
基于结巴分词的领域自适应分词方法研究
2023-06-01 13:43:26邢玲,程兵
计算机仿真 2023年4期
邢 玲,程 兵
(1. 中国科学院数学与系统科学研究院,北京 100190;2. 中国科学院大学,北京 10049)
1 引言
分词作为文本数据处理的前期工作,对后续任务结果的好坏起着至关重要的作用。中文文本相比英文文本要复杂,英文文本中单词和单词之间有空格作为分隔符,而中文文本中最小可分割单位为句子,句子是由字序列组成,但是单个字不代表一个词语,因此将字序列切分为词语即分词,是一个值得研究的问题。中文分词算法主要分为三种,分别是基于词典的分词算法、基于统计的分词算法和基于语义理解的分词算法。
基于词典的分词算法,在分词前给定词典,通过将待分词文本与词典进行匹配,根据规定的匹配算法得到词序列。按照扫描文本的顺序,常用的匹配算法有正向最大匹配算法,逆向最大匹配算法,双向最大匹配算法。另外,词典的结构设计影响着匹配效率,常见的词典结构设计基于整词二分[1]、基于Trie索引树[1]、基于逐字二分[1]、基于双字哈希机制[2]以及它们的改进形式[3,4]。由于直接和词典中词进行匹配,基于词典的分词算法准确率较高。然而词典无法穷尽所有词语,比如新词“新冠病毒”不在词典中,这意味着词典是不完备的。将不在词典中的词称为未登录词,包括人名、地名、机构名称、缩略词、领域词语、新词。未登录词较多的情况下,基于词典分词算法的准确率会随之下降。
基于统计的分词算法,分为有监督分词方法和无监督分词方法。有监督分词方法主要是基于字标注的机器学习算法,该方法将对字序列进行分词转化为对字序列进行位置标注问题。汉字的边界位置标注方法包括2位标记、4位标记等[5]。通常利用4位标记进行研究,B表示开始位置、M表示中间位置、E表示结束位置及S表示单字构词[5]。利用人工标注语料集学习模型参数,将学习好的模型对字序列文本进行预测,得到字位置标注。常见的用于分词的机器学习模型有隐马尔科夫模型(HMM)[6]、最大熵模型(ME)[7]、条件随机场模型(CRF)[8]。该方法可以较好的解决未登录词问题,但是需要大规模人工标注语料作为训练数据。无监督分词方法利用字串在未标注语料中的统计信息构建良度[9],经典的良度标准有子串频率[10]、描述长度增益[10]、邻接多样性[10]和分支信息熵[10]。该方法不需要对语料库进行人工标注,但是仅仅依赖于无监督分词方法进行分词,得到的准确率通常较低。
基于语义理解的分词方法,结合待切分文本的语义信息,模仿人的阅读理解方式进行分词。深度学习算法考虑了上下文信息,可以更好的理解语义,因此CNN[11]、LSTM[12]等被引入到分词任务中。词向量模型将词表示为向量,将词语数学化,可以更好表示词语语义,因此词向量模型如Word2Vec[13]、Glove[14]以及近几年提出的动态词向量训练模型如Elmo[15]、Bert[16]等被应用到分词任务中。但是这些算法比较复杂,对计算机要求较高。现在基于语义理解的分词算法还不是很成熟,有待发展。
