
基于梯度数据选择的跨领域情感分析
2023-05-29 10:19:48周夏冰
软件导刊 2023年5期
苏 仪,周夏冰
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
情感分析是自然语言处理的研究热点。情感分析是指针对一段带有情感色彩的文本,分析其包含的情感极性(积极,消极)。传统的情感分析利用特征模板或统计机器学习方法,对文本本身的特征进行分析。随着深度学习的发展以及预训练模型的广泛使用,各种情感分析算法的功能越来越强大[1-3]。然而,目前的模型对训练数据的结构和领域都非常敏感,领域依赖性强,在跨领域预测时会明显降低模型预测的准确率。因此,如何进行跨领域情感分析逐渐引起研究者关注。
跨领域情感分析往往面临目标领域数据匮乏的问题,因此主要目的在于利用大量源领域数据和少量目标领域数据进行模型训练,使模型在目标领域获得较好的情感分析结果。大多数已有的方法都在尝试从目标领域的无标注数据集上微调预训练模型,然后从源领域的标注数据集上再次微调预训练模型[4-5]。但这些方法并没有较好地利用源领域数据,并且需要大量目标领域的无标注数据。因此,本文使用数据选择方法增强模型在目标领域的性能。数据选择是领域适应方面的一种有效方法,该方法可使在进行跨领域任务训练时倾向于选择与目标领域相关性更强的数据,由此缓解由于源领域与目标领域的差异而造成模型表现下降的问题。已有的数据选择方法通常考虑从训练集中选取一个子集去训练模型[6-9],或是给每一个样本赋予不同权重[10-11],或者改变数据进入模型的顺序等[12-13]。这些数据选择方法虽然有效,但仍要依靠特定领域的信息和人为设计的启发式方法。为此,本文提出基于梯度数据选择(Gradient Data Selection,GDS)的跨领域情感分析方法。梯度数据选择是一个通用的机器学习方法,训练一个额外的权重分配网络,通过比较模型对训练样本和验证集的梯度相似度,给每一个训练样本分配权重,并按照此权重选择训练样本。本文的贡献如下:
(1)提出一种通用的机器学习方法GDS。通过比较模型对训练样本和验证集的梯度相似度给每一个训练样本分配权重,该方法可以运用于许多迁移学习场景中。
(2)提出一种结合梯度更新方向与梯度更新幅度的梯度相似度比较方法。
(3)提供一种跨领域情感分析任务的解决方案。通过情感分析网络和GDS 打分网络的交替训练,不需要依靠特定领域的信息和人为设计的启发式方法即可完成跨领域情感分析任务,并且在亚马逊产品评论数据集上取得了最佳效果。
1 相关工作
1.1 情感分析
情感分析任务是NLP 的重点任务之一,深度学习和GolVe[1]、word2vec[3]等词向量模型被提出后,大多数情感分析任务都由深度学习方法来解决。文献[14]提出TextCNN,用单层的CNN 对文本进行整行的计算,保留了语义的完整性,更易于模型理解。文献[15]提出DPCNN,作者参考Resnet[16],在CNN 中使用残差连接的方式缓解了梯度消失问题。RNN 系列网络由于其自身性质,非常适合处理时间序列等信息,但具有长程依赖等问题。文献[17]指出LSTM 具有处理变长序列的能力,能够有效捕捉长距离依存关系中蕴含的语义信息,并构建了LSTM 树形结构,成功应用于语义相关性分析和情感分析任务。文献[18]利用情感词典、否定词和强度词构建语言学启发序列正则化LSTM 模型,不依赖句子解析和短语级标注,简洁、有效地实现了句子级情感分析。Transformer[19]的提出令NLP进入了一个新阶段,该模型利用注意力机制实现了RNNs所欠缺的并行计算,并在各任务上取得了更佳的结果。以Transformer 为基础,文献[20]提出BERT,该模型堆叠Transformer 编码器,通过巨大的网络和数据集以及mask 等训练方法实现了对各项任务的突破。此后,GPT[21]、Ro-BERTa[22]等预训练语言模型相继被提出,都取得了不错的成绩。
