
面向非结构场景中垃圾拾取任务的高效感知方法
2023-05-23 14:45吴旭明米金鹏胡卫兵李清都
小型微型计算机系统 2023年6期
吴旭明,米金鹏,刘 丹,胡卫兵,唐 宋,李清都
1(上海理工大学 机器智能研究院,上海 200093)
2(上海理工大学 光电信息与计算机工程学院,上海 200093)
3(中原动力智能机器人有限公司,郑州 450000)
1 引 言
在自动化技术不断应用的现今,智能抓取任务具有广泛的应用前景与较高的研究意义,例如:垃圾拾取、物流分拣、生产线自动化等方向.自动化处理不仅能节省人力,更能提高工作效率、保障工作场景的安全性与可管理性.
以垃圾分拣工作为例,众多的垃圾分拣场景都需要大量人力资源来处理,而在这个处理过程中,一线工人不仅要工作在恶劣环境下,还要受到长期工作劳动与垃圾中有害物质对人体造成的不可逆伤害.为这类任务明确、效率与安全都需考量的工作场景制定最优的解决方案,自动化抓取技术是必不可少的重要环节.
基于计算机视觉的智能机械臂抓取,使用深度相机等外部设备对目标进行采样,再使用传统机器学习、图像处理、深度学习等方法分析与处理图像信息.结合视觉信息,令机械臂可以有效地在动态环境中,获取物体位置、姿态、类别等信息.
基于视觉的机械臂抓取方法主要分为两种:使用传统的机器学习以及使用深度学习.传统的机器学习已经发展了数十年,例如:SVM(Support Vector Machine),聚类,决策树等等,这些方法的最大优势在于它只需要少量的训练数据,并且具有较强的可解释性和较快的运行速度.文献[1]使用SVM-rank算法训练了一个三阶段学习模型,能够为五指机械臂生成可行的抓取策略.文献[2]从物体图像序列中提取局部特征并使用改进后的模糊C-Means聚类,然后把每个图像的关键点映射到统一维度的直方图矢量中,最后将该直方图视为多类支持向量机的输入向量,以建立训练分类器模型并实时识别运动对象.但伴随着大数据时代数据的爆炸式增长,传统机器学习方法体现出了疲态.这些方法通常需要多种算法同时使用,才能实现较为完整的目标识别、定位、抓取任务,加大了模型设计与训练难度.同时这些方法通常根据特定任务人工设计而成,容易受到任务内容、目标物体外型等因素的影响,即模型的泛化能力不强,难以迁移至新任务[3].
2012年,Hinton等人[4]提出AlexNet架构,是深度学习在图像领域的重要里程碑.自此,基于CNN(Convolutional Neural Network)的架构也逐步应用于机械臂抓取任务.文献[5]使用Faster-RCNN获取目标物体的一组候选框,再将这些特征融合输入两层全连接网络进行最佳抓取位置的预测,获得了较好的抓取预测效果.文献[6]方法使用级联式Faster-RCNN模型预测目标物体位置和物体抓取角度.文献[5,6]均采用Two-Stage的方法,该类方法相较于One-Stage的YOLO架构,拥有更高的识别精度,但检测速度较低.文献[7]提出了一个基于视觉可扩展的自监督强化学习框架,并使用7个工业机械臂分布式训练4个月,可以实现自动规划抓取策略,确定抓取姿态和动态响应外界各类扰动,最终得到高达96%的抓取成功率.此方法具有很强的泛化能力以及抗干扰能力,但该框架需要基于大量的数据、设备和时间成本.不适用于常规的生活与工业应用.
现有方法中,机器人感知任务大多得益于深度学习,获得了更高的感知精度.而这些方法无法直接迁移至移动机器人、嵌入式设备等低算力平台.针对多目标、物体姿态不固定、非结构化视觉场景以及需要检测速度的感知环境,本文结合垃圾拾取的具体任务提出一个高效感知方法,其中感知主要分为目标检测和物体姿态估计.本文的主要贡献如下:
1)构建了一个具有12个类的垃圾识别数据集.
