
由ChatGPT引发的思考:人工智能技术赋能电影领域
2023-05-15 01:06薄一航
现代电影技术 2023年4期
薄一航
北京电影学院美术学院,北京 100088
1 ChatGPT的出现: 人工智能的新高潮
纵观人工智能 (Artificial Intelligence,AI)技术的发展历程,大致经历了两次低谷和三次繁荣,如图1所示。20世纪50年代中期,计算机科学之父阿兰·图灵(Alan Mathison Turing)在英国哲学杂志《心智》上发表的文章《计算机器与智能》中首次提出“图灵测试”,用以测试机器的智能性。具体来讲,面对同样的问题,如果我们无法区分人和机器给出的答案,则认为该机器是智能的。“图灵测试”一直沿用至今,依旧是测试机器是否智能的主要办法之一,同时也是人工智能诞生的标志性事件之一。近日,由美国Open AI公司所研发的ChatGPT[1](Chat Generative Pre-trained Transformer)对话系统之所以使很多人为之惊叹也可归因于此。该对话系统通过学习和理解人类语言,结合上下文语境,可以像真正的人类一样与我们对话交流,以至于人们很难辨别出是机器在与我们交谈。

图1 人工智能的繁荣期与低谷期示意图
说到ChatGPT,不得不提到它的“孪生兄弟”InstructGPT[2]。Instruct GPT 模型采用人工反馈的方式结合强化学习对模型进行微调 (Fine-Tuning),进而生成更符合人类预期的回答。与Instruct GPT不同的是,Chat GPT 所采用的数据采集方式不同。在ChatGPT 模型中,采用有监督的微调来训练初始模型,人在其中同时扮演着用户与AI助手的双重角色,为训练器提供对话,并帮助机器撰写高质量的回复。Chat GPT 其实就是将这个新的对话集与InstructGPT 数据集相混合,并将其转换成对话的格式。具体来讲,Chat GPT 模型的训练过程主要包括三个步骤,如图2所示。首先,从问题数据集中随机抽取问题,并由标记者 (人)对问题进行标注给出高质量的回复,利用这些标注好的回复对GPT-3.5模型进行微调,进而形成有监督的微调模型(Supervised Fine-Tuning,SFT)。接下来训练奖励模型(Reward Model),即由标记者 (人)对模型给出的多个不同的回复进行打分排序,根据排序结果训练奖励模型。最后,从数据集中采样一个新的问题,在有监督的策略中对近端策略优化 (Proximal Policy Optimization,PPO)模型[3]进行初始化并生成一个输出结果,由奖励模型对所输出的结果进行奖励值计算,随后根据该奖励值与PPO 模型对策略进行更新。重复迭代第二步与第三步,直至输出更高质量的ChatGPT 模型。更进一步地讲,ChatGPT 之所以引起众人的关注和追捧,主要归因于其所引进的具有人类反馈功能的强化学习 (Reinforcement Learning with Human Feedback,RLHF)算法[4][5],较好地解决了如何让机器在与人的交互过程中可以生成越来越符合人类认知和需求的结果。

图2 Chat GPT 模型训练步骤示意图
从“图灵测试”到ChatGPT 对话系统的出现,如果说会计算、能计算是传统人工智能的核心,那么新一代人工智能的核心就是“会学习”,以认知为学习的条件,以知识为学习的客体,以交互为学习的形态,以理解为学习的核心,以记忆为学习的结果,让机器在学习的过程中不断解决新问题。可以说,机器学习(Machine Learning,ML)算法的进步直接关系到新一代人工智能的发展。李德毅院士将深度学习(Deep Learning,DL)[6]的机器学习算法作为传统人工智能与新一代人工智能的分界岭。
其实,从人工智能的三次崛起以及每次有突破性进展的重要事件,很容易看出人工智能的每一次崛起都依赖于算法的进步,更深一步地讲,是依赖于机器学习算法的进步。说到机器学习,是让机器具有像人一样的学习能力,例如,计算机视觉(Computer Vision,CV)[7]是为了让机器模拟人的视觉能力,能够“看”得懂。自然语言处理 (Natural Language Processing,NLP)[8]是为了让机器具有文字处理能力,会“阅读”,能“翻译”。同样的,计算机听觉是为了模拟人听的能力。语音识别 (Speech Recognition,SR)[9]模仿的是说的能力,机器人[10]可以模仿人的行为能力,人工情感[11]技术可以让机器拥有情感的能力,计算美学[12]则可以让机器具有审美能力等。而学习能力,是其他各种能力的基础和核心。换句话说,机器只有拥有了学习能力才可能学会和掌握其他技能。如果我们把计算机视觉比作人工智能的眼睛,计算机听觉比作人工智能的耳朵,机器学习则可以说是人工智能的大脑。
将人工智能第一次推向高潮的人工神经网络模型是深度学习模型的前身,是对人脑神经元网络的抽象模拟,网络中的每一个节点 (神经元)代表一种输出函数,连接节点之间的连线代表所连接节点的权重,如图3 (a)所示,对于实际输出的结果,与理想的输出结果相比较,所产生的误差反向传输反馈回模型并重新调整其中的各个权重值,直到实际输出结果与理想结果的误差在可接受的范围之内,运算结束。深度学习模型在人工神经网络模型中加入若干层中间隐藏单元层,如图3 (b)所示。简单地说,深度学习就是通过组合低层特征来形成更为抽象的高层特征,比如分类问题等。层数越多,学习过程也就越精细,结果自然也就越准确,当然,其所需的训练数据量也远远超过人工神经网络模型,即深度学习需要超大量的训练数据来对模型进行训练。

