
门控空洞卷积与级联网络中文命名实体识别
2023-05-23 14:45谭岩杰
小型微型计算机系统 2023年6期
谭岩杰,陈 玮,尹 钟
(上海理工大学 光电信息与计算机工程学院,上海200093)
1 引 言
命名实体识别(Named-Entity Recognition,NER)属于序列标注问题,是自然语言处理领域的四大基本任务之一,目的是将文本中的实体进行标注并定位,为后续的信息抽取、机器翻译等任务服务,具有重要的研究意义.
命名实体识别任务最先是利用规则和词典结合的方法进行实体识别[1,2],但是该类方法中词典与规则的搭建和维修十分繁重,可迁移性差,难以普及.随着机器学习技术的发展,结合隐马尔可夫模型[3,4]、条件随机场(Conditional Random Field,CRF)[5,6]、支持向量机[7,8]等进行命名实体识别的方法相继产生,但是机器学习的方法过度依赖人工提取的特征,在大量文本条件下,工作量大,实验结果会受到人工提取特征的影响,导致模型实验结果产生误差.伴随深度学习技术的发展与进步,命名实体识别任务得到了更好的发展.2016年,Ma等人[9]将LSTM与CNN结合,提出LSTM-CNNs混合结构,自动提取字符级特征,但CNN利用卷积核提取特征,感受野有限,无法有效获取上下文信息,不能解决句中词语长距离依赖等问题;Guillaume Lample等人[10]提出BiLSTM+CRF模型进行命名实体识别,该模型不仅解决了句中词语长距离依赖的问题,而且还能兼顾文本上下文信息,在命名实体识别任务上取得了良好的结果,但BiLSTM无法并行运算,模型运算速度较低;2017年,Emma Strubell等人[11]将空洞卷积(Dilated Cinvolution)引入命名实体识别任务中,提出ID-CNNs模型,空洞卷积通过空洞率,扩大感受野,加强卷积特征提取能力,使模型能有效获得上下文信息,同时利用卷积结构解决了BiLSTM无法并行运算问题,提高模型运算速度,但ID-CNNs只是单纯地将空洞卷积进行堆叠,没有考虑数据的处理与流通方式,容易产生梯度消失;2019年,武惠等人[12]针对小规模数据集实体识别任务,提出基于迁移学习的TrBiLSTM-CRF模型,在小规模数据集上,使用深度学习方法取得了良好的实验结果;同年,随着BERT(Bidirectional Encoder Representations from Transformers,BERT)[13]的提出,利用BERT结构进行编码,可有效提高模型的准确性,在模型中融入BERT结构,是模型迁移性的重要研究方向.2021年,王笑月等人[14]将门控空洞卷积(Gated-Dilated Convolution,DGCNN)引入命名实体识别任务中,在空洞卷积基础上引入残差与门控机制,改善了ID-CNNs容易产生梯度消失的问题.
本文将门控空洞卷积结构(DGCNN)引入BERT+BiLSTM+CRF中,解决BiLSTM无法并行运算问题,提高模型的运算速度,同时利用一维卷积对门控空洞卷积的输入信息进行特征压缩,解决门控空洞卷积中卷积核数目受限于输入特征维度的问题.
在中文文本中,实体存在多种属性,文本空间复杂度高,模型在进行命名实体识别时,CRF层需要在每个实体上进行大量分类任务,增加了工作量,降低了模型的准确度.本文提出级联(Cascade)[15]结构,将实体的位置与属性分开训练学习,使命名实体识别任务变为多任务学习,降低CRF层中进行分类的计算量,增强模型对实体的学习能力,提高模型性能.
中文命名实体识别目前主要以基于字向量、基于词向量、基于字词向量融合这3种特征输入进行学习.2018年,Zhang等人[16]利用Lattice结构融入词向量,为字词向量融合奠定基础,但模型迁移性差,无法适用于BERT;2019年,王银瑞等人[17]提出Trans-NER模型,结合上下文特征生成字符级向量,构建迁移学习模型,在中文命名实体识别任务上取得良好的实验结果;2020年,Li等人[18]基于Lattice结构,将其展平,提出FLAT结构,在Transformer架构上,改变位置编码,在嵌入时融入词向量,在中文命名实体识别上取得了SOTA的结果.模型采用词向量输入进行命名实体识别时,需要对文本进行分词,而分词结果会影响模型的标注结果,错误的分词与分词产生的误差会降低模型精度,同时构建文本词典代价昂贵,空间复杂度高.为防止引入错误分词信息和分词误差,降低模型复杂度,本文采用基于字向量输入进行学习.