2)提出了基于YOLOv4目标检测和TensorRT加速的高效感知方法.该方法设计了一种基于K-means++聚类算法的深度信息优化方法并通过相机内参矩阵计算物体位置信息,最后结合RGB图像使用图像形态学变化和Canny边缘检测算法实现物体主方向角度估计.整体感知方法框架结合深度学习方法和传统的机器学习方法,完成目标识别、目标定位和抓取角度估计3个任务,优点是实时性强且计算简便.
2 数据集
针对垃圾拾取任务,本文构建了一个具有12类垃圾的识别数据集.其中数据集的[Cylinder,Shoes]两个类别的功能主要是用于移动机器人抓取过程中,对行人进行避障,数据集的分类类别以及部分数据样例如图1所示.

图1 数据集样例(12分类)
整个数据集共标注有9792张图片,69477个标注边界框.数据每个类别的标注边界框数量分布图,如图2所示.
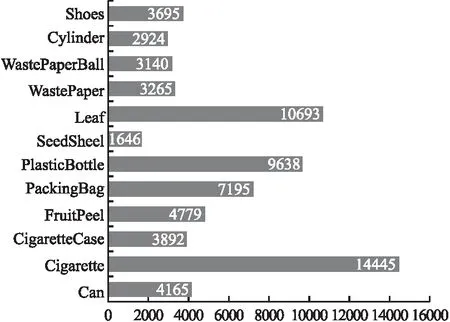
图2 各类数据的边界框数量分布图
近些年,已经逐渐使用深度学习方法来分类、检测和分割非结构化场景中的垃圾[8-10].为了预训练或微调深度模型,也有许多相关数据集被建立,一些公开数据集的统计数据如表1所示.
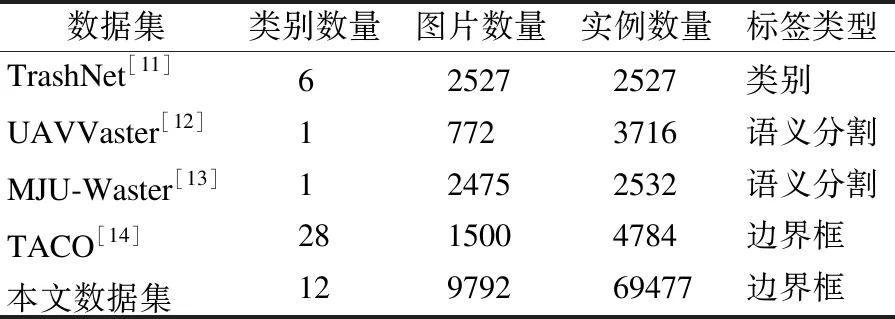
表1 公开垃圾数据集统计数据
针对非结构化场景中的垃圾拾取任务,UAVVaster和MJU-Waster两个数据集仅有一类,容易造成实际应用情况下,无法识别不同类别的垃圾,以此反馈相应的抓取状态.
TrashNet数据集实例背景颜色和纹理都较为单调(纯色),在实际环境下,应用效果较差,且该数据集只有类别信息,无法适用于检测任务.
TACO数据集类别丰富,28个大类下还包含60个子类,但是该数据集的数据实例数量分布明显不平衡[15],容易造成模型的过拟合.
本文构建的数据集通过分析实际的应用场景,针对实际场景的特点采集了数据.相对于现有数据集,本文数据集垃圾类别和实例数量丰富,类别分布均匀,实例背景具有一定复杂度,可应用于实际场景下的垃圾检测问题.
3 高效感知框架
整个框架硬件方面主要包括深度相机Intel RealSense D435和自主搭建的六自由度轻量型机械臂.机器人平台实体,相机与机械臂的大体位置结构,如图3中最左侧图所示.
