
基于多模态融合的突发事件分类研究
2023-05-27 15:00陈锟裴雷范涛
现代情报 2023年6期
关键词:突发事件
陈锟 裴雷 范涛


关键词: 突发事件; 多模态分类; 混合融合; 特征抽取
DOI:10.3969 / j.issn.1008-0821.2023.06.003
〔中图分类号〕D63; TP391.3 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 06-0024-11
随着信息技术的迅猛发展, 网络已然成为当下人们所依赖的虚拟世界。据中国互联网络信息中心(China Internet Network Information Center, CNNIC)发布的第50 次《中国互联网络发展状况统计报告》中显示, 截至2022 年6 月, 我国的网民规模已经达到10 51 亿人次, 网络新闻用户突破7 88亿, 占总体的75 0%[1] 。由于网民数量规模的庞大, 一旦在网络环境中产生突发事件的新闻并传播, 其传播速度之快、辐射面之广极易引起群体性事件的发生, 这对于社会秩序是极具破坏力的, 同时也会对政府公信力和执政能力提出挑战, 网络舆情也会在此过程中持续发酵。在中国共产党第二十次全国代表大会中, 习总书记明确指出: “要提高公共安全治理水平。坚持安全第一、预防为主, 建立大安全大应急框架, 完善公共安全体系, 推动公共安全治理模式向事前预防转型”[2] 。《中华人民共和国突发事件应对法》也指出: “要预防和减少突发事件的发生, 控制、减轻和消除突发事件引起的严重社会危害, 规范突发事件应对活动”[3] 。突发事件事态预防、舆情治理的前提工作便是对突发事件新闻进行识别分类, 高效精确的分类能够帮助相关部门搜集信息以及跟踪其发展趋势, 当某类突发事件的新闻数量陡然上升时, 政府部门就可以及时关注和处理, 这不仅能提前预警, 为政府采取对应的措施提供宝贵时间, 也能有效避免负面舆情升温, 提升政府在人民群众中的公信力。
突发事件的突发性、破坏性和衍生性等典型特征在传播过程中会给社会带来巨大的潜在威胁, 因此如何快速有效地识别分类突发事件信息成为目前的研究热点。梳理突发事件分类相关研究, 可以发现以下两个问题: ①多模态新闻在社交媒体中流行度较高[4] , 从笔者粗略统计的突发事件新闻数据来看, 多模态内容所占比例达到约四成左右, 而现有的突发事件分类研究主要以文本模态为主[5-6] , 缺乏结合多模态特征的研究, 忽略了多模态信息能够有效帮助提升突发事件分类模型性能的事实; ②在突发事件新闻中, 存在模态缺失或单个文本对应多张图片的情况, 现有的多模态分类研究缺乏针对此问题的解决方案[7] 。鉴于此, 本文设计了一种基于多模态混合融合的突发事件分类模型(EmergencyClassification Model with Hybrid Fusion, ECMHF),该模型基于预训练的BERT 模型和VGG19 模型对采集的新闻数据进行文本描述特征和图片语义特征抽取, 并对其采取级联拼接操作构成多模态模型的输入, 最后将单模态模型和多模态模型的决策层输出赋予权重, 进一步提升整体模型的检测性能和鲁棒性, 从而实现混合模态下的突发事件分类。
1研究现状
突发事件的分类研究是应急决策系统中的关键环节, 对于开展应急响应工作有着至关重要的作用。本节将从突发事件现有研究和多模态混合融合研究两个方面展开述评。
1.1突发事件分类研究