以上三种分词方法并不是割裂的,将它们进行整合,可以提高分词准确率。结巴分词是将词典分词和统计分词方法结合起来的分词工具。结巴分词基于一个具有将近35万个词的词典,为了实现高效查找词语,构建前缀树存储这些词语,对于待分词文本,根据前缀树,构建有向无环图,利用动态规划算法,找到路径最短的切分方式。对于不在词典中的词语,利用统计分词方法中的HMM算法,对这些词语进行字序列位置标注,根据标注结果进行分词。这样一方面基于词典可以进行有效分词,另一方面对未登录词也可以进行识别切分。但是,对于未登录词分词后得到的词语大部分词长为2,对于人名,地名,机构组织,专业领域词语等词长大于2的词语分词效果不是很好。比如对于金融领域“羊群效应”这个领域词组,结巴分词结果为“羊群”和“效应”这两个词,这是不合理的。
将“羊群效应”作为一个词进行切分称为领域分词。领域分词是指将领域中的专有领域词组作为整体切分出来,通常的分词算法将一个领域词组切分为几个词,这是不规范的,甚至会导致理解偏差。已知,领域词组通常只是出现在所在领域,属于低频词,因此领域分词是一个具有挑战但是重要的研究领域。
张梅山等[17]通过将词典信息以特征方式融入到统计分词模型来实现领域自适应性。该方法依赖于领域词典信息,严格来说没有完全实现领域自适应分词。韩冬煦等[18]将卡方统计量特征和边界熵特征加入到训练模型中,并结合自学习和协同学习策略进行训练,改善了分词方法领域适应性。该方法本质上将无监督统计分词方法与有监督统计分词方法结合起来,对于不同领域需要重新训练模型,比较耗费时间。张立邦等[9]首先利用通用词典对语料进行初步切分,利用EM算法不断更新切分结果,直到切分结果不再变化。然后利用左右分支信息熵构建良度,对切分结果进行调整,从而到达识别电子病历中未登录词的目的。该方法本质上是将词典分词方法与无监督统计分词方法结合起来,在对切分结果利用无监督方法调整时,针对电子病历特征定义了相应规则,对于其它领域分词不具有适用性。杜丽萍等[19]利用改进的互信息算法与少量基本规则结合,从语料中发现新词,将新词加载到汉语词法分析系统ICTCLAS中,从而改善汉语词法分析系统ICTCLAS。该方法在发现新词过程中,只是考虑了词的凝聚度,没有考虑词的自由度。冯国明等[20]将词典、统计、深度学习三者结合起来,学习分词算法。该方法没有考虑词典存储结构问题,同时利用深度学习算法,模型计算复杂度较高。宫法明等[21]以自适应马尔科夫模型为基础,结合领域词典和互信息,以语义和词义约束校准分词,实现对石油领域专业术语和组合词的精确识别。该方法需要提前构建石油领域词典,不能用于其它领域分词,领域迁移性较差。
