
一种高速可配置二维CFAR检测器设计实现
2023-05-30 06:10陶相颖张多利刘文娟宋宇鲲
合肥工业大学学报(自然科学版) 2023年5期
陶相颖, 张多利, 刘文娟, 倪 伟, 宋宇鲲
(1.合肥工业大学 微电子学院,安徽 合肥 230601; 2.教育部IC设计网上合作研究中心,安徽 合肥 230601)
0 引 言
雷达目标检测需要自适应处理,根据局部噪声功率自动调整检测门限,以保持恒虚警率(constant false alarm rate,CFAR),在复杂的杂波环境中检测出所关心的运动目标回波。单元平均(cell averaging,CA)CFAR处理算法作为最经典的CFAR算法[1],在均匀杂波背景下具有较好的检测性能,但在杂波边缘和多目标环境中的检测性能明显下降。因此,具有更好的多目标分辨能力的最小(smallest of,SO)选择检测器[2]和在杂波边缘具有良好性能的最大(greatest of,GO)选择检测器[3]相继被提出。不同于以上3种均值思想的CFAR算法,有序统计(ordered statistics,OS)CFAR算法通过对参考集排序,在非理想杂波环境中获得了更好的鲁棒性[4],在多目标情况下具有较高的分辨率。在一维CFAR算法的基础上,研究者们结合多普勒维雷达回波信息,提出了相应的多种二维CFAR算法[5-6]。
二维CFAR检测利用了信号和杂波的频域特性差异且增加了有效的参考单元数。相比一维CFAR处理,二维CFAR算法能有效降低虚警,提高检测性能[7],但同时带来了较大计算量。目前对二维CFAR算法实现,以DSP软件层面为主[8]。文献[9]提出一种基于DSP的二维十字窗CA-CFAR检测实现,以数据块矩阵操作代替CFAR检测的逐点实现提高时间效率。其对64×1 024点的距离-多普勒矩阵处理,在500 MHz时钟频率下仍需31.534 ms。面对高速的大规模雷达数据,现场可编程门阵列(field programmable gate array,FPGA)在实时性方面更具优势。