结合上述讨论的问题与解决方法,本文提出BERT+DGCNN+Cascade+CRF模型,在Resume数据集上进行命名实体识别实验,验证模型的有效性与优越性.本文主要工作可概括为以下3方面:
1)本文利用门控空洞卷积处理BiLSTM无法并行运算的缺点,将门控空洞卷积与BERT结合,提高模型运算速度.
2)本文提出级联结构进行命名实体识别,改善在中文文本命名实体识别任务中,CRF层需要大量分类计算的问题.
3)本文提出级联结构,将命名实体识别任务改为多任务学习,增强模型对实体的学习,提高模型的性能.
实验结果表明,本文提出的模型在中文文本Resume数据集上取得了良好的结果.
2 BERT+DGCNN+Cascade+CRF模型
本文采用BIO[19]标注,实体首字标注为B,实体内部标注为I,不为实体标注为O.
模型整体架构如图1所示,利用BERT生成字向量,使用门控空洞卷积网络对生成的字向量进行特征提取与编码,通过级联结构将编码信息送至CRF层与Softmax层进行解码,得到实体的位置标签与属性标签,将两种标签对应拼接,得到实体最终的标签结果.
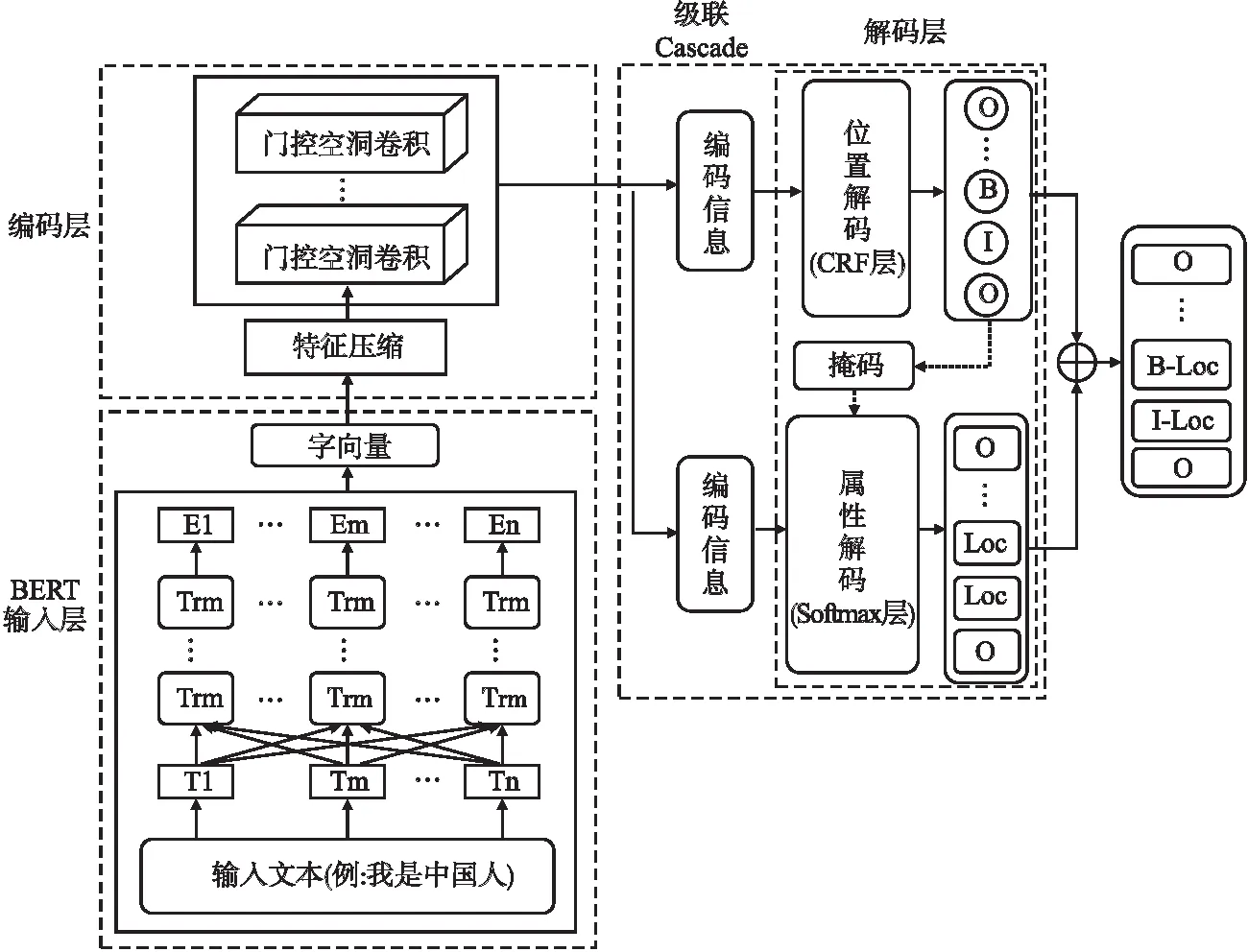
图1 模型架构
2.1 BERT输入层
模型输入层利用BERT产生字向量.在BERT嵌入层中,将实体的标签拆开嵌入,分为位置标签bio和属性标签attr.BERT的输入信息如表1所示.

表1 BERT的输入信息
2.2 DGCNN编码层
