
基于深度学习的轨道交通行人检测方法*
2023-06-04 06:24司广字刘光杰焦科杰王政军
计算机与数字工程 2023年2期
司广字 刘光杰 陆 斌 焦科杰 王政军
(1.南京信息工程大学电子与信息工程学院 南京 210044)(2.南京熊猫信息产业有限公司 南京 210038)(3.海康威视 南京 211106)
1 引言
随着城市人口的增加,城市道路越发拥堵,但同时给轨道交通事业带来了蓬勃的发展,越来越多的城市开始建设地铁,其中一些城市的地铁已经成为市民重要的出行工具。随着乘坐地铁的乘客越来越多,不可避免地会出现拥堵并带来一些安全问题,然而现有地铁内的各个业务系统还无法实现站内客流的实时检测。因此,研究使用基于地铁内监控视频的行人实时检测方法,对于城市轨道交通的安全运营和管理具有十分重要的意义。现有的行人目标检测方法主要包括基于传统图像分析的目标检测算法与基于深度神经网络的目标检测算法。传统目标检测方法主要是使用滑动窗口法,该方法主要通过使用随目标尺寸变化的窗口对图像进行全局搜索确定目标位置,原理简单但效率低下。Uijlings 等[1]基于图像中的目标区域具有连续性和相似性等特点提出了选择性搜索方法对滑动窗口法进行了改进,提高了目标检测的效率。在深度学习方法领域中,Girshick 等[2]利用选择性搜索方法提出了基于区域的卷积神经网络R-CNN(region-based convolutional neural network),但由于R-CNN 网络需要对每张输入图片的上千个变形后的区域进行卷积操作,所以计算量非常大,速度很慢。2015 年Girshick[3]基于R-CNN 提出了一种快速的基于区域的卷积网络模型fast R-CNN,但是fast R-CNN 仍旧无法满足实时检测的去求,于是Ren 等[4]提出了改进模型faster R-CNN,用区域提议网络替代了原来的选择性搜索方法进行候选区域提取。2017 年He 等[5]以faster R-CNN 为原型,融入了FCN(fully convolution network)[6]用于生成每个候选区域的掩膜,达到了更好的检测效果。虽然基于候选区域的目标检测网络在检测精度上达到了首屈一指的地步,但其检测速度仍然存在弊端。2016年Redmon等[7]将目标检测问题抽象成回归问题,提出了YOLO 检测模型,通过对完整图像的一次检测预测出感兴趣目标的边界框和类别,摒弃了R-CNN 系列中将检测任务分成两步走的操作,解决了目标检测模型效率低的问题但是对小目标的检测效果不佳。之后,Redmon 等[8~9]提出了YOLO 的改进版本YOLOV2 和YOLOV3 检测模型提高了目标检测的速度和精度。2016 年,Liu 等[10]继承了YOLO 模型的思想提出了SSD 目标检测模型,其利用不同尺度的特征图进行不同尺度的预测,相对于YOLO 精度和效率都有提升。近年来,很多人从姿态估计中获得启发,通过检测目标的关键点有效获取目标信息,比如CornerNet[11]以及CenterNet[12]模型等。
基于深度学习的目标检测算法往往依赖于更为复杂的深度网络模型,导致需要更多的计算资源,无法直接应用于需要同时分析多路视频的轨道交通场景。此外地铁场景下不仅有稀疏客流,还会存在密集客流,所以以上算法在地铁场景下的应用仍然存在以下几个问题:
1)多姿态人体目标检测的准确率问题:人在目标检测中可以看作一个非固定物体,形状变化多样,大小不一致,并且服装各式各样,在地铁内各种角度的监控摄像头下的行人几何形状差异较大,因此需要一个泛化能力强的行人检测器。
2)遮挡问题:地铁场景下的摄像头安装位置比较低,获取的视频流中行人会出现严重的遮挡情况,导致检测难度加大,所以需要标注此类数据且保证检测算法能兼顾此种情况。
3)计算资源需求:现有的目标检测算法考虑更多的是多种目标的平均检测准确率,所以网络结构较为复杂,对计算资源需求较高,针对地铁场景下的人体目标,需要在保证精确度足够的前提下设计更轻量化的检测模型。
针对上述问题,本文从目标检测的网络结构出发,考虑地铁场景中的行人检测尺寸相对固定,在YOLOV3 模型结构的基础上只保留了32 倍下采样的分支,减少了网络的深度,引入了Inception-V3结构[13],目的是在减少参数量的同时通过不同尺寸的滤波器,来获取不同感受野下的特征,并进行特征融合,以检测不同大小的物体。由于地铁场景下的人流存在遮挡严重的情况,本文将NMS(Non-Maximum Suppression)操作替换为softerNMS操作[14],为了使模型的训练精度更高以及收敛速度加快,本文引入了GIOU作为损失函数[15]。
2 相关技术
2.1 Inception结构
Inception 结构是在2014 年的ImageNet 竞赛中,google 团队提出的GoogLeNet 中所用到的网络模块。在Inception 结构中采用三种不同尺寸的滤波器,获得不同感受野下的特征,然后进行特征融合操作,另外Inception 结构利用1×1 的卷积核进行稀疏连接以减少参数量。本文采用Inception-V3结构是在原始Inception 结构上做了优化,原始Inception 结构如图1 所示,经过发展后的Inception-V3-1、Inception-V3-2、Inception-V3-3 结构分别如图2、图3、图4所示。
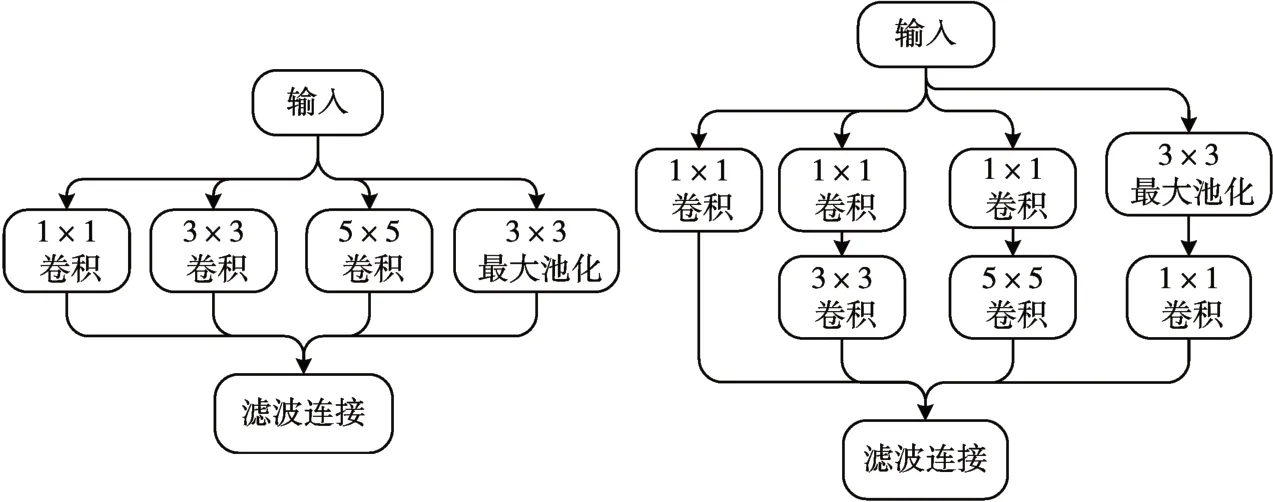
图1 Inception结构
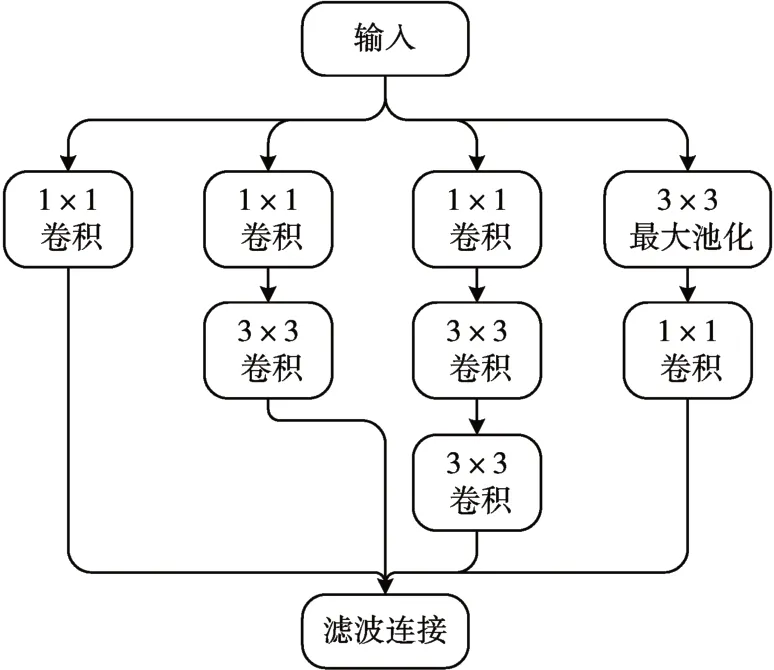
图2 Inception-V3-1结构

图3 Inception-V3-2结构

图4 Inception-V3-3结构
从图2~4 可以看出对Inception module 的做出了如下优化:
1)用较小的卷积核替代原来的卷积核以减少参数量从而提升网络的运算速度,例如使用5×5 的卷积核可以用两个3×3的卷积核代替。
2)用两个一维卷积代替二维卷积可以获得更全面的特征,增加模型的表征力。例如n×n 的卷积核用1×n的卷积核与n×1的卷积核代替。
2.2 softerNMS算法
由于YOLOV3 采用NMS 操作过滤重复检测框,但是在地铁场景下会出现比较严重的行人遮挡问题,如果继续采用NMS 操作则可能会把非相同目标的全部检测框过滤掉,造成召回率低的后果,因此采用softerNMS 操作,不再将IOU 大于某个阈值的BOX 得分直接置零,而是采用低一点的分数来代替原有的分数,以提高召回率。该算法的原理具体如下所示:
输入:原始目标检测框B={b1,…,bN}
对应的目标框置信度S={s1,…,sN}
输出:保留的目标检测框D
对应的目标框置信度S
2:whileB≠emptydo
3:m←argmx S
4:M←bm
5:D←D∪M;B←B-M
6:forbiinBdo
8:end
9:end while
10:returnD,S
2.3 改进的损失函数
由于在YOLOV3 以及一般的目标检测损失函数中,没有发挥IOU度量的作用,因此,针对本文单类别行人检测目的对损失函数做了IOU的优化,改进后的损失函数是在YOLOV3 损失函数的基础上融入了文献[15]提出的GIOU 思想。GIOU 的计算方法为对于真实框T 以及与之对应的预测框P 之间,可以找到其最小凸集C,如图5(包围T、P 的最小包围框),利用最小凸集即可计算GIOU。
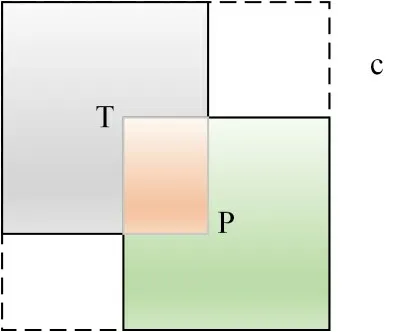
图5 GIOU示意图
GIOU有如下性质:
1)与IOU类似,GIOU也可以作为一个距离,loss可以用LGIOU=1-GIOU来计算。
2)与IOU类似,GIOU对物体的大小不敏感。
3)GIOU总是小于等于IOU,对于IOU,有0 ≤IOU≤1,GIOU则是-1 ≤GIOU≤1,在两个框完全重合时,有GIOU=IOU=1。当两个框不重合时,IOU始终为0,不论T、P 相隔多远,但是对于GIOU来说,T,P 不重合度越高(离得更远),GIOU越趋近于-1。
最后设计的损失函数为
其中S2代表最后的特征图(feature map)网格数,B代表每个网格有几个锚点框(anchors)预测,表示第i个栅格中第j个预测框是否负责这个目标(与该目标的标注数据真实框的IOU 最大的预测框负责该目标的坐标预测),fignore表示是否标注数据真实框和与之对应的检测框的IOU 大于设定的IOU阈值。
YOLOV3 基于COCO 数据集训练,可以检测80种类别的目标,而本文针对单类行人目标进行检测,与YOLOV3 的损失函数不同,改进的损失函数将其中的分类损失部分舍弃,减少了计算量、降低任务难度、加快了训练收敛速度的同时,对模型的精度带来较小的影响。另外也可以利用λc增大正样本置信度损失权重,将训练优化重点聚焦在检测目标正样本上。此外,利用GIOU可以发挥IOU度量的作用,使网络模型在训练过程中朝获取更准确的检测框方向优化。
3 检测算法网络模型
本文针对地铁场景下的单一行人目标检测,设计LPDNet 检测网络,该网络首先使用一个卷积核为3×3 的标准卷积层进行图像特征提取,然后采用了13 个可分离卷积层进行特征提取来加快特征提取的速度,接着使用一个Inception-V3-3 结构,通过不同大小的卷积核支路获得不同的感受野,多维度感知目标整体和局部的特征,来获取更准确的特征图,其中1×1 的卷积支路通道数为384,3×3 的卷积支路通道数为384,5×5 的卷积支路通道数为128,最大池化层支路通道数为128。最后使用一个卷积核大小为1×1 的标准卷积层提取最终的特征图,将特征图输入到Detection 层,通过softerNMS等操作输出检测框的坐标与置信度。LPDNet检测网络的结构框图如图6所示。