目前关于一维CFAR算法的FPGA实现已有大量的研究,而二维CFAR算法设计复杂度和计算量相对增大,FPGA实现较少,且大多通过调整窗口形状降低计算复杂度。文献[10]提出了支持CA、GO及SO算法的二维十字窗均值类CFAR实现结构;文献[11]提出了基于FPGA的二维米字型参考窗的FOSCA-CFAR实现方案。以上2种二维CFAR实现窗口大小固定,通过采用十字窗或米字窗减少参考单元数量,回避了矩形窗带来的巨大计算量,但是由于放弃大量有效信息,从而导致其杂波估计值的可靠性低于矩形窗[12]。
随着FPGA的发展,CFAR硬件实现不再需要以牺牲性能为代价来节省资源。近期,文献[13]提出了一种面向二维CFAR检测需求,目前实现复杂度最高且完善的先进方案。该方案采用矩形窗,实现了动态可配置二维CFAR处理器,兼容CA、GO、SO及OS算法且参考窗口尺寸和保护窗口尺寸可以动态配置,具有灵活的配置和较广的应用场景。但是其计算模块采用资源平铺的方法,资源消耗极大,同时关键路径较长导致主频受限。本文参考文献[13]的高可配置性优点,同时,通过链式先进先出(first input first output,FIFO)队列结构和滑动窗口处理降低资源消耗,求解参考单元累加和的计算量,充分利用数据集之间固有的数据依赖关系,使得硬件资源开销大幅降低,主频得到明显提升。
1 二维CFAR算法
上述研究者们关于二维CFAR算法的实现,多为固定参考窗口和保护窗口设计。然而,在实际雷达目标检测应用中,可通过参考窗口和保护窗口大小的调整,以优化检测性能。根据目标在二维空间的局部拓展性,二维矩形参考窗相较其他窗型CFAR能够获得更稳定且准确的背景杂波估计值[14]。因此本文以FPGA为实验平台,采用矩形窗型,设计实现了兼容CA、GO、SO、OS 4种经典CFAR算法且参考窗尺寸(N)、保护窗尺寸(M)可动态配置的二维CFAR算法硬件加速器结构,其中,3≤N≤31,1≤M≤21,N、M为奇数。本文采用链式FIFO队列结构和滑动窗口处理,实现了对既有计算结果的重复利用,即对于均值类CFAR的硬件实现减少了传统矩形窗口累加和求解所需加法器个数,对于OS-CFAR的硬件实现减少了数据反复读取带来的延迟,使用流水线设计实现每周期可以连续获得CFAR检测结果,具有较高的检测效率。在220 MHz的主频下,对于256×2 048点的距离-多普勒矩阵数据,4种CFAR检测器均在2.71 ms内完成。该二维CFAR检测器具有较大灵活性,提升了二维CFAR硬件实现的实时性和实用性。