在自然语言处理领域,通常采用一维卷积对输入信息进行处理,但普通卷积不能有效提取文本的上下文信息,在编码时会丢失重要的信息,为确保编码的准确性,本文采用门控空洞卷积进行编码.考虑到BERT编码信息的维度较大,为减少噪声,提高模型运算速度,先利用一维卷积对BERT输出的字向量进行特征压缩,再采用门控空洞卷积对压缩后的字向量进行编码.
空洞卷积(Dilated Convolution)源于图像分割领域[20],不同于普通卷积,空洞卷积实现了不使用池化层也能扩大感受野,提取更多的信息.空洞卷积的计算方法如式(1)所示:
(1)
其中,Ot空洞卷积的输出,F表示尺寸为s的滤波器,d表示空洞率,⨁表示卷积的拼接操作.
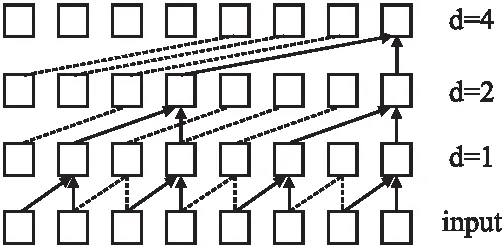
图2 空洞卷积采样
由图2可知,增大空洞卷积的空洞率d,可扩大卷积的感受野,提取更多有效的特征信息,使得编码更加准确.
为了更好地提取有效信息,加强数据流通,并防止梯度消失,在空洞卷积的基础上融入门控机制与残差机制,门控空洞卷积架构如图3所示.
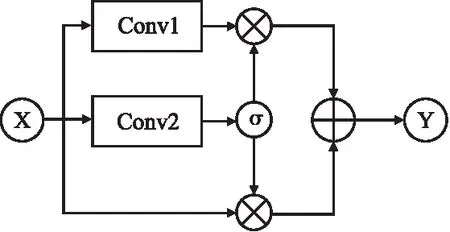
图3 门控空洞卷积架构
由图3可知,门控空洞卷积的输出Y的计算方法如式(2)、式(3)所示:
Y=X⊗(1-σ)+Conv1(X)⊗σ
(2)
σ=σ(Conv2(X))
(3)
其中,X为门控空洞卷积的输入,Conv1与Conv2为空洞卷积,σ表示sigmod函数,为Conv2的激活函数,⊗表示计算特征张量的Hardamard积,⨁表示特征张量的相加操作.Conv1没有激活函数,不容易产生梯度消失,结合残差结构,引入输入X,实现信息多通道传输,防止梯度消失.