图3 人工神经网络模型与深度学习网络模型示意图
在众多深度学习模型当中,除了卷积神经网络(Convolutional Neural Network,CNN)[13]、深度置信网络(Deep Belief Network,DBN)[14]、生成式对抗网络(Generative Adversarial Network,GAN)[15]等几种常见的模型之外,当下最受人工智能领域欢迎的非转化(Transformer)模型[16]莫属,其延伸模型生成式预训练模型(Generative Pre-Training,GPT)[17]和BERT (Bidirectional Encoder Representations from Transformers)模型[18]也已经广泛地应用于多个不同的领域。比如,Transformer模型在机器翻译中的应用,极好地发挥了编码器与解码器模块的作用,使机器翻译的精度较以往有了跨越式的提升。另外,Transformer模型不仅对文字对象有成功的应用,在Text-to-image[19]、Text-to-video[20]以 及Textto-3D[21]模型等方面都有较为出色的表现。除此以外,近几年还出现了大模型、扩散模型 (Diffusion Models,DFs)等新的、先进的机器学习模型,其在图像生成领域也取得了前所未有的成果。其中扩散模型将生成过程按顺序进行分解,可以通过添加引导机制来控制图像的生成过程而无需再训练。比如,相比于早期的GAN 或者CAN (Creative Adversarial Network,CAN)模型[23]生成的图像,专门用于Text-to-image图像生成的Stable Diffusion模型[23]无论从细节性还是分辨率方面都表现出了其极大的优势。
其中,GPT 模型[17]在文字生成方面体现出了巨大的优势,该模型以现有的文学著作、教材,甚至网络上的贴吧论坛、开源代码等为训练数据进行模型的无监督训练。从GPT-1 到GPT-3.5,GPT模型采用Transformer模型中的解码器模块,参数规模大幅度提高,模块结构不断增加和调整,直到刚刚闯入我们生活的ChatGPT[1]模型,人们在许多情况下已经很难辨别出这是机器生成的文字,在理解性与认知性方面的确有了很大程度的提升。大家也因此开始期待新的模型,同时对人工智能也充满了憧憬。
当然,对于上述各种机器学习模型,既有其不可替代的优势,也有其客观存在的问题。比如,深度学习在拥有准确率高、易于更新的优点的同时,还有训练速度慢,所需求的训练数据量庞大,且预测内容与训练数据内容直接相关等缺点,鲁棒性较弱。目前的模型依旧处于“鱼和熊掌不可兼得”的状态,即在保证结果精度的同时,仍要牺牲巨大的训练时间和训练成本,这也的确是我们所面临的实际问题。再比如,备受关注的ChatGPT 模型也存在对于未经训练的内容会给出婉转的或者不正确的回答,对算力要求极高、复杂冗长或者特别专业的问题无法处理以及很难解决的“黑盒子”等问题。尽管如此,诸多机器学习算法给我们带来的惊喜和价值是不容小觑的,也正是这些机器学习算法突飞猛进的发展才使得人工智能又一次迈向了繁荣的高峰。
电影作为技术与艺术的特殊共同体,无论是对电影本体的研究,还是电影艺术创作与制作过程中的底层算法研究,人工智能技术在其中越来越彰显出其重要的作用和地位。尤其是近期随着ChatGPT 大模型的出现,更是让我们对人工智能技术将会给未来电影发展所带来的影响和作用产生了新的期待。
2 新时代的计量电影学: 人工智能技术助力电影本体研究
说到电影本体研究,计量电影学[24]可以说是较早将计算和量化思维应用到电影本体研究当中的一门学科。纵观计量电影学从萌芽到诞生,再到今天,先后经历了手工计算、半自动计算和自动智能计算三个阶段,这三个阶段的变迁与计算机技术的发展息息相关。
计量电影学雏形的出现可以追溯到电影的胶片时代,电影研究者以量化的方式对影片的某些特征展开研究,从而对影片做出一个更加客观和理性的评价与分析结果。电影学者查尔斯·奥布莱恩(Charles O'Brien)这样评价计量电影学:“计量电影学可以改变人们对于电影结构的理解,而这本身为人们重新认识一部电影或一系列电影提供了强有力的刺激。”早在1912 年间,瑞福恩·斯特克顿(Reverend Dr.Stockton)就通过手工测量的方式对剪辑率进行计算,并根据剪辑率计算结果去判断影片的节奏与风格,其目的是比较和评估“长的电影场景与短的电影场景的价值。”[25]“他携带了一只秒表、一只袖珍计数器、一只电子闪光灯以及一个笔记本”,在纽约的一家电影院花了310个小时之久反复观看影片,手工计算得出了试验数据。从实验心理学的角度讲,如果没有一只手表的话,人们是无法建立对时间长短的认知的。雨果·明斯特伯格作为一名实验心理学家在1915年也进行了电影镜头平均长度的试验。随后,一些电影人又陆续对影片的平均镜头长度、镜头数量、镜头时长等进行量化,以具体、客观的数据作为评价与研究的依据。1974年,英国学者巴瑞·索特公开发表文章《统计方法与导演风格研究》,计量电影学由此诞生。2005年,芝加哥大学的电影史学家尤里·齐维安 (Yuri Tsivian)与统计学家、计算机专家戈内斯·赛维扬(Gunars Civjans)联合创建了一个共享式在线影片测量与统计数据库CINEMETRICS[24],如图4 所示,与大家共享数据与分析结果。

