
我国医药制造业上市公司财务风险预警研究
2023-05-26 08:51:10古丽思
中小企业管理与科技·下旬刊 2023年4期
古丽思


【摘 要】在新冠肺炎疫情防控常态化背景下,我国医药制造业呈现良好的发展态势。医药制造业上市公司具有良好的投资价值,研究其财务风险将有利于投资者评估医药制造行业未来发展情况并进行投资决策。论文以我国A股医药制造业上市公司为研究对象,基于其偿债能力、盈利能力、营运能力、现金流分析、发展能力及风险水平6个维度构建财务风险预警评价指标体系,利用Stacking算法实现财务风险预警,并对比K-近邻、Logistic回归、决策树3种单一分类器的预测效果。结果表明,提出的Stacking算法整体性能明显优于其他模型,准确率、F1-Value及AUC值均高达98.5%以上。
【关键词】医药制造业;财务风险预警;Stacking;不平衡数据;递归特征消除
【中图分类号】F406.7;F832.5;F426 【文献标志码】A 【文章编号】1673-1069(2023)04-0164-03
1 引言
由于经济全球化的不断深入,使得资本市场的规模持续地扩大,企业之间贸易的频繁发生及企业经营环境的日趋复杂使得其很容易陷入财务风险当中。基于此,构建适合的财务风险预警机制是必要的,因为它可以预测企业可能将面临的危机并能及时化解。在已有的文献研究中,还没有文献研究我国医药制造业上市公司的财务风险情况,在后疫情时期,医药制造业上市公司能否抓住机遇,持续良好的发展态势需要进一步量化分析,对于投资者而言,在进行投资时亦存在较高的风险,对现有上市公司进行财务风险分析具有必要性。基于此,本文以A股医药制造业上市公司为研究对象,利用Stacking集成算法实现财务风险预警,并根据预测结果提出相应建议。
2 文献回顾
Ohlson(1980)采用Logistic算法构建预测公司破产的概率模型,结果证明公司规模、资本结构、经营状况和变现能力指标对公司破产具有显著影响。吴世农和卢贤义(2001)采用Fisher线性判定分析、多元线性回归和Logistic回归3种方法基于我国140家上市公司的21个财务指标数据分别构建3种财务风险预警模型,研究结果表明Logistic模型预测性能最优,误判率最低。杨淑娥和徐伟刚(2003)基于Altman提出的Z分数模型结合主成分分析法,以我国上市公司为研究样本,提出Y分数财务风险预警模型,研究结果表明Y分数模型具有良好的预测效果。郑茂(2003)以我国112家上市公司为研究对象,采用概率模型和Logistic模型构建相应的财务风险预警数学模型,研究表明我国上市公司的财务信息是有效的,具有较强的预测能力,且线性概率模型和Logistic模型对财务风险也具有较好的识别能力。宋彪等(2015)通过爬取60家企业的相关新闻、博客等网络数据构建大数据指标,结合其财务指标构建了更为全面的财务风险预警指标体系,并利用支持向量机(SVM)模型进行预测,研究结果表明引入大数据指标后模型预测效果短期内有所提升,长期有明显提高。
由上述分析可知,企业财务风险预警的方法已经由传统的统计类方法转向新兴的机器学习算法。基于此,本文拟初步选取反映医药制造业上市公司偿债能力、营运能力、盈利能力、现金流分析、发展能力和风险水平6个维度的35个财务比率指标构建了我国医药制造业上市公司财务风险预警指标体系,同时使用SMOTETomek综合采样算法以解决样本不平衡问题,在特征选择上,使用递归特征消除(Recursive Feature Elimination,RFE)算法根据随机森林(Random Forest,RF)拟合结果选择贡献度高的前15个特征,最后构建Stacking集成算法结合网格搜索构建财务风险预警模型。
3 研究设计
3.1 样本选取与数据来源