2.3 Cascade解码层
传统模型利用CRF层识别实体的整体标签,需要根据实体的属性标签扩展BIO标签列表,当实体属性较多时,BIO标签列表的规模会扩大,CRF层需要在每个实体上进行类别较多的分类计算,损失函数的计算也更加繁琐复杂,容易产生误差.为简化模型,降低CRF层的分类计算量,提高模型学习能力,本文提出Cascade结构,利用Cascade结构,将编码信息分别输入至CRF层和Softmax层中进行解码,CRF层输出实体的位置标签,Softmax层输出实体的属性标签,形成多任务学习框架.
首先,将编码信息W={w1,w2,…,wn}输入至解码层的CRF层中,预测实体的位置标签B={b1,b2,…,bn},CRF层计算得分方法如式(4)所示:
(4)
其中,H∈RL×L,为状态转移矩阵,L代表标签的个数,Hbi,bj表示标签bi转移到bj的得分,Pi,bi表示输入序列中,第i个字符被标记为bi的概率得分.标注序列的概率计算方法如式(5)所示:
“早在一九三七年,我们就提出《抗日救国十大纲领》,提出国共合作,建立全国抗日民族统一战线,精诚团结,共赴国难。但你们国民党却一直坚持‘防共、溶共、限共、反共’的反动方针,不断制造摩擦。去年一月,还爆发了骇人听闻的‘皖南事变’。数千抗日将士不是死在鬼子枪下,却死在自己人手里。今年二月,我浙江省委书记刘英同志又被你们逮捕,关押于缙云省党部,至今生死不明。”
(5)
其中,U为所有可能的标注序列的集合.训练时采用负对数似然函数作为位置标签标注的损失函数lb,如式(6)所示:
lb=-logP(B*|W)
(6)
其中,B*是正确的标记序列.最终输出整体得分概率最大的序列,如式(7)所示:
B=argmaxSce(W,B′)
(7)
得到CRF层输出的位置标签后,将实体位置标为1,非实体标为0,得到实体词掩码M,将得到的掩码送至Softmax层参与实体属性解码.
在Softmax层,编码信息经过全连接层处理后,利用Softmax函数求出每个字所有属性的概率值,取概率值最大的属性作为该字的属性标签.Softmax层求取概率如式(8)所示:
(8)
其中,T表示属性总数,ai表示Softmax层第i个节点的输出.Softmax层采用交叉熵作为属性标注时的损失函数,如式(9)所示:
(9)
其中,pt为不同属性的概率,yt表示相应属性的权值,当pt对应的属性为正确属性时,yt设为1,反之,yt为0.利用级联结构传递的实体词掩码M,去掉Softmax层中,非实体的损失函数,如图4所示.
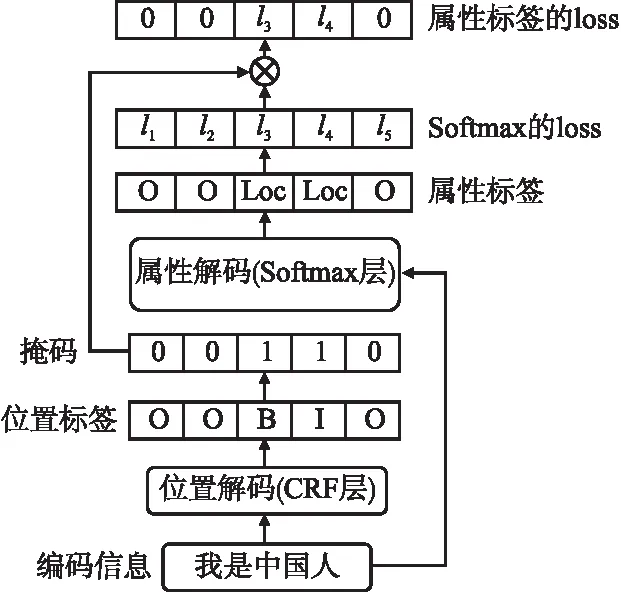
图4 Cascade结构
由图4可知,实体的属性损失函数la的计算方法如式(10)所示:
(10)
模型最终的损失函数为实体位置损失函数与实体属性损失函数的和,如式(11)所示:
l=lb+la
(11)
Cascade结构使得CRF层只需要在BIO标签上进行简单的分类计算,在Softmax层进行属性分类计算,降低了模型的计算量,减少误差;利用掩码机制,加强位置标签与属性标签的对应关系,在Softmax层针对实体计算损失函数,加强模型对实体的学习,提高模型的性能.
