
基于LDA的中小企业科技需求关键信息提取方法
2023-05-30 10:48张震
电脑知识与技术 2023年2期
张震
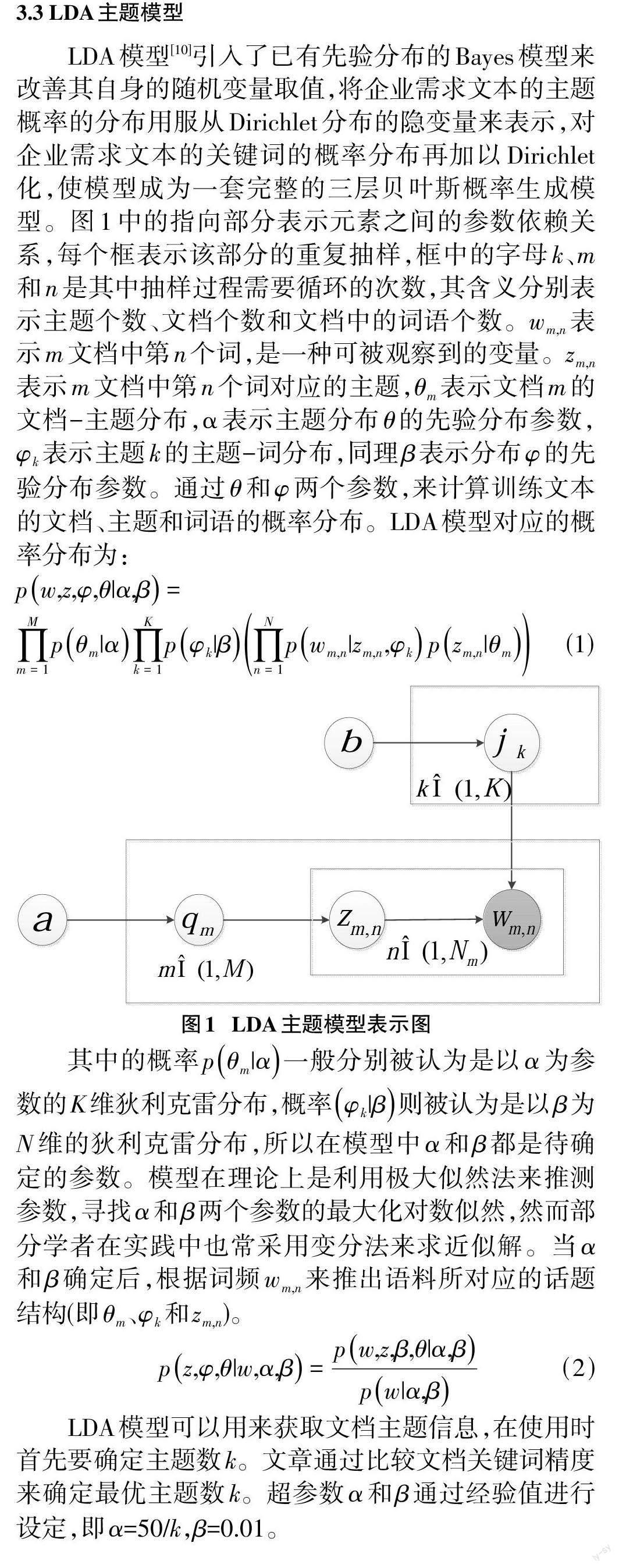

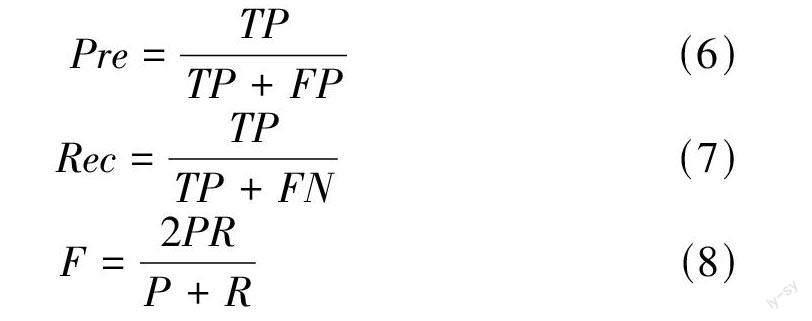
关键词:LDA 主题模型;文本预处理;关键词提取技术;企业科技需求
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)02-0016-04
1 概述
中小企业在我国的经济发展中的地位十分重要,在促进经济发展的同时,更能维护社会稳定。在协同创新模式下,中小企业的核心技术升级和企业综合发展的压力随之而来。中小企业的不足之处在于其高技术人才储备量不足,科学技术团队发展不够先进,在人才竞争方面处于劣势,当遇到企业科技需求问题自身不能更好解决时,往往通过企业家自身的社会关系寻找相关的专家或团队来解决难题,但最终成效往往取决于企业家自身所拥有的资源水平。所以,科技需求关键词的提取技术与科技协同创新平台相结合,将中小企业需求信息精准推荐给高校、研究所和科研团队,搭建企业与高校、研究所、科研团队所组成的科技协同,使中小企业的科技需求问题得到更好的解决方案[1]。
2相关研究
针对企业需求方面,文献[2]分析了在企业建模过程中使用机器学习方法是可行的,王学娟[3]提出了GM(1,1)模型和BP人工神经网络组合的企业人力资源需求预测模型来解决企业人力资源需求问题,但没有与高校或科研团队结合。李莹[4]通过主题模型的应用构建企业技术需求文本的向量空间模型对专家进行匹配,重点针对专家端的推荐和分析展开。Kang[5]等人结合潜在Dirichlet分配主题模型(Latent Dirichlet Allo?cation,LDA)和聚类算法,通过对技术类别进行分类后确定最佳匹配的团队,以此来选择产学研的合作伙伴,但忽视了企业方面的分析。综上所述,研究者对于企业需求文本特征的研究较少,需求大多为非结构化的中文文本,导致特征提取的精度也相对较低。主题模型方面,词频逆文档(Term Frequency - InverseDocument Frequency, TF-IDF)模型是最早的文本概率模型之一[6]。在企业科技需求的关键词提取上的不足之处在于该模型仅以词频来判断是否为关键词,在精度上会出现误差。经过潜在语义索引(Latent Seman?tic Indexing, LSI)、概率潜在语义索引(Probability La?tent Semantic Indexing, PLSI)等模型的优化,Blei等人[7]在此基础上提出了LDA模型,该模型可以挖掘不同主题下的关键信息,避免语义重复,因此更受广泛应用。
3模型构建
3.1 文本获取