针对以上问题,本文在结巴分词基础上,提出领域自适应分词方法。由于结巴分词对词长大于2的领域词组分词效果较差,本文提出的领域自适应分词方法主要利用无监督分词方法识别词长大于2的领域词组,从而使得结巴分词无需加载人工定义词典,可以实现领域自适应分词。该方法首先利用结巴分词方法对文本进行分词;其次基于标准化点互信息[22]和词频统计[23]两种方式计算相邻词合成为一个词组的凝聚度,设定凝聚度阈值,选择符合条件的词组;接着利用左右信息熵[24]计算选出词组的自由度,设定自由度阈值,选择符合条件词组;最后利用本文提出的词性约束规则去掉不符合构词规则的词组,尽可能得到正确的领域词组。将得到的领域词组作为结巴分词中自定义词典加入到结巴词库中,再次利用结巴分词对文本进行分词,实现领域自适应分词。本文接下来安排如下:第二节介绍相关知识;第三节介绍本文提出的领域自适应分词方法;第四节介绍实验部分;第五节介绍基于区分领域的领域自适应分词评价方法;第六节是结论。
2 相关知识
2.1 词组凝聚度的计算
给定两个词语,它们组成一个词组的可能性越大,称它们凝聚度越大。本文用两个分数公式来计算词语之间的凝聚度。
第一个分数公式基于标准化点互信息[22]给出。分数公式如下
Score1(w_a,w_b)=
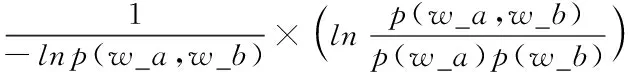
(1)
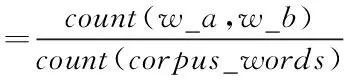
第二个分数公式基于词语出现频数以及共现词语频数来定义的[23],公式如下
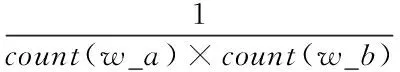
×(count(w_a,w_b)-mincount)
×count(vocab_words)
(2)
其中,count(w_a)表示词语a在语料中出现的次数;count(w_b)表示词语b在语料中出现的次数;count(w_a,w_b)表示词语a与词语b共现的次数;count(vocab_words)表示语料库去掉重复词后的词语个数;mincount表示设定的两个词语共现次数的阈值,当两个词语共现次数小于这个值时,则舍去由这两个词组成的词组,被用来作为减少出现偶见词组的可能。该分数的取值范围大于0。
设定凝聚度阈值,如果组合词组凝聚度分数大于阈值,则选出该词组,否则,舍弃该词组。计算得到的词组分数值越大,说明词语a与词语b组成词组的凝聚度越大,该词组越有可能被当作领域词组识别出来。
2.2 词组自由度的计算
考虑两个词语是否可以构成一个词组,一方面考虑它们的凝聚度,即这两个词语组合成一个词组的黏合性,这个度量可以利用2.1中式(1)或者式(2)来定义;另一方面需要考虑所构成词组的自由度,即该词组左右出现的紧邻字是否具有多样性。通常来说,一个词语的上下文是不固定的,可以和多种字结合。本文用左右信息熵[24]来度量词组的自由度。左右信息熵的公式如下:
左熵:
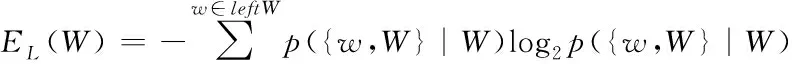
(3)
右熵:
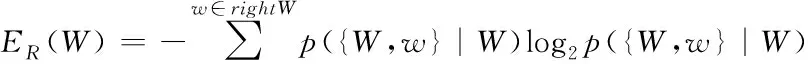
(4)
其中,W表示一个词组;leftW表示W左边所有紧邻字的集合;rightW表示W右边所有紧邻字的集合;p({w,W}|W)表示字w紧邻词组W左边的概率,通过统计词频来计算,等于字w紧邻词组W左边的频数与W左边所有紧邻字的频数之和的比值;
