
基于纠错码的SM3改进算法
2023-05-26 09:13郑明辉乔译萱朱小强
工程科学与技术 2023年3期
郑明辉,乔译萱,朱小强,陈 珩
(1.湖北民族大学 智能科学与工程学院,湖北 恩施 445000;2.四川大学 网络空间安全学院,四川 成都 610065)
在实际的通信过程中,数据保密性和数据完整性是传输数据的基本安全需求。密码杂凑算法作为基础的密码算法之一,主要功能是提供数据的完整性检验,即数据经过信道传输和存储过程未被未授权方修改。密码杂凑算法的实质是将任意长度的消息序列映射成固定长度的输出值(也称为杂凑值)。并且无法从杂凑值反推出原本的消息序列,称为杂凑函数的单向性。基于该特性,杂凑值可以构造“数据指纹”来进行数据的完整性检验,应用于身份认证、密钥推导、消息认证码、区块链等场景。典型的密码杂凑算法包括MD5、SHA1、SHA2、SM3等。其中,SM3算法[1]是由国家商用密码管理办公室于2010年公布的商用密码标准,2012年成为行业标准,并于2016年成为国家标准,2018年正式成为ISO/IEC国际标准[2]。北京大学密码学研究组开发维护的密码算法工具包OpenSSL分支GmSSL支持SM3算法[3],并在之后的正式版本中添加了SM3算法的实现[4]。
Merkle-Damgard(记作MD)结构[5-6]是密码杂凑算法的经典迭代结构,基于该结构所构造的杂凑函数,如果压缩函数具有抗碰撞性,则该函数也具有抗碰撞性。SM3算法作为MD结构的典型代表,将任意长度的数据输入压缩成256 bit的输出,能够有效抵御穷举攻击,同时采用消息双字介入、P置换等方法构造具有更高复杂性的轮函数,使得对SM3算法构造原像攻击是比较困难的[7]。安全性方面,目前针对MD5、SHA-1、RIPEMD、HAVAL等杂凑函数已找到快速碰撞的方法[8],同时在碰撞攻击、区分器攻击、原像攻击方式下,对SM3 算法的攻击难度相比其他传统算法更高[9],能够在具有高安全性需求的应用场景下进行数据传递。
然而,由于MD结构是串行结构,在效率上很难突破,同时易遭受消息扩展攻击及二次碰撞攻击[10],所以研究人员开始将目光投向杂凑算法的迭代结构。徐劲松等[11]提出基于并行扩展算法的杂凑函数,提升了算法安全强度,但不适合短消息的处理。Yang等[12]针对杂凑函数并行迭代结构的局部碰撞问题提出基于混沌映射的压缩函数,增强了算法的抗碰撞能力和运算效率,但由于基于格的并行迭代结构,导致运算开销没有显著降低。Halder等[13]利用2D-CA技术构建杂凑函数的迭代结构,使算法的随机性和扩散性有所提升,但算法的轮函数定义为35轮,运算复杂性不高。Liu等[14]构造具有更高随机性的3D-ECM来充当海绵函数,同时输出指定长度的杂凑值,减轻了侧信道攻击的威胁,但由于构造过程中增加字符转换操作,无法保证运算效率的提升。Todorova等[15]提出基于Zaslavsky混沌映射的杂凑算法,该算法具有更强的抗碰撞性,但由于迭代过程中使用较多异或操作,导致算法复杂性不高。王镇道等[16]将MD5算法迭代过程的64步运算设计为32级的流水线,在保持串行运算的前提下提高了算法的运算速度,但未曾考虑算法安全性。巫光福等[17]以MD5算法为例构造基于线性分组码的密码杂凑算法,提高了密码杂凑算法输出值的随机性,但产生的杂凑值为128 bit,抗穷举攻击能力较弱。