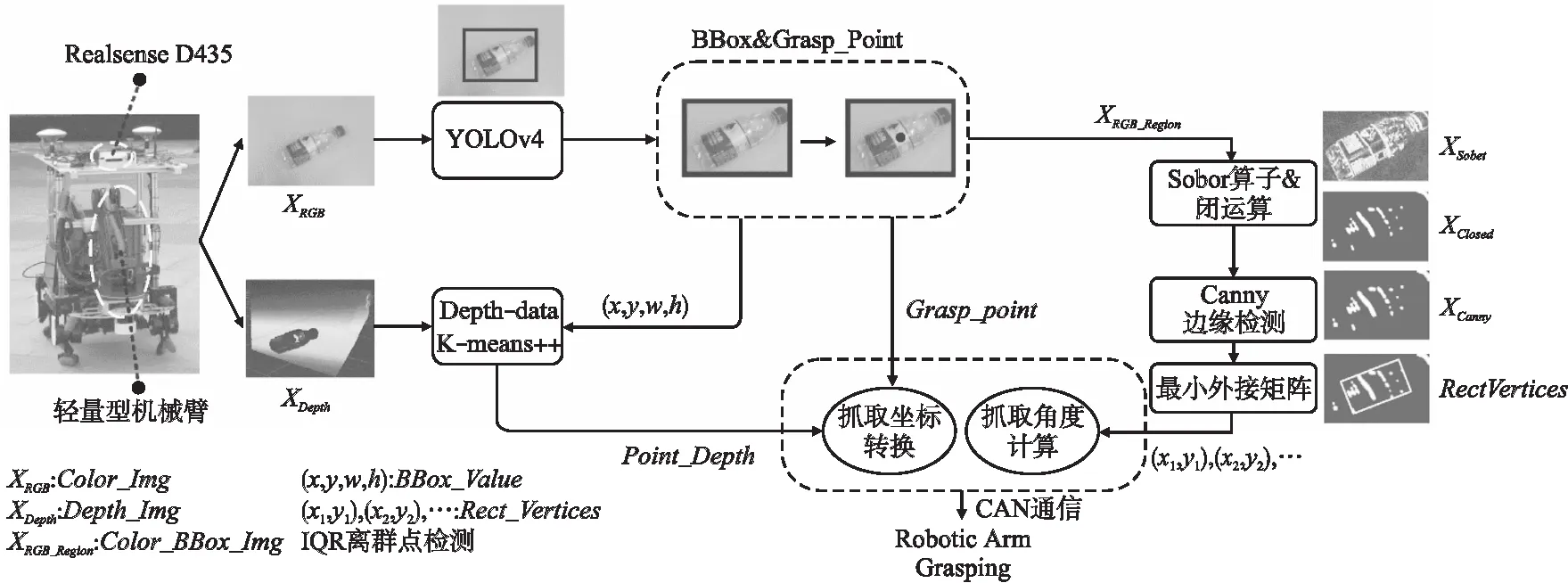
图3 高效感知方法框架图
高效感知方法总体分为3个部分:目标检测算法,物体定位以及物体姿态估计.首先,使用深度相机获取目标区域的彩色图与深度图,将彩色图输入YOLOv4检测模型中,获得相机视野范围内多个物体的边界框和类别;其次,结合深度图,利用K-means++聚类算法和四分位距异常点检测获取目标物体的深度信息并计算目标的抓取坐标;再次,结合彩色图、图像形态学变化和Canny边缘算法快速获取目标物体的抓取角度;最后根据先前获取的抓取坐标与抓取角度信息,实现机械臂的抓取任务.整体感知方法框架如图3所示.
4 目标检测算法
基于深度学习的常用目标检测算法主要可以分为两种:two-stage方法和one-stage方法.
现有的two-stage目标检测模型大多采用单独的模块生成候选区域(Region Proposal)[3].检测的第1阶段,模型从原始图中选取大量的目标候选区域;检测的第2阶段,模型对这些区域进行分类和定位.由于这类模型具有两个独立的步骤,因此它们通常情况下,需要更长的处理时间,但带来的是更高的检测精度.其中经典的模型有:R-CNN[16]、Faster-RCNN[17]等等.