数据来源于课题项目平台后台数据和科学家在线网络爬虫数据,包含需求标题、详细需求、限定时间、基本预算情况等信息。数据标题和详细需求是企业需求关键信息提取的重要内容,因此利用标题和详细需求将文档合并成一个文档,既能方便掌握需求主题信息,又能降低模型的时间复杂度。
3.2 预处理
由于文本的字词间无明显区分符号,所以在预处理上应进行文本的分词,文章主要运用Python语言版的Jieba分词器和Jieba库中的默认词性标注器进行标注。停用词通常是文本中出现频率高,却影响关键词提取效果的一类词语,停用词不但不利于表现文本所表达的主要内容,且给文本特征选择和提取带来干扰[8]。文章采用基于停用词表的停用词过滤方法,停用词表使用通用停用词表和专有停用词表,避免专业术语上不准确的停用词标记[9]。
4实验
4.1 实验环境
实验在内存为8G,系统为Windows 10的PC机上进行。训练及测试使用Python 3.7版本,调用gensim 库中的lda 包对LDA 算法实现。实验数据共计300 条,其中爬虫200条,采用Python第三方模块requests 抓取数据,通过循环翻页,获取网站的每页项目列表,使用正则表达式抓取每个项目列表对应的主页网址,进一步检索并抓取每个项目主页上的项目标题和项目内容描述,并保存在Excel表格中。经过数据预处理清洗后,将数据重新编号,并划分200 条数据作为训练集,主要训练模型主题数k,另外100 条作为测试集,作为评价本文算法的依据。针对数据集,每个文档采用10 人手动提取关键词,按照提取关键词的频率高低排序得出手动标注的关键信息。除此之外,基于相同的测试集,采用本文算法、TFIDF模型和传统的LDA 模型三种算法做对比实验。
4.2 评价标准
从关键词的定义和内在意义方面来讲,文本中提取关键词的评价标准是确定关键词本身是否符合文档的实际主题和语义。从关键词的科研角度和学术角度来讲,评价标准为所提取关键词的结构是否稳定,是否有利于对文本信息更好地挖掘[14]。当前多数使用精准率Pre(Precision)、召回率Rec(Recall)和二者综合值F 值(定量评价)对主题模型的效果进行评价,Pre、Rec和F值的计算公式见公式(6)、(7)和(8)。其中TP 表示预测为正,实际为正,FP表示预测为正,实际为负,FN 表示预测为负,实际为正。因此,精准率Pre 表示抽取的正确关键词占提取出的关键词条数的比例,召回率Rec表示抽取的正确关键词占样本中手动标注关键词的比例,F值为二者的综合评价。
4.3 实验结果及分析