2.4 标签处理
模型在CRF层识别位置标签时,会考虑相邻位置标签的合理性,而采用Softmax层识别属性标签时,Softmax层不会考虑相邻属性标签的合理性,实验结果会出现实体中属性标签不一致问题,导致实体识别错误,为解决该问题,本文在属性标签不同的实体上,统计实体内部出现次数最多的属性标签,作为实体最终的属性标签.
将得到的位置标签与属性标签进行拼接,拼接后的标签即为模型预测的实体标签.
2.5 评判指标
实验使用精确率P、召回率R和F1值衡量模型命名实体识别的结果,其中P表示模型识别结果的实体正确率,R表示模型识别结果在实际实体上的正确率,F1为P、R的均衡分.
P、R、F1的计算方法如式(12)、式(13)、式(14)所示:
(12)
(13)
(14)
命名实体识别任务在不同条件下应选用不同指标,若侧重模型识别结果的精确度,应选择P作为评判指标;若侧重模型正确识别的实体数量,应选择R作为评判指标.一般情况下,P、R是一对矛盾的度量,本文为权衡P、R这两种指标,采用F1作为模型实验结果的评判指标.
3 实验及结果分析
3.1 实验数据集
本文在中文文本Resume数据集上进行实验.Resume数据集中包含Title、Organization、Name、Education、Profession、Country、Location、Race 8种实体,实体属性较多,大小为2K,其训练集中实体分布如图5所示.
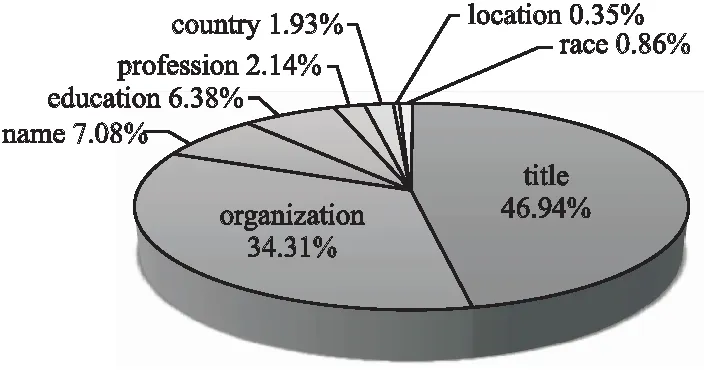
图5 Resume训练集实体分布
由图5可知,在Resume训练集中,占比最多的Title实体比占比最少的Location实体多出46.59%,数据量相差134倍,且除去Title与Organization两种实体占比超过10%,其余实体占比均少于10%,实体分布极其不均,文本空间复杂度高.
3.2 实验设置
本文基于tensorflow1.15学习框架,使用的GPU为Tesla K80,编程语言为Python3,开发工具为Pycharm.实验配置如表2所示.

表2 实验环境配置
模型使用BERT结构编码字向量,本文采用的BERT结构有12层,其中隐层为768维,并采用12头注意力机制,BERT的学习率设为3e-5,最大句长设为128.空洞卷积滤波器尺寸设为3,个数设置为300.模型采用Adam优化函数,初始学习率设为3e-5,dropout设为0.5,train_batch_size设为32,eval_batch_size设为8,epoch设为4.模型具体实验参数如表3所示.
