
基于对象代理的大数据共享可信数据湖平台
2023-05-23 15:06杨文哲郝渊科赵常胜杨先娣彭智勇
小型微型计算机系统 2023年6期
杨文哲,郝渊科,赵常胜,宋 伟,杨先娣,彭智勇
1(武汉大学 计算机学院,武汉 430000)
2(武汉大学 大数据研究院,武汉 430000)
1 引 言
随着大数据时代的到来,科学发展正在迈入到一个新阶段,科学研究的方法逐步推进到数据密集型科研.作为具有巨大开发利用潜力的战略资源,科学数据正逐渐成为推动国家科技创新发展和经济社会发展的重要驱动[1].2018年国务院办公厅印发《科学数据管理办法》,其中明确提出,建立科学数据管理系统是有关科研院所、高等院校在科学数据管理中的主要职责之一.随着越来越多的技术工具被利用到科研数据的存储、获取和共享活动,科学数据管理平台应运而生.高校作为科学研究的重要阵地之一,其科学活动所产生的研究数据规模量较大,且格式多样,包含了大量的结构化、半结构化和非结构化数据.并且通过对国内外科研数据平台发展现状的深入调研,充分了解了各类系统的模型构建、功能架构和优缺点之后,本文发现已有的科学数据平台都是基于关系数据库开发的,模型构建复杂;构造复杂查询时会产生较多的表连接操作,查询效率低下;数据重复存储会带来大量冗余,占用存储空间.为了解决上述问题,打破不同领域之间数据难以互通的数据孤岛问题,更好地支持各科研领域海量异构数据的存储和管理,本文在数据湖架构的支持下,基于对象代理数据模型设计了一个支持多源异构数据存储、个性化数据管理和数据安全去重的新架构数据共享可信数据湖平台,从而推动各学科领域数据的开放、交流和共享.
2 研究背景
2.1 数据湖
大数据时代,科学数据已经成为支撑科研创新发展的珍贵资产和战略资源.由于科研数据的数据量大、格式种类多样的特点,难以做到跨领域的数据集成和分析,更无法做到统一的查询,这会导致在数据存储过程中出现数据标准不一致的问题,影响上层的数据查询和集成分析.数据湖作为一个新兴的数据集中存储库逐渐得到了学者们的广泛关注.数据湖概念[2]由James Dixon在2010年在博客中首次提出.最初的数据湖指的是存储单一数据源中原始状态的数据集,但是单一来源数据湖的想法并没有被广泛接受,如今的数据湖[3]被定义为一个可大规模扩展的存储库,它以原生格式存储大量的结构化、半结构化和非结构化数据.数据湖的出现解决了学者在进行数据共享[4]时的以下问题:1)随着数据量的增加,存储和维护成本逐渐增加;2)科研数据种类多样、格式不一,需要一个集中存储库进行存储和管理;3)各研究领域数据缺乏互联互通,存在难以共享的问题.因此,本文在数据湖架构支持下,通过将数据进行脱敏处理后存储到由FastDFS[5]构建的数据存储库中,然后定义统一的元数据模型,利用对象代理数据模型进行统一的元数据存储,进而支持高效的数据查询和检索,并有效的推动数据共享.
2.2 科学数据平台现状
为了推动各学科不断提升科技创新能力,汇聚和整合各学科数据资源,有必要在推动科学数据分析和应用的基础之上,加快数据资源的开放、交流和共享.国内外对数据共享研究做了大量的积极探索[4],构建了越来越多的科学数据管理平台.国外著名的平台有美国麻省理工学院开发的 DSpace[6]、普渡大学基于HUBzero定制开发的PURR、密歇根大学自建开发的ICPSR[7]、美国康乃尔大学的 Fedora Commons、哈佛大学和麻省理工学院合作开发的Dataverse[8]等.国内各高校在研究数据开放和共享平台建设方面也做了许多积极探索,如复旦大学基于Dataverse开源项目开发的社会科学数据共享与交换平台、北京大学基于Dataverse开源项目设计的开放研究数据平台[9]、中国科学院的科学数据云平台、武汉大学图书馆基于DSpace建立了科学数据管理平台等等.但是上述介绍的数据管理与共享平台均存在一定的不足之处,下面本文以Dataverse为例分析这类平台的优缺点.
