
基于ERNIE+DPCNN+BiGRU 的农业新闻文本分类
2023-05-24 03:18杨森淇段旭良郎松松李志勇
计算机应用 2023年5期
杨森淇,段旭良*,肖 展,郎松松,李志勇
(1.四川农业大学 信息工程学院,四川 雅安 625014;2.四川农业大学 农业信息工程实验室,四川 雅安 625014)
0 引言
随着我国农业的快速发展,人们对农业新闻的质量提出了更高的要求,但因农业领域因涵盖面广、涉及产业众多,农业信息的获取仍存在针对性较差、分类不清等问题,人们需要花费大量时间甄别出所需的农业新闻,极大地阻碍了农业新闻的传播。
目前中文新闻分类最著名的数据集是THUCNews(THU Chinese Text Classification)[1],它包含74 万篇新闻文档,涉及体育、财经、房产、教育和科技等14 类新闻,但唯独没有农业新闻。农业新闻的分类在中文新闻分类领域目前仍处于起步阶段,如何精准、高效地实现农业新闻文本分类,为用户提供精准的农业新闻,提高农业新闻传播的效率,扩大农业新闻的传播范围,成了目前亟待解决的问题。
1 文本与新闻分类模型
1.1 针对不同领域新闻的分类模型
文本分类模型的更新进展较快,如Wang 等[2]提出了一种用于文本分类的归纳图卷积网络(Inductive Graph Convolutional Network for Text classification,InducT-GCN),该网络仅基于训练文档的统计数据构建图,并用词向量的加权和来表示文档向量。InducT-GCN 在测试期间进行单向图卷积网络(Graph Convolutional Network,GCN)的传播,能降低时间和空间复杂度,InducT-GCN 在5 个文本分类基准中取得了最好的效果。Wang 等[3]将多维边缘嵌入图卷积网络(Multi-dimensional Edge-enhanced Graph Convolutional Network,ME-GCN)用于半监督文本分类,通过构建文本图描述文本之间的多维关系,并将生成的图送入ME-GCN 训练,它可以整合整个文本语料库的丰富图边信息源。实验结果表明,ME-GCN 在8 个基准数据集中显著优于最先进的方法。Yang 等[4]提出了混合经典量子模型,由一种新颖的随机量子时间卷积(Quantum Temporal Convolution,QTC)学习框架组成,该框架取代了基于BERT(Bidirectional Encoder Representation from Transformers)的解码器中的一些层。实验结果表明,BERT-QTC 模型在Snips 和ATIS 口语数据集中获得了较好的结果。
新闻分类是文本分类的一个分支,文本分类技术自然也被应用到新闻领域[5],针对新闻分类的研究日益增多,很多学者都提出了针对新闻分类的模型。谢志峰等[6]针对财经新闻提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的中文财经新闻分类方法,通过CNN 对中文财经新闻进行分类,在大、小规模的财经语料上都表现优异。许英姿等[7]针对物流新闻分类提出了一种基于改进的加权补集朴素贝叶斯物流新闻分类的方法,针对文本不均衡的情况,加权补集朴素贝叶斯模型在进行新闻分类时更加快速和准确。朱芳鹏等[8]针对船舶工业领域新闻构建了一个船舶工业新闻语料库,并提出了基于文档频率、卡方统计量及潜在语义分析(Latent Semantic Analysis,LSA)进行特征选择和特征降维,将文档-词矩阵映射成文档-主题矩阵后,最终对处理后的特征采用支持向量机(Support Vector Machine,SVM)进行文本分类的方法。