综上所述,目前针对密码杂凑算法迭代结构的研究方法主要包含并行计算和混沌映射。其中:并行计算达到了提高数据运算效率,但与串行结构相比增大了计算复杂度;混沌映射则是通过提升初值敏感度来增强杂凑算法的抗碰撞性,但未考虑优化杂凑值的比特混乱度,杂凑值混乱度的提升也是算法安全性的重要评估条件之一。针对构建具有更高随机性的密码杂凑算法,本文提出基于纠错码的SM3改进算法的设计方案,选用纠错能力更强的线性分组码并计算对应的生成矩阵;在生成的有效码字中选择8个最优码字串联赋值给初始寄存器,同时与每个512 bit消息分组进行迭代压缩运算,所产生的杂凑值为256 bit,若采用蛮力攻击,则需要执行2256数量级的操作,保证算法的安全性。实验结果表明,本文算法满足雪崩效应,并在运算效率相近的情况下,产生的杂凑值随机性更高,同时算法内存消耗更少。
1 准备知识
在数字通信过程中不可避免发生差错,对于接收到的数据序列,纠错码的主要作用是在存储设备及通信中进行纠错和检错,被广泛用于密码学和通信系统中。纠错码主要分为分组码和卷积码。下面重点介绍分组码[18]及其相关知识[19-21]。
定义1(线性分组码)有限域GFq上 的一个(n,k)线性分组码C是GFqn上的k维线性子空间,其中,n为分组码的码长,码C中向量称作码字,k为信息码元长度,k/n为 码的信息率,n-k为 码C的校验位或者监督位。
定义2(汉明距离)两个不同码字之间的汉明距离定义为两个序列之间对应不同的位数,记作d。

式中,⊕为异或运算。
码字间的距离表示码字之间差异程度的大小。当存在干扰时,距离越大,一个码字变成另一个码字的可能性越小。
定义3(最小汉明距离)码C的最小汉明距离dmin定义为所有任意两个码字汉明距离的最小值。对于线性分组码,记为(n,k,dmin)。
定义4(生成矩阵)对于(n,k,d)线性分组码,有下列关系式:
式中:m为k维矢量;k×n的矩阵G称为线性分组码C的生成矩阵,G的行向量构成码C的一组基。
对于给定信息码元长度k、码长n的 线性分组码C,其生成矩阵不唯一,并且可以通过初等行变换相互进行转换。其中,无论生成矩阵如何初等变换,码字都是唯一确定的,任意生成矩阵可产生相同的 2k个码字。
2 基于纠错码的SM3算法构造
SM3算法是基于分组迭代的国际密码杂凑算法,该算法比其他国际杂凑算法标准设计更复杂,具体表现在Merkle Damgard迭代结构中每一轮压缩都使用2个消息字,以及消息拓展过程中每一轮都使用5个消息字,并且将不同群运算结合,使明文消息非线性迅速扩散。下面给出基于纠错码的SM3改进算法具体构造过程。
单个消息分组处理过程主要利用纠错码构建初始常量并将其嵌入到初始缓存器中,再进行64步迭代操作。具体分为初始常量构造、消息预处理、消息扩展、迭代压缩、杂凑值输出5个步骤。其中,输入是最大长度为264-1 bit的消息,输出是长度为256 bit的消息杂凑值,处理单元是512 bit消息分组。
2.1 初始常量构造