1.2 领域适应
在跨领域任务中,源数据集与目标数据集通常有着较大差异,使得从源数据集中训练出来的模型往往在目标数据集中表现很差。为了让模型能更好地应对跨领域任务,领域适应概念被提出。文献[23]提出结构对应学习(SCL),使用人为选择的中心词特征进行情感分析,其中中心词是两个领域之间表达情感的一些共享词;文献[24]提出的谱特征对齐(SFA)将不同领域的中心词和非中心词通过谱特征进行对齐,利用两个领域之间的互信息进行特征提取和分类;文献[25]提出域对抗神经网络模型(DANN),尝试将对抗网络的思想融入领域适应,其从两个领域中提取数据,并且通过一个鉴别器将两个领域的数据映射到不变域中;文献[26-27]使用半监督方法,以更有效地利用目标领域的特定信息;文献[28]提出交互式注意力迁移网络(IATN),通过整合句子级和方面级的信息,可以更好地跨域转移情绪。IATN 由两个注意网络组成,对这两个网络进行交互注意学习,可使句子和局部都能影响最后的情绪表征;文献[29]使用两个不同的分类器来提供不同视角,试图增强源领域和目标领域的分类一致性;文献[30]使用一个中心词选择器和可迁移的transformer 同时学习中心词和特征,然后在具有领域不变性的特征向量中进行情感分析;文献[31]提出主题驱动的自适应网络(TDAN),该网络由语义注意力网络和领域词注意力网络两个子网络组成,子网络的结构是基于Transformer 的。这些子网络采用不同形式的输入,其输出融合为特征进行后续任务。
1.3 数据选择
数据选择是领域适应方面一种受到关注的方法,该方法使跨领域任务训练时更倾向于选择与目标领域相关性更强的数据,由此缓解由于训练数据的领域差异而造成模型表现下降的问题。除领域适应外,在面对带噪数据或其他不理想数据时,数据选择也同样有着不错的效果[32-33]。目前已有了许多数据选择方法,例如从训练集中选出一个子集去训练模型[6-9],或是给每一个样本赋予不同权重[10-11],或者改变数据进入模型的顺序[12-13]等。然而,这些数据选择方法要依靠特定领域的信息和人为设计的启发式方法。为了避免人为设计启发式方法,文献[34]提出优化一个参数网络,在特定任务下学习数据选择策略,通过构建和使用学生模型与教师模型,选择最优的训练数据;文献[35]提出为不同训练样本自动分配权重,以更好地利用训练数据,从而实现跨领域的效果。
2 本文模型
图1 展示了本文模型的整体框架,主要包括基于预训练模型的分类网络和基于GDS 的打分网络。其中,分类网络θ是一个全连接层,打分网络φ是包含N 个数据的可训练矩阵,N 为训练集规模,矩阵中的每个值表示对应样本点被选择到的概率。
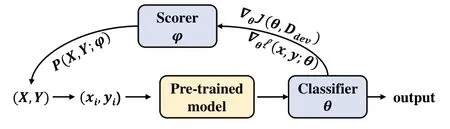
Fig.1 Overall framework of the model图1 模型整体框架
2.1 基于预训练模型的情感分析
BERT 对输入进行分词和编码之后,融合标记(token)、划分(segment)以及位置(position)向量,得到文本的向量表示如下:
其中,j表示层数。通过此方法,将文本转化为一个768维的向量Hi。
获得文本表示Hi后,通过一个全连接层获得文本的情感分析结果。
2.2 基于GDS的打分网络
机器学习的目标是优化风险J(θ,P(X,Y)),并且找到使其最优的参数θ*,即:
其中,<x,y>是从分布P(X,Y)中抽样出来的样本对,l(x,y;θ)指在样本对<x,y>上参数为θ时的损失值。一般情况下,优化目标是能够在测试集Dtest上达到最优效果,而测试集的分布满足Ptest(X,Y)。所以,目标就是最小化J(θ,Ptest(X,Y)),然而测试集的数据是不可知的,尤其在跨领域情感分析任务中,测试集与训练集的数据情况往往差异较大。因此,本文将目标领域的数据拆分成验证集和测试集。此时,有Pdev(X,Y) ≈Ptest(X,Y),虽然数量较少,但模型可以根据验证集给出的反馈更好地选择训练数据。
本文用φ参数化一个打分网络,该网络表示在Dtrain中赋予每一个样本的权重,初始时每个样本的权重相同。在模型训练过程中,每次在Dtrain中选取样本时,需要考虑到φ的影响,即Ptrain(X,Y)转化为Ptrain(X,Y;φ)。与此同时,加入φ之后的Ptrain(X,Y;φ)需要能够尽量与Pdev(X,Y)接近,此时模型的目标是同时优化θ和φ得到θ*与φ*,使得J(θ,Ptrain(X,Y;φ))最小。
基于以上目标,本文提出的模型有两组参数,一组为θ,另一组为φ,这两组参数的优化是交替进行的,即每一次更新θ之后,φ也会进行一次更新。设在t 时刻,θ和φ分别为θt和φt。θ的优化为:
而φ在初始化时,要保证不会对原来训练集的分布造成影响,即:
之后,每更新一次θ就更新一次φ。在样本进入分类网络之后,根据得到的损失l(x,y;θ),网络会计算出模型参数θ的梯度∇θl(x,y;θ)。同样的,也可以计算出验证集进入模型之后模型参数θ的梯度∇θJ(θ,Ddev)。通过比较这两者的相似度,打分网络会给每一个训练样本分配权重。显然,相似度更高的样本会分配更高权重。此外,为了更好进行打分网络的更新,本文提出一种兼顾梯度更新方向与梯度更新幅度的比较方法,如式(6)所示:
其中,gt=∇θl(x,y;θ),gd=∇θJ(θ,Ddev)。α表示梯度更新方向的权重,β表示梯度更新幅度的权重。α与β可以自行调整,α与β的和超过1 时,此相似度的值有可能超出1,但这并不会对后续的梯度更新过程造成影响,所以实验中并未对此进行约束。本文采用强化学习的思想进行优化,根据REINFORCE 算法[36],有以下更新规则:
在式(7)中,每个样本点所对应的sim(x,y,Ddev)与训练集分布P(X,Y;φ)的负对数相乘,作为loss,然后计算梯度、更新参数。不难看出,这里的sim(x,y,Ddev)即使超出1也没有影响,只是让梯度更大一些而已。
初始化θ和φ之后,每次先更新θ,然后更新φ。θ在φ的指导下进行更新,φ又根据θ得到的反馈进行更新,最终得到θ*和φ*,具体步骤见算法1。
算法1基于GDS的跨领域情感分析
输入:源领域训练集Dtrain,目标领域验证集Ddev。
输出:分类网络的最优参数θ*,打分网络的最优参数φ*。
分类网络由参数θ表示,打分网络由参数φ表示。在训练时,根据打分网络φ决定的Ptrain(X,Y;φ)选择样本点,然后根据选择的样本点使用梯度下降法更新θ。之后计算出模型在验证集上的梯度,同时逐个取出所有样本点,计算其梯度。最后,根据式(6)逐个计算样本点的相似度,根据式(7)更新φ。在T 个epoch 后,得到最优参数θ*和φ*。
两个网络在更新过程中性能都会不断增强,类似于对抗网络。但不同的是,对抗网络是在竞争中进步,而此网络是相互促进、共同进步的。在更新过程中,分类网络能够更好地鉴别情感极性,打分网络能够更好地选取与验证集更接近的样本。由打分网络φ的更新公式(7)可以看出,与验证集相似度更高的样本在更新后会获取到更高权重,这从直观上来看是合理的。
3 实验过程与结果
3.1 数据集
为了更好地验证本文提出的模型性能,实验采用亚马逊产品评论英文数据集[23]和online_shopping_10_cats 中文数据集。亚马逊产品评论数据集统计信息如表1 所示,online_shopping_10_cats数据集统计信息如表2所示。

Table 1 Amazon product review dataset statistics表 1 亚马逊产品评论数据集统计信息