实验结果表明,该方法能够有效解决文本向量的高维度、高稀疏性问题,在小样本集和类别有限的前提下获得了比传统方法更好的分类效果。李超凡等[9]为了解决中文电子病历文本分类的高维稀疏性、算法模型收敛较慢、分类效果不佳等问题,提出了一种基于注意力机制(Attention mechanism)结合CNN 和双向循环神经网络的模型。该病历文本分类模型对比实验的结果表明,该模型的F1 值达到了97.85%,有效地提升了病历文本分类的效果。目前国内农业新闻分类的模型还较少,其中霍婷婷[10]提出了一种基于FastText 对“重要词进行加权筛选”和“融合新闻标题”的模型CFT-FastText(Content Feature and Title Fast Text)应用于农业新闻文本分类,通过对特征增强的序列进行加权筛选,再融合提出的CFT-FastText 算法,可以获得更好的农业新闻分类效果。
农业文本与其他类别文本相比,具有长度较短、文本间较为类似、特征不突出,并且维度较高、稀疏性较强等特点,容易区分不开。例如“在山区如何养野鸡”和“在山区如何捉野鸡”这两个只有一字之差的农业新闻标题,前者属于畜牧业,而后者属于副业。针对农业文本的特点,不同作者提出了不同的解决办法。如金宁等[11]运用词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法对农业文本的特征进行扩展,并采用Word2Vec(Word to Vector)模型训练分词结果,将农业文本转为低维、连续的词向量,实现了农业问答社区中农业问句的精确快速分类;王郝日钦等[12]提出了一种基于CNN 和注意力机制的水稻文本分类方法,根据水稻文本具备的特征,采用Word2Vec 方法对文本数据进行处理与分析,并结合农业分词词典对文本数据进行向量化处理,有效地解决了文本的高维性和稀疏性问题。
1.2 基于BERT的新闻分类
目前,融合BERT 模型的新闻分类方法取得了较好的效果。BERT 模型是一种基于大量语料库训练完成的语言模型,生成的词向量拥有较多的先验信息、并且充分结合上下文语义等优点,因此被广泛应用于新闻分类领域。随后产生了一批基于BERT 进行改进的加强版模型,例如Liu 等[13]提出的RoBERTa(Robustly optimized BERT)模型是BERT 的改进版,具有训练时间更长、批量数据更大、训练序列更长等特点,并且加入了动态调整掩码机制,在GLUE(General Language Understanding Evaluation)、RACE(Large-scale ReAding Comprehension dataset from Examination)和SQuAD(Stanford Question Answering Dataset)上取得了当时最先进的成绩。哈工大讯飞联合实验室(HFL)的Cui 等[14]提出的MacBERT(MLM as correction BERT)模型在多个方面对RoBERTa 进行了改进,利用相似的单词掩码减小了预训练和微调阶段两者之间的差距,并在多个数据集上取得了较好的效果。