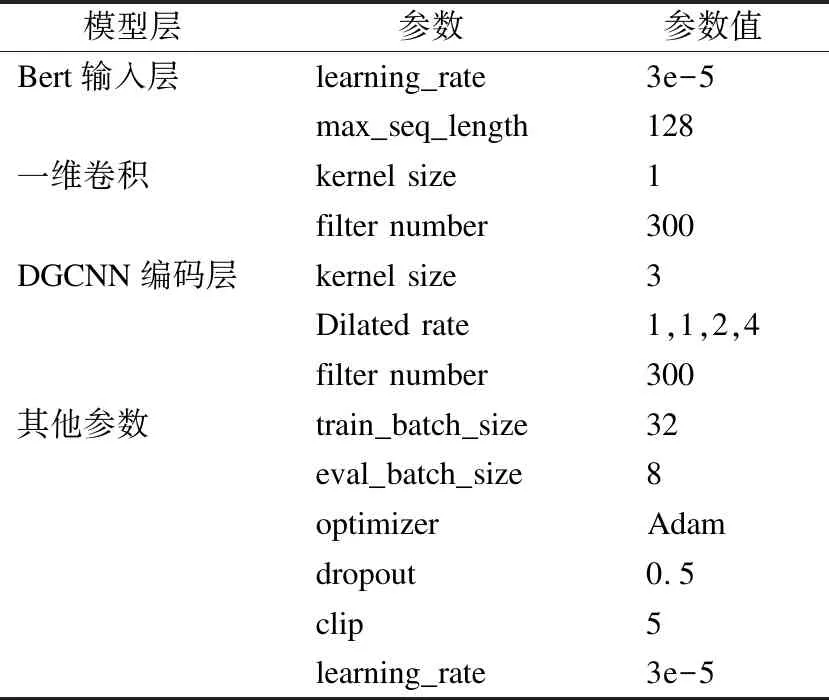
表3 模型实验参数
3.3 实验结果与分析
3.3.1 模型有效性实验
为验证本文提出的DGCNN、Cascade结构的有效性,本文在Resume数据集上,将本文模型(模型4)与传统的BERT+BiLSTM+CRF模型(模型1)、BERT+DGCNN+CRF(模型2)、BERT+BiLSTM+Cascade+CRF模型(模型3)进行对比实验,得到的实验结果如表4所示.

表4 模型有效性实结果(%)
根据表4的实验结果进行比较分析.结合BERT+BiLSTM+CRF模型与BERT+DGCNN+CRF模型的实验结果、BERT+BiLSTM+Cascade+CRF模型与BERT+DGCNN+Cascade+CRF模型实验结果可知,相较于BiLSTM结构,使用门控空洞卷积,模型的F1值相差不大,但运算速度得到提升,表明DGCNN结构可提高模型的运算速度,并能有效提取特征信息,证明了DGCNN结构的有效性.
结合BERT+BiLSTM+CRF模型的实验结果与BERT+BiLSTM+Cascade+CRF模型的实验结果、BERT+DGCNN+CRF模型与BERT+DGCNN+Cascade+CRF模型的实验结果可知,加入Cascade结构,模型的精确度P分别提高了3.03%、3.12%,召回率R分别降低了1.04%、1.04%,说明Cascade结构降低了模型预测的实体数量,减少了预测结果中错误识别的实体个数,表明Cascade结构增强了模型对实体的学习,模型更倾向识别出正确的实体,有效提高了模型的精确度;同时,加入Cascade结构,模型的P、R指标更为均衡,使得模型的F1指标分别提高了1.02%、0.97%,表明Cascade结构有效提高了模型的性能,验证了Cascade结构的有效性.
3.3.2 模型优越性实验
为验证模型的优越性,本文在Resume数据集上与其他模型的实验结果进行比较分析.各模型在Resume数据集上的实验结果如表5所示.
