
一种基于树莓派部署的改进YOLOv5 植物生长状态检测算法
2023-05-17 03:16:44崔强周艳肖洒赖盛鑫
电子技术与软件工程 2023年5期
崔强 周艳 肖洒 赖盛鑫
(联通(上海)产业互联网有限公司 上海市 200050)
植物是大自然基本资源,是食物、药物的主要来源。植物在地球上担任着至关重要的角色,它们是地球生态系统的基础,提供氧气和食物,维持着地球上所有生命的生存。植物也可以被用于制药、香料、染料、建筑材料和燃料等领域。虽然植物的生命周期和繁殖方式与动物有很大不同,但是它们同样具有适应环境、生长和进化的能力,是生命在地球上最为多样和美丽的表现之一。作为世界上有名的农业大国,提高农作物生产是一项非常具有挑战性的工作,因此,对植物的研究和识别对人类生活与研究有着重要性和一定的指导意义。
随着社会的发展,时代的脚步不断前行,植物的生长和发育的重要性比重越来越大。然而,确认植物的生长状况是一项耗费时间和具有挑战性的任务,需要大量的人工投入和专业技能。传统的确定植物生长状态的方法依赖于培育者的目视检查[1],这种方法依靠大量富有经验的劳务工作者,判断标准相对来说比较主观,速度慢,成本高,效率低,主观性强,准确率低,时效性差等缺点,非常容易出现误差。
近年来,计算机视觉技术在自动化植物生长分析和提高植物生长监测的效率和准确性方面展现了巨大的潜力[2]。人工智能的兴起与实时视频流摄像机监控的结合,加上计算硬件的迭代更新,使得通过视觉对植物状态检测具有高可行性[3]。基于视觉的检测模型中,YOLO 系列与SSD 已经非常成熟[4-8],在很多场景都有标准的落地方案。因此,应用深度学习于植物检测,能够显著地降低工作负担并缩短识别所需时间[9]。
计算机硬件与软件技术的发展,使农业与计算机工程技术的联系更加紧密。借助计算机视觉、机器学习、深度学习算法等创新工具,在植物检测方面有广阔的前途。然而,经典的机器学习大多依赖于手工制作的低级视觉特行证,这些特征是根据工程经验设计的。当捕获场景相对复杂时,这通常会导致性能不尽如人意。基于CNN 的模型通过端到端的方式来自动学习低级判别特征和模型参数,使得非专家也更容易处理基于计算机视觉的农作物检测任务[10]。然而,由于CNN 网络自身的特点,参数量大和计算开销大,从而限制了大多数CNN 模型只能在具有GPU 加速的高性能服务器上实现。这样的特性限制了CNN 在植物检测领域的应用[11]。
已经提出了各种计算机视觉算法用于植物生长监测和病害诊断。YOLOv5 是一种流行的目标检测算法[12],已广泛用于各种应用,包括植物生长监测。然而,YOLOv5 的高计算复杂性限制了其在树莓派等低功耗设备中的应用。为了使YOLOv5 模型更加实用并适合部署在端侧设备进行实时检测,在学术界、工业界已经提出了许多轻量化的方案,但随之而来的是精度的降低。因此,为了提高轻量级模型的精度,可以在网络结构中加入注意力机制,并以此作为输入,在特征层的每一层分配不同的权重,提取更广阔的全局特征,从而提高检测效果。此外,注意机制的特点也决定了其对模型的推理速度影响很小,且不需要分配额外的大空间[13]。