杨先凤等[15]针对传统文本特征无法充分解决一词多义的问题,利用BERT 字注释和双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)结合注意力机制提取特征。实验结果表明,在公开数据集THUCNews 上,该模型比未引入字注释的文本分类模型有明显提高。彭玉芳等[16]融合了中国图书馆分类法的族性检索和分面分类法的特性检索,构建了南海文献分类法,应用BERT 预训练模型实现细粒度的多标签南海证据性数据的自动分类,从更细粒度的视角实现数据分类,从而更有利于展开数据挖掘,找到数据间潜在的关联关系。张海丰等[17]提出了一种结合BERT 和特征投影网络的新闻主题文本分类方法,该方法将新闻类文本输入BERT 模型后,输出的特征再次进行多层全连接层的特征提取,并将最终提取到的文本特征结合特征投影方法进行提纯,从而强化分类效果。但是BERT 模型针对中文领域和其预训练模块仍有较多不足,在BERT 模型中,对文本的预处理都按照最小单位进行切分,在英文文本中掩码的对象多数情况下为词根,而非完整的词,对于中文则是按字切分,直接对单个的字进行掩码,这种方式限制了模型对于词语信息的学习。
1.3 基于ERNIE的新闻分类
BERT-Chinese-WWM(Whole Word Masking)模型[18]改进了中文处理的过程:首先对中文进行分词,在掩盖时将完整词语的所有字一并掩盖,便于模型对语义信息的学习。
百度发布的ERNIE(Enhanced Representation through kNowledge IntEgration)模型[19]则进一步扩展了中文全词掩盖策略,不仅包含了中文分词,还包括短语及命名实体的全词掩盖。国内也有学者利用ERNIE 进行新闻分类,如陈杰等[20]利用ERNIE 结合文本卷积神经网络(Text Convolutional Neural Network,TextCNN),通过领域预训练生成高阶文本特征向量并进行特征融合,实现语义增强,进而提升短文本分类效果。黄山成等[21]提出一种基于ERNIE2.0、双向长短时记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络和Attention 的隐式情感分析方法EBA(ERNIE2.0,BiLSTM and Attention),能够较好捕捉隐式情感句的语义及上下文信息,有效提升隐式情感的识别能力,并在SMP2019 公开数据集上取得了较好的分类效果。喻航等[22]利用ERNIE 结合TF-IDF针对区级人大报告特定的几方面内容进行文本分类,利用ERNIE 直接对语义知识单元进行建模,并且在此基础上加入TF-IDF 提升模型性能。实验结果表明,该方法在分类的准确率和召回率上表现不错,ERNIE 模型收敛速度得到了明显提升。
综上所述,为了避免BERT 在中文特征提取上的不足,以及目前国内在农业新闻分类领域的欠缺,采用ERNIR 结合深度金字塔卷积神经网络(Deep Pyramidal Convolutional Neural Network,DPCNN)和双向门控循环单元(BiGRU),提出EGC 模型。本文的主要工作包括:1)自建农业新闻数据集,对网络上真实存在的农业类新闻进行收集并清洗;2)在数据集上对比几组最经典的模型,并尝试了几种不同的激活函数,最终基于ERNIE、DPCNN 和BiGRU 提出EGC 模型。
2 EGC模型
为了提取更完整的特征,本文EGC 模型由3 个模型融合构成,包括ENIRE、BiGRU 和改进DPCNN。
2.1 ERNIE