在构造基于纠错码的SM3算法过程中,需要选择合适的线性分组码C,一个最优 (n,k,dmin)分 组码C必须满足以下条件。
1)确定n和k,使dmin尽量最大化,则构造出的码C可以提高纠错能力。
2)确定n和dmin,使k尽量最大化,则构造出的码C可以提高传输速率。
3)确定k和dmin,使n尽 量最小化,则构造出的码C可以提高传输速率。
综上所述,构造性能良好的纠错码,需要考虑信息k、码长n、最小汉明距离dmin这3个参数的相互制约问题,达到传输效率及纠错能力的平衡。
根据可变拟阵搜索算法和拟阵联接度的定义[22],可以构建一类最优的二进制线性 (n,k,dmin)码及它的生成矩阵Ga×b[23]。因为本文所构建的加法常数表需8个32 bit串联而成,所以选择构建SM3的线性分组码为(32,6,16),并求得该线性分组码的生成矩阵G6×32。为了使加法常数能达到随机化和无规律性最大化的效果,需要有效降低比特之间的规律性,经过测试,选择将生成矩阵G6×32进行循环左移6位,最终产生的杂凑值的熵值达到预期设计要求,即杂凑算法的随机性更高。生成码字集合U={u1,u2,···,u2k},k=6。
基于SM3算法的初始常量及迭代过程的特征,应选择8个码字串联来构建本文算法的初始常量,其中初始常量集合B0以下列方式选取:
重新构造的初始常量应满足两个要求:
1)初始常量二进制表示中,1、0的数量比趋近于1。
2)初始常量二进制表示中,最长1游程小于10,最长0游程小于8。
2.2 消息预处理
假设输入消息m的 长度为lbit,首先,在消息的末尾先添加比特“1”;再在后面添加k个“0”,k满足l+1+k≡488 mod 512;再添加64 bit的比特串来表示输入消息的长度l,得到填充后的消息m′,长度为512×nbit;最后,将消息m′按512 bit进行分组:
式中,n=(l+k+65)/512。
2.3 消息扩展
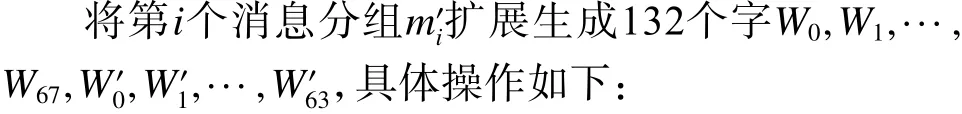
1)将m′i分为16个32 bit的比特串W0,W1,···,W15。
2)W16,W17,···,W67以下列规则进行扩展:
式中,Wj为 消息扩展的第j个字,< <<k表示循环左移k比特运算,固定公式P1(·)定义为:
3)W16,W17,···,W67以下列规则进行扩展:
式中,W′j为消息扩展的第j+69个字。
2.4 迭代压缩
将初始常量集合B0中8个码字分别赋值于寄存器A、B、C、D、E、F、G、H中,对第i个消息分组m′i以下列方式迭代:
式中,CF压缩函数由64步迭代运算组成,Bi为第i次迭代输入的集合。将Bi赋值于A、B、C、D、E、F、G、H作为初始寄存器,同时添加中间变量S S1、S S2、TT1、TT2进行左向赋值操作,具体过程描述如式(9)~(12):
式中,←表示左向赋值运算符,Tj为 32 bit常量,FFj(·)、GGj(·)为 定义好的布尔函数[1],0 ≤j≤63。
将更新后的中间变量TT1、TT2 与寄存器A、B、C、D、E、F、G、H进行状态更新,过程描述如下:
1)将初始寄存器A、C、E、G分别赋值于寄存器B、D、F、H,然后将中间变量TT1赋 值于寄存器A。