如何高效精准分类突发事件信息的关键在于信息特征的表示和模型的学习能力, 为此国内外众多学者开展了大量研究, 大体上可以分为两个阶段:第一阶段是利用传统的机器学习方法; 第二阶段是采用层次结构紧密的深度学习方法。在机器学习阶段, 学者通过自主研究设计特征提取规则来将非结构化的信息处理成形式一致的特征, 再利用分类器实现进一步的分类工作。例如, Liu Y 等[8] 考慮到单词的顺序和语义关系的重要性, 使用可变长度的n-gram 来表示文本特征, 利用支持向量机(SupportVector Machine, SVM)实现对突发事件文本分类;Wei B B 等[9] 在公共安全三角理论的基础上构建相应的事件规则库, 将此输入到最大熵模型(MaximumEntropy Model, MEM)中进行训练, 构造出突发事件分类模型; 陈国兰[10] 采用相对词频、词频增长率和爆发词权重来提取爆发词特征, 采用共词分析的方法实现爆发词聚类, 以此达到突发事件识别分类的目的; 张馨月等[11] 构建领域专用停用词表后利用TF-IDF 方法抽取文本特征, 再利用支持向量机在公开数据集上进行文本分类; 闫宏丽等[12] 将突发事件新闻中成组出现的类别关键词作为决策树的属性项, 通过判定类别组合情况实现分类。然而,这些提取方法通常只能抽取到表层的信息特征, 遗漏掉高层次的抽象语义信息, 难以表达词与词之间的相互关系和词序特征, 同时对于高维数据的泛化学习能力较差, 使得模型在识别分类的准确率上达到瓶颈阶段。
近些年随着技术和理论的不断发展, 深度学习逐渐成为研究热点, 与传统的机器学习相比, 前者更能全面地挖掘深层次的语义特征信息。深度学习是由Hinton G E 等[13] 在2006 年提出的概念, 主要是通过深层结构的学习模型从数据中提取出高度抽象的具备语义属性特征的信息, 解决了浅层结构网络对复杂函数表达效果欠佳的问题, 因其性能优越而被广泛应用于自然语言处理的多个任务中, 其中突发事件分类任务也因利乘便, 日臻完善。例如,Lai S W 等[14] 首先将文本特征进行词向量处理, 并将其输入到RNN 和CNN 联合组成的RCNN 神经网络中去, 最后可以观察到分本分类的效果显著提升;Zhou B 等[15] 利用多个基于BERT 模型对特定突发事件的推文进行分类, 实验结果显示基于BERT 的模型其准确率均有所上升; 胡庭恺等[16] 利用BERT模型抽取文本特征, 采用自适应决策边界模型来学习突发事件类别在高维语义空间上的决策边界, 该模型的有效性在公开数据集上被得以验证; 范昊等[17] 以新闻标题为研究对象, 构建融合词嵌入信息、文本特征信息和上下文信息的BERT-TEXTC?NN-BiLSTM 模型, 模型泛化能力和分类效果相较于传统模型有明显上升; 宋英华等[5] 考虑到词语间或词语与类别间相互关系, 在关键词特征的研究基础上提出了DCLSTM-MLP 的深度学习新闻文本分类模型, 以实现突发事件的识别和分类。
虽然深度学习方法在突发事件分类研究中获得巨大成功, 但从以上文献可以看出, 目前该领域的分类研究仍然局限于单模态分类, 未考虑到图片语义特征对分类模型研判性能的提升作用, 从而导致特征信息捕捉不充分、模型学习能力较弱的问题。针对此问题, 本文拟在突发事件分类研究中引入多模态融合思想, 结合突发事件文本和对应的图片展开分类研究。
1.2混合融合分类研究
