
ATPCRM:一种面向ABAC的双阶段访问策略冲突消解机制
2023-05-23 15:05邓显辉李斌勇邓良明
小型微型计算机系统 2023年6期
邓显辉,李斌勇,2,蒋 娜,邓良明
1(成都信息工程大学 网络空间安全学院,成都 610225)
2(先进密码技术与系统安全四川省重点实验室,成都 610225)
1 引 言
访问控制技术已经广泛应用于各类信息系统,以保证系统信任域内的资源被合法安全地访问和获取.访问控制技术自发展起至今已近50年,经历了从简单到复杂、从理论到实践的变革[1],其已经衍生出了许多经典的访问控制模型如:自主访问控制模型(DAC,Discretionary Access Control)、强制访问控制模型(MAC,Mandatory Access Control)、基于角色的访问控制模型(RBAC,Role-based Access Control)以及结合如信任评估[2]这类安全技术所构建的访问控制模型.这类模型已经被广泛应用于各类安全领域,发挥了不可小觑的作用.但是,随着信息技术的不断变革,传统的访问控制模型越来越难以适应复杂网络的访问控制需求,以至于对访问控制技术的研发工作提出了新的挑战.
基于属性的访问控制模型(ABAC,Attribute-based Access Control)通过引入属性的概念,将属性贯穿访问控制模型、策略以及机制3个层次,将访问控制模型中的相关信息以属性的形式统一建模[3],进而实现灵活地和细粒度地访问控制以及更为复杂的访问策略,以适应如今复杂网络和大规模环境下的访问控制需求[4].但是,随着信息系统的不断演变,系统内部的实体以及它们之间的关系愈发复杂,用于描述各类实体的属性也在愈发增多,同时访问策略的数量也在逐渐膨胀,此时,应用基于ABAC的访问控制机制就不可避免地发生了访问策略冲突问题.对于访问策略冲突,从广义的角度来释义就是由于异构系统之间存在安全策略不一致、语义相互矛盾以及特定的措施存在相互抵触的问题,这些问题进而导致了访问策略冲突[5];从ABAC模型本身的角度来解释,访问策略冲突就是系统基于访问策略对访问请求进行评估时,适配到了多条规则,且这些适配的规则给出了不同的评估结果,进而影响到了系统对访问请求的正常评估决策,同时无法保证信任域内资源的安全性.因此,为了保证基于ABAC的访问控制机制对访问请求的正常评估决策以及信息系统内的资源能被安全合法地访问和获取,解决基于ABAC的访问策略冲突问题成为了访问控制领域的一个重要研究内容之一,同时也成为了部分学者的研究热点;如文献[6,7]从基于ABAC的访问策略出发,研究策略规则中的“属性-属性值”对访问请求进行评估的作用机理,提出了对应的访问策略冲突消解方案;文献[8,9]从描述访问策略的语言机制出发,通过结合使用机制本身自带的冲突消解机制来消解ABAC的访问策略冲突.虽然现有方案在一定程度上解决了针对ABAC的访问策略冲突问题,但是大多数方案在消解冲突时,需要策略制定者手动参与策略的调整,缺乏了一定的灵活性[10],同时部分方案在利用访问策略中的规则属性解决访问策略冲突问题时,没有很好地考虑到属性的类型问题,且没有对规则属性进行划分处理,进而不能很好地提高消解冲突的准确性.不仅如此,现有访问策略冲突消解方案在消解冲突时大多数存在偏向性和粗粒度的消解结果等问题,包括在冲突消解过程,因系统对原有的策略规则进行了不合理地非人工修正冲突,进而导致正常访问请求无法通过,而恶意访问请求可以正常通过等这类危害信息系统的事件发生.
针对上述问题,本文从消解基于ABAC的访问策略冲突角度出发,引入K-prototypes聚类算法和TF-IDF算法,结合多种消解策略,提出一种面向ABAC的双阶段访问策略冲突消解机制:ATPCRM.首先,ATPCRM由系统运行前的访问策略冲突预消解和系统运行时的策略冲突消解两个阶段构成,其中系统运行前的访问策略冲突预消解是在访问控制机制运行前对访问策略中的规则进行预处理,进而加上权重标签,以规则权重大小的形式实现策略冲突预消解;其次,系统运行时的访问策略冲突消解则是在冲突预消解没有完全消解冲突的基础之上,采用适配新加载规则缓冲区中的新加载规则,以及根据冲突类型的不同自适应采用不同类别的消解策略的方法,以达到消解策略冲突的目的,进而实现细粒度的策略冲突消解机制.本文的贡献如下:
1)提出一种面向ABAC的双阶段访问策略冲突消解机制:ATPCRM.ATPCRM从系统运行前的访问策略冲突预消解与系统运行时的访问策略冲突消解两个阶段出发,消解基于ABAC的访问策略冲突;同时ATPCRM将基于ABAC的访问策略重新定义,利用分类型属性和数值型属性的概念来描述策略中的规则,并基于规则属性开展冲突消解工作;
2)提出策略规则集预处理算法和策略规则权重评估算法应用于系统运行前的访问策略冲突预消解阶段;该阶段改进了K-prototypes聚类算法和TF-IDF算法并应用其中,在克服传统K-prototypes聚类算法处理分类型数据和数值型数据时因量纲不统一、随机选取初始聚类中心所导致的低聚类效率和低正确率,以及传统TF-IDF算法无法识别类别区分度高的对象等问题的同时,降低了算法整体的计算复杂度,可以更好地适应策略规则处理,进而提高冲突消解的效率和准确性;
3)提出新加载规则缓冲区和自适应访问策略冲突类型的冲突消解策略应用于系统运行时的访问策略冲突消解阶段;该阶段建立在策略冲突预消解没有完全消解冲突的基础之上,并根据适配新加载规则和根据冲突类型的不同自适应不同类型的冲突消解策略来实现冲突消解.
本文的其余部分组织结构如下:第2节介绍了与本文相关的一些文献研究工作;第3节介绍了ATPCRM模型的相关概念以及详细的模型框架;第4节讨论了实验结果,并将其与两个访问策略冲突消解算法进行了比较;最后,第5节对本文进行了总结.