本文关注算法的硬件实现结构,关于CFAR算法原理不作赘述。参考窗口尺寸为N×N大小的二维矩形窗CFAR算法如图1所示。
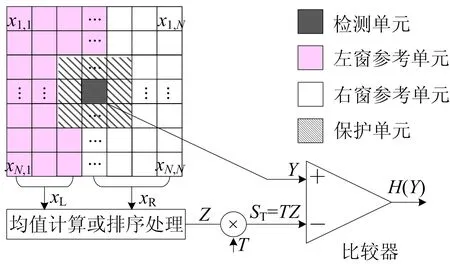
图1 二维矩形窗CFAR算法
矩形窗中心黑色单元为检测单元,记为Y。为防止目标能量泄露到背景单元中导致检测性能下降,通常在检测单元四周设置尺寸为M×M大小的区域作为保护单元,即图1中阴影区域。矩形窗内其余单元为参考单元,红色区域为左窗参考单元xL,白色区域为右窗参考单元xR。
为兼容CA、GO、SO 3种均值类CFAR算法,可通过计算出全部左窗参考单元均值ML、右窗参考单元均值MR,继而求得全窗均值。OS-CFAR算法需对所有参考单元升序排序,以获取第K个排序样本值XK作为背景杂波估计值。根据算法种类选择对应的杂波背景功率的估计值Z,与标称化因子T相乘得到检测门限ST。若待测单元幅值Y大于检测门限ST则判定该检测单元为目标,否则为杂波。CA、GO、SO、OS 4种CFAR算法关于Z的取值见表1所列。

表1 不同二维CFAR算法的Z值计算
2 硬件实现
2.1 系统结构
CFAR检测器以256×2 048点二维距离-多谱勒矩阵(Range Doppler Matrix,RDM)为输入数据。本设计整体结构如图2所示,主要由链式FIFO队列、滑动窗口求和处理模块、OS-CFAR流水比较模块、目标判定模块和检测单元预处理模块组成。链式FIFO队列负责数据的存储管理和RDM边缘扩展补充。滑动窗口求和处理模块每周期计算输出一个左窗累加和与对应右窗累加和。OS-CFAR流水比较模块采用二元积累法,每周期计算输出一个检测单元对应的二元积累和。目标判定模块则根据配置的算法类型选择对应的窗口累加和与经过预处理的参考单元幅值比较,得到最终的CFAR算法处理结果。
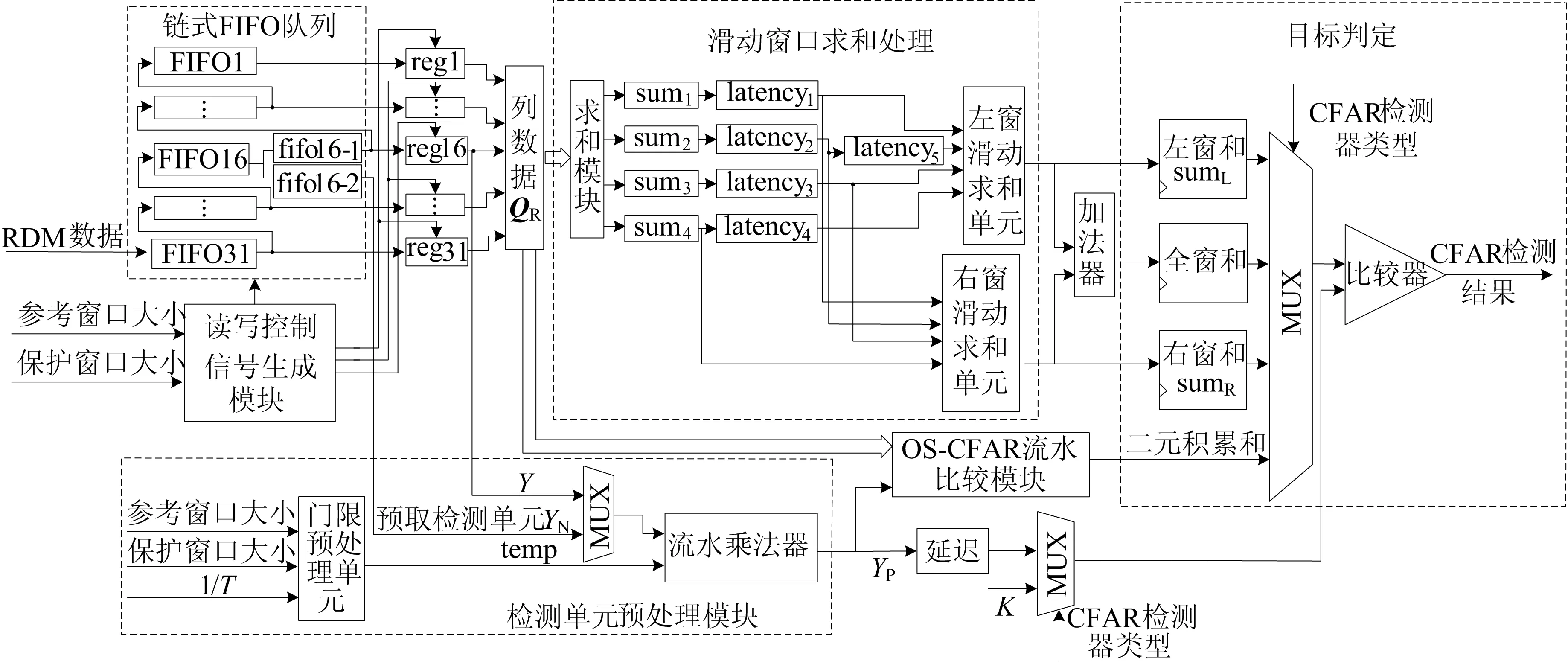
图2 兼容均值类和有序统计CAFR的硬件设计框图
2.2 链式FIFO队列