本文选取2022年我国A股317家医药制造业上市公司作为研究对象(根据证监会2012版行业分类),按照其是否被特别处理来划分是否财务风险预警,即将ST和*ST上市公司视作高财务风险企业(即需财务风险预警),非ST上市公司视作低财务风险企业(不需财务风险预警)。在本文研究的317家上市公司中,高财务风险企业数量为9家,低财务风险企业数量为308家。选取317家企业2015年至2022年的财务数据进行实证研究,数据来源于CSMAR数据库中公司研究系列栏目。
3.2 医药制造业企业财务风险预警指标体系构建
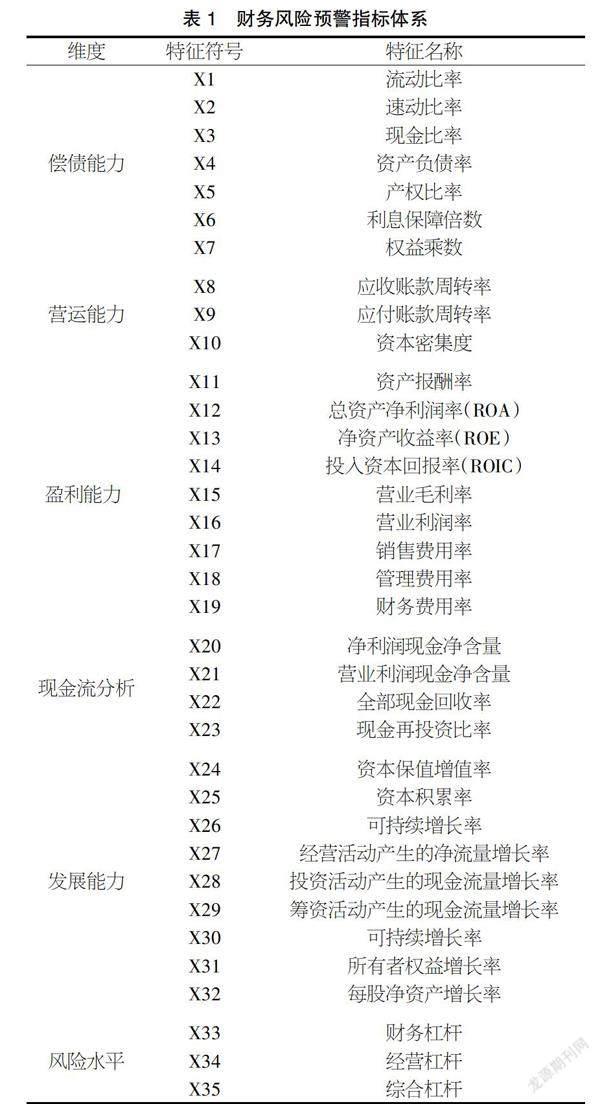
在变量选取层面,本文在前人大量研究的基础上,结合我国医药制造业上市公司财务风险成因初步选取反映企业偿债能力、营运能力、盈利能力、发展能力、现金流分析和风险水平6个维度累计35个财务指标构建了我国医药制造业上市公司財务风险预警指标体系,如表1所示。
3.3 数据预处理
本文首先对现有35个特征进行缺失情况统计,对缺失比例超过20%的特征进行剔除;对缺失比例5%~20%的特征采取以该特征的分布边缘值进行填充,其分布边缘值计算见式(1);对缺失比例低于5%的特征采取以各企业该特征字段的均值进行填充。同时,对重复样本数据进行剔除,最后对数据进行归一化处理。
padding values=mean+3×std (1)
其次,可以看到样本数据极度不平衡,正负样本比例约为1∶30,为解决样本非平衡的问题,利用SMOTETomek综合采样算法,实质是SMOTE过采样算法结合Tomek Link欠采样算法实现在通过SMOTE方法对少数类样本进行过采样后进行样本的清洗,剔除了部分由于过采样产生的噪音数据。具体而言,SMOTETomek综合采样算法判定噪声数据的主要思想是当找不到第三个样本到某两个样本的距离低于两个样本间距离时,就认为两个样本中有一个为噪声数据。在剔除噪音数据后,有利于后续模型的训练,且在经过SMOTETomek综合采样算法处理过后,正负样本比例为1∶1。
3.4 特征筛选
在特征选择层面,本文采用递归特征消除(Recursive Feature Elimination,RFE)算法,通过给定其随机森林(Random Forest,RF)算法进行拟合,根据特征重要性移除权重比较低的特征,并重新拟合模型,重复此过程,直至指定数量的特征被保留下来。本文设定最终保留15个特征,算法输出结果为保留流动比率、资产负债率、产权比率、权益乘数、应付账款周转率、资本密集度、总资产净利润率(ROA)、净资产收益率(ROE)、营业毛利率、销售费用率、管理费用率、财务费用率、财务杠杆、经营杠杆、综合杠杆。
3.5 Stacking算法设计
机器学习作为人工智能的一个分支,涉及数理统计、概率论、计算机原理等多门学科。随着现代网络信息技术的快速发展,机器学习逐渐在金融、医疗等众多领域得到了广泛的应用,并取得了一定的成果。机器学习分为监督学习、半监督学习、无监督学习和强化学习4类。其中,监督学习(Supervised Learning)主要解决分类和回归问题,如垃圾信息分类、新闻情感分类、房价预测等问题。其特点是采用有标签的数据进行模型训练和测试,而本文的财务风险预测即适用于监督学习算法。集成学习(Ensemble Learning)是通过某种策略将多个个体学习器结合而得到的一个强学习器,通常较单个分类器具有更好的学习效果。Stacking是一种机器学习集成算法,其通过将多个模型组合在一起进而构成一个性能更优的单一模型。其将原始数据输入多个模型中(亦称初级学习器)进行训练,再将每个模型的预测结果作为新的特征输入一个新的模型当中(亦称次级学习器),最后得到最终预测结果。本文利用K-近邻算法(K-NearestNeighbor,KNN)、支持向量机算法(Support Vector Machine, SVM)和决策树算法(Decision Tree,DT)作为初级学习器,利用逻辑回归模型(Logistic Regression,LR)作为次级学习器构建Stacking集成模型。同时,本文结合网格搜索对模型进行调优。