2 相关工作
访问策略冲突的研究起源于对访问策略管理架构机制的研究[11].针对策略冲突的研究主要分为策略冲突检测和策略冲突消解两个方面,而本文注重于策略冲突消解方面的研究.冲突消解方案的定义一般会遵循某种访问策略冲突消解原则,文献[12]指出的策略冲突消解原则有:近距离优先原则、指定优先原则、最近加载策略优先原则、本地策略优先原则、属主级别优先原则以及反向策略优先原则.文献[6]从策略消解的处理阶段出发,将策略冲突消解原则划分为了动态和静态两种策略冲突消解原则,即将策略消解的处理阶段划分为了处理前和处理中.文献[13]则从协作平台的应用出发,将策略冲突消解原则划分为了预定义消解策略和多方决策策略,进而应对更多种类的访问策略冲突.访问策略冲突有许多种类,针对不同类型的策略冲突所采取的消解方案以及消解原则也不尽相同.在早期,文献[12]将访问策略冲突简要地划分为元策略冲突与模态冲突,以此提出了对应的访问策略冲突消解方案.一些传统的访问策略冲突消解方案如:遍历子基法[14]、自主消解法[15]和随机消解法[16]虽然在一定程度上解决了当时的策略冲突问题,但是,随着策略规模数目的不断增加,其消解方案的计算时间复杂度也会随之增高,进而降低算法整体的计算效率;同时,因受人工主观意识的影响,自主消解法的出错概率也较高.文献[17,18]分别采用了指定优先级和属主级别优先级的冲突消解原则,通过建立策略规则优先级体系实现访问策略冲突的消解.文献[11]从访问策略的非一致性冲突角度出发,形式化地定义了访问策略非一致性冲突问题,通过采用指定优先原则的策略冲突消解原则实现了一套计算策略优先级的方法,进而消解了访问策略冲突.同样的,文献[19]也从访问策略的非一致性冲突角度出发,针对物联网环境下的访问策略因策略融合所带来的非一致性策略冲突问题,提出了一种基于竞价机制的静态策略冲突消解机制,根据竞价结果选择策略的原则消解访问策略冲突.文献[20]结合主体、对象以及组织与权限之间的映射关系,提出了一种基于关系的访问控制策略冲突消解方案,通过定义不同的主体、对象之间的映射关系以及权限与权限之间的间接转移关系,进而解决间接冲突的问题;然而该方案无法适应海量对象和复杂权限环境下的访问控制问题,且随着关系链的增多,冲突消解的效率和准确性会随之降低.文献[21]提出了一种基于策略优先级的策略间形式冲突消解机制;该机制通过对访问策略进行消解前化简,并利用冲突面积与自身频率的方式来计算表征每一条策略的优先级并排序,最后根据排序结果组成新策略集,以此消解策略冲突,同时也保证了策略集的完整性;但是当该机制在处理大规模策略规则时会产生大量的矩阵运算,进而导致计算复杂度的急剧增高,影响机制效率.在动态消解冲突方面,文献[22,23]采用系统运行时消解策略冲突的思想,通过构建动态感知的访问策略冲突检测与消解框架,消解在访问请求评估过程中所出现的策略冲突问题.上述消解访问策略冲突的方案都是从访问策略之间的关系出发展开研究,并没有考虑到策略内以及策略中的规则属性之间的关系也是导致策略冲突的因素之一,同时当访问策略数量逐渐膨胀时,冲突消解算法的效率也会随之降低.为了解决上述问题,部分学者从规则属性之间的关系出发研究消解访问策略冲突的方案.文献[24]从策略条件属性对策略决策属性的影响程度出发,通过采用属主级别优先的策略冲突消解原则,定义了一种基于属性影响度的显式策略冲突消解算法,解决了在分布式计算环境下的访问策略冲突问题.文献[25]从访问策略配置的角度出发,为解决现有精化技术下给出的访问策略配置无法处理不同类型策略冲突问题,提出了一种基于开放逻辑R反驳计算的访问策略精细化方法来计算消解策略冲突,并实现了对策略冲突的有序分析.文献[26]为解决当前云服务环境下的策略冲突消解方法单一和粒度不够的问题,提出了一种多消解策略的策略冲突消解机制;该机制从策略层次和属性层次出发,提出了粗粒度消解和细粒度两者消解算法,以便在面对不同类型的策略冲突时使用不同的消解方案来进行冲突消解处理.文献[6]基于ABAC模型设计出一种基于规则适用范围的静态冲突消解方案;该方案针对策略内的冲突规则可能有多个属性的值域存在重合,以及不同条件下对策略集需要进行不同程度的消解等问题,提出了规则适用范围和属性冲突频率的概念,并结合冲突消解阈值,实现了更灵活的策略冲突消解;但是该方法仅是通过遍历冲突规则来消解规则的冲突域,当面对大量冲突域时效率较低.文献[7]为解决传统优先级策略冲突消解策略过于简单,以及在复杂系统环境下不能很好地适应现有的访问控制需求的问题,提出了一种基于TF-IDF算法的ABAC策略冲突消解算法;该算法采用K-modes聚类算法来对策略规则进行聚类处理,并采用改进后的TF-IDF算法对处理后的规则进行权重评估,进而在消解冲突的同时,避免冲突消解结果的偏向性问题;但是,该算法只考虑到ABAC策略规则中的属性只有分类型属性值的问题,并没有考虑到策略规则中的属性是混合型的属性,且在处理时没有对规则属性进行类别划分处理,进而降低了消解结果的准确性.
可扩展的访问控制标记语言XACML(Extensible Access Control Markup Language)是基于XML的、可用于描述基于ABAC的访问控制机制的一种开放标准语言.XACML可以允许策略制定者在不同环境下灵活地制定和管理访问策略,同时最新的XACML版本也提供了13种冲突避免算法,以解决访问策略冲突问题.为了解决访问策略冲突问题,许多学者在XACML的基础之上提出了许多不同的消解方案.文献[8]从访问策略的描述语言XACML出发,分析了当前基于XACML的冲突消解算法不足之处,提出了一种新的一次性策略冲突消解算法;该算法基于策略冲突消解原则中的优先级原则,采用基于有向无环图(Directed Acyclic Graph,DAG)的拓扑排序来计算并合并规则的优先级,通过一个N维空间中的区域映射所有的规则,并按照优先级顺序实现了一次性的冲突消解.文献[27]为解决多策略和多管理员参与策略制定的环境下发生的访问策略冲突问题,提出了一种基于XACML和动态优先级模式的访问策略框架和消解算法,通过对发生策略冲突的域执行优先级的动态增减,进而消解访问策略冲突.文献[9]为解决XACML策略出现的策略冲突等问题,通过引入规则控制域的概念提出了一种策略冲突消解方法.同年,文献[28]提出一种组合XACML冲突避免算法来对不同类别的策略冲突进行消解,同时采用了面向方面的有限状态自动机对冲突类型进行分类.
综上所述分析可知,现有方案在使用规则属性解决访问策略冲突问题时,并没有完全考虑到策略规则属性是否为分类型还是数值型属性,且无法对规则类别进行划分处理,故无法有效地提高冲突消解的精度;同时大部分方案因消解算法以及机制的单一,故存在偏向性和粗粒度的消解结果,以及消解冲突过程因对原有的策略规则进行了非人工冲突修正而预留下了潜在的不安全因素等问题.