亚马逊产品评论数据集是跨领域情感分类的基准数据集,在许多跨领域情感分类任务中都有着广泛应用。其包含书本(books)、DVD、电子产品(electronics)、厨房用品(kitchen)4 个领域的亚马逊产品的英文评论,每个领域有1 000 个正样本和1 000 个负样本作为训练集,250 个正样本和250 个负样本作为验证集,250 个正样本和250 个负样本作为测试集。online_shopping_10cats 数据集是一个中文的产品评论数据集,包含来自各电商平台的10 个类别产品的6 万多条评论,正向与负向评论各约3 万条。本文选取其中衣服、水果、酒店、平板4 个领域的评论,每个领域随机选取1 000 个正样本和1 000 个负样本作为训练集,250 个正样本和250 个负样本作为验证集,250 个正样本和250个负样本作为测试集。

Table 2 online_shopping_10_cats dataset statistics表 2 online_shopping_10_cats数据集统计信息
3.2 实验参数设置
本文所使用的GPU 为NVIDIA GTX 1080Ti,使用pytorch 框架进行模型搭建、训练和测试,并使用多种预训练语言模型,隐层大小为768。模型采用交叉熵损失函数,使用Adam 优化器对参数进行微调与更新,批量大小为32,设置分类网络的学习率为1e-4,打分网络的学习率为5e-2,相似度比较中的参数α和β都为0.8,更新轮数为200。
3.3 实验结果及分析
为了验证本文方法在跨领域情感分类中的有效性,实验分别进行了基准模型比较以及通用性分析。
3.3.1 基准模型性能比较结果
跨领域情感分析在亚马逊产品评论数据集上的准确率如表3 所示。其中,在任务(Task)一栏中,“→”符号表示迁移方向,B、D、E、K 分别表示books、dvd、electronics、kitchen 4 个领域,加粗字体记录的是该迁移方向的最优结果。GDS 的结果来自本文实验,其余的实验结果来自文献[31]。为消除实验结果的随机性,共进行了6 次实验,并取其均值作为最后的结果。
为了更好、更全面地与目前的相关模型进行比较,基准模型性能比较选取了目前跨领域情感分析常用的亚马逊产品评论英文数据集,比较的基准模型包括:

Table 3 Accuracy of cross-domain sentiment analysis on Amazon product review dataset表 3 跨领域情感分析在亚马逊产品评论数据集上的准确率
(1)SCL。使用不同领域的特征相关性进行情感分类[23]。
(2)SFA。是一种线性方法,其将不同领域的中心词与非中心词通过谱特征进行对齐,利用两个领域之间的互信息进行特征提取和分类[24]。
(3)DANN。使用对抗网络的思想进行领域适应,其从两个领域中提取数据,并且通过一个鉴别器将两个领域的数据映射到不变域中[25]。
(4)IATN。基于注意力机制整合句子级和方面级的信息,可以更好地跨域转移情绪[28]。
(5)ACAN。使用两个不同的分类器提供不同视角,试图增强源领域与目标领域的分类一致性[29]。
(6)TPT。使用一个中心词选择器与可迁移的Transformer 同时学习中心词和特征,然后在具有领域不变性的特征向量中进行情感分类[30]。
(7)TDAN。由语义注意力网络和领域词注意力网络两个子网络组成,子网络的结构是基于 Transformer 的。这些子网络采用不同形式的输入,其输出融合为特征进行后续任务[31]。
(8)GDS。本文使用的模型,使用RoBERTa-large 作为特征提取器,连接上一个线性层作为分类器,然后利用GDS进行跨领域情感分类任务。