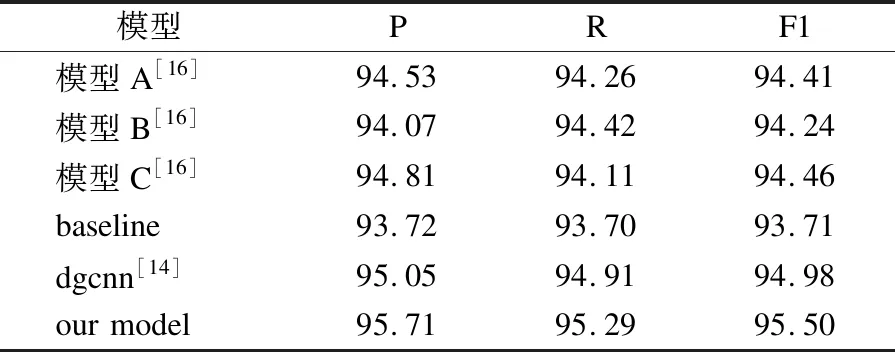
表5 Resume数据集上实验结果(%)
表5中,模型A表示Zhang等人提出的基于字向量输入的LSTM模型[16],模型B表示Zhang等人提出的基于词向量输入的LSTM模型[16],模型C表示Zhang等人提出的词格模型[16],dgcnn表示王等人提出的基于门控空洞卷积的模型[14].由表5的实验结果可知,本文提出的模型在P、R、F1指标上均取得了更好的结果,相比baseline模型,本文模型的P、R、F1指标分别提高了1.99%、1.59%、1.79%;相比dgcnn模型,本文模型的P、R、F1指标分别提高了0.66%、0.38%、0.52%.实验结果表明本文提出的BERT+DGCNN+Cascade+CRF在中文命名实体识别任务上能取得较好结果,模型具有优越性.
3.3.3 实体实验结果分析
本文分析模型在单个实体上的识别结果,验证模型的性能.BERT+DGCNN+Cascade+CRF模型在单个实体上的实验结果如表6所示.
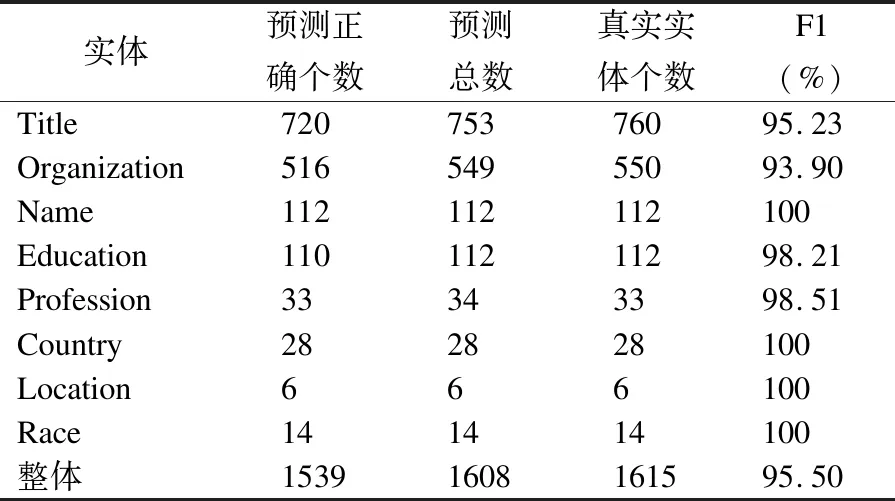
表6 模型实验结果
结合表6可知,模型在Name、Country、Loctation、Race等4个实体上的F1值达到了100%,在Title与Organization实体上的F1值相对较低.对于Name实体,在数据集中有较强的边界划分,一般出现在每一句的开头,模型容易识别;对于Country、Loctation、Race实体,由于数量较少,模型容易学习到实体的特征,能正确识别.对于Title与Organization实体,这两类实体较长,且在数据中常成对出现,例如“北京物资学院客座副教授”一句中,“北京物资学院”是Organization实体,“客座副教授”是Title实体,两类实体相邻,没有明显的边界划分,模型较难识别.
由表6中的F1值可知,模型实验结果整体的F1值不等于所有实体F1值的平均值,这是由Resume数据集中实体分布不均造成的.
3.3.4 标签实验结果分析
为验证表6的实验结果,分析模型在具体标签上的实验结果,如表7所示.