混合融合是特征级融合和决策级融合的结合体[18] 。特征级融合指对多模态数据进行特征信息提取后将其融合在一起的方式; 决策级融合是指将对数据进行推理或评估得到的初步决策信息进行融合的方式。多模态混合融合方法虽然使得模型的复杂度增加, 学习难度加大, 但结合了两种策略的优势, 在深度学习模型搭建中较为常用。例如, Lan ZZ 等[19] 将混合融合方法应用于多媒体事件的检测,设计双融合的方案解决了过拟合问题, 并在该领域取得SOTA 效果; 陶霄等[20] 从文本、视觉和用户3个特征维度切入口搭建谣言检测模型, 并在前后期融合以实现特征和决策的自动加权, 最后将模型运用于微博和Twitter 数据集检验自身的准确率; HuangF 等[21] 利用视觉与语义内容之间的内在联系和特征, 通过混合融合框架搭建起一种新的图文情感识别模型, 即深度多模态关注融合模型; Tashu T M等[22] 以艺术绘画为研究对象, 利用CNN 抽取图像特征, 利用BERT 联动Bi-GRU 捕捉具有上下文关系的文本特征, 最后进行多级融合后, 构造出艺术绘画多模态情感识别框架; Yucel C 等[23] 在情感识别领域也提出一种混合融合策略, 寻找相同的潜在空间来融合视频和音频两者的特征, 并采用D-S证据理论来融合视听空间和文本模态特征; 张继东等[24] 以旅游评论为研究对象, 将融合后的文本表情特征以及提取的图片特征分别放入分类器中进行反讽识别, 再将二者的识别概率进行融合, 构建出多模态旅游评论中反讽识别模型。
考虑到现有的突发事件分类研究中模态单一致使分类效果差、突发事件信息结构不统一导致模态缺失或单文本对应多图片的问题, 本文将在多模态思想的基础上加入混合融合策略, 即用深度学习方法提取出突发事件新闻的文本描述特征和图像语义特征后, 利用加权平均策略将指向同一条文本的所有图片特征处理为一个特征向量, 然后在前后期分别对特征信息和决策信息进行融合, 并将收集的真实新闻数据输入到模型中进行训练和测试, 以此构建起鲁棒性强、分类效果优越的突发事件分类模型。
2基于多模态融合的突发事件分类模型构建
2.1模型总体架构
本文将采集的突发事件新闻数据拆分为文本数据和图片数据, 然后分别输入到特征提取模型中进行特征提取, 再将提取的文本特征和图片特征输入到特征融合模型中进行信息融合, 最后将单模态模型和多模态模型的决策层输出赋予对应权重, 以实现混合融合策略下的突发事件分类。
具体地, 构建多模态融合的突发事件分类模型ECMHF, 该模型由4 个部分组成, 分别是突发事件文本特征抽取分类模型、突发事件图像特征抽取分类模型、突发事件多模态融合分类模型和突发事件混合融合策略, 其中混合融合由前期特征融合和后期各模型决策层输出的概率分布及对应权重组成, 模型总体架构如图1 所示。在文本模块, 利用预训练模型BERT 对其进行特征抽取, 然后联动BiLSTM 网络捕捉上下文语义特征信息; 在图片模块, 利用迁移学习的思想将VGG19 卷积神经网络作为特征抽取的基础模型; 在特征级融合模块, 采用Concatenate 特征拼接技术融合文本特征和图像特征; 最后利用3 个分类模型的决策层输出进行权重分配, 构建出ECMHF 模型。
2.2突发事件文本特征抽取分类模型
BERT(Bidirectional Encoder Representations fromTransformers)[25] 是谷歌团队的Devlin J 等在2018 年提出的预训练语言模型, 因掩码语言模型(MaskedLanguage Model, MLM)和下一句预测(Next SentencePrediction, NSP)的独特设计而在众多的自然语言处理任务中表现突出。预训练的BERT 模型可以很好地提取词语级、句子级和句子之间关系的特征, 在文本分类任务[26] 、序列标注任务[27] 以及问答系统领域[28] 等都取得了很好的效果。在Jawahar G 等[29]对BERT 模型的内置推理研究中表明, 各编码层学习到的特征不尽相同, 从低向上分别是短语级特征、句法结构特征和语义特征, 层次越高, 学习到的特征就越抽象。因此, 本文采用BERT 模型对突发事件的文本信息进行描述特征抽取, 同时引入BiL?STM 网络来捕捉文本中长距离的上下文语义信息,获取能为分类提供决策的优质特征。具体流程如图2 所示。