而国内研究主要是针对国外先进数据平台的通过深入分析上述科学数据管理平台模型构建复杂、查询效率低下、缺乏数据安全去重和个性化数据管理的问题.因此在数据湖架构的支持下,本平台利用分布式文件系统FastDFS等技术构建数据湖集中存储库,然后基于对象代理数据模型进行自底向上的建模,通过4种代理关系:选择、连接、合并和分组代理操作建立代理类,可以实现各项个性化数据空间平台的功能需求,并丰富各数据实体之间的语义信息;通过代理类的方式,以虚属性的方式进行部分或全部的继承,可在很大程度上减少数据存储消耗;利用基于路径导航的跨类查询能够避免大量的表连接操作,提高查询搜索效率.
3 预备知识
对象代理数据模型[10,11]是在面向对象数据模型基础上发展起来的.关系数据模型是目前最容易被人接受的数据建模方式,但是关系数据模型并不适用于复杂的数据模型,将数据规范化为表形式的过程会影响检索大型、复杂和分层结构数据的性能,需要大量连接条件才能从多个表检索数据.此外,关系表中外键的存在也会造成大量的存储数据冗余.对象代理数据模型将现实世界中客观实体表示成对象,通过定义代理对象来表现对象的多方面本质和动态变化特性.对象与代理对象之间通过双向指针相联系[12],因而能够大大提高复杂查询的效率.对象代理模型既具有关系数据模型的柔软性,又具有面向对象数据模型表现复杂信息的能力,因此能满足复杂科学数据管理的建模需求[13,14].由于对象代理数据模型在复杂建模方面的独特优越性,所以,本文所介绍的大数据共享可信数据湖平台基于对象代理数据模型建模,构建更符合多源异构科研数据存储和数据检索的高效平台.
定义1.(源类)每个数据对象都包含一个唯一的标识符,一些属性和方法,具有相同属性和方法的数据模式被抽象表示为源类.源类的形式化定义如下:
C=<{Oi},{Ti:ai},{Mi}>
1){Oi}表示对象的集合,称为类C的扩展;
2){Ti:ai}表示类C中对象的属性集;
3){Mi}表示类C中对象的方法集.
定义2.(源对象)源类中定义的属性和方法的实例化表示源对象.源对象的形式化定义如下:
“反思”包括两个方面的内容。一是反思写作过程对今后阅读活动的反拨作用。通过读写结合过程中对某一特定类型文章的语言现象、篇章结构和写作技巧的强化认知,使学生逐渐能够在阅读中快速自动识别各种语言模式,从而促进阅读能力的提高。二是学生通过网络平台评价、同学互评、小组讨论、教师指导等方式对自己习作中体现出来的思辨能力进行评估。按照思辨能力层级模型中的认知标准,即清晰性、相关性、逻辑性、深刻性、灵活性来评价自己的分析、推理、评价能力。按照文秋芳的思辨层级模型,这些反思活动的目的是培养学生的元思辨能力,即对自己的思辨计划、检查、调整与评估的技能。
O=
1)o表示对象O的对象标识符,可以唯一的表示一个对象;
2){Ta:a}表示对象O的属性集合,其中a和Ta分别表示一个属性的名称和类型.对象O的属性a的值表示为o.a,对于每个属性Ta:a都有读写两个基本方法,其中read(o,a)用于读取o.a;write(o,a,v)用于将O.a替换成新值v,这两个操作的形式化定义如下:
read(o,a)=>↑o.a
write(o,a,v)=>o.a:=v
注意,=>、↑和:=分别代表了激活、结果返回和赋值操作;
3){M}表示对象O所拥有的方法集合,用m表示方法名,p和Tp分别表示方法的参数名和参数类型.操作某个方法可以定义为:
apply(o,m,{p})
定义3.(代理类)代理类是源类的外延和扩展,它继承了源类的某些或全部属性和方法,同时,也可以定义自己的属性和方法.假设一个源类的形式为Cs=<{os},{Tas:as},{ms:{Tps:ps}}>,则其代理类的形式化定义如下:
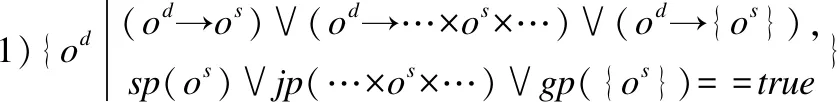
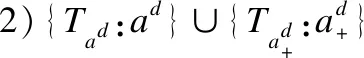
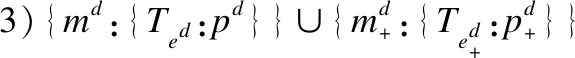
定义4.(代理对象)代理对象是源对象的扩展,它继承了源对象的某些或全部属性值和方法,同时也可以拥有自己的属性值和方法.假设源对象用os来表示,代理对象的形式化定义如下:
定义5.(实属性)代理对象追加的属性称为实属性,需要占用真实的物理存储空间.
