
基于联合训练的分类器的乳腺癌图像分类
2023-06-02 06:33张晋凯白艳萍梅银珍
计算机测量与控制 2023年5期
张晋凯,高 翔,王 鹏,白艳萍,梅银珍
(中北大学 数学学院,太原 030051)
0 引言
根据世界卫生组织国际癌症研究机构(IARC)的最新统计数据显示:2021年乳腺癌成为全球发病率最高的癌症,其发病率和死亡率均为女性癌症首位,并且整体发病率呈上升和年轻化趋势[1]。因此,乳腺肿瘤的早期检测和诊断治疗显得格外重要。目前组织病理学分析是乳腺癌诊断的主要方法。病理学家根据活检获得的病理图像来判断乳腺癌良恶性[2]。但是由于病理图像本身的复杂度会导致病理学家有细微的诊断分歧进而减缓诊断效率,并且长时间工作也会影响诊断的结果甚至是误判,从而需要大量人力物力来分析病理学图像。近年来,利用机器学习诊断乳腺癌的计算机自动识别技术愈发成熟,它通过分析大量的乳腺癌病理图像数据来提高诊断的准确率与效率。卷积神经网络提取组织病理学图像特征后,利用机器学习模型来对乳腺癌图像进行分析,进行乳腺癌良恶性分类。
Spanhol等[3]利用卷积神经网络进行特征提取与之前使用手工制作的纹理描述符进行比较,并使用最近邻算法、支持向量机、决策树、随机森林等不同的分类器对乳腺癌病理图像特征分类,实现了识别率的提高。Hou等[4]采用数据增强和迁移学习来改进的深度卷积神经网络模型对乳腺癌病理图像进行自动分类,既加快了训练速度不需要重新训练初始化权重又避免训练图像样本量少而出现深度学习模型过拟合。Hameed等[5]提出一种集成深度学习方法来对癌类和非癌类的乳腺癌组织病理学图像进行分类,其采用经过预训练微调的VGG16和VGG19网络模型的集合预测概率的平均值来提升单模型分类的性能指标。于凌涛等[6]采用基于Inceptionv3架构的卷积神经网络和图像分块化思想对乳腺癌病理图像数据集良恶性分类。Sharma等[7]对比分析了基于手工制作的颜色、纹理等特征与基于预训练网络作为特征提取器分别来训练传统分类器支持向量机的乳腺癌组织病理学图像分类性能,表明使用预训练网络作为特征提取器表现出更好的性能。Yurttakal等[8]采用梯度提升和深度学习的堆叠集成模型诊断乳腺癌肿瘤,结果表明集成模型优于一些单一的机器学习方法。