3 ATPCRM模型的构建
该部分的主要工作是提出ATPCRM的具体框架模型.ATPCRM由系统运行前的访问策略冲突预消解和系统运行时的访问策略冲突消解两个阶段组成;首先,系统运行前的访问策略冲突预消解阶段由策略规则集预处理算法与策略规则权重评估算法构成;策略规则集预处理算法主要对全局的策略规则集进行评估前的类别划分预处理,并在此基础之上保证后期对规则评估的准确性;而策略规则权重评估算法的目的是为了更好地通过规则权重来消解策略冲突,进而实现系统运行前的冲突预消解,减少系统运行时因消解冲突所带来的时间消耗.其次,系统运行时的访问策略冲突消解阶段是消解基于冲突预消解基础之上没有完全消解的策略冲突,通过采用适配新加载规则和根据冲突类型的不同自适应采用不同类别的消解策略,进而实现冲突消解.接下来介绍本文所提出的冲突消解机制的相关基础知识概念与定义.
3.1 基础知识概念与相关定义
3.1.1 基于ABAC的访问策略
访问策略是访问控制机制对访问请求进行评估的依据.ABAC模型的访问策略是由若干条规则组成的策略集,每条规则包含了主体属性、客体属性、环境属性、操作属性以及授权决策这5个属性项,且每个属性项以“属性-属性值”键值对的形式来表示,其中除了操作属性以及授权决策外,其余属性项可以由分类型属性和数值型属性来描述;同时当访问控制机制使用访问策略对访问请求进行评估时,策略规则中的主体属性、客体属性和环境属性起着区别于其它规则的作用,而操作属性和授权决策则起到最后的决策作用.因此从评估访问请求的角度来说,如果将规则集的主体属性、客体属性、环境属性3个属性项与操作属性、授权决策两个操作属性项分开处理,而在随后的访问请求评估过程中,只依据处理后的规则适配对应的操作属性和授权决策,进而对访问请求做出正确地评估;那么相比于传统方案,上述方案可以在实现对访问请求正常评估的同时,减少系统对规则属性的处理难度,进而提高访问请求评估的效率.故本文将基于ABAC的访问策略重构为一种只包含主体属性、客体属性和环境属性的全体规则集,每个规则集是由分类型属性和数值型属性来刻画的混合型数据集,且每条规则与操作属性和授权决策做了对应的映射处理.为了方便本文的描述,对本文访问策略的相关知识概念给出如下定义:
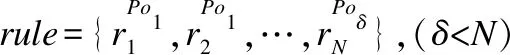
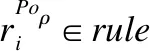
定义3.设CLi∈rule是全体规则集rule在预处理过程中所得出的一个类别类,其关于分类型属性的类中心根据定义2可表示为:
(1)

其关于数值型属性的类中心根据定义2可表示为:
(2)
同样的,在rule中的所有规则也可以用类中心的表示方式来表示,只是在分类型属性中,当前属性的取值所对应的出现频率为1,而属性值域中其余取值的出现频率为0.
3.1.2 K-prototypes聚类算法

(3)
其中dCA和dNU分别表示对象与类中心在分类型属性和数值型属性下的相异度,而dCA则表示0-1简单匹配相异性度量,dNU表示欧式距离,而参数μ则是用来调节控制分类型属性和数值型属性两者的贡献大小.
K-prototypes算法的目标函数定义如下:
(4)
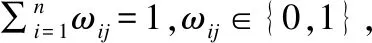
3.1.3 网格聚类
网格聚类算法是一种计算效率很高的空间数据结构聚类算法;将网格聚类算法与一些传统聚类算法结合可以降低聚类算法本身的计算复杂度[30],解决传统聚类算法因无法自主划分聚类数目和随机选取聚类初始中心点所带来的聚类效果不佳的问题.本文将网格聚类算法与本文所提出的改进型K-prototypes聚类算法相结合,提出策略规则集预处理算法,在解决传统K-prototypes聚类算法所面临的一些问题的同时,提高策略规则集处理的性能.接下来给出相关公式.
网格密度:对于网格Gx,其网格密度的计算公式为:
|Gx|=total(rj)
(5)
其中total(rj)表示网格Gx区域内包含的规则数据点数量总和.
网格质心:对于空间中的任意网格Gi,其网格的质心计算公式为:
(6)
其中rj(1≤j≤N)表示坐落在网格Gi内的一个规则数据点.
网格划分阈值:为了进一步细化空间中的网格以达到网格间密度的均衡性,同时获得更高效率的聚类效果,需要一个阈值来控制网格划分的程度,其对应计算公式为:
(7)
其中rα,rβ表示NCU维空间中任意两个规则数据点,d(rα,rβ)表示两点之间的欧式距离,minG表示划分网格中密度最小的网格密度值.
相似网格度量值:为了识别相似网格并将相似网格归为同类以获得初始聚类中心,需要一个值来衡量两个网格之间的相似程度.本文引入万有引力公式,并在其基础之上做出改进用来表达两个网格之间的相似程度,其网格相似度计算公式为:
(8)
其中,对于万有引力公式中两点的质量和两点之间距离的表示,本文使用两个网格的密度值来代替两个网格的质量,而两个网格之间的距离则用两个网格质心之间欧式距离的平方值来表示;对于e-τ,由于本文的网格划分采取的是均匀划分原则,故没有考虑引力系数的影响,而是使用e-τ来代替;其中e-τ表示相似因子,其可理解为:如果两个网格相似度越大,则τ的值越小,e-τ的值越大;对于τ,其计算公式为:
(9)
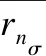
(10)
3.1.4 TF-IDF算法
TF-IDF算法是一种用于信息检索和数据挖掘的常用加权技术,其基本思想为:一个词在某一个文本中出现的频率较高,而在其它文本中出现的频率较低,说明该词对于区别和表达文本的核心内容起着重要的作用.传统的TF-IDF算法主要由TF和IDF两部分的乘积组成,其计算公式为:
(11)
其中wi,j表示文本j中词i出现的数量;∑Kwk,j表示文本j中所有词出现次数的总和;N表示全局中文本的数量;Nw表示全局文本中词i出现的文本数.本文在该算法的基础之上进行改进,提出适应于本文模型的TF-IDF算法.
3.2 系统运行前的访问策略冲突预消解
在这一小节中,本文将介绍实现访问策略冲突预消解阶段功能的两个核心算法:策略规则集预处理算法和策略规则权重评估算法,并在最后展现该阶段整体的工作流程.