p( {W,w}|W)表示字w紧邻词组W右边的概率,等于字w紧邻词组W右边的频数与W右边所有紧邻字的频数之和的比值。
取min(EL(W),ER(W))作为词组W的自由度,用来和设定的自由度阈值比较,如果大于阈值则说明词组W的左右紧邻字比较多样,W可以看作一个词组,否则W不能作为一个词组。自由度越大,该词组被识别出来的可能性越大。
2.3 词性搭配规则
由凝聚度和自由度两个统计度量识别领域词组的同时,也会引入一些严格意义上不是领域词组的组合。比如由词语“上”和词语“显著”组成的词组“上显著”,该词组的凝聚度分数和自由度分数大于所设置的凝聚度阈值和自由度阈值,因此词组“上显著”会被当作领域词组识别出来,显然,这是不合理的词组组合。根据短语结构类型[25]提出了针对结巴分词中词长大于2的未登录词的词性搭配规则,实现了对词组的约束,从而尽可能筛选出标准词组。本文中的词性是按照北大词性标注集来定义的。本文提出的词组词性搭配规则如附录1所示。
3 领域自适应分词方法
3.1 领域词组识别
在结巴分词的前提下,首先利用凝聚度公式计算结巴分词后相邻词语组成词组的凝聚度,通过凝聚度阈值选出词组候选词;其次利用自由度公式对候选词组计算其自由度,根据自由度阈值再次选出候选词组;最后根据本文规定的词组词性搭配规则,从候选词组中选出领域词组。凝聚度和自由度用来确定可能是固定搭配的词组,词性约束进一步过滤掉不规范词组,从而得到规范的领域词组。领域词组识别流程如图1所示。

图1 领域词组识别流
3.2 领域自适应分词方法
将利用凝聚度、自由度、词性约束得到的领域词组作为结巴分词自定义词典参与分词,从而实现领域自适应分词。算法流程如图2所示。
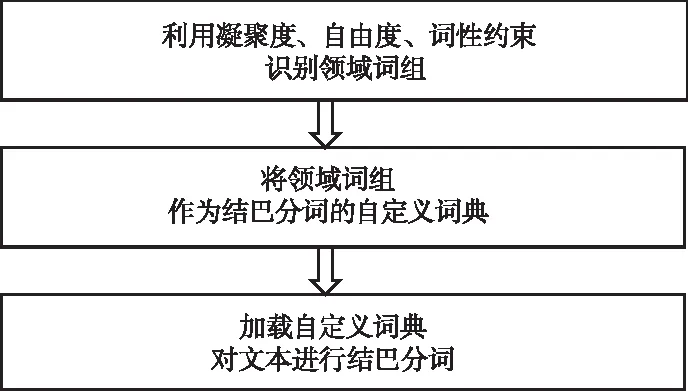
图2 领域自适应分词算法流程
4 实验及结果分析
4.1 数据介绍
本文中用到的数据来自中国知网,下载金融领域的100篇论文,这些论文主要集中于投资和证券学科;法律领域的100篇论文,这些论文主要集中于诉讼法与司法制度学科。将每篇PDF文献转化为txt格式,利用正则表达式对txt格式文献进行处理,得到只含有标点符号,英文字母,数字,中文的文档,然后将相同领域的文档整合为一个文档集。将该文档集以标点符号为分隔符进行切分,得到以行为单位的金融和法律领域文档集。
4.2 参数设置
当按照标准化点互信息(NPMI)即式(1)计算词组凝聚度时,分数取值范围为[-1,1],当分数阈值取-1时,没有起到任何筛选作用;分数阈值取1时,阈值太大,导致筛选词组个数为0。因此选取3个具有代表性阈值,阈值分别取-0.5,0,0.5;当按照词频统计方法即式(2)计算词组凝聚度分数时,由于文献[23]阈值默认值为10,因此本文阈值分别取5, 10, 15。利用左右信息熵计算自由度,当阈值取0.1时,得到词组个数同阈值取0.5时相差不大。当阈值取1.5时,得到的词组个数同阈值取1时相差不大。当阈值取2.5时,词组个数同阈值取2时相差不大,且此时词组个数不是很多,因此自由度阈值分别取0.5, 1, 2。