由于数据集训练样本数量少以及癌细胞的粘连性和颜色分布不均匀等问题,现阶段研究大多是乳腺癌良恶性二元分类,对良恶性子类分类研究较少,为了进一步满足临床应用的需求,Han等[9]提出了一种结构化深度卷积神经网络模型,对类内和类间分层特征空间自动学习低级到高级的语义特征和判别性分层特征,用于对相似度高的不同类别精准化多分类,实验表明模型多分类精度较高且具有一定稳定性。利用卷积神经网络可以提取出不同类别病理图像的局部细节特征和全局结构特征,但对提取的特征进行分析训练分类器进而准确的进行图像分类也是重中之重。
现有的关于乳腺癌病理图像分析的模型大多基于单一的模型和集成学习[10]模型,单一分类器模型分类精确率不高,集成分类器模型也存在着模型复杂、参数量多导致的计算量大和训练时间过长的问题。本文构建了联合训练的分类器的乳腺癌病理图像分析模型,通过贝叶斯优化对几种分类器共同训练寻找最优超参数以提升分类器模型的准确率,来辅助医生进行诊断。在提高医生的工作效率的同时减少因经验不足而导致的误诊或漏诊病例的现象。
1 方法与原理
1.1 卷积神经网络
卷积神经网络(CNN,convolutional neural network)的研究始于20世纪80至90年代,到21世纪后,随着深度学习理论的提出、数值计算设备的改进以及各种标准的数据集的出现,卷积神经网络得到了快速发展,一些卷积神经网络的经典模型层出不穷,比如VGG[11]、ResNet、DenseNet[12]等。
在乳腺癌组织病理学图像中,不管是轮廓、边缘、纹理等局部细节更丰富的低层特征,还是通过深层卷积网络得到的感受野更大的、全局信息更多的高层特征都包含很多的图像特征信息。在传统的卷积神经网络中,如果有L层,那么有L个连接,基于 DenseNet 的卷积神经网络将每一层所有的特征图进行通道拼接,然后作为输入传递给之后所有层,通过建立前面所有层与后面每一层的密集连接来实现特征重用,如果一个DenseNet网络有L层,那么其有L(L+1)/2个连接。这种连接方式不仅加强了特征的传递,缓解了深层网络梯度消失的问题,而且减少了参数量避免过拟合。这些特点让DenseNet在参数和计算成本更少的情形下比其他卷积神经网络实现更优的性能。因此本文采用DenseNet201预训练网络来提取乳腺癌图像卷积特征。如图1所示,DenseNet201模型包含4个稠密块,每个稠密块由多个1×1卷积层,3×3卷积层构成的块(block)组成。各个稠密块中block的数量分别为6,12,48,32。稠密块越多相对应通道数也增加,模型也更加复杂。所以稠密块后面是1×1卷积层和步幅为2的2×2平均池化层组成的过渡块,卷积层用来降低通道数,池化层进一步降低模型复杂度,最后一个稠密块后面没有过渡块。另外,通过迁移学习将在ImageNet数据集预训练好的模型参数在新的全连接层和输出层进行训练和微调,加快训练速度。