2)对中间变量TT2 进行公式运算后赋值于E,具体运算过程如下:
式中,固定公式P0(·)定义为:
3)将更新后的寄存器B、F进行循环左移操作后赋值于寄存器C、G,描述如下:
每轮迭代的输入都是上一轮迭代的输出再与512 bit的分组消息进行运算的结果。
2.5 输出杂凑值
最终所有消息分组处理完毕之后,最后一个512 bit的输出即为算法杂凑值。
密码杂凑算法的安全水平是由它的输出长度决定的[24],本文所构造的杂凑函数输出长度为512 bit,与128 bit的输出相比更能抵抗原像攻击、第二原像攻击和碰撞攻击。
3 实验分析与对比
第2节所构造的密码杂凑函数是针对SM3算法的改进算法,下面从雪崩效应、信息熵方面进行本文算法的安全性分析,同时通过仿真实验进行算法运算效率和内存损耗性能分析与讨论。
3.1 安全性分析
3.1.1 雪崩效应分析
密码学中约定密码杂凑算法应满足雪崩效应,即输入消息微小的改变会引起杂凑值至少一半以上的位数发生变化,以达到更好的混淆效果,利用式(17)~(19)对本文改进算法的雪崩效应进行稳定性评估。
式(17)~(19)中,Bi为第i次测试的杂凑值改变的比特数,P为平均雪崩系数,N为测试的总次数,n为杂凑值比特数,B为平均变化比特数。理想状态下P为50%,表明密码杂凑算法具有良好的雪崩效应,均方差 ΔP数值越小,则密码杂凑算法的稳定性越好[25]。
为了进一步验证改进算法性能,选择传统SHA-256算法和SM3算法,以及改进的MD5算法[17](记为Wu-MD5算法)进行雪崩效应测试。随机选择明文消息并计算生成的杂凑值,任意改变消息中的1 bit,同时计算新生成的杂凑值。由于杂凑值长度不同,所以仅针对雪崩系数P及均方差 ΔP进行数值比较,结果如表1所示。值得说明的是,雪崩效应仅是杂凑算法扩散效应的指标之一,其结果无法直观地进行4种算法混淆性的优劣比较,仅能够进行雪崩效应的稳定性评估。
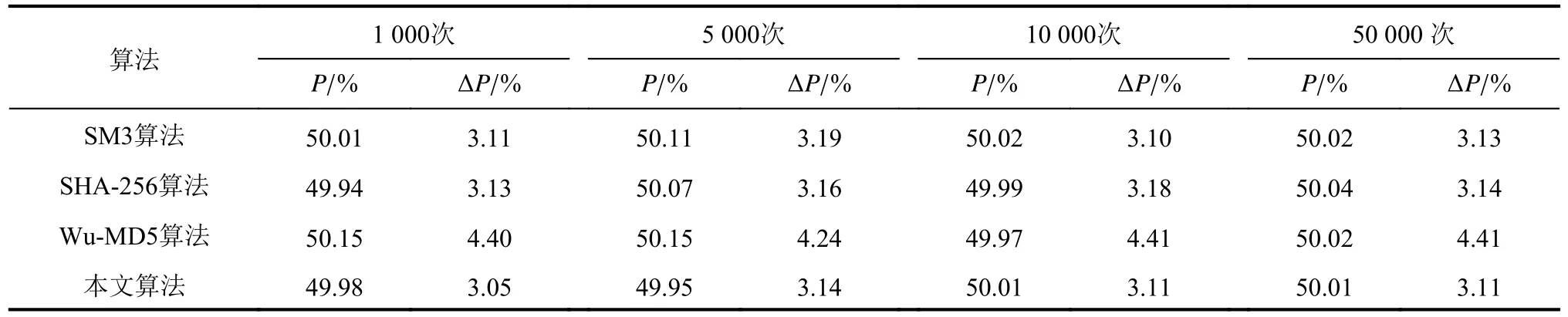
表1 不同测试次数下4种算法的雪崩特性统计Tab.1 Avalanche characteristics statistics of four algorithms under different test times
表1结果表明:在测试总次数N分别为1 000、5 000、10 000和50 000的情况下,本文算法与其他3种算法的雪崩系数P均接近50%,达到了杂凑函数雪崩效应的理想状态,说明本文算法拥有良好的混淆和扩散性;同时,本文算法的均方差 ΔP的数值偏小,充分说明本文算法具有稳定的雪崩效应。
3.1.2 信息熵分析
熵反映了信息源的平均不确定性,在密码学领域内,信息熵也是用于衡量信息序列随机性的一项重要指标。信息序列的随机性越大,熵值越大;信息序列的随机性越小,熵值越小[26]。一般熵值的大小也与攻击者分析杂凑算法的规律性所需要的时间成正比。利用熵值的大小来度量纠错码构建的改进密码杂凑算法的安全性。熵的计算公式为:
式中,H(x)为 消息x的 信息熵,p(xi)为 消息中xi出现的概率。