定义6.(虚属性)代理对象继承自源对象的属性称为虚属性,并不实际存储其值,具体的数据依然存储在源对象的方法和属性中,通过双向指针获取属性值.
4 系统设计
4.1 模型设计
大数据共享可信数据湖平台数据建模采用对象代理数据模型进行开发,其数据库设计包括基本类设计以及继承自基本类的代理类设.基本类就是没有源类的类,它们是最基本的类,其所有的属性都是实属性,是各种代理类的代理基础.为了对各类数据进行合理存储,设计了两个基本类:数据文件类(File)、用户类(Tuser).上述两个基本类中的实属性存储了大部分的数据,对于其他实体的设计则可以通过代理类的方式,以虚属性的方式进行部分或全部的继承,并在此基础上根据需求进行扩展.这主要通过SELECT、UNION、GROUP 以 及 JOIN 4类代理关系来进行[11],如图1所示.通过灵活的代理类建模,可以实现各项个性化数据空间平台的功能需求及复杂查询需求,并丰富各数据实体之间的语义信息,减少存储空间的占用.
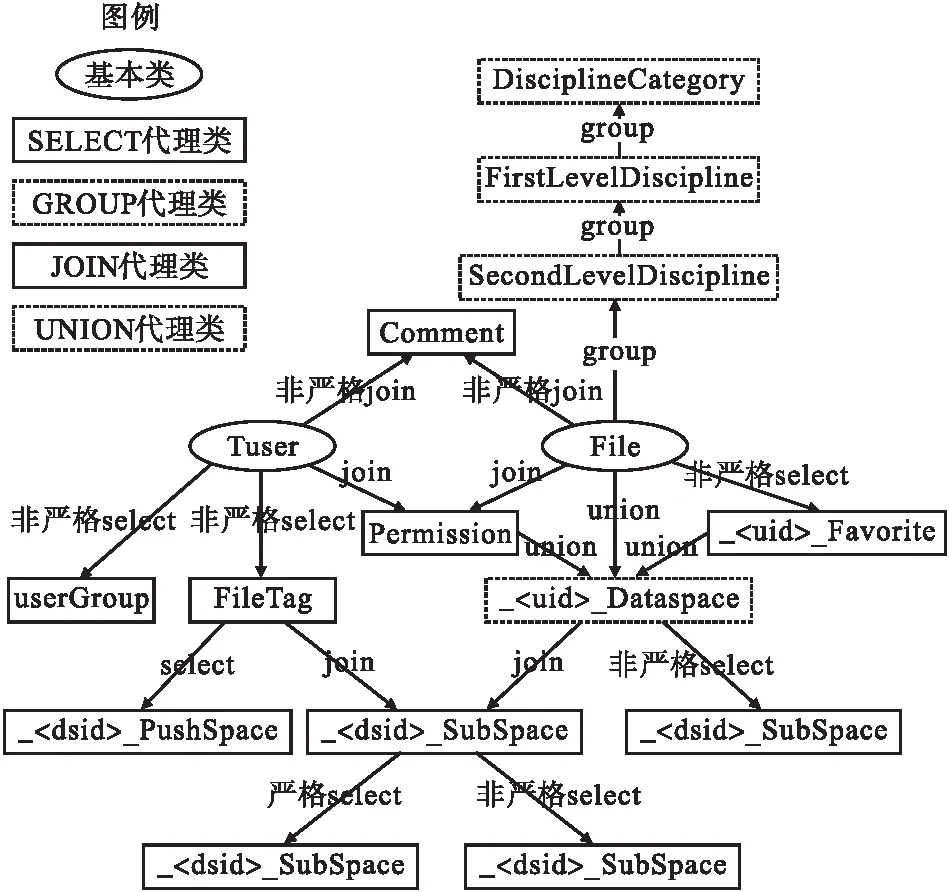
图1 对象代理数据模型
4.2 架构设计
