明了该方法的有效性。Shi等[13]通过介绍基于随机条件的情感识别模型,提出了一种改进的情感词强度计算方法。Giatsoglou 等[14]给出了一种基于词典、词嵌入和混合矢量的研究方法。梁斌等[15]提出了一种基于多注意力卷积神经网络的特定情感分析方法。
3 基于Fast Unfolding算法的情感词典构建
3.1 语料的选取
本文以手机评论信息作为案例,使用某电商平台销量前6 的手机评论作为原始数据集。在去重、删除无用评论信息等操作后,得到的数据如表1 所示。

表1 评论数据
为了方便统计和计算,选取正面评论和负面评论各5000 个作为实验语料,从中各随机抽取3000条分别作为正负面评论训练集,剩下的各2000 条作为测试集。
3.2 基础情感词典的构建
目前有很多机构发布了情感词典,如《知网》情感词词典等,但是它们都有着各自的局限性。为了保证实验的准确,本文通过搜集整理,合并了知网Hownet 情感词典、台湾大学NTUSD 情感词典以及清华大学中文褒贬义词典作为实验的基础情感词典。各情感词典和合并去重后的词典详情如表2所示。
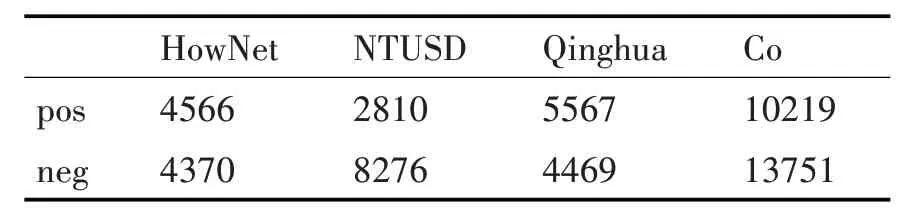
表2 基础情感词典

表3 划分示例
表2 中,展示了不同词典中褒义词和贬义词的数量,其中NTUSD 为台湾大学情感词典,Qinghua为清华大学中文褒贬义词典,Co 为几种情感词典合并后去掉重复的词得到的情感词典[16],即基础情感词典。
3.3 情感词典的扩展
3.3.1 SO-PMI算法
点互信息(Pointwise Mutual Information,PMI)是SO-PMI 算法的核心,用来表示词与词之间的关联程度。Turney[17]等根据PMI 的概念将其应用到词语间互信息的计算,计算公式如下所示。
其中,p(wi,wj)代表词i 和j 在同一条文本中共同出现的概率。p(wi)和p(wj)分别表示词i和词j在单位文本中独自出现的概率。在实际计算中,上述概率值可以用频率来表示,即有如下公式:
式(2)~(4)中:count(wi,wj)表示词i 和词j 在语料中共同出现的文本数;count(wi)表示包含词i 的文本数,count(wj)同理;q为数据集中总的文本条数。根据上述计算方式便可以通过将情感倾向未知的词分别与不同类别情感倾向的词的互信息值得差值来给其分类,可以用式(5)表示。