实验数据集的中小企业科技需求共计六个方向,模型参数主题数k 影响着LDA模型和本文算法的实验精度,而TF-IDF算法的精度主要受关键词数num的影响。因此,实验利用控制变量的原则,对相关数据进行实验。表1是在k=3,以及每个主题的关键词为2个的条件下完成的(即num = 6),相应的TF-IDF算法关键词数num =6,保證实验每个模型的关键词数量为6个。为了便于比对和计算,每个需求文档的人工手动标注的关键词数为5。超参数α 和β 的值取α=50/k,β=0.01。本实验在上述数据集和参数的基础条件下完成。
根据表1和图2实验结果可以看出,本文提出算法在数据集的六个研究方向的F值依次为0.59、0.69、0.62、0.59、0.60、0.68。本文算法的每个研究方向的F值在数值上均高于另外的两个算法。并且,表4-1也显示了本文算法的Pre、Rec值也高于另外两种算法。所以直接表明了本文算法优于常用的TF-IDF和传统的LDA算法。在实际应用中,LDA模型将不同主题之间的关键词提取出来,在一定程度上解决了语义重复和多义性的问题,对次要主题和无关语义有很好的过滤作用。
此外,主题数k 大小一方面决定了关键词提取的数量,在另一方面对提取效果也有影响。本文设置k的取值在1至5之间,每个主题下的关键词数为2的情况下进行实验,保证关键词的提取数量和质量,从而训练出k 的最佳值。图3是本文算法与传统的LDA模型的F值的整体变化情况,本文算法在1至5之间是优于传统的LDA模型,但是随着主题数k 的增大,两种算法的F值逐渐接近,且F值出现先上升后缓慢下降的趋势。原因在于随着k 的增大,模型中抽取的关键词数越大,即公式(6)中的FP逐渐增大,因此精准率Pre在逐渐降低,F值也在不断降低,本文算法在K =3时效果最好。
5结束语
本文针对中小企业的人才不足和科学技术不够先进的问题,从需求文本入手,提出一种融合多特征加权的LDA算法,对中小企业科技需求关键词进行提取。关键词提取技术与科技协同创新平台相结合,将企业需求精确表达,并争取匹配到专家、高校或科研团队,在一定程度上能够促进产学研联动。该算法与传统算法相比,精度方面有明显的提升。就本研究而言,今后将从以下几个研究方向进行改进:首先是对LDA主题模型进一步改进和完善;其次是对中小企业科技协同平台的运行体系机制进行进一步深化和完善;最后可以将此模型进行其他应用领域的推广,例如高校信息模型,专家信息模型等。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
少儿科学周刊·儿童版(2017年9期)2018-03-15
儿童故事画报·发现号趣味百科(2017年4期)2017-06-30
信息安全研究(2016年4期)2016-12-01
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19
儿童故事画报·发现号趣味百科(2015年10期)2016-01-20
小学教学参考(2015年20期)2016-01-15