图6 LDPNet的总体框架图
如表1所示,LPDNet模型采用1×Conv、13×DP、1×Inception-V3-3、1×Conv、1×Detection 的网络结构,总共下采样五次,分别发生在Conv0、DP2、DP4、DP6、DP12层,每次都是两倍下采样,最后达到总下采样的32倍。最后的卷积层Conv15中存储了网络预测框相对锚点框(anchor)的x轴坐标偏置量(X)、y 轴坐标偏置量(Y)、框宽偏置量(W)、框高偏置量(H)、检测置信度(Confidence)、classes分类信息,所以卷积层的通道数为3×(5+1)=18,其中3 表示三个anchors,即每个网格预测数为3;5 表示X、Y、W、H、Confidence 五个信息量;1 表示需要分类的种类只有行人一种。

表1 LPDNet网络结构表
通过将LPDNet 网络的参数量与Faster RCNN、YOLOV3 进行对比,如表2 所示,可以看出LPDNet网络可以使浮点计算量大大减少。
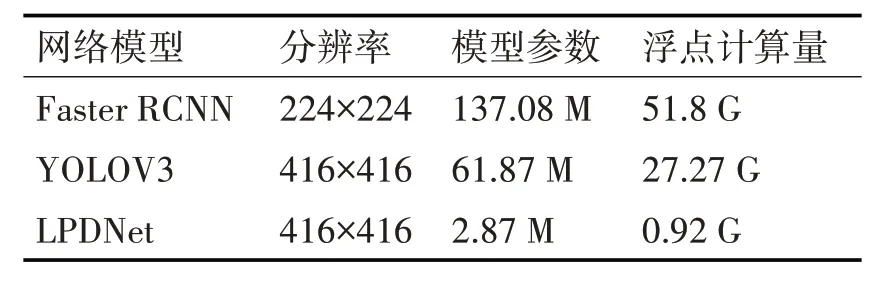
表2 网络参数、计算量
从表2 可知与Faster RCNN 相比,LPDNet 在使用更大分辨率的输入图片时,参数量反而仅为Faster RCNN 的1/48,浮点数计算量仅为Faster RCNN 的1/56;与YOLOV3 相比,使用相同分辨率的输入图片时,参数量仅为YOLOV3 的1/22,浮点计算量仅为YOLOV3 的1/30。定量分析表明LPDNet 可以大幅度降低参数量以及计算量,在轨道交通场景摄像头数量巨大的情况下,每台服务器能够同时实时分析更多的视频数据,可以显著降低成本。另外当前智能摄像头中常使用边缘计算,而边缘芯片的算力有限,使用小模型可以满足实时计算要求。
4 实验与结果分析
4.1 数据集准备
本文实验所采用的数据集一部分为地铁实际场景下标注的数据(NCC),另一部分为公开数据集,例如COCO 与PASCAL VOC,COCO 数据集包含了行人和其他总共80个物体的类别,PASCAL VOC包含了20 个物体类别,分别从中将标签为人的数据类挑选出来。为了验证LPDNet模型在公开数据集以及实际数据集上的效果。测试集选用了VOC2007 TEST 与NCC 的部分数据。最后实验准备的数据集分布如表3所示。
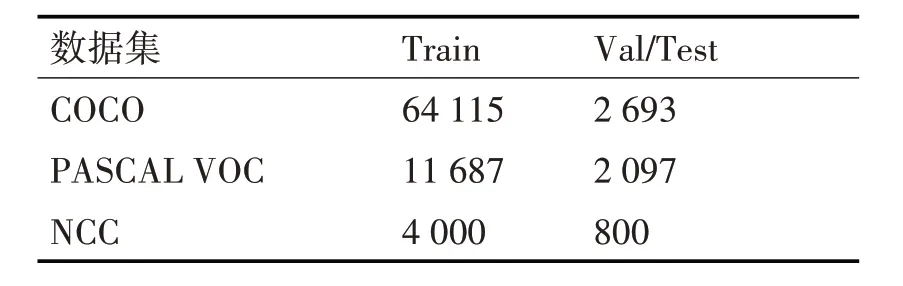
表3 数据集分布情况
4.2 测试指标
行人检测测试的性能指标采用如下三个指标:
1)mAP(用户衡量模型的准确率)。
2)模型速度,主要测试模型的推理时间,以多帧测试取平均。
3)模型推理时占用显存,单卡多路视频分析测试。
4.2.1 mAP计算
分类结果一般会出现如表4 所示的4 种情况,其中TP 表示正例分类正确;TN 表示负例分类正确;FP表示负例分类错误;FN表示正例分类错误。

表4 评估预测混淆矩阵
利用上述四个变量可以计算出准确率P(Precision)与召回率R(Recall):