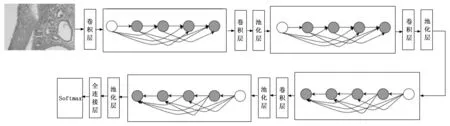
图1 包含4个稠密块的DenseNet201结构图
1.2 分类器
分类器[13]是一种机器学习技术,它可以用来将输入数据分类到不同的类别中。它的基本原理是,通过学习训练数据,构建一个模型,用于将新的输入数据分类到正确的类别中。分类器可以用于许多不同的应用,包括文本分类、图像分类、语音识别等。分类器首先从训练数据中提取特征,然后,使用这些特征构建一个模型,用于将新的输入数据分类到正确的类别中。分类器可以使用不同的算法,比如支持向量机[14]、K最邻近法[15]、决策树、朴素贝叶斯[16]等。这些算法都有自己的优点和缺点,因此,在使用分类器时,需要根据实际情况选择合适的算法。分类器主要目标是尽可能地逼近真正的分类模型,有效地提取输入数据的特征,并且减少参数的数量来降低模型的复杂度,提高模型的泛化能力和可解释性。
1.2.1 支持向量机
支持向量机(SVM,support vector machine)是一个机器学习的过程,一般来讲,它是一种二分类模型,其基本模型定义为使特征空间间隔最大的线性分类器,它的学习策略是通过在高维空间中寻找一个最大间隔分类超平面,将不同类别的数据样本点分开而使不同类别的点之间的间隔最大,将目标函数优化问题最终转化为一个凸二次规划问题的求解。由于现实问题中样本并不总是线性可分的,因此引入核函数的思想,将样本从原始空间映射到一个更高维的特征空间,找到合适的超平面,并通过序列最小优化算法求解。SVM模型分类性能的好坏很大程度上取决于模型参数的选择,SVM中核函数参数g和惩罚因子C是决定SVM性能的重要参数。
1.2.2 其他分类器
K最邻近法(KNN,k-nearest neighbor)是一种基于距离的分类方法,待求数据样本的类别是根据特征空间中最邻近的k个数据样本的类别来决定的。它的基本原理是,首先按照新样本数据特征与训练样本特征的距离进行排序,然后根据与其最邻近的k个样本类别所属最多来判定新样本的类别。如果这k个样本大多数属于某一个类别,则该样本也属于这个类别以及具有这个类别上样本的特性,否则再按照某种判别规则确定新样本类别。