2.3突发事件图像特征抽取分类模型
在突发事件识别中, 除文本以外, 图片同样包含着丰富的视觉语义信息, 有助于精确识别突发事件类型, 因此在多模态分析过程中, 图片的特征抽取也很重要。大量研究表明, 卷积神经网络在图像特征抽取方面卓有成效, 在计算机视觉领域表现突出。本文选取VGG19 网络作为突发事件图像特征抽取器, VGG19 模型是在ImageNet 数据集(含有1 400多万张图片, 超过2 万多个分类)上进行预训练, 取最后一层作为图像特征输出, 其优势在于在感受也相同时, 采用迭代效率更高的3×3 小卷积减少参数量, 增加多个非线性层来保证复杂的模型学习, 同时其付出代价更小[31] 。
本文利用开源计算机视觉库OpenCV[32] 内置的resize()函数将图片尺寸统一设置为224×224, 带有RGB 彩色三通道, 作为VGG19 模型的输入。再将深度学习库Keras 中封装的VGG19 载入, 其结构包含16 个卷积层, 5 个最大池化层和3 个全连接层, 为保证实现领域迁移下的特征学习效果, 将VGG19 模型的权重参数Weights 設置为Imagenet,随后将训练得到的特征向量输入到以ReLU 为激活函数的Dense 层。为防止出现过拟合现象, 增强模型泛化能力, 本文加入Dropout 层随机丢弃网络单元, 最后将结果输入到Softmax 函数中获得图像的分类标签。具体模型如图3 所示。
2.4突发事件多模态融合分类模型
多模态特征融合能够捕捉不同模态之间的信息交互, 是提升多模态分类模型性能的关键步骤[33] 。特征融合的方式有简单的级联融合和加权融合, 虽然特征级联融合比较简单, 但在识别任务中也能有效提升模型性能[34] 。本文选取级联拼接的方式来融合突发事件的文本和图片特征, 即用Concatenate操作将两者联合起来。
对于上游任务中获取的文本描述特征H 和图片语义特征V 进行拼接, 得到多模态向量表示M,如式(8) 所示。
3实验与结果分析
3.1数据获取及数据预处理
在国家标准化管理委员会发布的《突发事件分类与编码》中将突发事件分为4 类: 自然灾害事件、公共卫生事件、社会安全事件和事故灾难事件。本文将全球网、中国法院网、百度新闻以及澎湃新闻等新闻媒体作为数据源头, 以4 类事件名称为关键词检索, 采用爬虫工具与人工结合的方法,共采集文本2 125条, 图片2 137张, 文本与图片存在一对多情况, 数据示例如图4 所示。
对获取的突发事件新闻进行预处理, 采用以下手段措施来检验数据可用性和降低噪音: ①检查图片与文本的契合度, 对图文不符的进行剔除; ②利用Python 对文本去除特殊字符和停用词; ③导入CV2 库检测图片是否可读取和修改为224×224 尺寸,对不符合要求的图片进行剔除; ④以图片存储路径字符串为基础对象, 对其进行特定修改后获得对应文本位置, 再一一对应读取; ⑤为不同事件类型贴上数字标签, 通过fit_transform 方法转换为one-hot形式; ⑥将清洗后的文本、图像和标签数据存储为Pickle 文件。经过清洗筛选最终获得符合条件的文本图片2 111对, 各类别文本和图片数量如表1 所示, 再将数据按照4 ∶1 划分为训练集和测试集, 分别为1 688对和423对。