3.2.1 策略规则集预处理算法
为解决现有方案和算法中,对策略规则集这类混合型数据的处理存在因数据量纲不一致所导致地消解结果的低准确性和弱稳定性,以及因参数设置所导致地计算复杂度高等问题,提出一种策略规则集预处理算法;该算法借助K-prototypes算法对混合型数据处理的友好性,通过将网格聚类思想融入以及改进K-prototypes算法,实现对策略规则集这类混合型数据在处理效率和准确性上的提升,同时减少原有算法中欧式距离的计算量与整体的计算复杂度,进而高效地为后期规则评估提供有效的预处理结果.在提出策略规则集预处理算法之前,本文首先引入策略规则类别划分算法.
1)策略规则类别划分算法
策略规则类别划分算法的基本思想是:首先初始化空间中的网格,将进行了去冗余等处理的全体规则集rule中所有的规则数据点映射到网格中,依据划分阈值threshold进一步划分均衡网格密度;其次在划分好的网格中去除劣质网格,保留优质网格;最后在保留的优质网格中归类相似的网格得到不同的网格类.这些网格类的数量即是K值,网格类中网格密度最大的网格的质心即是初始化聚类中心.
策略规则类别划分算法的基本步骤如下:
Step 1.初始化网格,对全体规则集rule进行去冗余等处理得到规则集rule*,然后将rule*中的所有规则数据点映射到初始化网格中,并依据网格划分阈值threshold、网格大小与网格密度|Gx|来对网格进行进一步均衡化划分,得到网格密度与网格大小两者比例均衡的网格;
Step 2.计算网格密度,根据密度阈值denθ筛选出优质网格,去除劣质网格;
Step 3.计算网格质心COMi,并在优质网格中计算任意两个网格之间的相似网格度量值;
Step 4.选择一个未被遍历的质心,判断该质心与其它质心之间的相似网格度量值是否不低于合并阈值Mergeθ,如果是,则标记为同类质心,否则标记为非同类质心;
Step 5.重复Step 4,直至所有质心都被遍历;
Step 6.根据所得到的不同网格类中,网格密度最大的网格的质心点即为初始聚类中心,网格类个数即为rule*中数据之间的类别数K.
策略规则类别划分算法的伪代码如算法1所示.
算法1.Strategy rule category classification algorithm
输入:Sample Datasetrule
输出:Policy Rule Category SetsetSim,Category NumberK
1.Initializing the grid ofG;#Gis the original grid
2.Data processing for the Sample datasetruletorule*
3.Map therule*to theG,then get thethresholdto further partition theG;
4.Get the density ofNGgrids inGby Equation(5);
5.FORiinNGdo
6.IF|Gi|≥denθthen
7. addGitosetπ;#setπis the data set that holds the grid center
8.EndIF
9.EndFOR
10.Get theCOMiof the Grid in thesetπby Equation(6);
11.K=1;
12.FORoinNπdo
13.j=o+1;
14.IFCOMois notmarkedthen
15.FORjinNπdo #Nπis the number of elements of thesetπ
16.IFCOMjis not markedthen
17. Get theSimilar(COMo,COMj) by Equation(8);
18.IFSimilar(COMo,COMj)≥Mergeθthen
19. addCOMjtosetSimK;
20. markerCOMjtoClassK;#ClassKmeansCOMjbelongs to ClassK
21.EndIF
22.EndIF
23.EndFOR
24. addCOMotosetSimK;
25. markerCOMotoClassK;
26.K=K+1;
27.EndIF
28.EndFOR
29.RETURNPolicy rule category setsetSim,Category numberK;
2)策略规则集预处理算法
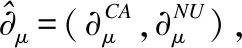
(12)
(13)
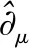
(14)
策略规则集预处理算法的基本步骤如下:
Step 1.依据算法1得到策略规则集的划分类别集合setSim以及划分类别数K,并根据setSim获取初始聚类中心;
Step 2.计算每个网格质心点与聚类中心点的相异性度量值;
Step 3.根据相异性度量值将网格分配到最邻近的聚类中心点;
Step 4.计算更新聚类中心点,其中数值型属性部分通过计算同一类中对象取值的平均值得到,分类型属性部分依据定义3计算类中心;
Step 5.重复Step 3~Step 5,直至公式(4)的值不再发生变化.
策略规则集预处理算法的伪代码如算法2所示.
算法2.Policy rule set pre-processing algorithm
输入:Sample Datasetrule
输出: Category Collectionrule′
1.Get initial cluster centers and category numberKby Algorithm1;
2.FORiinNGdo#NGdenotes the number of grids in G
3.FORjinNCCdo #NCCis the number of initial clustering centers
4. Calculate theSimilar(COMi,CCj);#CCjis the initial clustering centers
5. AddSimilar(COMi,CCj)toAlloi;#Alloistores the similarity measures ofCOMiandCCj
6.EndFOR
7.EndFOR
8.Assign theCOMito the nearest cluster centroid based on the maximum value inAlloi;
9.Calculate the value ofF(X,R) and determine if the value ofF(X,R) has changed;
10.WHILEF(X,R) is still changingdo
11. Update the Clustering Center;
12. Calculate theSimilar(COMi,CCj) and assigning theCOMito the closest cluster centroids;
13. Calculate the value ofF(X,R) and determine if the value ofF(X,R) has changed;
14.EndWHILE
15.RETURNCategory Collectionrule′;
3.2.2 策略规则权重评估算法
在针对ABAC的访问策略中,当一个属性项的取值在当前的策略集中出现频率越小,说明该属性具有明显的特异性能标识出与其它规则之前的差异性,因此在评估过程中此类属性应该赋予更高的权重值;相反,一个属性的取值在当前的策略集中出现频率越高,说明该属性就越普通,无法显示出与其它属性之间的差异性,应该赋予较低的权重值.因此,为了更好地对基于ABAC的访问策略中的规则进行权重评估,进而以规则权重大小的形式消解策略冲突,即选择当前权重值最高的规则来评估当前的访问请求,本文对TF-IDF算法的进行改进,提出一种策略规则权重评估算法应用于策略规则集的权重评估;该算法在克服了传统TF-IDF算法没有考虑到因评估对象所处位置不同而导致权重值不同等问题的同时,更加适应本文所提出的应用环境.
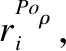
(15)
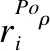
(16)

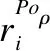
Step 1.统计预处理后的全体规则集rule′中,含有属性ATTi的规则数量、本类集合中属性的数量总和、ATTi在全体聚类结果集合和本类规则集中出现的次数以及频率;
策略规则权重评估算法的伪代码如算法3所示.