针对第2节中生成矩阵G6×32分别进行循环左移5、6、7位操作,输入长度为20~500 byte的样本数据,计算在输入数据相同时的杂凑值信息熵,如图1所示。由图1可以看出,循环左移6位时信息熵数值更高,相对于循环左移5、7位稳定性更好,而循环左移操作的目的是增大比特之间的无规律性,说明构造的加法常数值符合算法设计最初指标,即达到随机性和无规律性最大化,提升了杂凑值随机性。
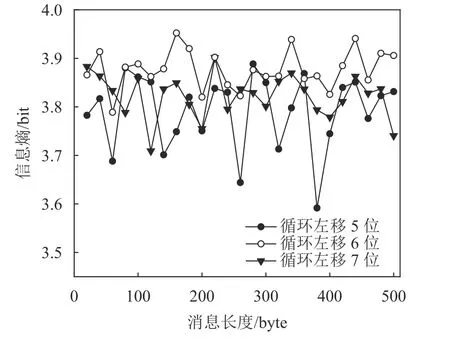
图1 本文算法中不同循环左移位数的信息熵比较Fig.1 Information entropy comparison of different cyclic left shift numbers in the proposed algorithm
为了评估本文算法的杂凑值随机性,在明文样本相同的情况下,选择典型的密码杂凑算法进行杂凑值的信息熵对比实验,具体标准为:1)本文算法是基于SM3算法的改进杂凑算法,所以选择SM3算法进行对比;2)在杂凑值长度都为256 bit的情况下,选择SHA-256算法进行对比。不同算法的杂凑值信息熵对比实验结果如表2所示。

表2 本文算法、SM3算法及SHA-256算法的杂凑值信息熵比较Tab.2 Comparison of information entropy between the proposed algorithm, SM3 algorithm and SHA-256 algorithm
表2表明:在迭代结构相似的情况下,本文算法因为选择纠错更强的最优码 (n,k,dmin)来构建加法常数表,杂凑值的熵值相对于 SM3算法有所增加;在杂凑值长度相同的情况下,由于本文算法迭代结构包含消息双字介入等方法,使得轮函数复杂性提升,消息能够快速扩散,从而导致最终生成杂凑值的信息熵值更高,随机性更强。以上结果表明,本文所构造的SM3改进算法利用纠错码技术有效平衡了杂凑值长度和迭代结构两个方面,使得算法杂凑值随机性有所提升,能够更好地隐藏明文消息和杂凑值之间的关联性。
3.2 性能分析
一般来说,密码杂凑算法的运算效率及内存损耗是需要研究人员考虑的重要方面,在配置为Intel Core i5-9400 2.90 GHz、16 GB RAM的计算机上,进行改进算法与传统SM3算法的时间效率及内存损耗的对比实验,并进行分析。
3.2.1 运算效率分析
利用 Java 1.8.0_291进行算法运算效率测试。针对不同明文消息长度的输入,分别选择本文算法与SM3算法进行效率分析,如图2所示。
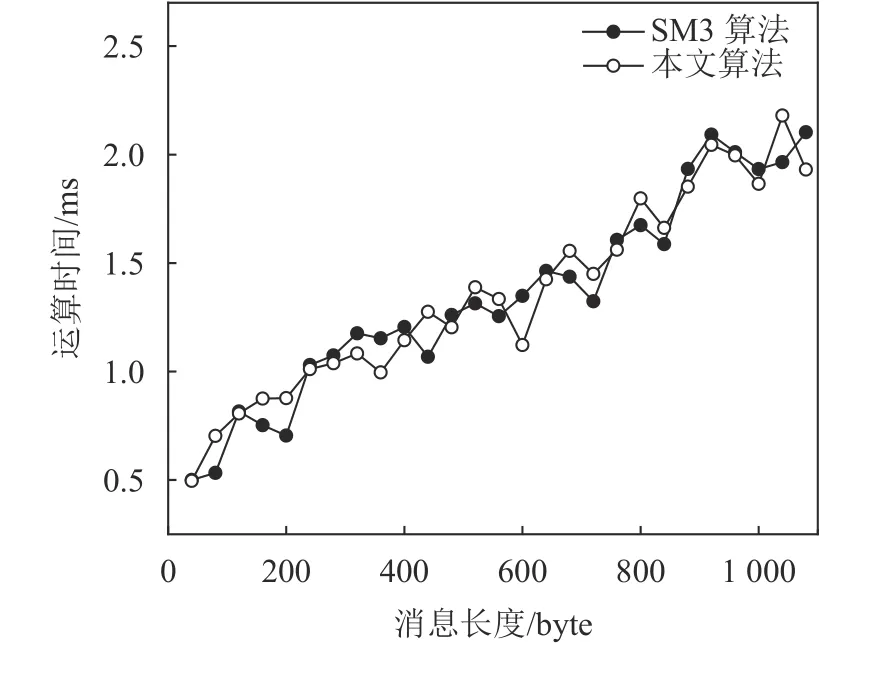
图2 本文算法与SM3算法时间复杂度比较Fig.2 Comparison of time complexity between the proposed algorithm and SM3 algorithm
由于迭代结构的串行特性,明文消息长度和运行时间成正比,图2结果表明,本文算法可以支持算法快速运算,在输入明文消息长度为40~1 080 byte的条件下,1 s内可以进行450~2 000次运算,与SM3算法的运算效率基本一致。