ERNIE 是基于谷歌公司研发的BERT 模型,原生的BERT 用在中文上时是基于单个字的,忽略了文字的联系,而ERNIE 可以很好地捕捉文字之间的关系。以“越南巴沙鱼出口仍未走出困境”为例,BERT 和ERNIE 的掩码策略对比如图1 所示,ERNIE 加入了前后文本的联系,更容易推理出被掩盖掉的文字。当使用原生BERT,会随机掩码15%的文字,BERT 不会考虑上下文的联系,导致一个词被分开,不易推理出被掩盖掉的文字;而ERNIE 的掩码策略会考虑文字之间的关系,会以词来进行掩码,能够更容易推理出被掩盖的文字。
ERNIE 的核心 部分是Transformer-encode[23],如 图2 所示。数据输入后,经过编码和添加位置信息,利用多头注意力机制进行计算,通过归一化以及前向传播和再次归一化,从多头注意力机制到再次归一化构成一个层,经过N个这样的层,输出编码。

图2 Transformer-encode结构Fig.2 Structure of Transformer-encode
2.2 BiGRU
循环神经网络(Recurrent Neural Network,RNN)是自然语言处理任务中的一个重要方法,与CNN 相比,它的最大优势是能够提取到上下文的文本特征,在处理序列问题时优势明显。Hochreiter 等[24]提出了长短时记忆(Long Short-Term Memory,LSTM)网络,LSTM 在记忆上下文重要信息的同时,会遗忘掉无关信息,解决了RNN 反向梯度消散等问题;但LSTM 计算量比较大,训练时间过长。针对LSTM 的不足,Cho 等[25]提出了门控循环单元(Gated Recurrent Unit,GRU),对LSTM 进行简化,结构如图3 所示。
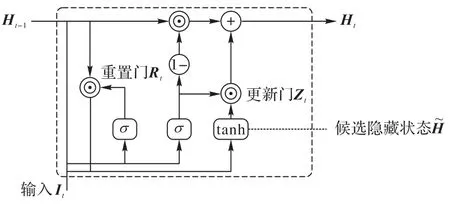
图3 GRU结构Fig.3 Structure of GRU
其中:Zt表示更新门;W表示权值矩阵;Ht表示t时刻的隐藏层状态;xt表示t时刻的输入;Rt表示重置门。
但单向的GRU 只提取了上文对下文的影响,无法反映出下文对上文的影响。为了充分提取每个新闻标题的特征,采用BiGRU,它每步的输出由当前状态的前向状态和后向状态组合而成,可以提取更加完整、丰富的特征信息。BiGRU结构如图4 所示。
图4 BiGRU结构Fig.4 Structure of BiGRU
2.3 改进DPCNN
Johnson 等[26]提出的DPCNN 的核心是等长卷积和1/2 池化层,等长卷积的输入和输出都为n,而1/2 池化层令每次输入的序列长度减半,随着层数的加深,将长度叠起来,最终会呈现一个金字塔形状。
针对农业新闻标题的特点,本文对DPCNN 进行改进,提出DPCNN-upgrade。根据计算,农业类新闻数据集平均长度大概在18.98,农业新闻标题要比其他新闻短一些,针对该特点,将DPCNN 的卷积层减少2 个,以保留更多的文本特征,达到了更好的效果。
DPCNN 与DPCNN-upgrade 的对比如图5 所示,数据输入后经过Region embedding,将数据转化为句向量表示,然后将这些特征向量依次输入到后面的卷积组,每个卷积组包含1个卷积层以及从输入到输出的残差相连。每个组之间由步长为2 的池化层相连接,可以设置多个卷积组来提取特征,直到最后的卷积组得到最终文本的特征向量表示。

图5 DPCNN和DPCNN-upgrade对比Fig.5 Comparison between DPCNN and DPCNN-upgrade
2.4 EGC模型结构