与之相对的,one-stage检测器使用各种比例的预定义框或关键点来定位对象,将物体的类别概率和位置坐标直接视为回归问题,因此该类检测器具有更高的实时性和更简易的模型设计.其中经典的模型有:SSD[18]、YOLO系列[19,20]等等.
结合垃圾拾取的实际任务和移动机器人的具体实验场景以及一些典型模型在本文数据集中的实验结果对比(详细见7.1节),本文选用更为轻量化的one-stage检测器中的YOLOv4模型,以实现高效感知任务.同时在硬件中部署Nvidia TensorRT用于提高模型的前向推理速度.
4.1 YOLOv4目标检测模型
YOLOv4架构是在原有YOLOv3架构的基础上,从主干网络、数据增强、模型训练、特征融合等多个方面引入当前最先进的方法,从而获得一个高效且强大的目标检测模型.该模型主要由3个部分组成:主干网络(Backbone)、颈部(Neck)和头部(Head).YOLOv4架构3个部分的主要功能以及相较于YOLOv3的改进点如下:
1)Backbone:该部分负责图像的特征提取,用于整体模型前端提取丰富的图像信息,生成特征图供后续的网络使用.YOLOv4的主干网络使用了CSPDarknet53,该主干网络是在Darknet53的基础上结合CSPNet[21](Cross-Stage-Partial-connections)改进而成,可以大幅减少计算量.改动部分主要体现在ResBlock.
2)Neck:该部分主要就是用各类方法处理或融合主干网络提取出来的特征,从而提高网络的性能.YOLOv4在这个部分的改进是使用了SPP(Spatial Pyramid Pooling)结构[22]和PANet(Path Aggregation Network)结构[23].SPP结构使用4种不同尺度的最大池化,它能够很大程度地增加感受野,并找出最显著的特征信息.PANet结构缩小顶层与底层特征之间的信息路径,可以较好地保留浅层特征.
3)Head:该部分的功能就是将经过融合的主干网络特征信息用于目标分类与定位.此处YOLOv4和YOLOv3是相同的.
YOLOv4除了在模型架构上有修改,还在激活函数、模型训练、数据处理等等方面都应用了非常多的最新技术.例如:数据增强Mosaic,激活函数Mish[24]等等.
4.2 TensorRT
TensorRT是一个针对深度学习前向推理的优化器,可以为嵌入式等边缘计算平台进行推理加速.TensorRT的优化方法如图4所示,其中最主要的是层间/张量融合以及数据精度校准.前者通过合并层间的模块,使其占用更少的CUDA核心,以此提高推理速度.后者则是适当降低数据精度,从而压缩模型体积.
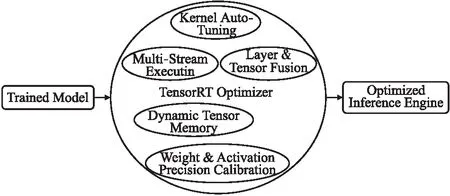
图4 TensorRT优化方法
5 抓取目标坐标定位
当YOLOv4模型输出目标边界框之后,把框的中心点作为抓取点.将框内所有像素点的深度值聚类为3类,排序第2的聚类中心值作为抓取点到相机成像镜头的距离.最后使用相机内参矩阵进行矩阵转换获取抓取点坐标.
经典的K-means算法从数据集中随机选取K个样本作为初始的聚类中心.它有如下几个缺点:
1)数据中的异常点(噪声数据/离群点)会对均值产生较大的影响,最终导致中心偏移.
2)不同的簇中心初始值会影响聚类结果.
针对上述存在的两个问题,本文分别采用边界框缩小、四分位距和K-means++进行改进.