3.2实验设计
3.2.1实验环境及参数设置
本文的所有实验均使用Python3.8 进行编写运行, 使用的深度学习框架为Tensorflow2.10.0, 实验运行设备的内存为16.0GB, Intel(R) Iris(R) XeGraphics 显卡, CPU 型号为Intel(R) Core(TM) i5-12500H。
在本文的ECMHF 模型中, BERT 预训练参数使用谷歌提供的基于维基百科中文预料训练好的模型参数, 句子长度设置为128, 若长度大于该值则从左向右截取128 字符作为输入数据, 若不足则采用Padding 方法补充为0, 抽取模型的sequence_output 特征作为文本特征向量表示。在BiLSTM 中,将LSTM 的Units 设置为128, 优化器采用随机梯度下降(Stochastic Gradient Descent, SGD)[35] , 学习率设置为0.001, 动量大小为0.9, 同时采用Drop?out 技术防止模型训练过拟合, 其值设置为0.5,全连接层使用激活函数ReLU。利用Earlystopping方法监测损失值, 当损失值在10 个轮次中没有进展时自动终止训练。VGG19 模型训练时设置输入张量为(224,224,3), 抽取模型最后一个全连接层输出作为图像特征。经多次实验发现, 文本特征抽取分类模型在训练轮数为45 左右便稳定, 故将Epochs 设置为50, 批次大小设置为8; 图片特征抽取分类模型Epochs 设置为100, 批次大小设置为8; 特征融合分类模型Epochs 设置为25, 批次大小设置为128。损失函数设置为交叉熵损失函数。
经过多次动态调整权重的实验对比, 本文提出的ECMHF 模型在α =0.4、β =0. 4、γ =0.2 时识别性能最好, 即决策层融合阶段文本分类模型输出概率分布权重为0.4, 多模态分类模型输出概率分布权重为0.4, 图像分类模型概率分布权重为0.2。
3.2.2评价指标
本文选择精确率(Precision)、召回率(Recall)和F1 值(F1-score)来对突发事件的分类结果进行评估, 精确率是衡量模型不将负类样本预测为正的能力, 召回率是衡量模型找出真样本的能力, F1 值是衡量模型的稳健能力, 其值越大, 模型稳健能力越强。具体计算方式如式(12)~式(14) 所示。
其中TP 表示样本为正且预测为正, FP 表示样本为负但预测为正, FN 表示样本为正预测为负。
3.2.3基线模型
为验证本文模型的有效性, 选取以下模型作为对比的基線模型, 这些模型在之前研究中都达到过优越效果, 具有一定的对比性。
1) BERT-BiLSTM。为验证提出模型的有效性,本文设计BERT 联动BiLSTM 的对比模型来对文本特征进行抽取, 后接一个维度为256、激活函数为ReLU 的全连接层, 以及一个分类的Softmax 层。
2) VGG19[36] 。VGG19 模型在众多计算机视觉任务中取得过最优效果, 为探索该模型在领域迁移后的效果, 将收集的突发事件图片数据处理后输入模型获得图像语义特征, 后接一个维度为256、激活函数为ReLU 的全连接层, 以及一个分类的Softmax 层。
3) ECMMF。为与混合模态模型性能对比, 构建文本图片融合的多模态分类模型, 将突发事件的文本和图片特征进行拼接, 后接一个维度为256、激活函数为ReLU 的全连接层和用于分类的Softmax层。
4) SVM(text)[11] 。SVM 在传统的机器学习任务中性能优越, 将BERT 模型抽取的文本特征降维后作为该模型输入, 对文本进行分类。