为了迎接这个挑战,在本文中,我们提出了一种改进版YOLOv5 网络,而这种网络的网络结构更简单、计算参数更少,是一种轻量级的网络,并可以在树莓派上实时检测植物的生长状态。我们引入了多种新颖技术,如Ghost 模块、注意力模块,来优化模型的性能。我们还构建了一个全面的植物生长图像数据集,并将植物的生长状态分为五类,以便于模型的训练和评估。实验结果表明,我们提出的方法有潜力改变植物生长监测,并提供一种更为高效和准确的评估植物生长状态的方法。我们的模型轻量且实时的特点也使其能够在低功耗设备中应用,大大扩展了其潜在的应用场景。
1 相关工作
1.1 数据集准备与预处理
本文使用的数据集图片是通过实时摄像机在植物培养的大棚中拍摄视频录像,然后按照固定时序间隔截帧获得的。因此,在架设摄像机时,要求光线充足,可以完整的覆盖植物的特征。使用摄像机采取实时视频流的原因有三点。
(1)数据集的样本数量必须充足,且包含了植物生长的整个周期,获取到的视频源需要通过严格的筛选来确定数据是否符合要求。而且在数据打标的时候,数据集的图片质量非常重要。
(2)本文研究的算法最终面向的是落地应用,因此摄像头监控植物生长态势与获取数据源,与实际应用场景一致。
(3)边缘端设备树莓派4B 版本,支持通过USB接口直连摄像机,符合预期和整体业务设计。
为了让训练样本更符合实际情况,本文拍摄的图片基于多种情况下不同角度对植物进行拍摄,并对训练集的样本进行了数据增强处理,尽可能的消除了无用照片的面积,减少干扰物对模型的影响。使用开源标注工具对图片进行标注。共计图片总数为5323 张。
1.2 注意力机制
注意力是一种认知过程,它选择性的作用于相关信息而忽略深度神经网络中的其他信息。最早起源于自然语言处理,如今已广泛的用于各种领域。Squeeze-and-Excitation(SE)在ImageNet2017数据集上获得了冠军[14],而卷积注意力模块(CBAM)结合了通道注意力和空间注意力,更容易的与其他模块架构相结合[15]。多个实验表明,加载了CBAM 模块之后,分类和检测的性能有了显著的提高[16]。
2 模型介绍
2.1 YOLOv5网络概述
在2D 目标检测与分类中,YOLO(You Only Look Once)是一种具有出色准确性和监测速度的目标检测算法。YOLOv5 利用深度和宽度的倍数来缩放网络的深度和每层中卷积核的通道数量。YOLOv5 是一种常用的目标检测模型,其整体框架包括输入端、Backbone、Neck、Prediction 四部分。在输入端,采用Mosaic 数据增强和padding 技术,网络输入图片大小默认为640×640像 素。Backbone 部 分 包 含Focus 层 和CSP 结 构[17]。Neck 层主要将物体特征进行融合,输出端则对应的是损失函数与非极大值抑制。这些设计和结构的综合应用使得YOLOv5 在目标检测任务中表现较好。通过这样的设计,YOLOv5 可以有效地提高模型的鲁棒性和准确性,在各种场景下都能够良好地检测目标物体。因此,YOLOv5 被广泛应用于各种领域,如自动驾驶、智能安防等。
2.2 Ghost模块
使用嵌入式设备实现实时植物状态检测是一个严峻的挑战,本文在模型优化中,使用Ghost模块来替换卷积,从而减少模型参数。如图1 所示,首先通过卷积运算从n 个通道的输入图生成m 个通道的固有特征图,其次,通过cheap operation 生成s-1 个通道的ghost 特征图,最后将Y和Yghost拼接起来,此时输出特征图的尺寸变为n(n=m·s)。正如文献[18]所提出的观点一样,Ghost 模块够生成更多特征图,但它所需要的计算量却非常的少。Ghost 模块的前向传播过程可以分为三个部分。在第一部分中,他通过普通的卷积过滤器生成了一些内在特征图。然后,通过对每个内在特征进行一系列的廉价操作来生成幽灵特征图。最后,将第一部分中获得的固有特征图和第二部分中的幽灵特征图拼接起来,作为输出。