其中w是待分类的词,w+和w-分别代表褒义和贬义种子词。实际应用中会选取一定规模的带有明显情感倾向的正向种子词和负向种子词,因此,公式调整为如下所示,
选定n 个正向情感词和负向情感词,分别计算待分类的词w 和他们的SO 值,设定相应阈值,大于阈值则判定w 为正向情感词;小于阈值则为负向情感词;等于阈值则代表w不具有情感倾向性。
传统的SO-PMI 基准词选取方式为人工地从情感词典中选取若干组带有强烈情感倾向性的词汇作为待选基准词,这种方式带有一定的主观性,并且除了效率低下外还可能导致基准词出现频率过低,与候选词共现频率为0 的情况。根据式(1)可知,这种情况就无法计算其情感倾向了。因此本文采用以下方式选取基准词:1)读取评论文本数据,将读取到的数据放入集合T={t1,t2,…,tn};2)对T 中的每个文本元素进行预处理、去停用词等操作得到ti*;3)使用TF-IDF 算法对ti*进行计算,选取其中词性为/v,/vi,/vn,/a 的词语加入候选词集合T_CONDI ={tc1,tc2,…,tcn};4)遍历tci,若其在基础积极情感词典中,则放入积极情感基准词集合P_CONDI 中;若在基础消极情感词典中,则放入消极情感基准词集合N_CONDI 中;若不在基础情感词典中,则分别比较tci在正向语料和的负向语料中的TF-IDF 值,若前者大,则将tci放入P_CONDI,反之放入N_CONDI。至此,情感基准词集合选取完毕。流程如图1所示。
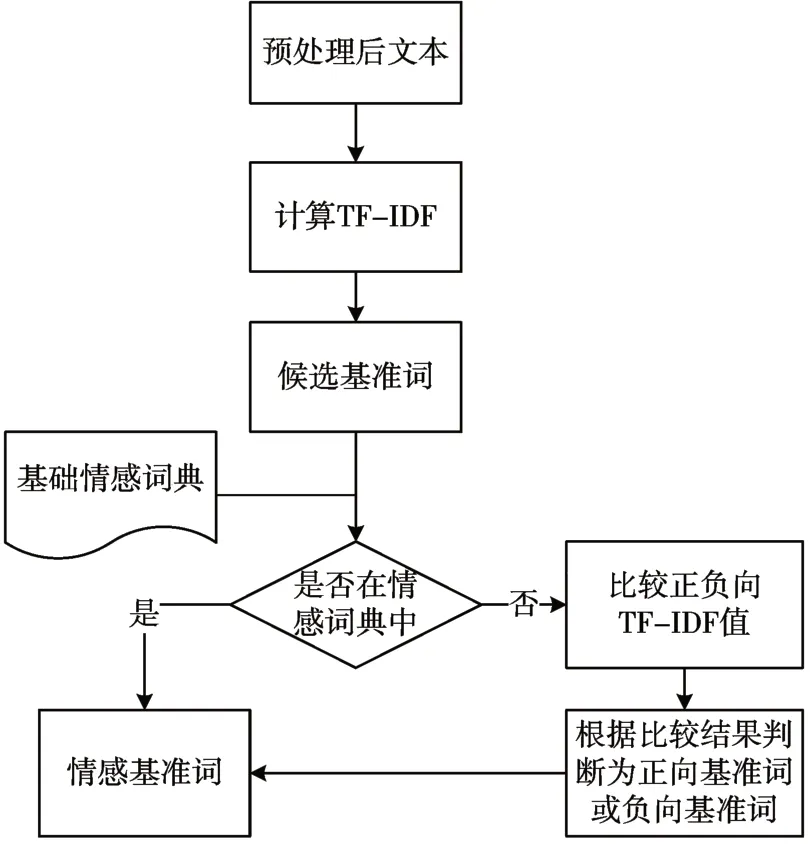
图1 基准词选择流程
3.3.2 Fast Unfolding算法
Fast Unfolding 算法是一种基于图理论的社区发现算法。社区划分的目的是使得划分后的社区内部连接较为紧密而社区间的连接较为稀疏。算法通过模块度来评判社区划分的效果。模块度的概念由Newman[18]等提出,简单来说,连接越紧密的点划分到一个社区中,模块度的值越大,模块度最大的划分就是最优的社区划分[19],公式如下:
将节点i放入社区后,Q的变化值为
其中ki,in代表社区中的节点和i 节点的连边权重之和。算法基本流程如下:
Step1:将图中每个节点当做独立的社区;
Step2:尝试将每个节点i 加入到其每个邻居节点,计算加入后的模块度;
ΔQ 的变化量,如果maxΔQ>0,则将节点i合并到ΔQ最大的社区,否则不变[20];
Step3:重复step2的步骤,直到节点所属社区不再变化;
Step4:将step3中得到的社区压缩,构成新的节点;