4 实证分析及结果
4.1 评估指标
在样本非平衡情况下,衡量模型性能的好坏更重要的是尽可能将全部财务风险高的企业识别出来,即更注重模型将高财务风险企业找出的正确率。本文使用准确率(Accuracy)、查全率(Recall)、查准率(Precision)、F1-Value及AUC值对本文所构建的财务风险预警模型进行性能评估。上述指标都可基于混淆矩阵计算而来,下面对混淆矩阵进行具体说明。定义TP表示真正例,即实际为正样本且被预测为正样本的个数;FP表示假正例,即实际为负样本但被预测为正样本的个数;TN表示真负例,即实际为负样本且被预测为负样本的个数;FN表示假负例,即实际为正样本但被预测为负样本的个数,而混淆矩阵即由这4个指标所构成的矩阵。基于此,可得准确率、查全率、查准率的计算公式依次为:
由式(2)~式(4)可知准确率指模型预测正确的样本数占样本总数的比例;查全率指实际为正例的样本中模型找对的比率,即衡量模型找回正样本的能力;查准率指模型预测为正例的样本中实际正例所占比率。而往往查全率和查准率是矛盾的,一个高另一个就低,那么为了同时考虑到查全率和查准率,就引入了F1-Value指标,其是查全率和查准率的调和平均数,计算公式如下:
AUC指ROC曲线下的面积,对比准确率、查全率、查准率、F1-Value 4个指标,其能够反映当给模型不同的分类阈值时模型的不同性能表现情况。同时,AUC具有对不平衡数据不敏感的优势且AUC指标也易与随机猜想的结果进行比较,能较好度量模型的性能,AUC值介于0.5到1之间,AUC值越大说明模型性能越好,当AUC值小于等于0.5,即说明模型结果与随机猜想一样甚至更差,说明模型没有预测价值。
4.2 模型结果分析及比较
本文按8∶2划分训练集和测试集,将训练样本数据输入本文所构建Stacking模型进行模型训练,在测试集上进行预测得到预测结果,并與KNN、Logistic回归、决策树3种模型预测性能进行对比,得到这4种模型的输出结果(见表2),发现本文构建的Stacking集成模型性能最优,在准确率、查全率、查准率、F1-Value及AUC值上都明显优于其他3种模型。
进一步分析并进行可视化,得到图1。
5 结语
本文以我国A股317家医药制造业上市公司为研究样本,结合其财务信息构建了我国医药制造业上市公司财务风险预警指标体系,采用了SMOTETomek综合采样算法实现了样本均衡,在数据清洗层面,以企业为单位进行分组填充缺失值等,使用了递归特征消除(RFE)算法来进行特征筛选,最后构建了Stacking集成算法进行财务风险预警。通过实证分析,得出结论:本文所提出的Stacking集成学习算法较K-近邻、决策树、Logistic回归这种单一分类器具有更好的准确率、F1-Value及AUC值等,其对于机器学习、深度学习在我国医药制造业上市公司财务风险预警的应用方面具有一定意义。
【参考文献】
【1】Ohlson J A.Financial Ratios and the Probabilistic Prediction of Bankruptcy[J].Journal of Accounting Research,1980,18(1):109-131.
【2】吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001(06):46-55+96.
【3】杨淑娥,徐伟刚.上市公司财务预警模型——Y分数模型的实证研究[J].中国软科学,2003(01):56-60.
【4】郑茂.我国上市公司财务风险预警模型的构建及实证分析[J].金融论坛,2003(10):38-42+50.
【5】宋彪,朱建明,李煦.基于大数据的企业财务预警研究[J].中央财经大学学报,2015(06):55-64.