平台采用分层架构,如图2所示,基础资源层中包含物理服务器设施,包括Web服务器、数据库服务器与文件服务器.Web服务器采用tomcat技术,保障了系统的高性能与高可用性;为了提高对数据库的访问效率,将数据库服务器和Web服务器部署于同一台物理服务器之中;文件服务器使用Nginx代理,通过专用的服务端软件对文件进行存取,保证安全性.平台使用开发框架Springboot、SpringMVC及Mybatis-Plus进行后端构建,对保存于对象代理数据库Totem中的元数据信息和文件系统FastDFS中的实际文件进行持久化操作.前端以Web界面的形式展示,采用开源框架Layui,并结合模板引擎FreeMaker进行编写.在软件应用层,平台提供了账户管理、权限管理、数据服务、数据空间管理及数据共享等功能,满足多样化的数据管理需求.
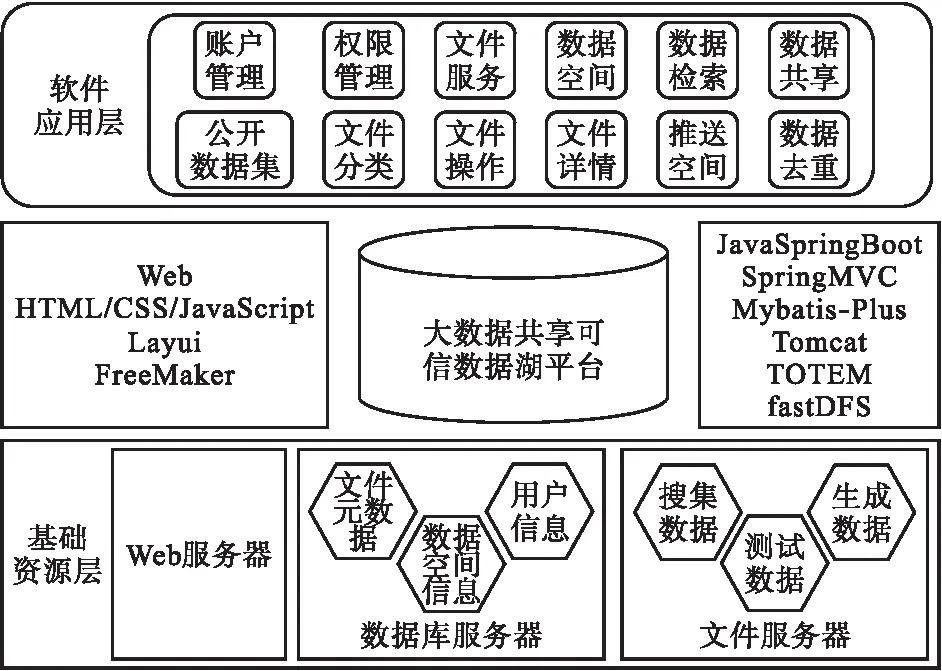
图2 大数据共享可信数据湖平台架构
4.3 特色功能设计
大数据共享可信数据湖平台分别基于对象代理数据模型、基于角色的访问控制(Role-Based Access Control,RBAC)[15]和数据分块技术设计了个性化数据空间管理、权限管理和数据安全去重[16]三大特色核心功能.