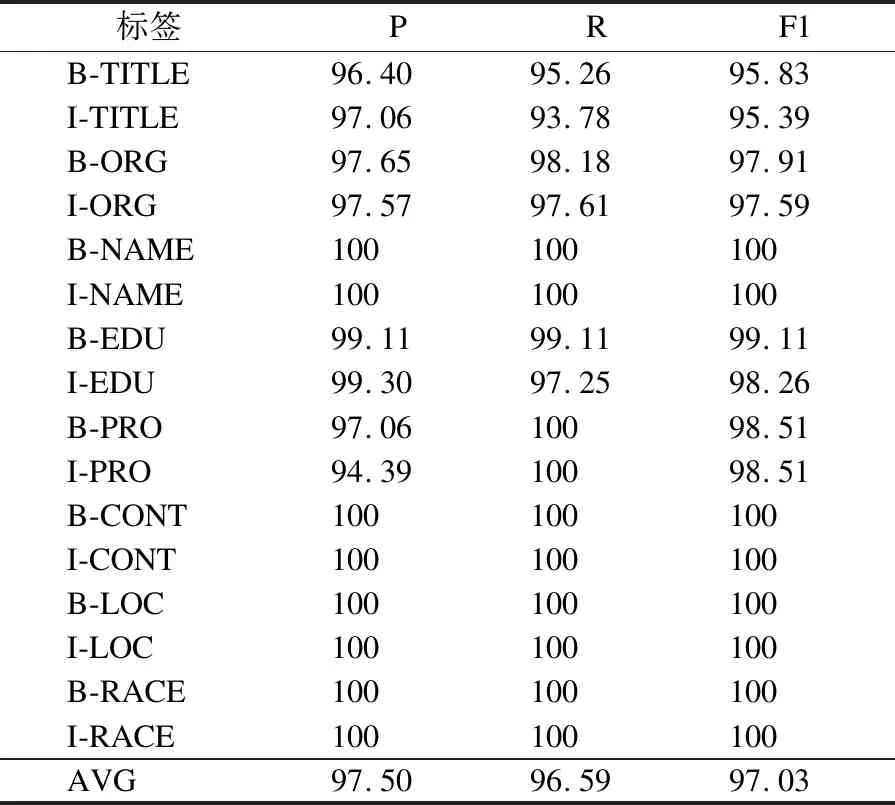
表7 标签实验结果(%)
由表7可知,模型在B-NAME、I-NAME等8个标签上实现了正确的预测,在B-TITLE等6个标签上不能实现准确地预测,但F1值都超过了95%.表7的标签实验结果验证了表6中模型在单个实体识别上得到的实验结果.
3.3.5 典型错误案例分析
结合表6、表7,分析实验文本数据可知,Title、Organization实体较长,在对长实体识别时,模型存在不能完全识别的情况,部分典型错误案例如表8所示.

表8 典型错误案例
由表8可知,在Organization实体“国内贸易部”中,错误地将“国内”识别成“O”,导致实体识别错误;在Organization实体“大冶有色金属公司赤马山矿”中,将“赤马山矿” 识别成“O”,未能完全识别出长实体.同时,模型也存在将长实体识别成多个实体的情况,例如在长实体“天津市政府共同领导组建的北洋(天津)钢材批发交易市场”中,整体为Organization实体,而模型在识别时,将该实体识别成“天津市政府”与“北洋(天津)钢材批发交易市场”两个Organization实体.分析错误案例可知,模型在长实体识别上的误差降低了模型在Title与Organization实体上的F1值.
4 总 结
本文提出基于门控空洞卷积与级联结构的BERT+DGCNN+Cascade+CRF模型,在中文文本上进行实体识别,取得了良好的结果,在模型识别速度上得到提升,在识别精度上也得到改善.DGCNN解决了BiLSTM无法并行运算的问题,加快模型训练速度;Cascade结构将实体的位置标签与属性标签分开训练,构成多任务学习架构,降低在CRF层中分类计算的复杂度,增强了模型的学习能力,提高了模型精度.本文提出的门控空洞卷积与级联结构的网络为后续中文命名实体识别研究提供了一定的研究价值.
中文文本中的长实体识别仍较为困难,在后继的研究中,将对中文文本中长实体的识别进行深入研究,以期提高模型性能.
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
故事作文·高年级(2017年2期)2017-03-01
新闻传播(2015年20期)2015-07-18
世界科学(2013年11期)2013-03-11