一些可用于文本分类的先进模型,如ChineseBERT,RoBERTa 和MacBERT,它们进行了一些基于BERT 的调整,如更改掩码策略、增大batch size 或者将字形考虑进特征范围内等,这些调整虽然在一定程度上提升了训练的效果,但针对农业新闻的高维度和稀疏性特点,效果有限。针对农业文本特征较少、文本间较为类似、特征不突出、维度较高、稀疏性较强等问题,本文的EGC 模型将DPCNN-upgrade 与BiGRU 提取出的特征进行融合,以降低特征的稀疏性并降低特征维度,融合后的特征更准确,能有效提高农业新闻分类的准确度。EGC 模型结构如图6 所示,主要包括输入编码层、特征提取层、特征融合层和Softmax。

图6 EGC详细框架Fig.6 Detailed framework of EGC
1)输入编码层。数据集输入后,经过ERNIE 的掩码机制,embedding 过后,输入transformer encode,将数据集转化为编码。
2)特征提取层。将编码后的数据分别输入DPCNNupgrade 和BiGRU 两部分进行特征提取。
数据输入到DPCNN-upgrade,经过一个卷积层后,与没经过卷积层的数据进行拼接操作,然后输入循环模块;接着依次经过1/2 池化层和卷积层,再将池化后的数据和卷积后的数据进行拼接,并不断循环这个模块N次;循环结束后,将数据进行一次池化得到最终的特征。
为了得到BiGRU 部分的特征,将数据输入到GRU 中,每个位置上有两个反方向的GRU,通过将信息不断传递,分别汇总前向和后向信息,最终将每个位置上的两个GRU 的汇总信息进行拼合,组成该数据的特征。
3)特征融合层。将DPCNN-upgrade 提取出来的特征和BiGRU 提取出来的特征进行拼接,组成最终的特征。
4)Softmax。利用Softmax 对拼接后的特征进行全链接,从而得到最终类别的概率[27],进一步输出最终结果。
3 实验与结果分析
3.1 数据集
由于目前没有公开的新闻,需要采用自建数据集,本实验所用的农业数据集利用八爪鱼软件[28]在中国畜牧网、海洋资讯网、西南渔业网、中国农业网、中国大豆网和中国油脂科技网等农业新闻网站进行数据爬取。数据时效性对保证数据质量至关重要[29-31],因此我们从2022 年4 月开始采集最新数据,并进行去除停用词、标点符号等操作的预处理,以保证数据的可用性和质量。数据集总量为20 834,各类别具体情况如表1 所示,其中训练集、测试集和验证集的比例为8∶1∶1,数据集的句子的平均长度为18.98。
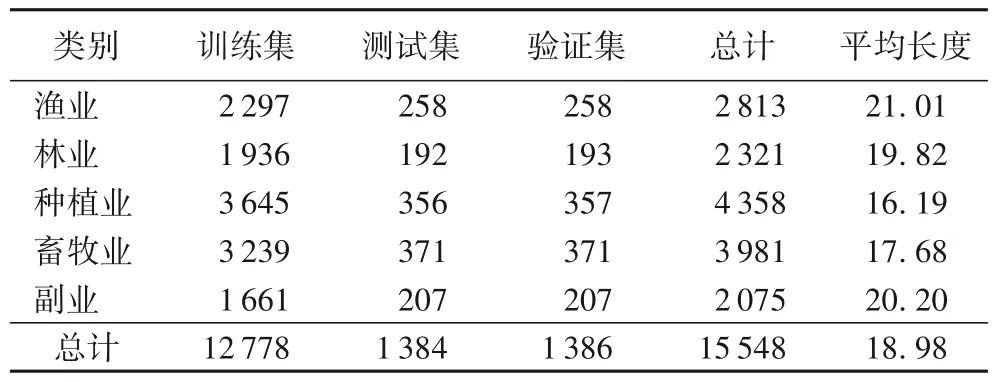
表1 数据集各类别数量Tab.1 Number of each category in dataset
3.2 评价指标
评价指标使用精确率P(Precision)、召回率R(Recall)和F1 分数F1(F1-score)[26],计算公式如下:
其中:TP(True Positive)表示将正类预测为正类数;FN(False Negative)表示将正类预测为负类数;FP(False Positive)表示将负类预测为正类数;TN(True Negative)表示将负类预测为负类数。
宏平均(Macro-averaging)[31]在很多项目中经常被使用,但是针对农业新闻数据集有些不适用。原因在于农业新闻数据集中每个类别所占比重不同,且数据集之前的数量差距较大,林业、副业新闻数据较少,所以采用权重平均(Weighted-averaging)[32]更客观。权重平均是所有类别的F1加权平均,公式如下:
其中:n为类别数,ki为类别i占数据集总数的比例。