5) SVM(img)。将VGG19 模型抽取的图片特征作为SVM 输入, 对图片进行分类。
6) SVM(text+img)。级联拼接降维后的文本描述特征和图片语义特征, 作为SVM 的多模态特征输入。
3.3实验结果分析
本文通过在搜集的突发事件新闻数据集上实验评估模型的性能效果, 通过消融实验和不同模型对比实验来比较模型的评价指标以及细粒度事件上的分类效果, 以此达到验证本文提出的基于多模态融合的突发事件分类模型(ECMHF)有效性的目的。
3.3.1消融实验
为验证本文提出模型的有效性, 进行消融实验对比, 实验结果如表2 所示。
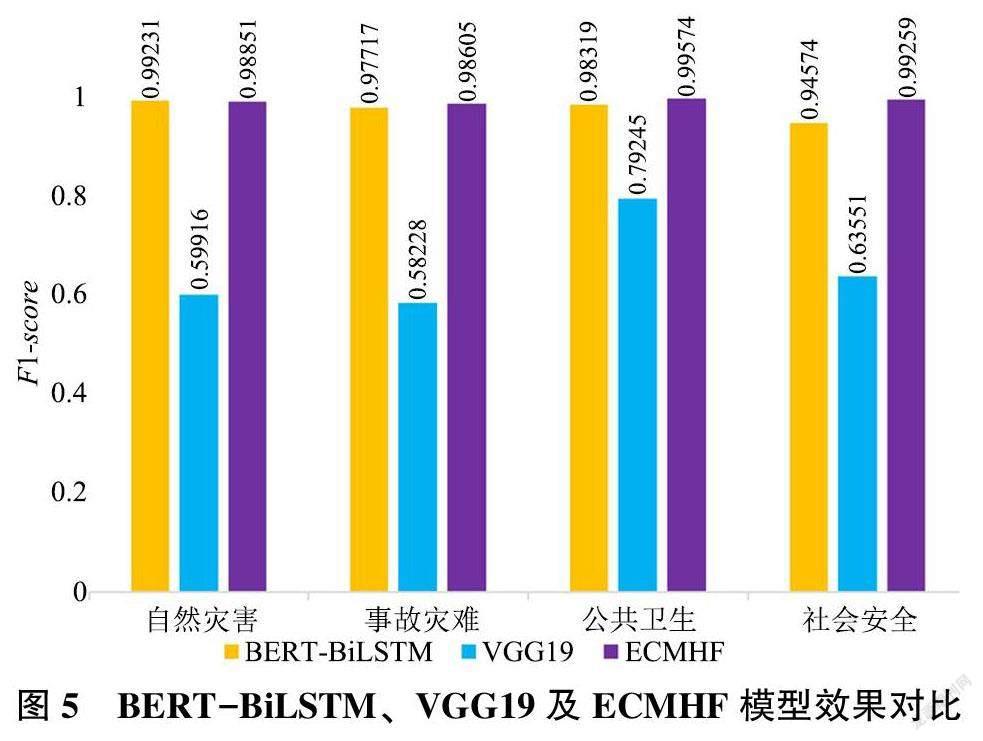
从实验结果可以看出: 在融合文本特征和图片特征后, 模型的表现均优于单模态模型的表现, 验证了信息融合策略的有效性。同时, 为验证本文提出的混合融合策略的有效性, 绘制ECMHF 模型与单文本模态分类模型BERT-BiLSTM 与单图像模态分类模型VGG19 的分类效果对比图, 如图5 所示。在突发事件4 类新闻的分类效果中, 最差的是基于图像特征的VGG19 模型, 其F1 值远低于BERTBiLSTM模型和ECMHF 模型, 说明突发事件新闻识别分类任务中单一的图像语义特征在信息表征能力上比文本描述特征弱。此外, 在自然灾害类事件新闻中BERT-BiLSTM 模型分类效果最佳, 比EC?MHF 模型的F1 值高出0.38%, 但在事故灾难、公共卫生、社会安全3 类突发事件的识别分类任务中均为ECMHF 模型最佳, 其F1 值分别高出BERTBiLSTM模型0.888%、1.255%和4.685%。总体而言, ECMHF 模型识别分类综合效果最佳, 说明混合融合策略极大地提升了模型在突发事件新闻上的分类性能。
3.3.2不同模型对比实验
本文设计的其余基线模型对突发事件整体识别分类的结果如表3 所示。结合表1 分析, 在实验结果对比中发现: 捕捉长距离双向语义信息的BERTBiLSTM模型性能优于SVM 模型, 这说明融合文本上下文语义信息能够提升文本分类器的识别效果。SVM 模型在图片分类上的效果优于深层次网络结构的VGG19 模型, 原因在于VGG19 提取图像语义特征属于高维特征, 且最后连接Softmax 分类器, 将提取的特征输入到两个分类器模型时, SVM 对高维特征的效果分类会比Softmax 好[37] 。融合文本图片特征的多模态突发事件识别模型(Emergency Clas?sification Method with Multimodal Model, ECMMF)和基于SVM 的多模态识别模型均比单一模态识别模型在各项指标上略胜一筹, 这充分展现出多模态融合在突发事件识别中的优势。值得关注的是, 本文提出的ERMHF 模型在各项指标中均达到最优效果, 与次优模型相比, Precision 高出0.466%, Re?call 高出0.898%, F1-score 高出0.51%, 这充分说明ECMHF 模型性能优越, 在突发事件新闻研究中提升了分类效果。