二维CFAR实现面临的首要问题是RDM输入数据每周期逐点更新,而滑动窗口计算需要每周期逐列更新。因此,本设计以31个256深度的FIFO首尾相连,构成链式FIFO队列,将串行输入数据转化为31个输出端口并行输出。实现每个时钟周期更新滑动窗口所需的包含N个数据的列向量QR,提高数据吞吐效率,为后续计算模块的全流水实现提供保障。巧妙设计FIFO深度为多普勒维采样点个数,使得链式FIFO队列只需在初始化时进行一次队列预存,无需在滑动窗口由各行行末移动到下一行行首时重新对FIFO队列缓存。即当本周期FIFO队列读出的QR为第i行最后一个参考窗口的第N个列向量时,下一个时钟周期FIFO队列读出的数据即为第i+1行中第1个参考窗口所需的第1个列向量。
链式FIFO队列的另一作用是实现对RDM的边缘补充且不增加额外缓存资源。由于检测单元位于RDM数据边缘时存在窗口内参考单元缺失的情况,本设计以复制补边的方式对RDM边缘参考窗内缺失数据加以补充。根据配置的参考窗口大小,通过对RDM首行和末行重复(N-1)/2次缓存到FIFO中,实现行数据补充。当FIFO组读出数据为首列或末列后,通过控制FIFO组读写能拉低(N-1)/2时钟周期,实现RDM列数据的边缘填充。
2.3 滑动窗口设计
不同于一维CFAR滑动窗口结构简单,二维矩形窗CFAR剔除保护窗口再被分为左窗和右窗后,窗口形状不规则,同时需要兼顾参考窗口和保护窗口尺寸可动态配置的设计目标,给滑动窗口设计带来一定难度。本设计对于每周期更新的一列数据,首先由链式FIFO队列后的31个寄存器根据参考窗口配置,将超过窗口的数据点置0,实现参考窗口尺寸的控制。每列数据QR在求和模块中根据保护窗口大小切割成:保护窗上方的各参考单元累加和sum1、保护窗范围内的各参考单元累加和sum2、保护窗下方的各参考单元累加和sum33个部分。由以上3个部分之和求得全列数据累加和sum4。
本文滑动窗口设计如图3所示,窗口向右滑动。根据窗口形状产生的数据组织规律,在滑动窗口求和模块求出当前检测单元对应的左窗参考单元累加和sumL后,对sumL加入沿左窗边缘右侧的参考单元幅值(图3中黄色部分),减去左窗最左侧一列参考单元幅值(图3中蓝色部分),即可实现左窗累加和的向右滑动。对于右窗累加和sumR的滑动求解方法同理。
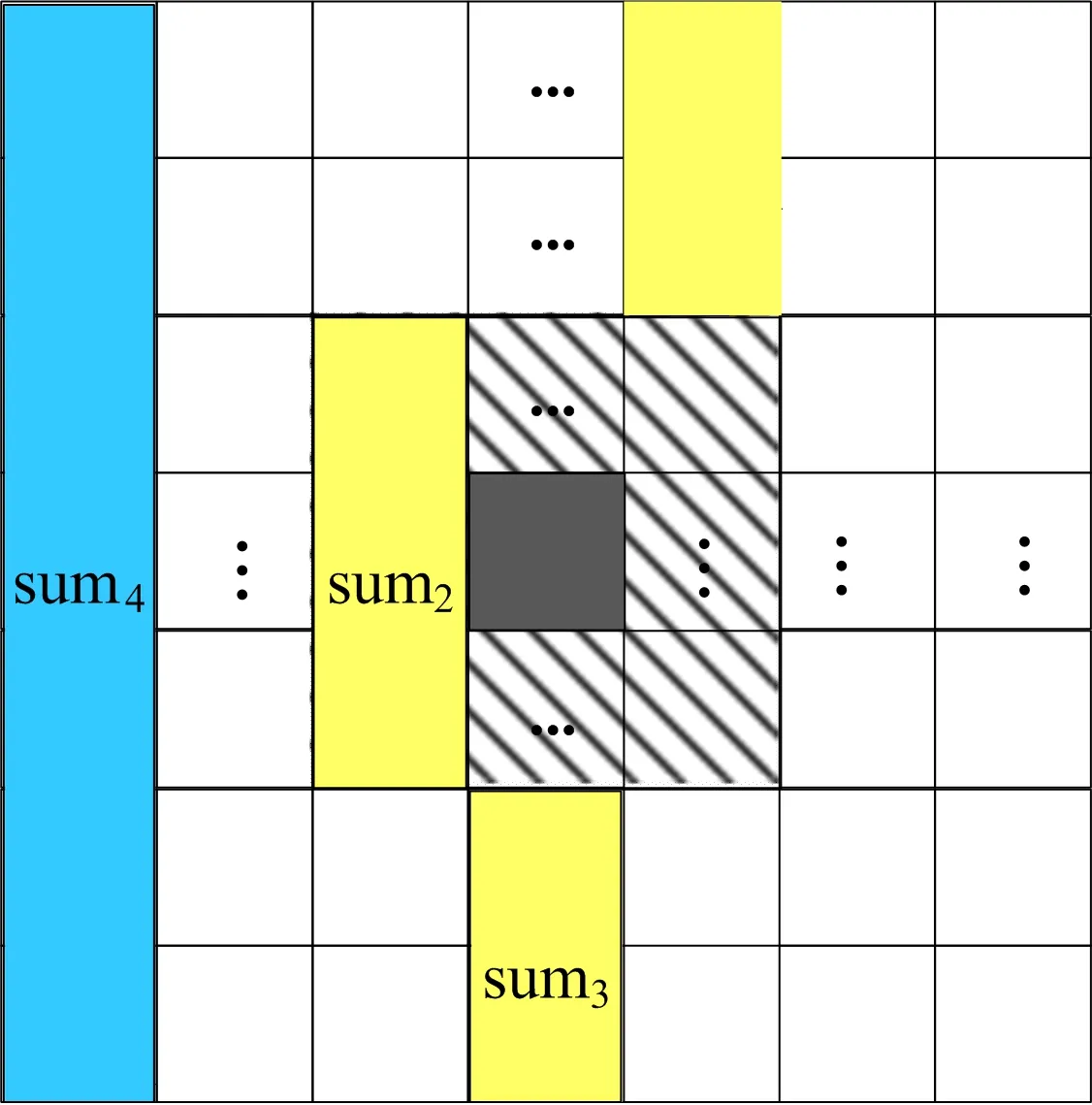
图3 均值类CFAR滑动窗口设计