决策树(DT,decision tree)通过构建一种树形结构来描述一系列的决策过程,根据决策过程将样本进行分类。它的每个内节点表示一个属性特征,每个叶节点代表一个类别输出,我们希望根据最少的内节点可以将所有样本尽可能划分到同一类别中即叶子节点上,也就是说最重要一点是选择最优的划分特征。决策树模型训练复杂度低但不够稳定,训练数据轻微变化可能导致节点选择不同,通过一定剪枝策略来避免数据的过拟合。
朴素贝叶斯(NB,naive bayesian)是一种基于贝叶斯定理与特征条件独立假设的分类方法,它用后验概率来判断样本类别,朴素贝叶斯模型假设特征之间相互独立,首先根据已知分类的训练样本集计算在各类别下各个特征属性的条件概率估计,然后根据贝叶斯定理和各个类别、特征的概率来判断样本最大概率的类别。朴素贝叶斯模型可以处理多类别问题而且泛化能力也较强,在特征独立假设的前提下与其他分类方法相比具有最小的误差率。
集成学习通过将多个相同分类器或多个分类性能不同的简单分类器组合在一起对应同一样本数据的判断结果来达到学习的目的。它不要求每个学习器性能最好,但多个学习器博采众长来选择分类最优结果,其预测精度和稳定性相比较于单一分类器大部分都提到了提升,但本质上没有改变单个分类器分类准确率,是通过一定的组合策略来提高分类器准确率。随机森林就是一种以决策树作为基预测器的集成学习方法。
1.2.3 贝叶斯优化
贝叶斯优化[17](BO,bayesian optimisation)是一种利用先验知识逼近未知目标函数的后验分布从而调节超参数的超参数优化算法。其通过高斯过程建立目标函数的概率模型,并用它来选择最优的超参数来评估真实的目标函数。我们的目标并不是使用尽可能多的数据点完全推断未知的目标函数,而是希望能选取获得最优性能的超参数,即求得最大化目标函数的超参数,因此超参数选择就可以看作为一种最优化问题。根据目标函数的初始候选解集合找到下一个最佳观测点,该点具有高均值或高方差来避免陷入局部最优,并将该点加入集合中,重复这一步骤,直至迭代终止,从而最快找到全局最优解。网格搜索通过穷举模型所有超参数组合来寻找最优超参数,当模型超参数多时优化速度慢且针对非凸问题容易陷入局部最优。随机搜索通过随机探索超参数空间的值,但它求解过程中没有利用之前已搜索点的信息,因此贝叶斯优化比网格搜索和随机搜索更为有效。