在目标检测中,根据检测框的置信度降序排列分别获取每个检测框与所有标注数据真实值(ground truth)的IOU,记录最大的IOU 值,当该IOU≥0.5,称之为匹配项,且每个标注数据框最多匹配一次,此时该检测框记为TP;当该IOU<0.5,该检测框记为FP。最后没有匹配到检测框的标注数据框记为FN,已知TP、FN、FP,可以求出P、R值。
目标检测的检测框数目与质量可以通过置信度的阈值进行调整,通过设置不同置信度阈值可以获得不同的准确率(P)与召回率(R),在计算平均精度(Average-Precision,AP)时,就是按照不同的阈值设定获得多组P-R值,最后使用不同的P-R值组计算AP,P-R曲线示例如图7所示。
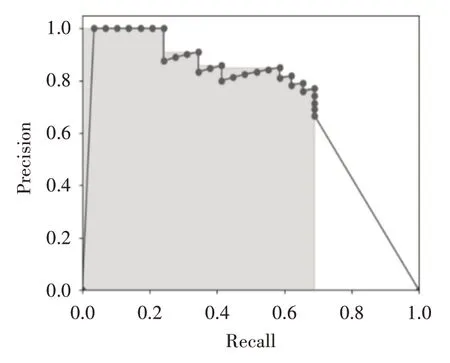
图7 P-R曲线图
如图7 中有多组P-R 值,以点表示,每个点往左画一条线段直到与上一个点的垂直线相交,这样阴影区域面积就是AP 值。AP 值越大,代表模型效果越好。如果存在多类检测,按相同方法计算出AP后求取平均值就是mAP值。
4.2.2 性能对比
本文将提出的LPDNet 与Faster RCNN 以及YOLOV3 模型进行实际计算资源占用、计算速度、模型文件大小对比,对比结果如表5所示。

表5 网络模型计算资源占用、推理速度
由表5可以看出在实际应用测试中,LPDNet对比Faster-RCNN 和YOLOV3 的计算资源需求显著减少,推理速度显著加快,模型大小显著减小。
本文提出的LPDNet 模型基于Caffe 框架设计,具体性能对比测试结果如表6所示。

表6 网络模型测试mAP
由表6 可以看出,YOLOV3 对于行人单类检测的mAP 略微高于LPDNet。在行人大小差异大,场景复杂多样的VOC 数据集上差距不到3%,而在行人大小差异不大,场景比较固定的地铁NCC 数据集上,检测效果的差距仅为0.54%。实验结果表明,本文提出的LPDNet 相比较于YOLOV3 算法能够在轨道交通场景中实现相近的检测结果,但计算速度明显优于YOLOV3模型。
5 结语
针对目前的目标检测算法在地铁场景下的行人检测实时性不高的问题,本文提出了一种更轻量化、快速化的行人检测算法,该算法在改进YOLOV3 的同时,加入了Inception-V3-3 网络结构模块,考虑到地铁场景中的行人遮挡问题,改用softerNMS 检测框去重算法,同时去除原损失函数中的分类部分并引入了GIOU思想。本文基于公开数据集中的行人样本和真实地铁场景中的行人样本进行实验,对比了YOLOV3、Faster-RCNN算法与本文提出的算法的检测效果与检测速度,实验结果表明,本文提出的LPDNet 行人检测算法在检测效果相差不大的情况下,推理速度显著加快,模型大小和所需的计算资源显著减小。本文提出的方法目的在于应用在地铁场景下检测行人目标,但是在人群密集的情况下仍存在部分漏检的情况,针对这一情况,今后将从目标检测算法的原理和检测模型设计方面进行深入研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
电视技术(2014年19期)2014-03-11
上海理工大学学报(2012年2期)2012-03-20
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