Step5:重复上述步骤,直到ΔQ不再大于0。
使用FU 算法,通过社区划分可以很好地弥补式(1)中,基准词和候选词无法共现的问题。比如,现有基准词“好看”,和候选词“漂亮”和“耐用”,显然它们都属于积极情感词,但是由于“好看”和“耐用”共现次数为0 导致无法将“耐用”加入到积极情感词中。使用FU 算法,则可以通过其他词语之间的联系,将其正确的划分到一个社区。程序示例效果如下。
3.3.3 FU-PMI算法
有了3.3.1 节和3.3.2 节的铺垫,我们便可以提出FU-PMI 算法。由上文可知,SO-PMI 最大的缺陷就是基准词的选取,一是人工方式的成本过大,二是当基准词出现频率过低或者和候选词无法共现时会导致候选词无法被正确的分类。针对这两个缺点,首先引入了TF-IDF算法来选取基准词,避免了大量的人工劳动的同时,提高了基准词的质量。其次,文本分类也可以看作是一种社区的划分,并且通过社区划分,可以解决两个词共现不了导致无法分类的问题。
Fast Unfolding 算法是一种基于图论的无监督算法,只需要考虑构建初始的图结构。3.3.1 中提到的PMI可以反映词与词之间的关联程度,因此本文选用语料中词语作为节点,词语间的PMI值作为权值,使用第三方库networkx 进行图结构的构造,之后经过3.3.2 介绍的算法的步骤便可以得到划分出来的社区。
在得到社区数据之后,就要结合3.3.1 中方法所构建的基准词集合来进行词典的扩展了。之后将图中得到的候选词加上基准词与基础情感词典合并、去重,便得到了扩展后的情感词典。
4 算法测试
4.1 数据集
本文使用3.2 节中筛选出的4000 条评论数据作为数据集,其中正面评论2000条,负面评论2000条。
4.2 实验环境
实验是在CPU 服务器上运行的,CPU 型Inter(R)Core(TM)i7-8750H,内存为16G,软件环境为Python3.7。
4.3 评价指标
对于词典扩展的结果,本文使用准确率(Precision),召回率(Recall)以及F1 值三个指标进行分析。计算方式如下:
TP 代表样本情感为正向,判别为正向。FP 代表样本情感为负向,判别结果也为负向。
其中FN 代表样本的情感倾向为正向,预测得到的结果却为负向。
F1折中了召回率和精确率。
4.4 实验结果分析
为了更加清晰的观察到算法的效果,本文分别选取20、40、80 个基准词,在不同的条件下,观察两种算法扩展的词典的实际效果。详细数据如表4~6所示。