在均值类CFAR设计中,根据参考窗尺寸和保护窗尺寸,通过控制sum1、sum2、sum3、sum4的延迟关系实现对多种窗口尺寸的兼容设计。图2中延迟关系为:
(1)
滑动窗口设计充分利用了已经求出的部分和信息,均衡了计算资源,减少了求和模块的数据吞吐压力,使得计算效率得到提升。
2.4 检测单元预处理
均值类CFAR算法对门限计算的常见处理是将左窗和、右窗和分别除以参考单元数目得到均值,再与标称化因子T相乘,得到检测门限。该方法需要2个除法器和1个乘法器,每步计算为串行。本设计以1/T作为均值类检测器输入。通过对标称化因子的预处理,在链式FIFO队列初始化预存数据的同时,并行完成temp等于参考单元个数与1/T相乘的计算。因此,在计算窗口累加和的同时,可以并行计算出检测单元幅值与temp的乘积YP。以YP与窗口累加和的比较,代替门限ST与检测单元幅值的比较,作为检测单元是否为目标的判定条件。优化后,本设计只需2次乘法,且可以由一个乘法器分时复用完成计算,节约了硬件资源的同时,利用FPGA的并行性压缩了计算时间。当运行OS-CFAR检测器时,temp直接被赋值为1/T,YP作为预取检测单元YN与1/T的乘积,称为压缩检测单元幅值。
2.5 OS-CFAR流水比较与二元积累
传统的OS-CFAR算法需要对参考单元数据进行全排序以获得杂波背景功率的估计值。显然,对于较大尺寸的二维矩形窗,全排序带来极大的计算量和比较器资源消耗。大窗口数据全排序成为OS-CFAR进行FPGA实现的瓶颈。
全排序为获得第K个排序样本值,需要计算其他各参考单元之间的大小关系,从而带来冗余信息及巨大的计算复杂度。其实,算法只关注压缩检测单元幅值与参考单元第K个排序样本的大小关系,即压缩检测单元幅值是否大于K个参考单元样本。因此,解决这一问题的关键在于消除冗余信息,将二元积累法应用于OS-CFAR可使判定条件等效转换,若sumB大于等于K则为目标,否则为杂波。其中sumB为压缩检测单元幅值与各参考单元幅值比较结果的二元积累和。二元积累法的应用将计算复杂度降低为N2次比较和累加。二维矩形窗OS-CFAR硬件设计通过复用均值类CFAR的链式FIFO队列结构以节约资源,延用滑动窗口思想,充分利用相邻窗口的数据依赖关系以减少缓存。