5.1 物体边界框改进
YOLOv4输出的标准边界框,并不是严格贴合物体边界.即边框的边界区域有可能对应的是目标物体背景的深度信息(异常值),从而影响聚类效果.因此本文先对物体边界框进行缩小,初步减少异常深度值以及整体的深度数据.
首先通过YOLOv4模型返回抓取目标的边界框大小与位置值(x,y,w,h),4个值分别对应边界框的左上角的坐标、框宽和框高.然后使用以下公式得到新的边界框值(x′,y′,w′,h′)用于深度值聚类:
(1)
w′=λw
(2)
y′和h′计算方式分别同x′和w′一样,λ为边界框缩放比例.
5.2 IQR异常深度信息检测
由于光照,相机硬件以及物体背景等外部因素,使得目标范围内通常会具有很多异常深度信息,从而影响深度值聚类的最终效果.因此本文先利用箱型图的四分位距IQR(Interquartile Range)删除一些异常点,再使用K-means++进行区域深度值聚类.
同时删除异常值之后,会使数据量减少,从而令深度值聚类的速度提升.
5.3 K-means++算法
K-means算法从数据集中随机选取K个样本作为初始的聚类中心,相对应的,这些聚类中心的初始值也是随机的.而不合适的初始值会直接影响聚类的效果.
本文选用的K-means++算法[25]则是令初始的聚类中心彼此尽可能的远离,以此来获取更好的初始值.算法初始点选择的步骤如下:
1)先设定簇数k,然后从输入样本X中随机选取初始聚类中心c1,并将聚类中心放入空集合⊂X.
2)计算数据集X中的每个样本数据与当前已有的聚类中心c∈,之间的最短距离D(x).然后使用下述概率公式以及轮盘法选取下一个聚类中心ci=x′∈X:
(3)
3)重复执行步骤b),直到选出k个聚类中心.
之后的聚类过程与标准的K-means算法一致.
5.4 抓取坐标计算
像素坐标到世界坐标的转换过程如下:
(4)
上述公式中:K-相机内参矩阵,M-相机外参矩阵(其中R、T分别为相机与世界坐标系之间的旋转矩阵和平移矩阵),Xw-为目标物体在世界坐标系的坐标,(u,v)-像素坐标(抓取点).其中世界坐标系原点定为:机械臂底座原点.
由于制造工艺的问题,相机镜头还存在径向和切向畸变两个问题.因此坐标转换之间还需要进行畸变校正.畸变参数distortioncoeffs=[k1,k2,k3,p1,p2].抓取点在相机坐标系下的坐标(xc,yc,zc)计算过程如下:
(5)
(6)
(7)
公式(6)为畸变校正计算,获取物体相机坐标之后,再根据相机与实验平台的相对位置获取外参矩阵M.最后计算得到抓取目标在世界坐标系下的真实坐标.
6 抓取角度估计
文献[26,27]与文献[5,6]类似,他们都是使用Cornell数据集训练一个two-stage的最优抓取位置检测模型.这类方法在没有高性能GPU的前提下,检测速度都较慢.文献[28]则是通过改变机械臂执行末端,采用吸取的方式,完成类似任务,这也就不需要进行角度估计.文献[29]则是根据实验经验,将抓取状态设定为固定的3个角度.这个方法可扩展性不强,且实际应用具有较多抓取死角.文献[30]结合Canny算法和Hough算法,估计物体角度,但当物体背景复杂时,会提取到与物体主方向不一致的直线,从而影响算法效果.