从表3可以看出,GDS 比已有的任何一种方法都更优。在12 个迁移方向中,GDS 在10 个方向上取得了第一,另外两个方向的第一是TDAN,但差距不大。GDS 在有些方向的迁移能力远远超过其他方法,在B→K、D→B、D→K、E→K、K→B 方向的迁移均比已知的最好方法高出2%以上。从均值来看,GDS 比SCL 高出11.5%,比SFA 高出 9.1%,比DANN 高出6.1%,比IATN 高出2.3%,比ACAN 高出2.8%,比TPT 高出5.4%,比 TDAN 高出1.2%。相对于其他方法,GDS 对数据有更准确的可迁移性评估能力。另外,分类网络和打分网络同时更新,使得打分网络会针对分类网络目前的分类能力而动态更新数据的可迁移性。而其他基于域不变性和中心词的迁移方法,只考虑数据是否可迁移的某个方面(域不变性或中心词),并没有考虑到影响数据迁移性的其他因素,所以迁移能力不如GDS。
3.3.2 模型通用性分析
为了验证本文GDS 方法的通用性,分别在英文和中文数据集上对不同预训练模型与不同方法进行测试。基于不同的预训练模型,融合基于GDS 的打分网络(带有下标g),体现了GDS 的通用性。表4 展示了不同预训练模型与方法在亚马逊评论数据集上的准确率。实验结果均来自本文实验,为消除实验结果的随机性,共进行了6 次实验,并取其均值作为最后的结果。
下面对各预训练模型作一个说明:

Table 4 Accuracy of different pretrained models and methods on Amazon product review dataset表 4 不同预训练模型与方法在亚马逊产品评论数据集上的准确率
(1)BERT。指bert-base-uncased,其强调了不再像以往一样采用传统的单向语言模型,或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的Masked Language Model(MLM),以生成深度的双向语言表征。BERT 论文发表时提及在11 个NLP 任务中取得了新突破[20]。
(2)DBERT。指distilbert-base-uncased,由于BERT 模型巨大,DistilBERT 使用知识蒸馏的方法将BERT 进行压缩。DistilBERT 的参数大约只有BERT 的40%,而速度快了60%,并且保持了一定精度[37]。
(3)GPT-2。使用Transformer 架构,相比word level 的嵌入词向量能够学习到更丰富的语义语境信息,相比传统的RNN 网络能够建模更长距离的相关信息,沿用Unsupervised pretraining+Supervised fine-tuning 的套路,是有着15亿参数、40G 网页数据(800 万个多样化文档)的超大模型,在很多任务上刷新了成绩[38]。
(4)RoBERTa。指roberta-base,与BERT 架构基本相同,数据规模、训练时长、batch-size 等都有所增加,同时也作了一些小的改动[22]。
从表4 可以看出,直接使用源领域的数据微调预训练模型,很难使其在目标领域上获得理想效果。而加入GDS之后,几乎所有任务的准确率都有所提升。在4 个预训练模型12 个迁移方向的共48 组数据中,GDS 在44 组数据中取得了第一。其中,有8 组数据的提升率在5%以上。从均值来看,GDS 使得BERT 的准确率提升了3.7%,DBERT的准确率提升了3.5%,GPT-2 的准确率提升了0.8%,Ro-BERTa 的准确率提升了2.1%。由此可以证明,GDS 方法适用于各种预训练模型。