为对比各个模型在细粒度事件上的分类性能,绘制本文单模态分类模型和多模态分类模型在具体突发事件新闻上的识别效果, 得到各模型分类效果图, 如图6 所示。在自然灾害类事件新闻中, 识别分类效果最好的是BERT-BiLSTM 模型, F1 值达到99.231%; 在事故灾难类和社会安全类事件新闻中, 识别分类效果最好的是ECMHF 模型, F1 值分别为98.605%、99.259%; 在公共卫生类事件新闻中, 识别分类效果最好的是ECMMH 模型和ECM?HF 模型, 两者的F1 值均达到99.574%。在单模态文本分类中, BERT-BiLSTM 模型在自然灾害和公共卫生事件中分类效果均优于SVM 模型, 但二者在社会安全类事件新闻的分类效果远低于其他3类事件, 究其原因, 笔者认为是由于训练样本量偏少, 其训练样本仅为257 对新闻数据, 致使模型学习不充分, 分类效果相比其他3 类事件较差一点;在单模态图片分类中, SVM 模型在自然灾害类、事故灾难类和社会安全类事件新闻的分类效果均优于基于VGG19 的分类模型, 但在公共卫生类事件新闻上基于VGG19 的模型识别效果高出SVM 模型0.619%, 但两个模型的分类效果均远低于文本分类效果。此外, 在数据量充足的情况下, 两个模型在自然灾害类和事故灾难类事件新闻的识别效果仍然低于66%, 笔者对此进行图像数据整理与核对时发现, 两类事件新闻中部分图片在不依赖文本的情况下极难区分, 例如自然灾害类新闻中的火灾图片、不可抗力导致的建筑坍塌图片与事故灾害类新闻中的房屋火灾图片、撞击导致建筑毁坏图片, 这也致使计算机在提取两类新闻图片特征时因相似度高存在极高的难度, 导致分类模型不易区分; 在多模态分类中, 加入混合融合策略的ECMHF 模型在各类具体事件新闻识别分类效果都达到了98.6%以上,除了在公共卫生类事件新闻中与仅融合特征的EC?MMF 模型识别效果持平外, 其余各项指标均高出SVM 模型和ECMMF 模型, 说明本文提出的模型在真实实验数据中表现出较强的识别分类性能。
绘制ECMHF 模型accuracy 准确率曲线和loss损失曲线, 如图7 和图8 所示。从图7 中可以看出,准确率在前10 轮迭代中稳步上升, 在20 轮迭代后呈现出稳定趋势, 维持在98%以上, 表明模型學习能力稳定, 同时模型训练也未出现过拟合现象。从图8 的损失曲线走势中可以看出, 迭代初期模型loss 值下降趋势明显, 表明深度神经网络学习能力突出, 在20 轮后呈现出稳定状态, 趋于收敛。
4结语
本文针对目前突发事件分类研究的模态单一、分类效果不理想的问题, 同时考虑到新闻媒体中承载着形式各异的新闻, 设计了一种在特征级和决策级混合融合的多模态突发事件分类模型ECMHF。该模型利用预训练的BERT 模型对新闻提取文本特征, 引用VGG19 模型对新闻提取图像特征, 再以此为基础构建文本单模态、图像单模态和特征融合多模态的分类模型, 最后将各模型的结果输出进行决策级融合。本文在真实的突发事件新闻数据集中展开实证研究, 实验结果表明, 混合融合的策略能够较好地结合前期融合和后期融合的优势, 具备一定的鲁棒性和可拓展性, 该方法应用于真实场景下突发事件新闻数据集所取得的分类效果均优于其他基线模型, 表明ECMHF 模型在突发事件的分类中具有一定的优势。尽管本文提出的模型在采集的新闻数据集上效果良好, 但仍需在更多样、更复杂的突发事件新闻环境进一步验证, 尤其在针对图片模态的研究中, 为更加精准识别出不同类别的突发事件, 需要扩大样本数据量。在未来研究中, 将尝试设计能够有效学习突发事件多模态数据特征的算法, 增强模型表示能力, 从而能更为精准地判别突发事件类型。
猜你喜欢
传媒评论(2019年3期)2019-06-18
科技传播(2019年24期)2019-06-15
新闻传播(2018年2期)2018-12-07
新闻传播(2018年14期)2018-11-13
传媒评论(2018年4期)2018-06-27
新闻传播(2016年19期)2016-07-19
西藏科技(2015年9期)2015-09-26