4.3 领域分词评价方法
本文利用自己构建的金融与法律领域文本对领域分词进行研究,没有现有的领域分词评价标准可以利用。由于本文是将领域自适应分词方法同结巴分词的领域分词结果进行比较,基于此前提,重新定义评价方法精确率与召回率计算公式,如式(5)与(6)所示。
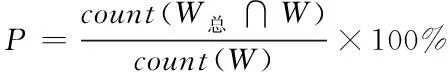
(5)
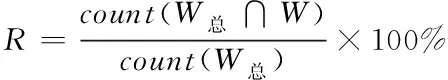
(6)
其中,count(W总)表示领域词组标准库中词数;W表示对文本进行领域分词的结果;count(W总∩W)表示领域分词结果中属于领域词组标准库中词的个数。以下给出W总与W的计算方式。
领域词组标准库W总计算:将利用式(1)计算凝聚度(凝聚度阈值取-0.5,自由度阈值取0.1)与利用式(2)计算凝聚度(凝聚度阈值取0.001,自由度阈值取0.1)进行领域自适应分词的结果分别记为W11,W12;将直接利用结巴词库对相同领域文档集进行分词的结果记为W2。如果词语w∈{W11∪W12∪W2}且w∉{W11∩W12∩W2},则将w加入到词库中,通过人工查找词库中正确词组作为领域词组标准库,记为W总。具体流程图如图3所示。

图3 领域词组标准库构建流程图
领域分词结果W计算:领域自适应分词结果记为W1,直接利用结巴分词的结果记为W2,如果词语w∉{W1∩W2}且w∈W1,将w加入到Wdic,Wdic记为领域自适应分词算法下领域分词结果;如果词语w∉{W1∩W2}且w∈W2,则将w加入到W结巴,W结巴记为结巴分词下领域分词结果。具体流程图如图4所示:
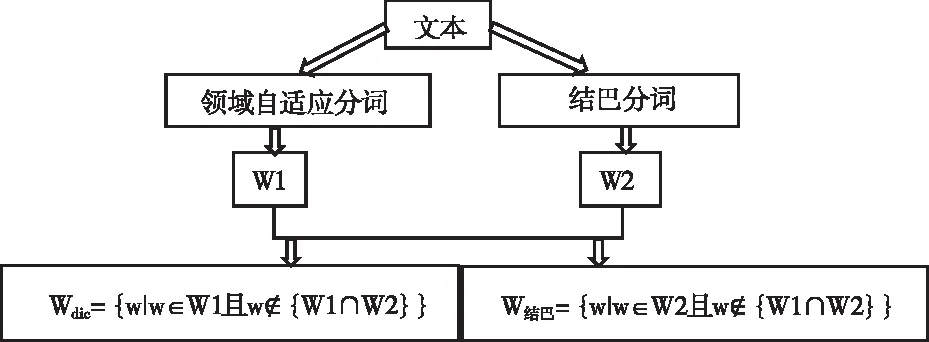
图4 领域分词结果获取流程图
4.4 实验结果及分析
将凝聚度与自由度不同阈值参数组合得到的领域词组作为自定义词典加入到结巴词库中,对相应领域文本实现领域自适应分词。将得到的领域分词结果同不加自定义词典分词后的领域分词结果进行比较。
实验结果:
根据定义的精确率与召回率的计算方法,列出领域自适应分词算法与直接用结巴分词算法进行领域分词的精确率及召回率。表1表示金融领域结果,表2表示法律领域结果。下表中,参数第一列表示凝聚度阈值,阈值参数为-0.5,0,0.5表示利用式(1)计算凝聚度,阈值参数为5,10,15表示利用式(2)计算凝聚度。第二列表示自由度阈值;加词典表示领域自适应分词,不加词典表示直接利用结巴分词;正确词数表示领域分词结果中属于领域词组标准库中词的个数。

表1 金融领域自适应分词与结巴分词对于领域分词的精确率、召回率
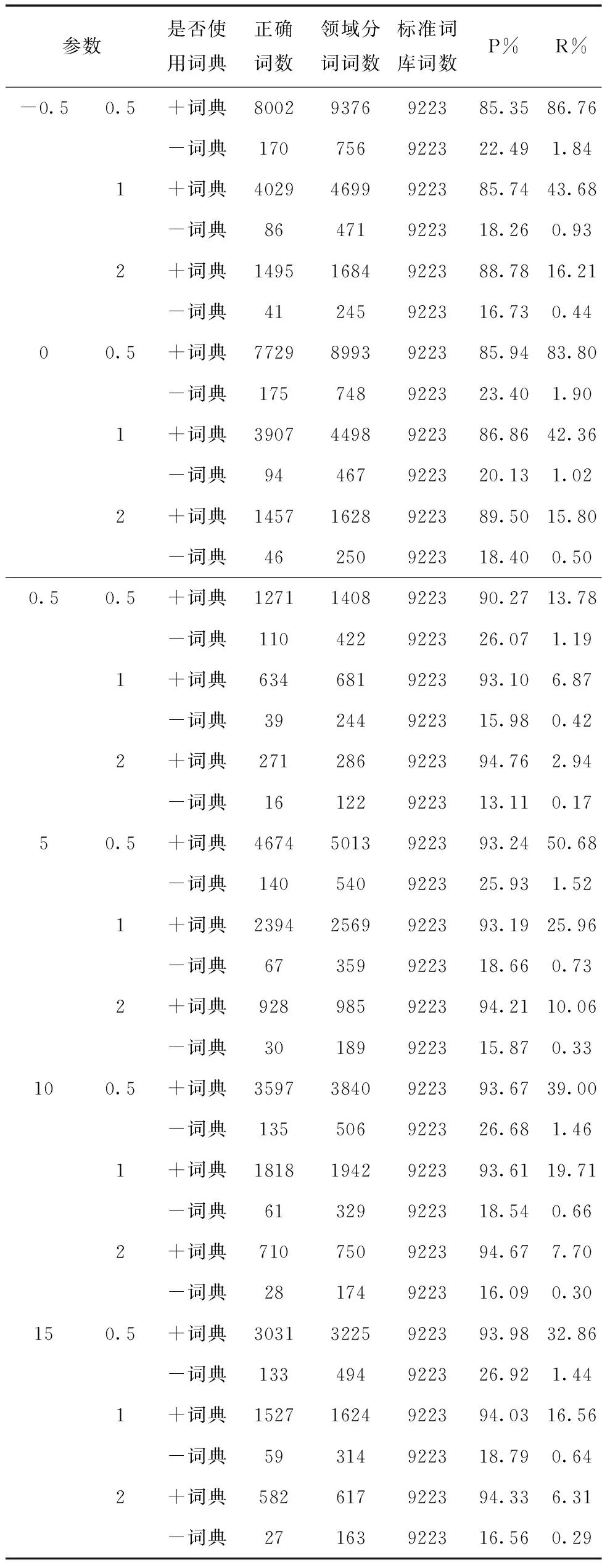
表2 法律领域自适应分词与结巴分词对于领域分词的精确率、召回率
实验结果分析:
总体来看,结巴分词对于领域分词来说,准确率和召回率远远低于本文提出的领域自适应分词算法。