算法3.Policy rule set weight evaluation algorithm
输入:Category Collectionrule′,Total Number of RulesN
输出:weighted labels
1.Splitting operation forrule′ toWord;#Wordis the dataset that holds the word separation results
2.Performing word frequency statistics operations onWordtowordcount;#wordcountis the data set that holds the word frequency results
3.Count the sum of the number of attributes contained inwordcounttoASum;
4.labels=[0 forainrange(N)];
5.FORiinwordcountdo
6. Count the sum of the number of attributes contained inwordcountitoSumAti;
7.SASum=0;OASum=0;EASum=0;Sum=0;
8.FORj,kini.items()do
9. Count the number of rules withATTjinrule′ toRSumj;
10. Count the sum of the number ofATTjcontained inrule′ toASumj;
11.AFrj=ASumj/ASum;
12.WFrj=WSumj/SumAti;
13. CalculateTFi,j,IDFi,jandωibyAFrj,WFrj,SumAti,RSumj,ASum,ASumj,WSumjandN;
14.IFATTjbelongstoSAithen
15.SASum=TFi,j·IDFi,j·ωi;
16.ELSEIFATTjbelongstoSAithen
17.OASum=TFi,j·IDFi,j·ωi;
18.ELSEthen
19.EASum=TFi,j·IDFi,j·ωi;
20.EndIF
21.EndFOR
22.Sum=σ·SASum+τ·OASum+φ·EASum;
23. addSumtolabels[i];
24.EndFOR
25.RETURNweighted labels;
3)系统运行前的访问策略冲突预消解工作流程
针对系统运行前的访问策略冲突预消解的工作流程如图1所示.
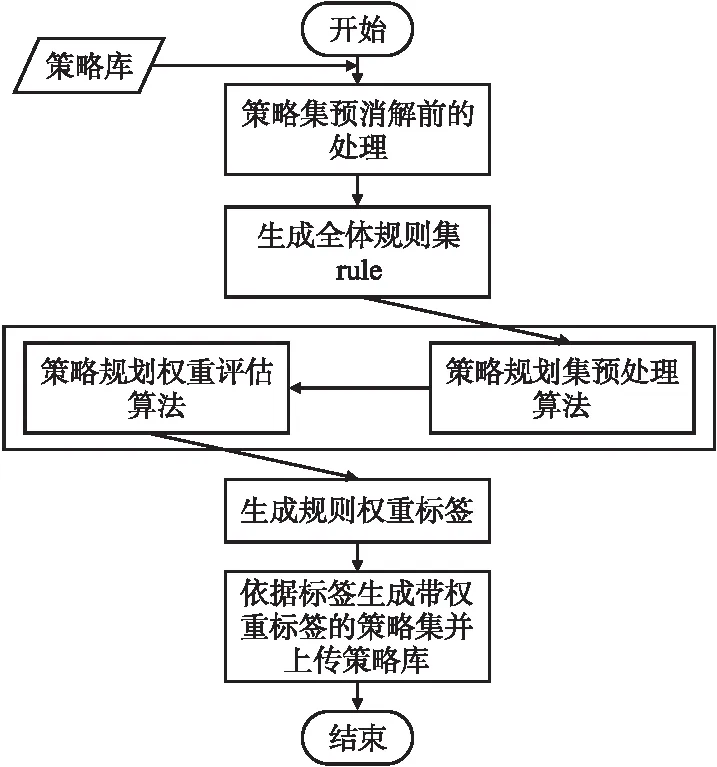
图1 系统运行前的访问策略冲突预消解工作流程图
Step 1.对策略库中的策略规则进行合并标识处理获得全体规则集合rule,并去除规则集合中规则的决策与操作属性;
Step 2.对rule进行预处理获得预处理结果;
Step 3.根据预处理结果对规则进行评估获得规则评估标签;
Step 4.生成规则带权重标签的策略集并上传策略库.
3.3 系统运行时的策略冲突消解
在这一小节中,本文将介绍实现策略冲突消解阶段功能的两个核心功能:新加载规则缓冲区和自适应访问策略冲突类型的冲突消解策略,并在最后展现该部分整体的工作流程.
3.3.1 新加载规则缓冲区
在消解访问策略冲突的过程中可能会出现更新访问策略库中策略集的情况,除了因消解冲突而导致冲突策略的系统自动修正更新之外,也有因新规则上传替代旧规则所导致的策略内容更新的情况.但随之而来的问题就是,当在进行冲突消解或者评估访问请求的过程中,可能会出现因规则更新不及时,导致系统使用的是旧版本策略规则的情况,这就违背了一定的访问控制原则,同时可能会导致一些不安全的访问获取情况发生.为了解决上述问题,本文提出一种新加载规则缓冲区.
新加载规则缓冲区应用于系统运行时的策略冲突消解最初阶段,当系统新加载规则后,新加载规则会进入缓冲区中,同时系统会通过计算访问评估高峰期来判断更新预消解策略集并上传策略库的时间节点,进而保证不会因策略更新导致系统使用旧策略集进行访问评估所带来的信息安全问题.需要注意的是,当更新完毕的预消解策略集上传策略库之后,系统会撤销缓冲区中的相关规则.
新加载规则缓冲区的工作流程分为系统更新阶段和系统匹配阶段,具体流程如下:
Step 1.系统更新阶段
Step 1.1.系统捕获新加载的规则,并将新规则上传至新加载规则缓冲区;
Step 1.2.判断系统是否处于访问评估高峰期,如果是则触发计时器,该条规则进入更新等待期,并在计时器到期后进入Step 1.2;如果不是,则进入Step 1.3;
Step 1.3.系统根据捕获的新加载规则,将其分配至合适的规则类中重新估算整体的规则权重;
Step 1.4.生成新的带权重标签策略集并上传更新旧版本的策略集;
Step 1.5.撤销缓冲区中已经更新加载策略库的规则.
Step 2.系统匹配阶段
Step 2.1.系统捕获访问新加载规则缓冲区的请求,并根据访问请求匹配新加载规则缓冲区的规则;
Step 2.2.判断访问请求匹配新加载规则缓冲区中规则的情况,如果适配成功则返回决策结果,如果适配失败则进行下一步的冲突消解流程.
3.3.2 自适应访问策略冲突类型的冲突消解策略
针对当前多数策略冲突消解机制只支持单一的消解策略,且支持多消解策略的冲突消解机制需要人工定位策略冲突类型来选择适合的消解策略等问题,本文提出一种自适应访问策略冲突类型的冲突消解策略.该自适应冲突消解策略由多种消解策略组成,应用于新加载规则缓冲区中无适配规则的情况下,并根据冲突类型自适应选择消解策略来对冲突进行消解.
本文将消解策略的类型划分为3种,其分别为Class1、Class2和Class3,其中Class1的优先级最高,然后依次是Class2和Class3;同时根据一些现有工作[7,26],选择制定4种消解策略用于在系统运行时的策略冲突消解,它们分别是:策略发布时序优先策略、拒绝操作优先策略、允许操作优先策略和管理员决策,其对应的等级分别为Class1、Class1、Class2和Class3,相关定义如表1所示;需要注意的是,当出现访问策略冲突时,首先检测冲突类型,然后再根据冲突类型自适应选择冲突消解策略;拒绝操作优先策略和允许操作优先策略为管理员在系统运行前选定指定.