非结构场景中,抓取目标物体周围往往会具有干扰信息,例如:阴影、强光、物体材质以及背景纹理等等,这些干扰会影响相机硬件的传感器检测效果和深度模型效果.为了在复杂场景中能够迅速获取物体的抓取角度,本文提出基于Canny算法[31]和图像形态学变化的抓取角度估计方法.首先是截取具有抓取目标的边界框区域,然后使用Sobel算子加强全图像的边缘信息,再通过阈值设定和图像闭运算获取主物体像素信息.最后使用Canny检测主物体边缘信息,并求解最小外接矩阵.矩阵具有4个返回坐标[(x1,y1),(x2,y2),(x3,y3),(x4,y4)],其中矩阵最左上角的顶点为(x1,y1).鉴于反三角函数值域问题以及图像坐标系问题,因此将两个向量以x轴进行镜像变换,并将差向量的起始点平移至原点.外接矩阵第一条边的角度计算公式如下:
x′=x2-x1
(8)
y′=-y2+y1
(9)
(10)
算法1.抓取角度估计方法
输入:BBox区域的彩色图XRGB_Region.
输出:抓取目标的角度Grasp_Angle.
a)全图边缘信息
XSobel←Sobel(Xgray,dx=1)-Sobel(Xgray,dy=1)
//Xgray由XRGB_Region获取
b)主目标图像信息
XClosed←morphologyEx(threshold(XSobel),Close)
c)目标边缘信息XCanny←Canny(XClosed)
d)if(m,n)∈XCanny<η*BBoxdo//η为边缘选取范围0~1
e)最小外接矩阵顶点[(x1,y1),(x2,y2),(x3,y3),(x4,y4)]
RectVertices←minAreaRect()
利用公式(8)~公式(10)计算
elseifdo
利用公式(8)~公式(10)计算
returnGrasp_Angle
7 实 验
7.1 目标检测模型实验结果