由于链式FIFO队列每周期输出的数据为包含N个数据的列向量QR,在不加额外控制和存储资源的情况下,每个列向量读且只读出一次。而每一个列向量将作为N个连续参考窗口中的一列参考单元。因此,当一个列向量QR读出时,希望可以同时获得所有需要与QR比较的压缩检测单元幅值,这些压缩检测单元幅值所组成的队列记为待检测序列QY。QY与QR的相对位置关系如图4所示。
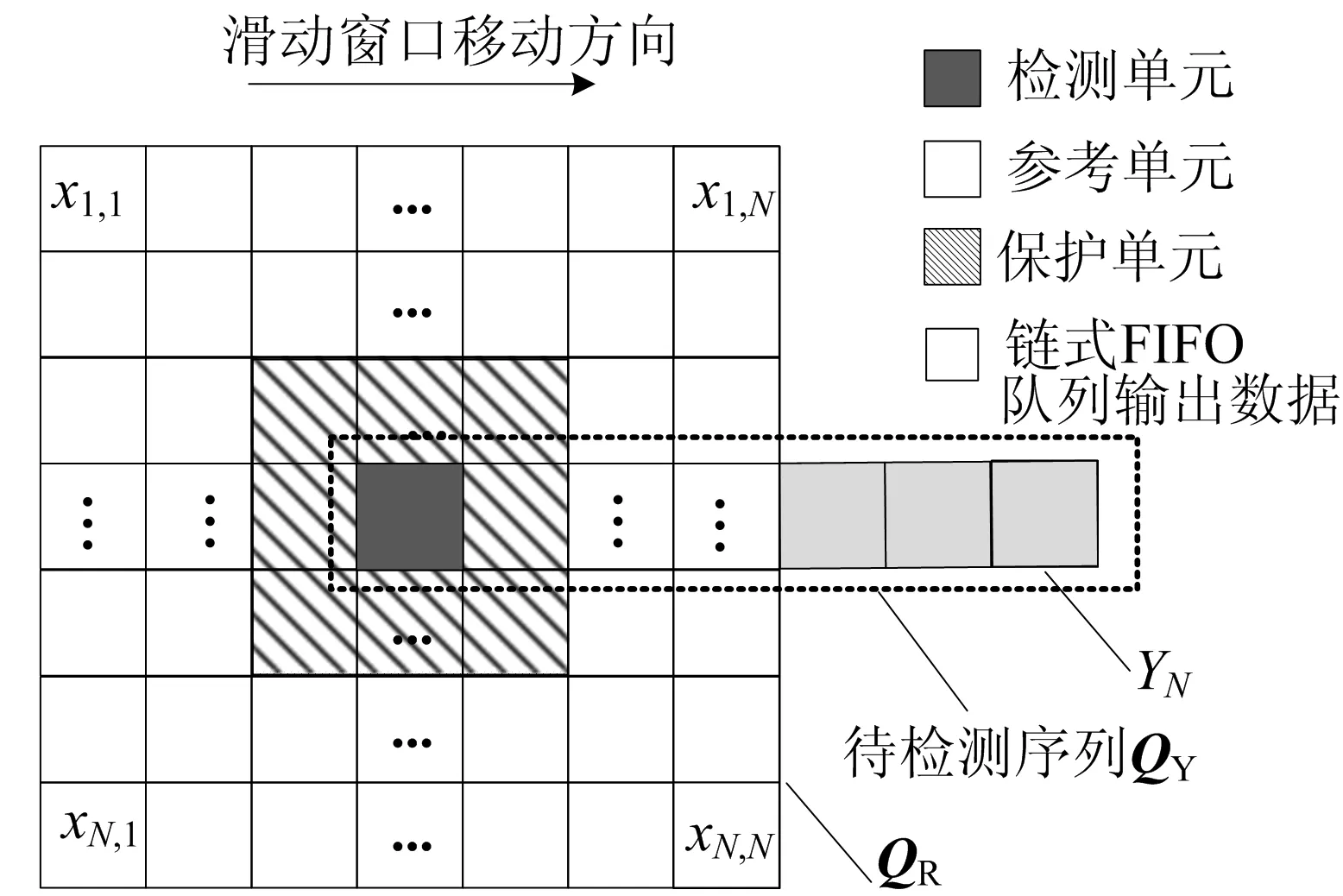
图4 OS-CAFR滑动窗口数据关系
根据图4中窗口向右滑动所需的数据更新规律,设计预取检测单元YN经过压缩后与列向量QR在同一周期到达图2中OS-CFAR流水比较模块的输入端口。OS-CFAR流水比较模块内包含寄存QY的31个移位寄存器和961个比较器,可在单周期完成QY与QR中各元素幅值比较。由于QR为检测单元Y所在参考窗口的第N个列向量,将QR与Y比较的二元积累和记为列积累和SN。同理,经过本周期比较后对于YN将得到对应的列积累和S1。将检测单元Y对应的SN与之前N-1个周期获得的各列的列积累和相加,得到有效二元积累和sumB,与K比较即可判定OS-CFAR检测结果。
3 实验结果
3.1 MATLAB建模
根据FMCW雷达系统工作原理,基于MATLAB对Chirp序列的Range Doppler处理进行仿真。首先生成以均匀杂波为背景噪声、携带2个目标信息的差频信号,再分别对快时间维度采样和慢时间维度采样进行加窗和FFT处理,最终得到RDM信息三维图,如图5所示。RDM数据即为二维CFAR检测器的输入。

图5 均匀杂波背景下存在2个目标的RDM信息三维图
3.2 FPGA实现效果
本设计以32位无符号定点数作为数据输入,参考窗尺寸N和保护窗尺寸M可动态配置,其中,3≤N≤31,1≤M≤21,N、M为奇数。设计以Xilinx xc6vlx240t FPGA开发板为实验平台,综合主频为220 MHz。
对于256×2 048点RDM 4种CFAR检测器均在2.71 ms(594 659周期)内完成检测,通过与MATLAB软件测试结果对比,验证了功能正确性,对于图5所示雷达回波信号的CFAR检测结果如图6所示。
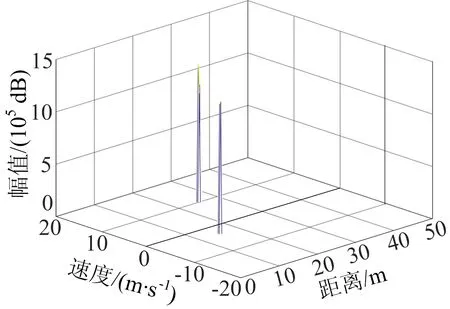