为了验证GDS 在其他语言环境中依然有效,本文在online_shopping_10_cats 中文数据集上对不同预训练模型和不同方法进行了测试。表5 展示了各模型在online_shopping_10_cats 数据集上的准确率。在Task 一栏中,“→”符号表示迁移方向,C、F、H、P 分别表示衣服、水果、酒店、平板。实验结果均来自本文实验,为消除实验结果的随机性,共进行了6 次实验,并取其均值作为最后的结果。
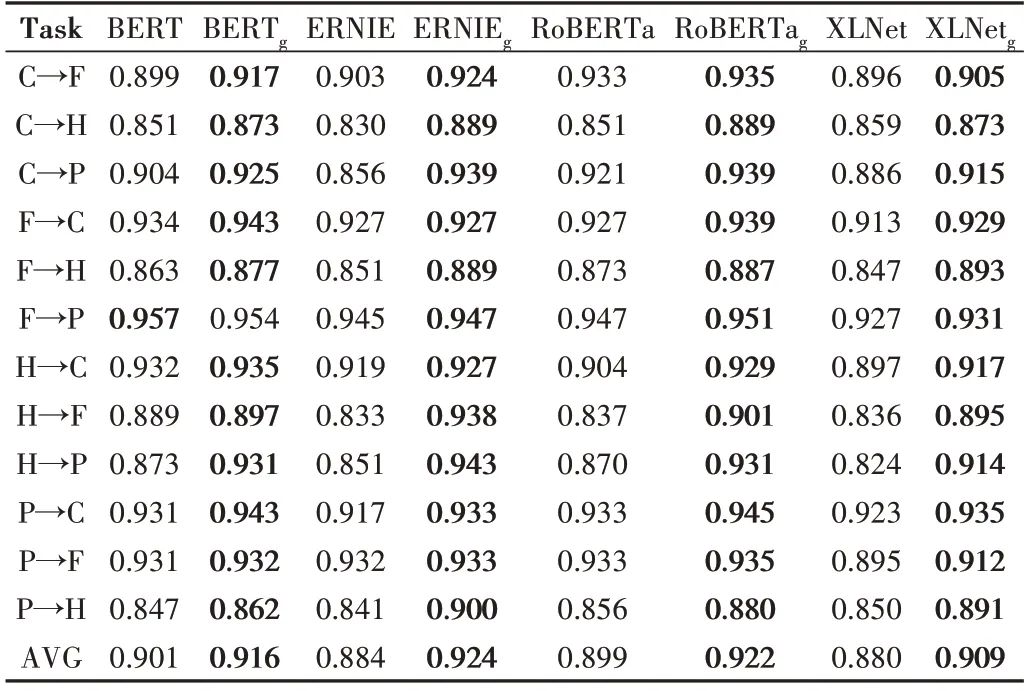
Table 5 Accuracy of cross-domain sentiment analysis on the online_shopping_10_cats dataset表 5 跨领域情感分析在online_shopping_10_cats数据集上的准确率
下面对各中文预训练模型作一个说明:
(1)BERT。指bert-base-chinese,这是BERT 使用中文语料训练而成的中文预训练模型[14]。
(2)ERNIE。基于BERT 模型作了进一步优化,在中文的NLP 任务上得到了最佳结果。其主要是在mask 的机制上作了改进,在预训练阶段增加了外部知识,由3 种层次的mask 组成。在此基础上,借助百度在中文社区的强大能力,中文的ERNIE 还使用了各种异质的数据集[39]。
(3)RoBERTa。指hfl/chinese-roberta-wwm-ext,这是RoBERTa 使用中文语料训练而成的中文预训练模型[22]。
(4)XLNet。指chinese-xlnet-base,使用AR 模型替代AE 模型,解决mask 带来的负面影响,引入双流注意力机制,由中文数据集训练而成[40]。
在online_shopping_10_cats 数据集上的准确率很多都超过了90%。同样,GDS 取得了最佳结果,在48 组数据中有47 组排在第一名,仅有一组以微弱的劣势低于原方法。其中,有10 组数据的提升在5%以上。在ERNIE 的H→F这一组数据中,GDS 的加入使得准确率提升了10.5%。从均值上看,GDS 使得BERT 的准确率提升了1.5%,ERNIE的准确率提升了4%,RoBERTa 的准确率提升了2.3%,XLNet 的准确率提升了2.9%。由此可以证明,GDS 适用于多种语言环境。
4 结语
本文针对目前跨领域情感分析要依靠大量无标注数据以及特定领域的信息和启发式方法的问题,提出梯度数据选择(GDS),同时提出一种结合梯度更新方向与梯度更新幅度的梯度相似度比较方法,并结合预训练模型实现了对训练集数据的高效利用,在亚马逊产品评论数据集上达到了87.3%的平均准确率,高于现有的各种方法。同时,GDS 有着非常强大的可移植性,可以在许多迁移任务场景中发挥作用,本文的实验证明了GDS 在迁移任务中的有效性。
尽管本文的方法已经取得了一定效果,但是依然有提升空间。如何提升GDS 更新时的效率是一个值得关注的问题。在本文的实验中,分类网络仅有一个全连接层,所以打分网络在比较梯度时计算量并不大。但如果模型复杂度增加,打分网络的更新将变得十分耗时,所以需要考虑如何加速打分网络的更新。异步更新可能是一个不错的解决方案,这将是下一步工作的重点。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
应用数学(2020年2期)2020-06-24 06:02:50
青年生活(2019年23期)2019-09-10 12:55:43
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
中国交通信息化(2018年5期)2018-08-21 03:37:40
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
河南科技(2014年3期)2014-02-27 14:05:45
