
基于时间序列神经网络预测模型的职工出勤记录数据校正方法
2023-06-02 23:52:01魏葳耿一婷吕倩杨显军
计算机应用文摘 2023年10期
关键词:神经网络
魏葳 耿一婷 吕倩 杨显军


关键词:神经网络;出勤记录;数据校正
1引言
可靠且准确的职工出勤数据可以为企业的决策和调度工作提供重要信息,但由于企业内职工的出勤记录数量较大,出勤记录会不可避免地出现误差,因此需要对职工的出勤记录进行核对和校正[1]。本文基于时间序列神经网络预测模型,设计职工出勤记录数据校正方法,为企业内的出勤数据修正提供理论支持。
2显著误差检测原理约束出勤记录数据未知变量
在变量不可测的基础上对误差变量进行估计,剔除出冗余性变量。在显著误差的检测原理下给定统计函数,计算式为:
3基于时间序列神经网络预测模型获取校正最优解
按照时间序列神经网络预测模型对职工的出勤记录数据进行误差误测,在反向推导中获取校正最优解。其中最优解的计算精准度与预测误差有关,因此需要保证预测误差在最小范围内,即:
4全覆盖视域流程下实现职工出勤记录数据校正
在时间序列神经网络预测模型的相关性分析下,对出勤数据进行核对和校正。分析校验报错形式如表1所列。
根据表1所列,在工作现场需要对出勤进行记录,按照前置确认和过程验证2种形式,对工作人员的出勤情况进行分析。基于对现场工作中出现的错误类型的分析,将上文中获取的预测模型最优解代人校正过程中,以全覆盖的形式设计校正流程,对错误情况或是符合条件的内容进行覆盖。
在进行职工出勤记录校正时需要对基础表格进行获取,并对照职工在不同时段内的出勤记录和相关文件,将数据导人至模型内。按照逻辑和策略在校验过程分类出2个路径,即报错和通过,当出现报错后转入校正环节,没有出现错误的直接归纳到新的文档中,在校正完毕后进行基础表格输出。至此,基于时间序列神经网络模型实现校正方法设计。
5实验测试分析
实验测试中选择动态数据校正方法和多层次数据校正方法作为对照组,分别与本文方法进行对比,以驗证不同校正方法的有效性。
5.1准备职工出勤记录数据
以某电网企业作为测试对象,对其工作人员的现场工作活动进行数据调取,以保证出勤记录数据的真实性。随机选择15名工作人员的打卡时间,并将其作为数据来源。该企业的正常上班时间为8:00,下班时间为17:00,超过5min为迟到,提前打卡为早退。调取2022年12月无迟到和早退人员的数据记录如表2所列。
根据表2所列,在随机选择的工作人员中出现了出勤打卡记录错误的情况,具体情况如下。
(1)12月15日:编号为#16和#32工作人员在上班打卡日寸出现记录异常,表现为迟到状态;而编号#34的工作人员在下班打卡时出现异常,表现为早退状态。
(2)12月27日:编号为#28的工作人员表现为迟到状态;编号为#40工作人员表现为早退状态。
基于上述情况,需要对工作人员的打卡记录进行校正,使其在工资记账前修正为正确形式,不影响工作人员的全勤保障。
5.2出勤数据校正准确性比较及分析
将上述出现问题的数据上传至测试平台中,分别连接3组校正方法,以验证不同方法校正的准确性。调取视频监控整理上述人员的实际打卡时间,具体情况如下。
(1)12月15日:编号#32工作人员上班打卡时间分别为7:58;编号#34工作人员下班打卡时间为17:05。
(2)12月27日:编号#28工作人员上班打卡时间分别为7:55;编号#40工作人员下班打卡时间分别为17:15。
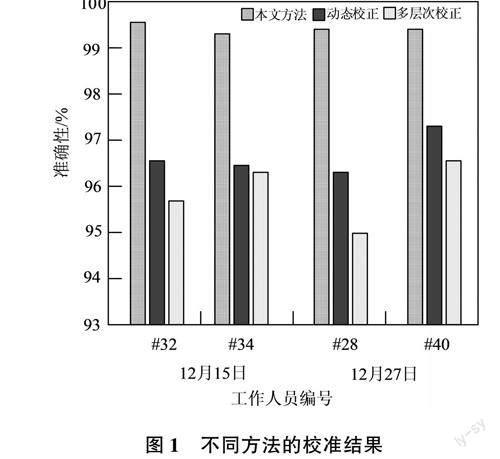
以视频调取数据作为校正对照,分别验证不同方法的校正准确性,具体如图1所示。
根据图1测试结果可知,本文方法的打卡记录校正结果准确性高于99%,而2组方法在不同日期内的校准结果与实际数据存在较大误差,综合结果可知本文方法更有效。
5.3出勤数据校正效率对比及分析
上文验证了新方法的校正准确性,为进一步验证新方法的有效性,对多组职工出勤数据进行校正效率测试。仍将上班打卡和下班打卡的数据记录作为测试对象,调取该企业2022年内所有错误数据,测试结果如表3所列。
根据表3所列,在不同月份中产生的错误出勤记录有所不同,在本文方法应用下能够在20s内完成校正,而动态数据校正方法和多层次数据校正方法所需的时间明显比本文方法更多,说明本文方法的数据校正效率更高。
6结束语
本文通过时间序列预测模型的应用并结合实验验证了新方法的有效性,其能够对职工的出勤记录进行有效校正。但由于时间有限,在研究中只选择了较少的数据完成测试,具有一定的不足,后续研究中会增加校正的数据类型,为企业员工的出勤记录数据校正提供理论支持。
猜你喜欢
装备制造技术(2020年11期)2021-01-26 00:39:08
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年12期)2019-07-16 08:45:28
中国生物医学工程学报(2019年5期)2019-07-16 07:56:56
北京航空航天大学学报(2017年12期)2017-04-23 08:31:45
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
电测与仪表(2014年20期)2014-04-04 11:58:02
电测与仪表(2014年2期)2014-04-04 09:04:04