图6 CAFR算法检测结果
对比文献[13]提出的矩形窗动态可配置二维CFAR处理器设计,其设计最大主频为120 MHz,平均单点的CFAR处理周期为2.7个周期。本文最大时钟频率为220 MHz,平均单点处理周期为1.1周期。因此平均单点CFAR处理在时间上的加速比为4.4倍,本设计计算速度提升主要得益于链式FIFO队列在计算模块启动后无需在滑动窗口换行处理时浪费更新缓存的时间。文献[13]实现了CA、GO、SO、OS算法,根据其设计方案推测其中均值类CFAR检测计算模块消耗961个加法器。本设计采用滑动窗口设计使得均值类CFAR检测计算模块仅消耗39个加法器,加法器资源消耗节约95.9%。关于OS-CFAR设计,若同样处理尺寸为31的参考窗口,文献[13]将参考窗口数据全部寄存以完成滑动窗口处理,至少消耗961个寄存器,而本设计通过对参考单元的预取更加充分地利用了窗口数据更新规律,只需要31个移位寄存器对QY寄存即可,该模块寄存器资源节约96.8%。文献[15]本质上为兼容均值类和有序均值类算法一维窗口设计,最大窗口参考单元数为340。本设计仅使用与该一维窗口接近的FPGA资源,完成二维矩形窗CFAR设计,且最大参考单元数为961,其他各项资源比对见表2所列。

表2 二维CFAR检测器硬件资源消耗与对比
4 结 论
本文给出了一种高速可配置兼容CA、GO、SO、OS CFAR检测器的硬件加速设计,设计采用矩形窗,实现检测器类型、标称化因子、排序值K、参考窗口尺寸、保护窗口尺寸可动态配置。对于256×2 048点二维RDM数据可在2.71 ms内完成CFAR检测,具有高效的检测效率和较小的硬件资源开销。
猜你喜欢
科学与信息化(2021年30期)2021-12-24
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
制造技术与机床(2018年11期)2018-11-23
意林(绘英语)(2018年1期)2018-04-28
产品可靠性报告(2017年7期)2017-09-05
西北工业大学学报(2015年3期)2015-12-14
遥测遥控(2015年2期)2015-04-23
城市轨道交通研究(2015年11期)2015-02-27