3.2.2 内存消耗分析
JProfiler作为商业授权的Java性能剖析工具,具有对被分析对象影响较小、针对内存(memory)分析功能强大等特点,专用于分析Java SE、Java EE应用程序。利用JProfiler分析工具,针对不同长度的明文输入,选用30个明文样本集,对本文改进算法及SM3算法分别进行相同明文输入的内存损耗测试对比,结果如图3所示。
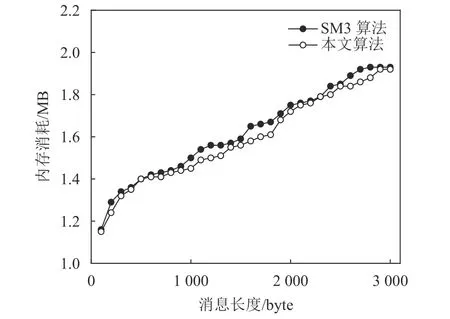
图3 本文算法与SM3算法内存损耗比较Fig.3 Comparison of memory loss between the proposed algorithm and SM3 algorithm
由图3可知:本文算法的内存损耗并不高,在明文输入长度为100~3 000 byte的条件下,随着消息长度的增加,计算量增大,导致内存损耗呈线性增长趋势;同时,由于本文利用纠错码来构造加法常数表,导致在消息长度相同的情况下,本文算法相比于SM3算法内存损耗降低0.01~0.07 MB,实现了性能优化。
基于纠错码的SM3算法是在传统SM3算法的基础上进行的改进。改进后的SM3算法不仅具有较强的雪崩效应,且具有更强的随机性,使攻击者更难找到其中规律。上述算法效率及内存损耗实验表明,本文改进算法在效率相同的情况下内存损耗有所下降,为高效率、低内存需求的应用场景提供技术参考。
4 结 论
为了提高杂凑值的随机性,本文利用纠错码可以在数字通信过程中提高可靠度的特性,提出一种对SM3算法的改进方案。该方案选择拟阵理论构建的线性分组码(32,6,16),通过生成矩阵G6×32计算有效码字,同时利用周期性原则选择8个码字构建初始常量值,并嵌入到迭代结构中进行64轮运算;从信息熵值和雪崩效应两个角度进行杂凑值稳定性和随机性评估,同时测试本文算法在运算效率和内存损耗的全局性能并进行分析。实验结果表明,本文算法具有理想雪崩效应的特性,生成的杂凑值相比其他密码杂凑算法混乱度有明显提高,使攻击者更难逆推出明文消息,具备更高的算法安全性。另外,本文算法在保留传统密码杂凑算法的串行迭代结构的前提下,能够在1 s内进行450~2 000次高速运算,且内存损耗与SM3算法相比降低0.01~0.07 MB,为信息安全领域的应用开发提供理论参考。在未来的研究工作中,将重点研究密码杂凑算法的迭代结构,尝试采用并行结构进行数据运算效率的优化,并且在区块链技术的底层架构来验证优化后算法的适用性。
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
湘潮(上半月)(2019年11期)2019-05-22
疯狂英语·新读写(2018年2期)2018-11-29
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
扬子江(2018年1期)2018-01-26
中国科技纵横(2016年20期)2016-12-28
电测与仪表(2016年12期)2016-04-11
通信电源技术(2016年5期)2016-03-22
河池学院学报(2014年5期)2014-02-27