表4 20个基准词下的准确率、召回率和F值
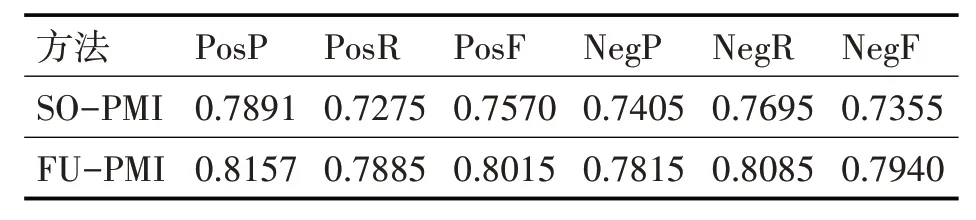
表5 40个基准词下的准确率、召回率和F值
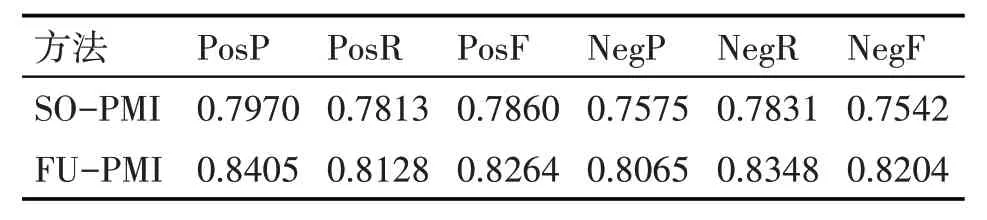
表6 80个基准词下的准确率、召回率和F值
表中PosP、PosR、PosF 分别代表正面情感判别的准确率、召回率和F1值,NegP、NegR、NegF分别代表负面情感判别的准确率、召回率和F1值。
从表4~6 可以看出,随着基准词的增多,两种算法扩展词典的正确率、召回率以及F1值都在稳步提升,但是增速随着基准词的增多而放缓。相同基准词的情况下本文算法扩展的词典相较于SO-PMI算法有着较大的提升。从图2 和图3 可以看出,FU-PMI的扩展效果在正面情感词和负面情感词扩展上明显优于SO-PMI 算法,证明了算法在扩展词典上的有效性。
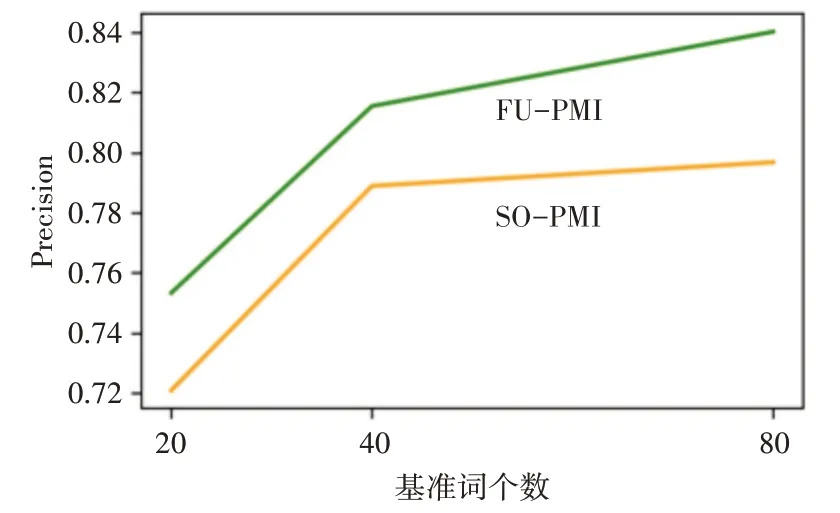
图2 正面情感准确率
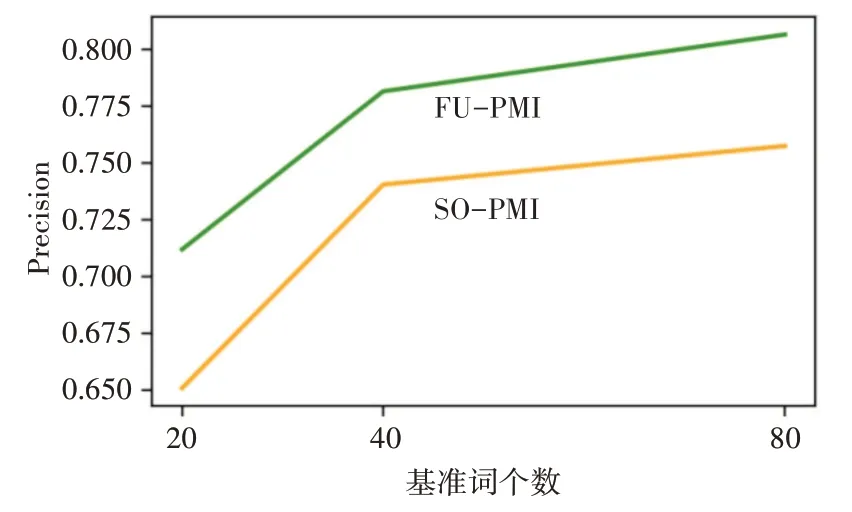
图3 负面情感准确率
5 结语
本文提出了一种融合PMI和FU 算法的情感词典扩展算法,利用PMI 可以表示词语间关系的特性,使之作为权值加入到FU中进行社区划分,然后使用TF-IDF 算法优化了传统的基础词选取,提高了基准词的代表性。最后以改进得到的基准词为基础,从社区中筛选出正负向情感候选词,完成情感词典的扩展。实验证明算法在情感词典扩展方面相较于传统的SO-PMI 算法有着较大的提升。但是算法还有改进的地方,比如在构建图结构的时候没有考虑到降噪等因素,可能是导致算法在消极词汇上表现不如积极词汇的原因,也为以后的工作提供了新的思路。
猜你喜欢
文苑(2019年24期)2020-01-06
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
海外华文教育(2016年1期)2017-01-20
公民与法治(2016年19期)2016-05-17
当代教育理论与实践(2015年9期)2015-12-16
读者·校园版(2015年7期)2015-05-14
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
河南科技(2014年15期)2014-02-27