1)数据去重
大数据共享可信数据湖平台为了保证用户隐私和数据安全,在数据上传前需要对数据进行加密处理[17-19].然而,由于不同用户持有的密钥不同,相同的数据被加密成不同的密文,无法识别冗余数据并进行去重以节约资源.为了解决上述问题,本平台在用户上传数据时首先将数据转换为二进制数据,采用基于模式匹配的方式进行数据分块;然后通过计算完整数据与数据块的hash值,在文件系统中使用数据块的二次hash值作为指纹寻址;最后将数据hash值及每个块的hash值记录在数据库中.待用户上传数据时时,若数据hash值已存在于数据库中,则无需重复上传.对于不重复数据,计算每个数据块的hash值及二次hash值,记为hash′,并使用hash′作为该数据块的指纹.若某文件块的hash′已在文件系统中存在,则无需重复加密上传.而对于不重复数据块,则使用该块hash值作为该块的密钥加密并上传至文件系统中.当用户进行数据下载时,首先获取数据对应的数据块的哈希值,计算其hash′以下载数据块密文,使用hash值解密每个数据块密文后进行拼接以获取完整数据.由于无法通过二次hash值得到初始hash值,即无法获取数据块的密钥,因此上传的数据是安全的.利用该数据加密去重机制,能够在保证数据安全的前提下,较大程度上节约了数据存储所占用的内存资源.
2)权限管理
权限管理对于科学数据的共享是十分重要的,因此,大数据共享可信数据湖平台中设计了基于角色的访问控制,通过将权限授予给角色,角色授予给用户来实现.本平台设计了不可见、可查看和可编辑3个级别的权限,每个用户对于每个数据文件都具有其中一种权限.为了简化用户权限管理,减少系统的开销,采用RBAC来进行授权.在大数据共享可信数据湖平台中,将一个用户组即若干由组创建者所指定用户的集合设置为一个角色,数据文件上传者可以创建、编辑、删除多个用户组,并直接对用户组进行授权.
3)个性化数据空间管理
个性化数据空间管理是大数据共享可信数据湖平台管理的核心功能之一,用户可以通过创建数据空间对数据文件进行个性化的组织与分类.平台中定义了4类数据空间:根数据空间、严格数据空间、非严格数据空间以及推送空间.每个用户初始默认拥有一个根数据空间,当用户上传数据文件、从公开数据集中收藏数据文件以及被其他用户授予某数据文件的可查看或可编辑权限时,这些该用户强相关的数据文件会被自动添加到根数据空间之中.一个严格的数据空间主要用于数据的自动分类,如果源类中的对象符合严格代理条件,则会自动代理至严格数据空间中.该类数据空间中数据文件的添加删除会在指定文件标签后由平台自动进行而无需用户手动操作,大大增加了操作的便捷性.然而,用户也可能会有自定义数据空间中数据文件的需求,比如用户可能会想不同标签的文件组织到一个数据空间中,此时严格数据空间不再适用,因此,本平台基于对象代理机制的非严格代理类设计了非严格数据空间,实现了数据的动态分类.非严格数据空间可以由用户根据个人需求创建的,允许用户手动转移或者删除数据,用户可以通过创建严格数据空间和非严格数据空间灵活管理数据空间内文件,个性化数据空间架构如图3所示.此外,推送空间是基于用户偏好进行自动分类而设计的[20],也是平台中一类重要的个性化数据空间,通过基于文件标签的自动检索匹配,为用户自动推送感兴趣的文件.
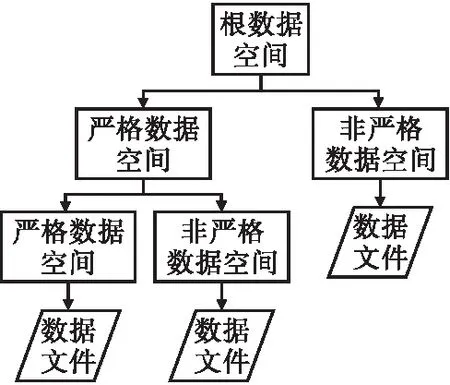
图3 个性化数据空间架构
5 实验设计
本文基于对象代理数据库Totem和关系型数据库Mysql设计了查询效率对比实验.本文实验运行在Windows 10,64bit的笔记本上,硬件环境为处理器i7-7700,2.8GHz,8核8线程,内存8GB.在实验设备等条件相同的前提下,实验数据通过编写并运行脚本在数据库中插入,随着数据量的不断增加,本文比较利用Totem中的选择代理、连接代理、合并代理以及分组代理分别与mysql中的对应的选择、连接、合并和分组操作进行对比实验,比较查询20次所需的平均时间变化情况.实验结果如下表格所示,通过表1和表2可以看到,连接代理操作和选择代理操作在数据量由几条增加到上万条时,所需的代理查询时间都要优于在Mysql中进行相应的选择和连接操作所需的时间.而在表3和表4的实验结果中可以看到,当数据量少于10条时,Totem数据库中进行合并和分组代理查询所需的时间略高于在MySQL中所需的查询时间,但仅相差约0.01ms,这很难在查询时被用户所感知,因此可以忽略不记.但是,随着数据量的逐级增加,totem的代理查询效率越来越优于mysql中通过表进行合并及分组操作所需的查询消耗.通过对实验结果进行分析可以,这些结果的产生来源于对象代理机制的先进性.由于在对象代理数据库中,代理对象的虚属性并没有占用实际的存储空间,而是以双向指针的方式进行连接.当数据量逐渐增加时,在对象代理机制中进行多级代理查询主要是通过双向指针的连接进行,而在关系数据库中需要大量的表进行匹配连接操作.因此,随着数据量的增加,totem中基于代理关系链的双向指针存储方法,避免了关系数据库中的表连接操作,有效的减少了查询时间,大大提高了查询搜索的效率.