单个分类器都可进行超参数优化来寻找模型性能最佳的超参数,进而减少模型损失提高分类精度。本文使用贝叶斯优化的支持向量机(BO-SVM)来进行对比。采用径向基核函数训练SVM分类器,并通过使用贝叶斯超参数优化SVM中核函数参数g和惩罚因子C,找到最小化五折交叉验证损失的超参数。
径向基核函数:
(1)
加入惩罚因子C后,支持向量机优化的目标函数和约束条件:
(2)
1.2.4 联合训练的分类器
现有的关于乳腺癌病理图像分析的模型大多基于单一分类器模型和集成分类器模型。单一分类器优化是对自身超参数寻找最优结果,当单个分类器无法很好地学习样本时,模型的泛化能力会受到影响,分类器在测试集上的表现也会变差。为了提高模型的准确率,可以使用集成分类器模型,它通过为每种分类器找到最佳超参数,并通过集成学习策略构建集成分类器来增强泛化能力。总体来说,集成分类器模型是在结合的多个单分类器模型优化结果中寻找最优结果,其泛化能力是远大于单个分类器的泛化能力的,但它并不改变单分类器分类准确率。而且随着基分类器个数的增加模型复杂度变高,训练时间也会变长。
本文针对这些问题提出一种联合训练的分类器,不是根据超参数优化迭代结果直接优化单一分类器,而是先联合多个分类器SVM、KNN、决策树、随机森林和朴素贝叶斯对超参数观测感知域进行扩大以便有损失更小的估计点,再根据估计点来迭代优化超参数进而联合训练出拟合性能较好的分类器。这既汲取不同分类器模型的可取之处来增强泛化能力又加大了模型观测域,在避免陷入局部最优的同时提升分类准确率。图2为寻找观测最小值与估计最小值的优化过程,根据最小观测值找到损失最小的估计点方向,下一轮迭代继续朝这个方向寻找最小估计点,如果使损失降低,根据找到的估计点更新拟合函数,如果到某一个值优化梯度成负方向则到达局部最优,通过增加随机数扰动跳出局部最优找到下一个梯度变正的点,直到迭代结束。那么损失最小的观测点和估计点也就找到了。表1为高斯拟合目标函数迭代步骤。

表1 高斯过程拟合目标函数步骤
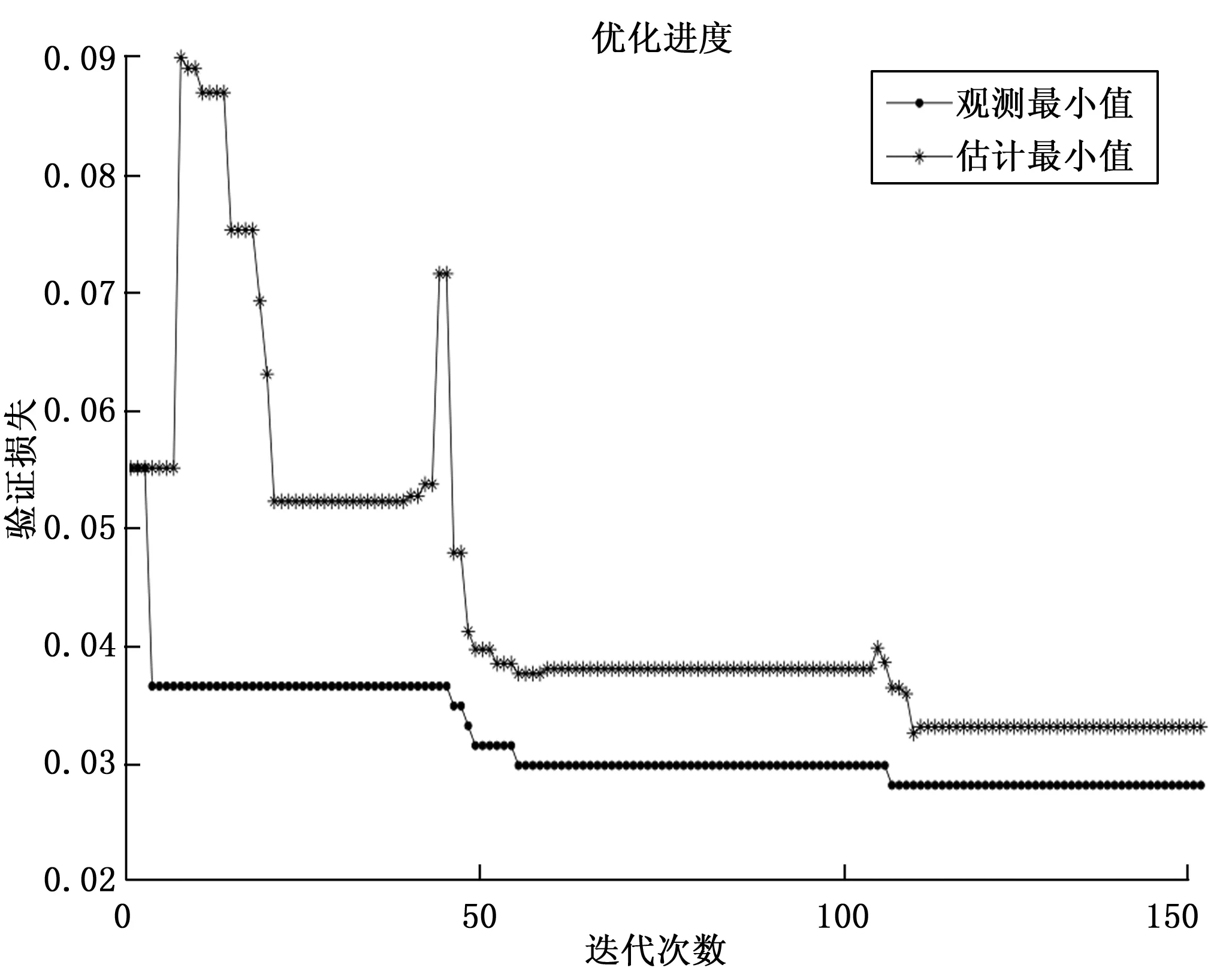
图2 寻找观测值与估计值的优化过程
表2为某一组数据联合训练的分类器迭代优化过程。由表可得出,迭代次数为13,KNN模型为最佳观测分类器,其超参数Num Neighbors为7;迭代次数为61,KNN模型为最佳估计分类器即返回的模型为KNN模型,其超参数Num Neighbors为16。
2 实验结果与分析
2.1 数据集