表1 自适应访问策略冲突类型的冲突消解策略划分类别
3.3.3 系统运行时的策略冲突消解工作流程
针对系统运行时的策略冲突消解的工作流程如图2所示.
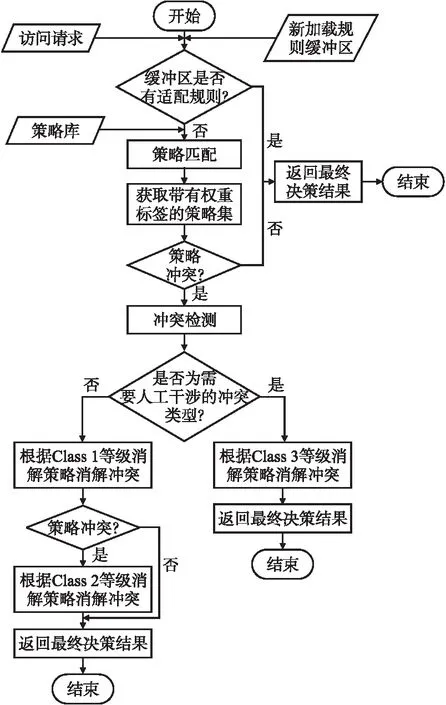
图2 系统运行时的策略冲突消解工作流程图
Step 1.捕获访问请求,判断新加载规则缓冲区中是否具有适配的新加载规则,如果是,则返回决策结果;如果不是,则跳转至Step 2;
Step 2.根据访问请求在策略库中适配带标签权重的策略集,判断是否发生访问策略冲突即判断当前是否有多条规则拥有同等的权重值且该权重值在适配策略集中最大,如果是则跳转至Step 3;如果不是则返回决策结果;
Step 3.对发生冲突的访问策略进行冲突检测,并判断是否为需要人工干涉的冲突类型,如果是,则执行Class3的消解策略并返回决策结果;如果不是,则跳转至Step 4;
Step 4.执行Class1的消解策略并判断是否消解冲突,如果没有则跳转至Step 5;如果是则返回决策结果;
Step 5.执行Class2的消解策略并返回决策结果.
4 实验及分析
4.1 实验环境
本文实验的操作运行选择在英特尔11th Gen Intel(R)Core(TM)i5-11400 @ 2.60GHz六核处理器、16GB内存和64位Windows10操作系统的PC机上进行,集成开发环境为JetBrains PyCharm 2019.1.1 x64和Myeclipse2017 CI.
4.2 实验设置
本文一共设置了两组实验.第1组实验是检测策略规则集预处理算法的有效性,验证策略规则集预处理算法对访问策略这类混合型数据集是否能正确的处理,通过对比K-prototypes算法、EKP算法[31]和OCIL算法[32]在分类型和混合型数据上的处理性能,分析得到本文算法与其它算法之间的差异性.第2组实验为评估ATPCRM的冲突消解性能,通过设置不同量级的人工策略集,验证ATPCRM对冲突策略是否能够成功消解,通过对比XACML下的两类冲突消解算法,分析得到本文算法与XACML下的两类冲突消解算法之间的差异性.值得注意的是,由于除本文算法以外的3个算法受初始聚类中心选择以及受其它参数的影响,每次运行结果可能有所不同,因此本文所涉及到的实验结果均是在算法运行30次后取实验结果的平均值.
4.3 实验数据
本文所使用的实验数据一共设置为两种且分别对应两组实验.针对第1组实验,本文从UCI数据集[33]中选取了6组由分类型和混合型的数据集组成的测试数据来对策略规则集预处理算法进行实验,同时为了防止原始数据之间的差异会对结果造成影响,本文在实验前对其数值进行了归一化处理,具体数据指标如表2所示;针对第2组实验,本文随机生成了五组符合XACML标准的标准人工策略集来对ATPCRM进行测试且测试前已做了数据预处理工作,其人工策略集的数量规模依次为100、200、500、1000、2000;其中,每一条策略都有不少于1条的规则,每个规则由主体属性、客体属性、环境属性、操作和决策属性构成,同时本文使用了策略冲突检测算法对五组人工策略集进行了冲突检测,具体数据指标如表3所示.
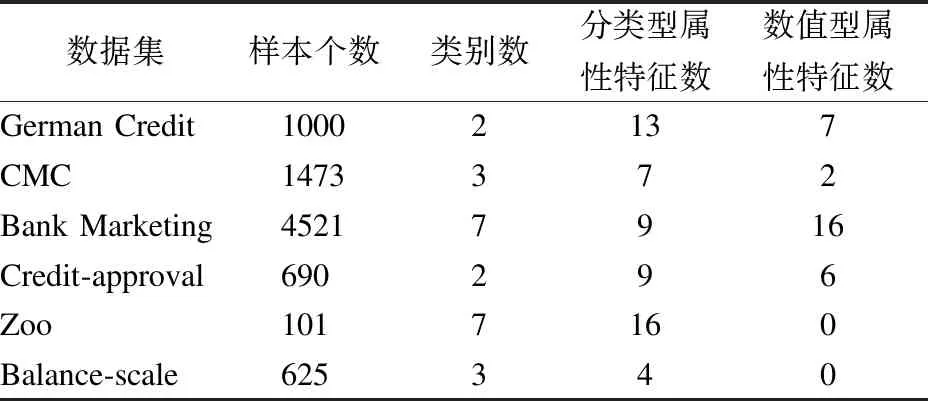
表2 第1部分实验所用数据集

表3 第2部分实验所用数据集
4.4 评价指标
在本文实验中,首先采用聚类精确度(Cluster Accuracy,CA)[34]、标准化互信息(Normalized Mutual Information,NMI)[35]、调整兰德系数(Adjusted Rand index,ARI)[36]、Fowlkes-Mallows指数(Fowlkes-Mallows Index,FMI)[37]以及通过对比真实标签和预测标签之间的类别数来评价策略规则集预处理算法的性能;其次通过时间指标和冲突消解指标来衡量评价ATPCRM冲突消解性能.
聚类精确度CA:真实标签与聚类所得标签之间的差异与样本总数的比值.其计算公式如公式(17)所示:
(17)
其中βi和cluster(γi)分别表示数据的真实标签和聚类所得标签,N表示样本总数,∂(βi,cluster(γi))表示相似性指示函数,其计算公式如公式(18)所示:
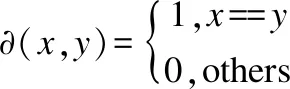
(18)
标准化互信息NMI:一种借助熵的概念来对聚类算法性能进行评价的度量值.其计算公式如公式(19)所示:
(19)
其中P(i,j)表示随机变量(i,j)的联合概率分布,P(i)和P(j)分别表示变量i和j的概率分布.