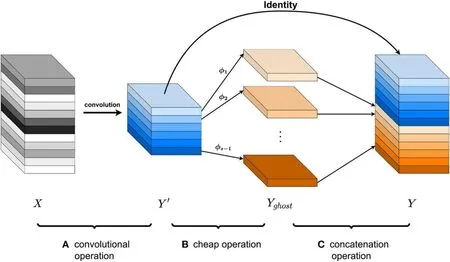
图1: Ghost 模块运行的三个部分
普通卷积层的操作可以表述为:



在公式(4)中,+代表的是拼接操作,具体ghost模块展示如图1 所示。
用Ghost 模块代替普通的卷积模块可以简化卷积操作,提升模型速度[18]。值得注意的是,Ghost 模块的计算参数比普通的卷积层更少。因此在本文中,Ghost Bottleneck 模块和G3Ghost_X 模块是基于Ghost 模块构建的。如图2 所示。在骨干网中,本文使用步长为2 的Ghost 模块,下采样并使用C3Ghost_X 模块提取图像特征,而不是普通的卷积和C3_X 模块。使用MNIST 数据集进行检测,GHOST 模块提高了训练的收敛速度和检测速度,而检测精度几乎没有任何损失。

图2: 添加Ghost 的模块示意图

2.3 卷积注意力模块(CBAM)
CBAM 是一种前馈CNN 注意力模块,它在2018年提出,被证明是一种简单而又非常有效的方法[19]。该模块包含两个子模块:通道注意力模块和空间注意力模块,这两个模块顺序执行。当输入特征图时,CBAM将在通道和空间维度上生成注意力图,这些注意力图将与输入特征图相乘,生成细化的特征图。更重要的是,CBAM 是一个轻量级的模型,可以实现端到端的训练,并且可以被训练成为一个可以嵌入到任何一个卷积神经网络当中,CBAM 的基础架构图如图3 所示。
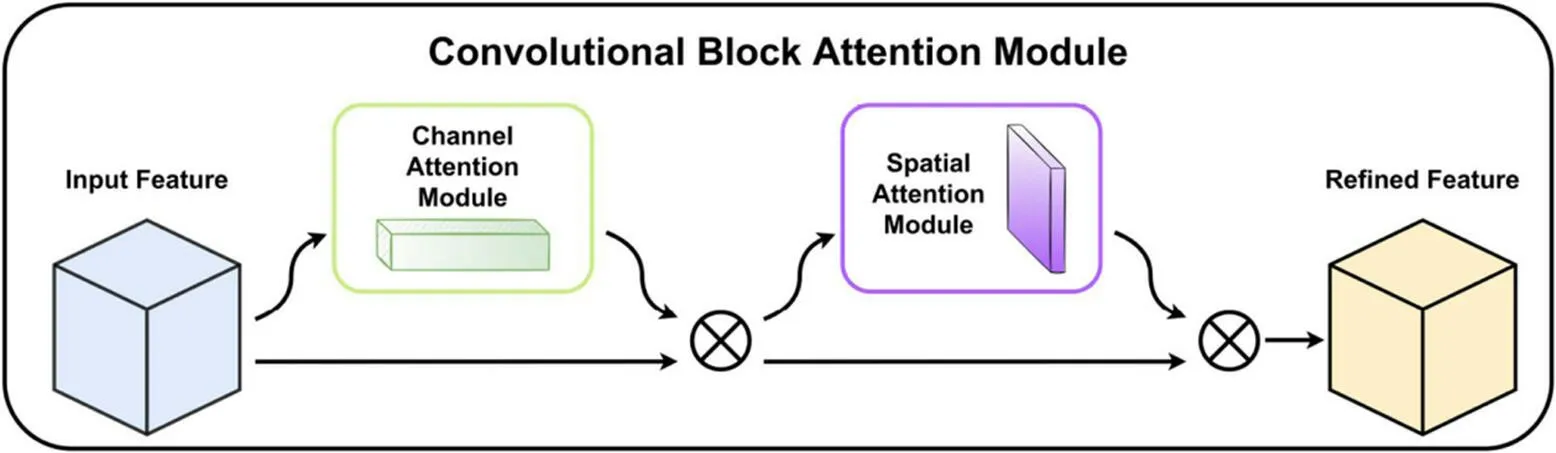
图3: CBAM 卷积注意力模块结构
为了将注意力机制引入到网络中,本文进行了大量的深入研究。MobileNetV2[20]中通过引入倒置残差和线性Neck 层提高了模型的性能。与经典的残差网络相比,MobileNetV2 中的倒置残差利用1×1 的卷积层扩展输入特征的通道,设定扩展率为6,然后中间扩展层使用3×3 深度卷积来获取非线性。最后,使用1×1 的线性卷积层来降维。而在MobileNetV3 中,在通道注意力提取后的扩展层附加了Squeeze-and-Excitation(SE)模块[21,22]。
受到MobileNetV2 和MobileNetV3 的启发,本文保留了倒置残差线性瓶颈模型的一般结构具体结构,然后引入了CBAM,增加了提取空间信息的能力,同时,MobileNet 中 使 用 的 第 一 个1×1 卷 集 中 的ReLU 或 者hswish[23]图如图4 所示。
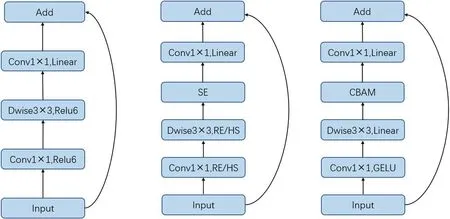
图4: 三种不同的Neck 块比较
如 图4 所 示,A 表 示MobileNetV2 块。B 表 示MobileNetV3 块,在不同的网络深度使用不同的激活函数。C 表示引入了CBAM 的块,使用GELU 和Linear。
3 实验
3.1 实验相关配置
试验在高性能的服务器上进行训练,使用了Nvidia RTX 4070 显卡。12GB 显存。操作系统为Ubuntu21.04(64位)。Python 版本为3.9,Pytorch 版本为1.13.1。部署的树莓派版本为4B.