2016年,Spanhol等人[18]发布了BreakHis乳腺癌组织病理图像公开数据集。该数据集包含了来自82位患者的7 909幅乳腺癌良恶性组织病理图像,其中良性2 480例,恶性5 429例。本文根据不同放大倍数40×、100×、200×、400×分为4组数据,针对每组数据,随机将图像的70%作为训练集,图像的30%作为测试集,具体分布情况如表3所示。
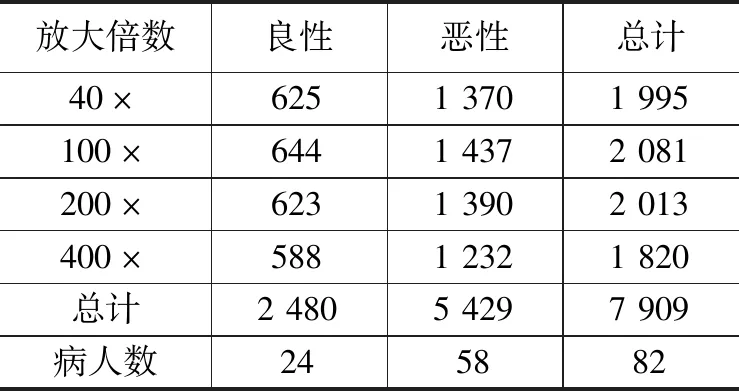
表3 按放大倍数的良恶性分类图片数目
良性和恶性乳腺肿瘤又各包括4种子类,良性子类包括腺病(A)、纤维腺瘤(F)、叶状肿瘤(PT)、管状腺瘤(TA);恶性子类包括导管癌(DC)、小叶癌(LC)、粘液癌(MC)、乳头状癌(PC)。
2.2 评价指标
本文主要的评价指标是图像级准确率,令Nrec_I为分类正确的图片数量,N为测试集样本的数量,则图像级准确率定义为:
(3)
为了更直观的反映真实的良恶性样本与预测的良恶性样本的差异,进一步评估本文方法的乳腺癌图像识别性能,本文采用混淆矩阵来对分类结果进行分析,以及敏感性,特异性,精确率和F1_score四种评价指标。敏感性表示在所有恶性样本中恶性样本被诊断正确的概率,特异性表示在所有良性样本中良性样本被诊断正确的概率,精确率表示被诊断为恶性的样本中诊断正确的概率,F1_score是敏感性和精确率的调和平均数,来平衡两者使其同时达到最高。
2.3 结果比较
根据单一分类器与本文所提出的联合训练的分类器的比较,实验结果如表4所示。可以看出无论是对单一分类器SVM,还是对超参数优化后的BO-SVM,联合训练的分类器对不同放大倍数的图像分类准确率都得到了提升,在40×、100×、200×、400×下得到的准确率分别为99.67%、98.08%、99.01%、96.34%。结果表明本文提出的联合训练的分类器一定程度上能有效提高乳腺癌病理图像识别准确率。
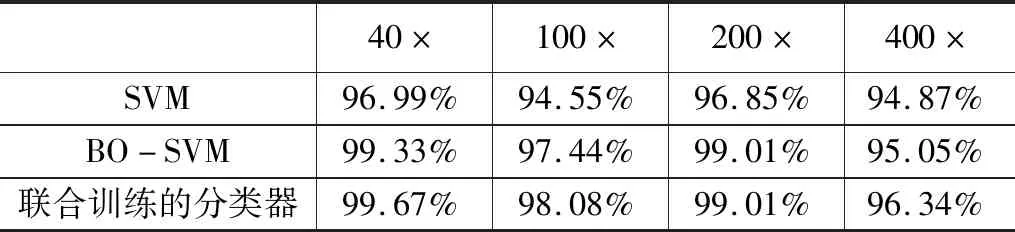
表4 图像层面的准确率
图3为不同放大倍数下的混淆矩阵。横坐标表示样本的预测标签,纵坐标表示样本的真实标签。从图3可以看出,良性样本被误判为恶性样本的数量并不多,反而400倍数恶性样本被误判为良性样本的数量比较多,说明样本不均衡对该模型二分类的影响并不大。但是由于400倍数图像放大倍数过大,图像中包含更多精确的病灶位置局部信息,缺少了全局信息,导致识别准确率较低。
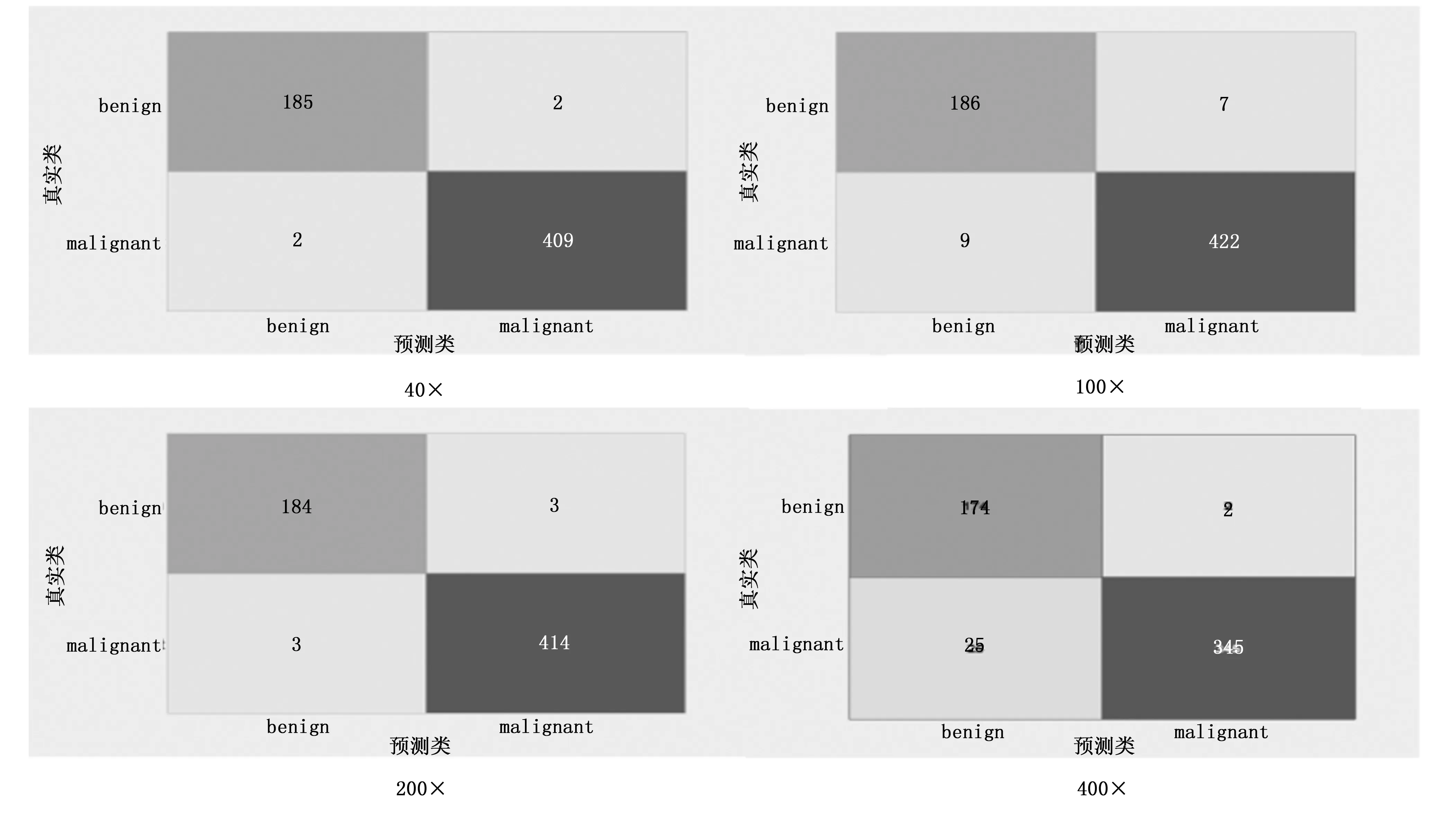