调整兰德系数ARI:一种在兰德系数(Rand Index,RI)的基础之上进行过归一化处理的评价指标,主要对一个聚类算法的结果和真实分类情况进行比较从而对聚类算法进行评价.其计算公式如公式(20)所示:
(20)
其中ARI∈[-1,1],ARI值越趋近于1表示聚类结果与真实情况越接近;E(RI)表示期望的计算正确决策的比率,MAX(RI)最大的计算正确决策的比率.
Fowlkes-Mallows指数(Fowlkes-Mallows Index,FMI):一种由准确率和召回率所构成的几何平均数,其数学公式如公式(21)所示:
(21)
其中,TP代表聚类结果和真实结果中标签相匹配的点对数量,FP代表在真实结果中的与在聚类结果中的标签不归属同一类集群的成对数量,FN代表在聚类结果中的与在真实结果中的标签不归属同一类集群的成对数量.
4.5 参数设置
本文相关算法的参数设置如表4所示.
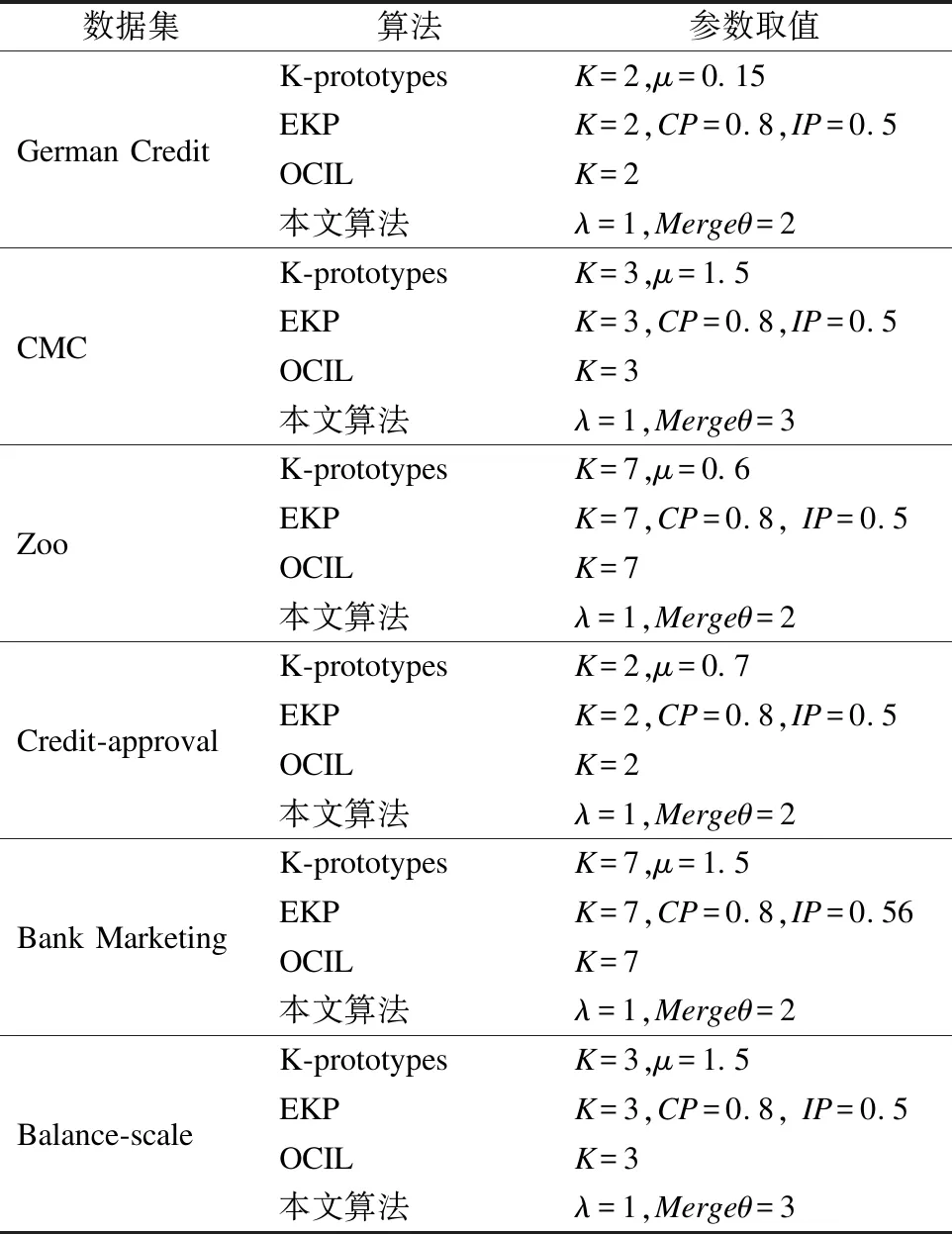
表4 相关算法参数设置
4.6 实验结果分析
4.6.1 策略规则集预处理算法的有效性实验结果分析
1)策略规则类别划分算法的有效性分析
本轮实验中,为了验证策略规则类别划分算法的准确性,使用表2中的数据集对算法进行多次实验,实验结果如图3和表5所示.

图3 K值获取实验结果图

表5 策略规则类别划分算法预测K值实验结果
图3中展现的是策略规则类别划分算法在取不同密度阈值时分别获得的6种数据集中数据之间的类别数目即K值,横坐标表示密度阈值的取值,纵坐标表示K值取值.从图3可以看出,随着密度阈值取值的递增,算法分别获取6种数据集的K值呈递减趋势,且当密度阈值达到某个值域范围后,6种数据集的K值都呈收敛趋势.
由表5所知,6种数据集依据图3所示的结果取对应的密度阈值可以正确获取K值,这表明策略规则类别划分算法可以正确的划分数据集内规则之间的类别以及获取预处理算法所需要使用的初始聚类中心.
2)策略规则集预处理算法的有效性实验结果分析
本轮实验中,在使用表2的UCI数据集在表4所示的参数设置下,分别将K-prototypes算法、EKP算法和OCIL算法与本文算法进行对比,并使用聚类精确度CA、标准化互信息NMI、调整兰德系数ARI和Fowlkes-Mallows指数4个评价指标对实验结果进行评价,评价结果如表6~表9所示.