表2 Totem选择代理查询和mysql选择查询比较
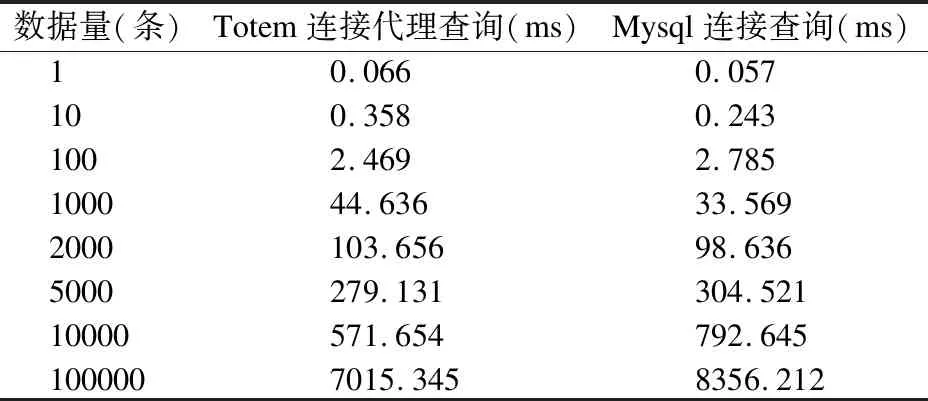
表3 Totem合并代理查询和mysql合并查询比较
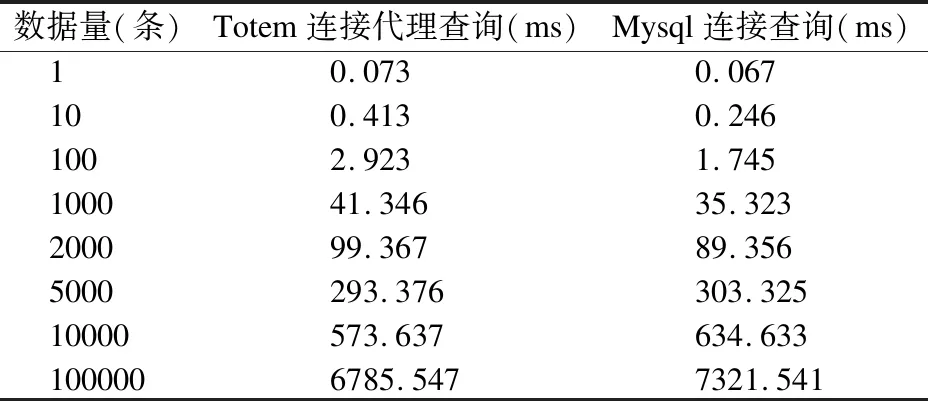
表4 Totem分组代理查询和mysql分组查询比较
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
铁道通信信号(2020年4期)2020-09-21
趣味(数学)(2018年12期)2018-12-29
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
现代营销(创富信息版)(2018年8期)2018-09-08
电子测试(2017年12期)2017-12-18
学生天地(2016年23期)2016-05-17
测绘科学与工程(2013年1期)2013-03-11