本实验中,模型使用GPU进行训练,型号为Nvidia GeForce RTX 2060S.实际运行平台为:Nvidia Jetson Xavier NX.实验先对3个模型进行初步对比,识别准确率结果如表2所示.

表2 目标检测模型对比实验
YOLOv4相较于两个经典的two-stage模型,在识别准确率上依然具有优势,因此选定YOLOv4作为抓取任务的检测模型.该模型的训练方法为:图片输入尺寸为(608,608);随机选取训练集、验证集分别为8151和1641张;数据增强使用mixup、blur等;模型的anchors不直接采用COCO数据集的初始设定,而是根据12分类垃圾数据集的GT(Ground Truth)框大小分布重新生成.YOLOv4在该数据集的实验结果如表3所示.
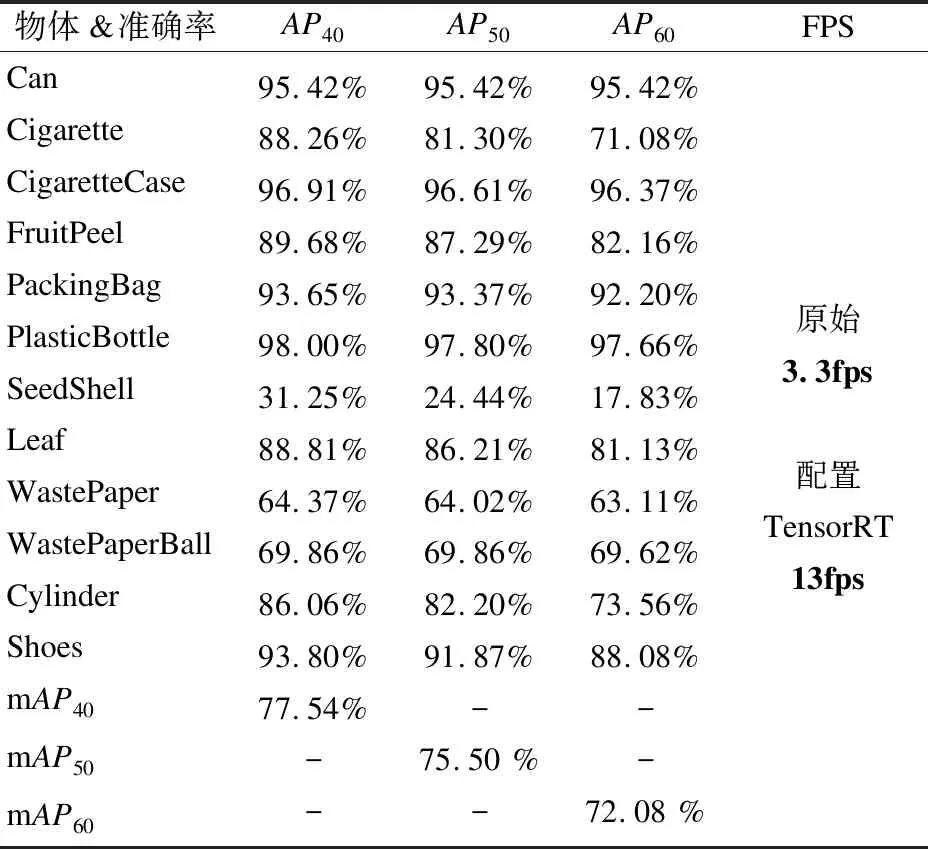
表3 YOLOv4检测结果
从实验结果中可以看出,SeedShell类别的识别准确率很低,这可能是由于数据集中的SeedShell数据量太少.YOLOv4在Xavier NX上运行的原始FPS为3.3,在部署TensorRT之后,能稳定在13FPS左右.实际运行的目标检测效果如图5所示.

图5 YOLOv4目标检测实际效果
7.2 K-means++深度聚类结果
深度聚类实验中,本文先将检测器输出的边界框进行缩小,初步降低深度数据量以及部分异常值,再使用四分位距进一步删除深度值中的离群点,异常点检测效果如图6(上)所示.最后使用去噪过后的深度信息,进行深度值聚类,设定聚类中心为3类,取第2个中心值为最终的抓取点深度值.聚类结果如图6(下)所示,深度值对比实验结果如表4所示.
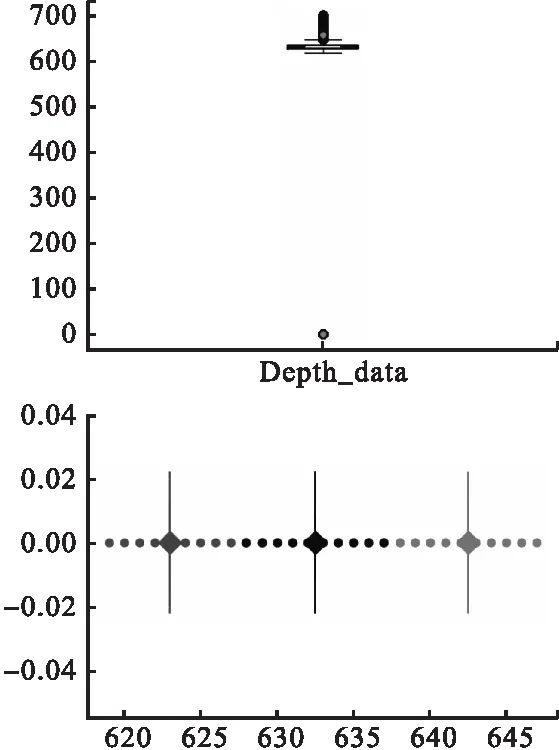
图6 深度值四分距检测(上)和深度值聚类结果(下)
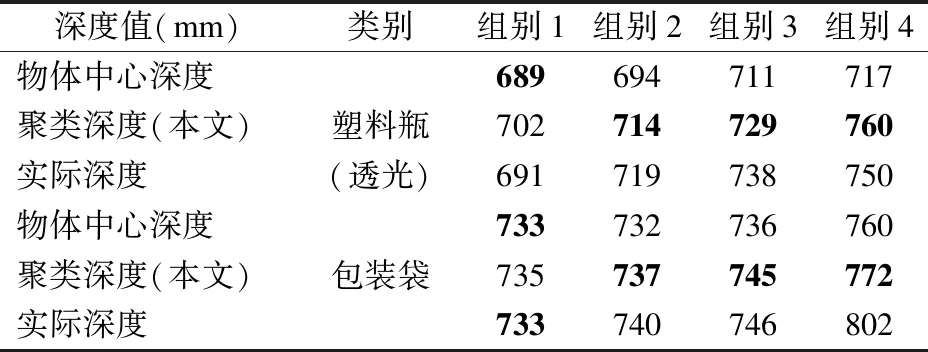
表4 深度值聚类实验对比结果
表4中,物体中心深度是指不经过任何处理,直接选取抓取点的深度值信息;聚类深度是指使用本文优化方法获取的深度值信息.