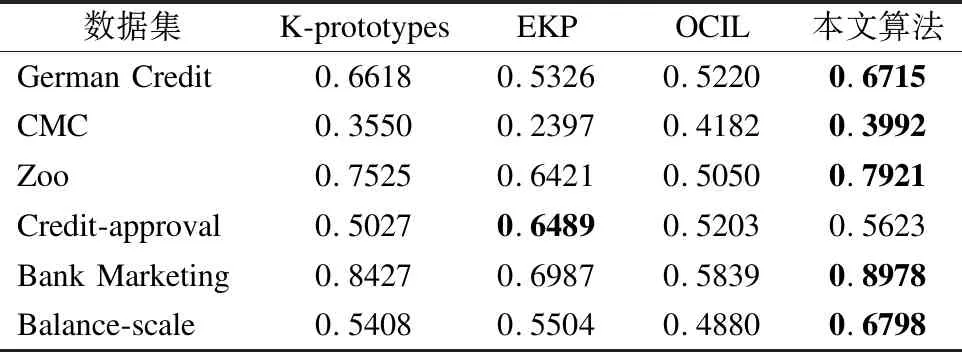
表6 算法评价指标CA的评价结果比较
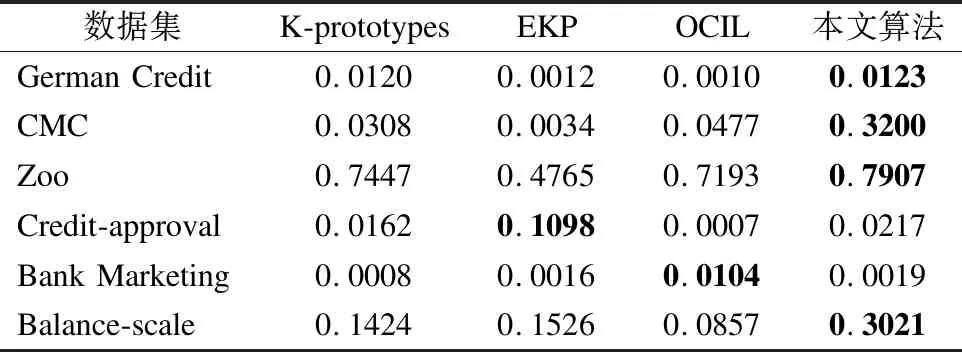
表7 算法评价指标NMI的评价结果比较

表8 算法评价指标ARI的评价结果比较

表9 算法评价指标FMI的评价结果比较
由表6~表9可知,从CA、NMI和ARI值上看,EKP算法在数据集Credit-approval、CMC和Zoo上取得了最优的结果,而OCIL算法在数据集Bank Marketing上取得的实验结果NMI优于其他算法.除此之外,本文提出的算法在其余数据集上均取得了最优的结果.这证明了本文所提出的策略规则集预处理算法在一定程度上可以有效地处理策略规则这类混合型数据.
因此,根据本轮实验结果的分析,策略规则集预处理算法相比于其余3种聚类处理算法,可以较好的处理分析处理策略规则这类混合型数据.
4.6.2 ATPCRM冲突消解的性能实验结果分析
本轮实验中,使用如表3所示的人工策略数据集在如表3.3所示的参数设置下,分别使用XACML环境下的允许优先组合消解算法和拒绝优先组合消解算法与ATPCRM进行对比.冲突消解的性能实验结果如表10和图4所示.
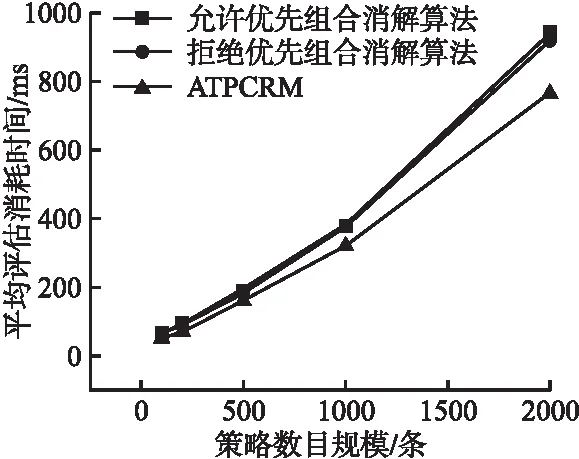
图4 3类冲突消解方法的执行时间结果对比图

表10 冲突消解执行次数结果比较
表10中通过对比数据的形式直观展现了ATPCRM与XACML环境下的允许优先组合消解算法和拒绝优先组合消解算法对5种人工策略数据集的执行次数对比.可见,ATPCRM在同样请求条件下执行的冲突消解次数均小于XACML环境下的两个冲突消解算法,这证明了ATPCRM中的系统运行前的访问策略冲突预消解阶段在一定程度上起到了冲突消解的作用,其消解程度最高达到了48.1%.
图4中比较的是3种冲突消解方法在5种人工策略数据集上的执行时间,横坐标表示策略规模数量,纵坐标表示执行时间.由图4的折线图可知,3种冲突消解方法在评估访问策略所消耗的时间都会随着策略数目的增加,且ATPCRM与其余两个算法对比均表现出了更优异的结果,且随着冲突数目的增多,XACML环境下的两个冲突消解算法的时间消耗增长率往往低于ATPCRM的增长率,而冲突数目少时3种冲突消解方法的时间消耗较为相近.
因此,根据本轮实验结果的分析,ATPCRM相比于XACML环境下的两个冲突消解算法,在一定程度上表现出了较好的消解效果.
5 结 论
本文提出了一种面向ABAC的双阶段访问策略冲突消解机制:ATPCRM用于消解基于ABAC的访问策略冲突.相比于其它冲突消解机制,ATPCRM提供了一些独特的功能.1) ATPCRM提出了系统运行前的访问策略冲突预消解与系统运行时的访问策略冲突消解两个阶段的消解方法,通过两个阶段的冲突消解,在提高消解粒度的同时,进一步降低了系统运行时用于冲突消解的时间消耗,增强了用户友好性;2) ATPCRM支持在系统策略库未更新时,实时读取新加载的访问策略规则,进一步地提高系统的实用性和安全性;3) ATPCRM支持根据冲突类型的不同自适应采用不同的访问策略冲突消解策略,在解决现有大部分支持多消解策略的机制需要人工根据冲突类型选择消解策略的同时,提高了消解粒度.实验表明,本文机制中的算法和机制本身都表现出了相较于其它机制和算法的优异性,对提高消解面向ABAC的访问策略冲突的粒度和效率有积极意义.未来的工作正在计划进一步分析和加强该机制,例如将策略规则集预处理算法中的密度阈值与合并阈值改造为自适应的阈值,以至于能更好地对策略规则进行划分处理从而提高冲突消解的效率;或者应用智能合约在其中.研究自适应和更安全的访问策略冲突消解机制是有意义的.
猜你喜欢
环球时报(2022-04-16)2022-04-16
井冈教育(2020年6期)2020-12-14
制导与引信(2017年3期)2017-11-02
中国公共安全(2017年11期)2017-02-06
通信学报(2016年11期)2016-08-16
现代工业经济和信息化(2016年19期)2016-05-17
工业设计(2016年11期)2016-04-16
信息安全研究(2016年10期)2016-02-28
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