图3 二分类不同放大倍数的混淆矩阵
乳腺癌组织病理图像良恶性分类是为了更好的帮助病理学家来对患者进行检测。将良性误分类为恶性可能会花费一定时间来重新检测,而将恶性误分类为良性则可能导致患者错失最佳治疗时间。则敏感性越高,可以越快让病人得到及时治疗,表5中4种放大倍数的敏感性分别为99.51%,97.91%,99.28%,93.24%,很大程度上避免了乳腺癌恶性被漏诊的情况。F1_score分别为99.22%,97.16%,98.84%,95.94%,也说明了恶性样本在不漏诊的同时也有较高的精确率。
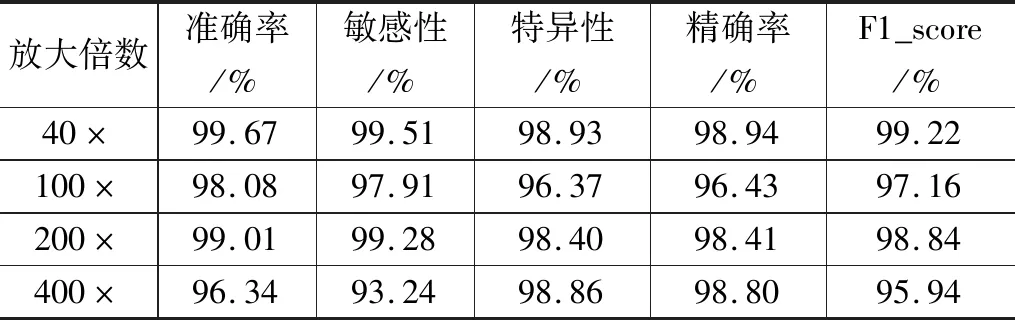
表5 不同放大倍数下的良恶性识别结果
表6为与文献中几种方法的比较,文献[19-21]以Protocol原则划分数据集,文献[21-22]以图像为单位划分数据集,所用数据集和数据集划分比例均与本文一致,其中训练集70%,测试集30%。对比图像级准确率可以看出,在40×和200×的放大倍数上,本文方法的识别准确率均高于文献中方法的识别准确率。在100×和400×放大倍数上,文献[21]的识别准确率略高于本文方法,而其他文献的识别准确率均比本文的较低。可以看出相较于文献中提出的方法,本文方法在乳腺癌组织病理学图像识别问题中是有效的,但依然有提升的空间。
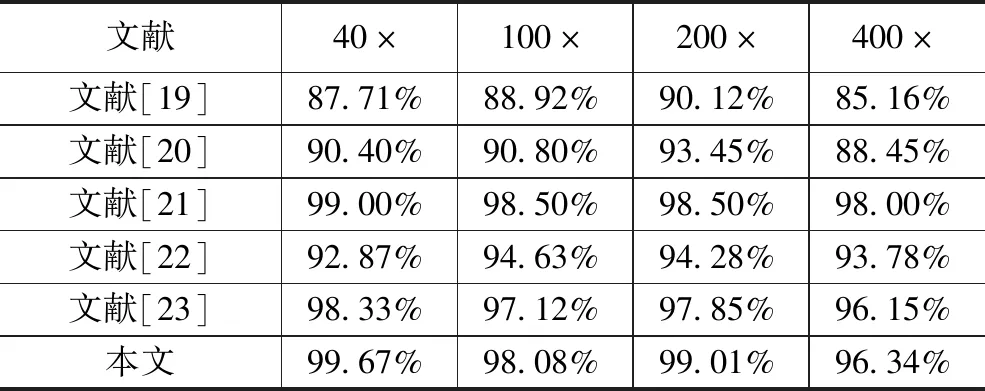
表6 与其他方法的图像级准确率对比
为了更好的评估实验结果,我们又对不同的子类准确率进行了比较,图4是其对应的混淆矩阵。A表示腺病,F表示纤维腺瘤,PT表示叶状肿瘤,TA表示管状腺瘤,DC表示导管癌,LC表示小叶癌,MC表示粘液癌,PC表示乳头状癌。可以看出,由于导管癌的样本数量远远超过其他子类,样本严重不均衡导致识别结果偏向于样本多的类,子类图像的准确率还有待提升。

图4 八分类不同放大倍数的混淆矩阵
3 结束语
本文针对单一分类器超参数观测域小提出了一种联合训练的分类器。通过联合几种分类器扩大其观测域来迭代优化超参数进而联合训练出拟合性能较好的分类器。在BreakHis数据集的实验结果表明提出的联合训练的分类器可以有效提高乳腺癌病理图像识别准确率。对不平衡样本数据的问题未来可以通过数据扩充与增强方法进一步提高不同放大倍数的图像及子类的识别准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