为了优化网络参数,本文使用随机梯度下降(SGD)进行训练。初始学习率(lr0)设置为0.01。
3.2 Mosaic增强优化
一种常见的方法来增强神经网络模型的鲁棒性和泛化能力是使用Mosaic 数据增强。该方法将多个不同的图像随机拼接在一起,形成一个新的合成图像,然后通过对合成图像进行裁剪和缩放等操作,从而产生多个不同的训练样本[23,24]。具体来说,Mosaic 数据增强的步骤如下:
(1)从训练集中随机选取4 张不同的图像,并将它们随机拼接在一起形成一张新的合成图像。
(2)随机生成一个裁剪区域,并对裁剪区域进行裁剪,得到一张新的图像。
(3)对新的图像进行缩放操作,得到不同大小的训练样本。
(4)将缩放后的训练样本输入神经网络进行训练。
Mosaic 数据增强不仅仅只是一种常用的图像数据增强方法,它还具有许多其他优点。在深度学习中,训练集的多样性和数量对于提升模型的鲁棒性和泛化能力至关重要,而Mosaic 数据增强正是可以通过将多张不同的图像随机拼接在一起来实现这个目的。此外,Mosaic数据增强还可以帮助模型学习到更多的特征,从而提高模型的分类准确率和检测精度。通过对合成图像进行裁剪和缩放等操作,Mosaic 数据增强可以生成多个不同的训练样本,从而让模型在训练过程中接触到更多的变化,从而使其更好地适应各种实际场景。因此,Mosaic 数据增强在深度学习中被广泛应用,并且已经成为了提高模型性能的有效工具之一。然而,Mosaic 数据增强也存在一些缺点。首先,由于Mosaic 数据增强是通过随机拼接多张不同的图像来生成新的训练样本,因此会导致生成的合成图像存在一定的噪声和不连续性,可能会影响模型的训练效果。其次,Mosaic 数据增强需要较高的计算资源和时间,因为需要随机选取图像、拼接图像、裁剪图像和缩放图像等操作。最后,Mosaic 数据增强可能会导致过拟合问题,因为生成的训练样本与原始训练样本存在一定的重叠和相似性,可能会让模型过于依赖训练数据,而无法泛化到新的测试数据。
基于本文的模型需求和数据特点,修改原有的Mosaic 输入为3×3 共9 张图片,经过测试,模型的准确率得到了提升。如图5 所示。

图5: Mosaic 原理示意图
3.3 模型消融实验
表1 中对比了YOLOv5s, YOLOv5s-ghost, YOLOv5s-ghost-CBAM 的优劣性,证明了本文优化后的模型具备优势。

表1: 模型消融实验
3.4 树莓派4B部署
将本文的算法部署在端侧树莓派服务器上,可以成功运行,单张图片推理时间11.7FPS,满足实际场景需求。
4 结论
为了实现在树莓派上部署植物生长状态模型,本文提出了一种改良后的轻量级YOLOv5 模型。首先,我们根据实时视频流挑选符合实际情况的场景,通过视频流截帧,挑选训练素材。构建了一个符合业务场景的数据集,共计5323 张图片。其实,为了轻量化模型,引入了Ghost 模块。为了提取全局语义信息,引入了CBAM模块。为了增强数据集的表现能力,优化了Mosaic 方法。使本文优化后的YOLOv5 模型具有精度高,推理速度快的特点。并且部署在树莓派4B 上成功运行,证明了本文方法的可行性,具有更一定的推广性和应用前景。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2019年11期)2019-07-04 00:34:32
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子制作(2017年17期)2017-12-18 06:40:43
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国酿造(2016年12期)2016-03-01 03:08:19
电视技术(2014年19期)2014-03-11 15:38:20