实验使用两类物体,塑料瓶和包装袋,每类采集4个组别进行对比.从表中的数据可以看出,直接选取某个点的深度值,可能会出现与实际结果相差很多的深度信息,该现象在透光物体中尤其常见.撇除相机本身的测量误差,有可能是因为红外传感器通过透光物体,导致返回异常的深度值.实验结果表现出本文的聚类方法能一定程度上弥补硬件以及透光物体带来的异常深度信息.
7.3 角度估计结果
图7共有4个实例,每个实例共有4张结果图,分别为角度估计中的4个主要步骤.其中①、②为裁切过的数据集原图处理结果,③、④为实际目标检测边界框区域处理结果.从实例③的Sobel图中可以看出,图的左下角具有干扰信息(其他物体);实例①、②则是物体背景具有明显的纹理.对于这类非结构场景中遇到的干扰信息,在经过阈值设定以及形态学变化后,图中的部分干扰像素会被消弱或消除.为了进一步消除目标以外的像素干扰,在选取Canny边界信息的时候,会基于边界框缩小选取范围,对应算法1中的步骤d.

图7 角度估计方法实验结果.其中每个实例:Sobel(左上)&闭运算(右上)& Canny(左下)&最小外接矩阵(右下)
表5为角度估计实验,共4组,其中组别号分别对应图3中的序号,组别2和组别4的结果误差可能是由于主物体的像素信息在形态变化过程中也被一定程度地消除,但该误差不影响机械臂的抓取任务.

表5 角度估计实验对比结果
表6为角度估计检测速度对比实验.现有方法中,大多是使用深度学习的方法估计物体角度,该类型方法感知能力比较强大,它同时还能够检测到物体的最优抓取位置.但从表中的数据可以看出:该类型方法即便在强大的GPU算力支持下,检测速度仍旧较为不足,其较高的计算要求和功耗要求,也使得该类型方法无法部署到轻量型的移动机器人上.而本文使用的角度估计方法,在CPU上运行时间仅需4.3ms,能够高效的完成对应任务.

表6 角度估计检测速度对比结果
图8为本文整体感知方法部署到移动机器人上的实际抓取展示图.

图8 机器人抓取展示图
8 结束语
本文针对移动机器人垃圾拾取任务,提出一个结合深度学习和传统机器学习的高效感知方法.在多目标、物体姿态不固定、非结构化视觉场景以及需要检测速度的感知环境中实现了目标的识别、定位与角度估计.
从目标检测的实验结果来看,对于常见的垃圾,如塑料瓶,包装袋等都具有较高的识别准确率和检测速度.深度聚类实验中,验证了该方法能够一定程度上优化目标物体的深度信息.抓取角度估计实验,验证了该方法检测的实时性强,可以较为准确的估计物体主方向角度,同时可以消除或消弱目标物体周围的一些干扰信息.
未来的研究方向与改进点有两个:1)继续丰富与改善本文数据集,例如:解决SeedShell类的实例不平衡问题;2)优化本文的抓取框架,例如:提高检测模型的稳定性与实时性,进一步优化角度估计方法等等.增强感知方法框架的整体一致性,使其可以更加稳定、高效地运行在移动机器人上.
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中学生数理化·高一版(2020年1期)2020-02-20
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
科普童话·百科探秘(2015年4期)2015-05-14
电子设计工程(2015年6期)2015-02-27