通过表1与表2中精确率和召回率可以看出,当凝聚度分数阈值不变时,随着自由度阈值越大,识别的领域词组越少,此时,领域自适应分词精确率越高,召回率越低;对于同一凝聚度计算公式来说,当自由度阈值不变时,凝聚度分数阈值越大,识别的领域词组越少,领域自适应分词精确率越高,召回率越低;基于NPMI即式(1)与词频统计即式(2)计算词组凝聚度,当最终识别词组个数相差不大时,利用式(2)识别领域词组得到的精确率与召回率均高于式(1),说明将NPMI与左右信息熵搭配,比词频统计与左右信息熵搭配识别领域词组的效果差。
通过表1与表2中正确词数可以看出,领域自适应分词算法切分出来的领域词组远远多于结巴分词切分出来的领域词组;通过领域分词词数可以看出,领域自适应分词得到总词数多于结巴分词总词数,这是因为领域自适应分词得到的词组长度一般大于2,重复词比较少;结巴分词分出来的词中大部分词长为2,重复词比较多,因此去重后剩余词数较少。
领域自适应分词由于加入了领域词组,从而调整了分词切分位置,可以将领域词组作为整体识别出来,相比于结巴分词,领域自适应分词算法提高了领域分词准确率与召回率。因此本文提出的领域自适应分词算法是有效的。
5 基于区分领域的领域自适应分词评价方法
为了从不同角度证明领域自适应分词算法的有效性,本文基于区分领域给出了领域自适应分词的评价方法。对于不同的两个领域,利用分词算法对文本进行分词后,度量这两个领域分词后文本的距离,如果距离越大,称该分词方法区分领域的效果越好,即该分词方法能够有效实现领域分词。基于此概念,本文提出了一种基于word2vec[23]的度量方法,用来对领域自适应分词算法区分领域的效果进行评价。
5.1 基于word2vec的度量方法
将利用领域自适应分词算法得到的金融领域分词结果记为W金融dic,法律领域分词结果记为W法律dic;将直接利用结巴分词得到金融领域分词结果记为W金融jieba,法律领域分词结果记为W法律jieba。利用word2vec求解词向量,在此基础上给出领域自适应分词方法区分领域效果的度量方法:距离差度量法。公式如下
difference=
distance(vector(W金融dic),vector(W法律dic))
-distance(vector(W金融jieba),vector(W法律jieba))
(7)
其中
distance(vector(W金融),vector(W法律))
vector(W金融)与vector(W法律)指金融领域文本与法律领域文本的向量表示,通过对相应领域文本分词后求解所有词语向量的平均值得到,即


式(7)表示利用领域自适应分词算法对金融和法律领域进行分词后,这两个领域文本距离与利用结巴分词算法对金融和法律领域分词后文本距离的差值。如果这个差值大于0,表示利用领域自适应分词算法分词后,区分领域的效果优于利用结巴分词。这个差值越大,说明领域自适应分词算法区分领域效果越好。
5.2 区分领域的效果分析