3.3 实验参数
序列长度设置为19,学习率为10-5,ENIRE 隐藏层数量为768,BiGRU 隐藏层数量为256,dropout 设置为0.1。
3.4 模型对比
针对农业新闻利用不同的模型做了多组实验,包含基础的BERT、较为先进的模型RoBERTa 和MacBERT,以及BERT+CNN、BERT+RNN、BERT+DPCNN、ERNIE、ERNIE+DPCNN 和ERNIE+BiGRU,激活函数为线性整流函数(Rectified Linear Unit,ReLU)[33],结果如表2 所示,其中:加粗为最优结果,下划线为次优结果。由表2 可以看出,EGC达到了最好的效果,要全面优于其他对比模型,在精确率、召回率和F1 分数上比次优结果分别提高了1.33、1.11 和1.21个百分点,比ERNIE 分别提高了1.47、1.29 和1.42 个百分点,这得益于EGC 大幅降低了农业文本的稀疏性和高维度特征。
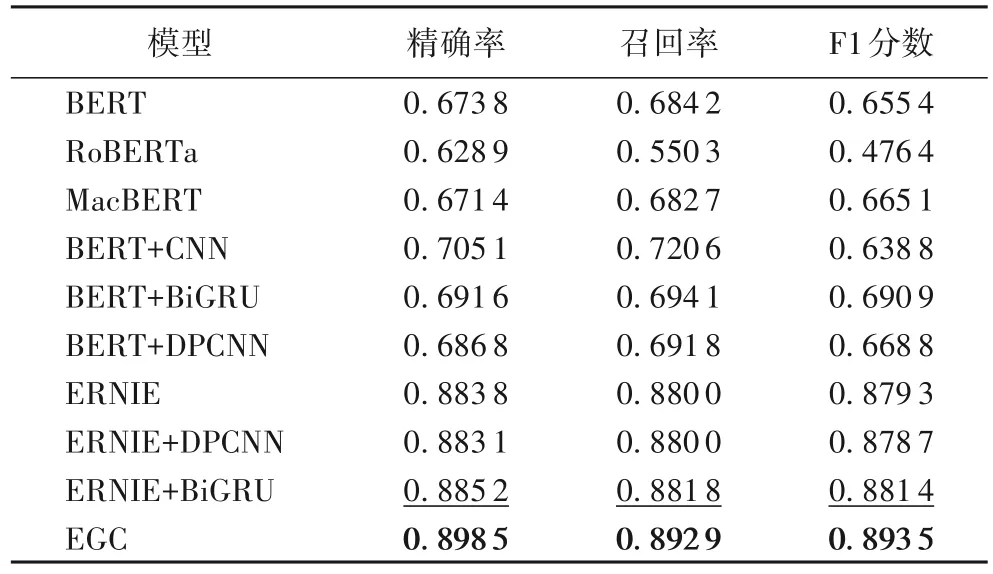
表2 不同模型的加权平均指标的比较Tab.2 Comparison of weighted-average indicators of different models
为了探索不同激活函数对EGC 模型的影响,进一步尝试使用ReLU[33]、带泄露修正 线性单元(Leaky ReLU)[34]、RReLU(Reflected ReLU)[35]和PReLU[36]进行实验,结果如表3所示。可以看出,针对农业新闻文本的分类,使用RReLU 的实际效果更好,相较于ReLU 提升了0.99 个百分点。
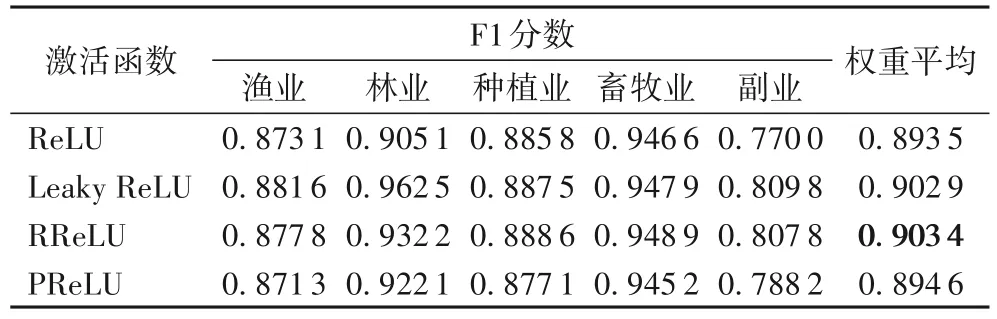
表3 四种不同激活函数的性能对比Tab.3 Performance comparison of four different activation functions
4 结语
随着农业现代化的不断发展,农业新闻的传播显得尤为重要,准确的新闻分类可以提高新闻传播的效率。本文利用新闻的标题信息,提出基于ERNIE、DPCNN 和BiGRU 的EGC模型,与传统模型相比,综合性能更好,可为精确分类农业新闻提供理论方法支持。
但农业新闻中的副业分类难度较大,因为近些年的研究方法都是基于深度学习,而副业中包含的类别较多,比如糖业、食用油、纺织业、药材采集、手工副业等,数据集的分配将显著影响副业的分类,若出现一些只在测试集中出现的数据,准确率将明显降低,而且目前还缺乏副业的详细分类规范。因此,在接下来的研究中,我们将进一步研究副业的细分化,以进一步提高分类准确率。
目前关于农业新闻的数据集还较少,但随着自媒体的逐步发展,今后可考虑爬取自媒体来源的新闻。
EGC 模型目前仅考虑了农业新闻的标题,并未考虑新闻的主体和文中配图,今后可以考虑结合多模态数据以提取到更多的特征,进一步提高数据分类效果。
EGC 模型对算力有一定的要求,在接下来的研究中,可以精简模型,加快训练过程。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年11期)2019-07-04
通信学报(2019年5期)2019-06-11
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
通信技术(2018年3期)2018-03-21
初中生世界·七年级(2017年9期)2017-10-13
浙江大学学报(工学版)(2015年4期)2015-03-01