利用领域自适应分词算法分别对金融领域、法律领域文本分词,得到词典大小分别为292621、260845;直接利用结巴分词算法对金融领域、法律领域文本分词,得到词典大小分别为354325、316261。本文利用Word2vec中skip-gram模型[26]来训练词语向量,上下文窗口大小参数设置为5,向量维度设置为500维。利用5.1中定义的距离差度量法,有
difference=distance(vector(W金融dic),vector(W法律dic))-
distance(vector(W金融jieba),vector(W法律jieba))
=1.002-0.9852=0.0168
可以看出,利用领域自适应分词后区分领域的效果优于结巴分词区分领域的效果,说明领域自适应分词算法相比于结巴分词有效实现了领域分词。
6 结论
本文提出了一种领域自适应分词算法,在结巴分词的基础上,利用标准化点互信息及词频统计方法计算相邻词语组成词组的凝聚度,左右信息熵计算词组的自由度,词性约束筛选规范词组,将最后得到的领域词组作为自定义词典加入到结巴词库中参与分词,从而完善了结巴分词。通过在100篇金融领域文章和100篇法律领域文章上进行实验,说明该方法可以有效发现领域词组。利用精确率和召回率对领域分词结果进行评价,发现相比结巴分词,领域自适应分词算法提高了领域分词的准确率和召回率。最后提出了一种基于区分领域的领域自适应分词评价方法,利用word2vec获取词向量,通过定义距离差度量公式来进行评价,实验结果表明,领域自适应分词算法区分领域效果优于结巴分词,即该算法能够有效进行领域分词。
由于领域自适应分词算法是在结巴分词基础上识别领域词组,如果结巴分词切分错误,则导致得到的领域词组是错误的,因此在下一步工作中,可以考虑直接对文本识别领域词组,从而避免引进错误领域词组。该算法对结巴分词后相邻词语进行组合,对于单字与双字组合的词组识别结果不是很好,会将不规则词组别识别出来;对于双字词语组合,会出现结合顺序前后紊乱情况。在下一步工作中,可以通过其它约束方法来尽量规避这两种情况的发生。对于基于区分领域的评价方法,本文直接求解文本所有词向量平均值来表征文本,在下一步工作中,可以提出其它向量计算方式来表征文本,从而提高评价方法的精确度。
猜你喜欢
考试与评价·高二版(2021年1期)2021-09-10 14:44:53
智富时代(2019年6期)2019-07-24 10:33:16
高中生·天天向上(2016年9期)2016-11-22 09:10:34
学苑创造·B版(2016年8期)2016-07-02 06:34:30
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
海峡姐妹(2014年2期)2014-02-27 15:08:49
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
新作文·小学高年级版(2013年6期)2013-04-29 00:44:03
外语学刊(2011年3期)2011-01-22 03:42:20