图4 CINEMETRICS界面示例图
在计算机技术刚刚起步,甚至还没有出现计算机的情况下,对电影镜头的度量只能通过手工测量的方式,来计算和分析每个镜头的长度以及镜头的变化节奏。然而,这种手动的方式持续了若干年,直到数字电影代替了胶片电影,大家依旧喜欢和习惯用这种手动的方式去测量和计算镜头的长度与节奏。随着计算机视觉技术的进步,计算机科学家通过量化分析每一帧镜头画面中的颜色、纹理、光流等特征,设计出了自动检测电影镜头边界、镜头切换方式以及镜头时长等的检测和识别算法。随着这些算法准确率的不断提升,人们对镜头的分析也从手动转变为半自动,即手动+自动的方式,甚至完全交给计算机自动完成这些分析工作。这种分析效率的提高也是显而易见的。
当然,时至今日,对电影本体的研究也不再局限于计量电影学中对色彩、镜头等电影风格的研究,而是扩展到对镜头内容的理解与分析、对镜头画面的美学与情感分析等更高层次的研究。目前的计算机视觉算法也足以能够帮助和实现这些高级视觉的自动分析工作。
当前学校内部质量保证体系文本编制工作尚有迹可循,但后续“诊断与改进”抓手难觅, 如何“诊”?如何“改”?既不能隔靴搔痒,也不能徒增大量工作,增加师生工作学习的压力和负担。
考虑到电影本体巨大数据量的计算问题,我们会采用“分而治之”、从微观到宏观的分析方法。从某一帧镜头画面中的某个区域或事物,到整帧画面的分析,从一帧镜头画面到某一个镜头的分析,从一个镜头到一个场景的分析,从一个场景到一段故事情节的分析,以及从某段故事情节到整部影片的分析。分析过程也很好理解,抽象、提取出研究对象的各种特征,设计相应的算法并编程实现,这种量化的、计算性的分析思路在极大程度上可以提高对电影分析的效率,保证分析结果的客观性。
举个例子来看,在计算机视觉和深度学习算法的支持下,Flueckiger等人开发了一套用于半自动和自动分析电影美学和叙事的VIAN 视觉分析软件[26],如图5所示,形成了一套强有力的电影色彩理论和分析理念,将人的理解与数字方法结合起来,对电影色彩的风格、表达和叙事展开分析,探究电影色彩的美学与技术之间的关系,允许人们执行一般意义的注释任务和电影本体的数字分析,还可以灵活地应用于其它具有不同电影分析主题的研究项目上。从微观 (比如单个屏幕截图甚至画面中的某个前景或背景目标)到中观 (某个镜头或某个场景),再到宏观(整部影片及影片库)的层次性的分析方式,不仅对不同层级的色彩美学进行了深入地分析和可视化,还将三个层次的分析结合起来。该软件将人的注释与视觉表达相关联,并将分析结果映射到一系列可以即时访问和交互的视觉表现当中,极大地拓展了电影研究既定的、传统的方法,也使得电影的分析更加客观、细致和全面。

图5 VIAN 视觉分析系统示意图[26]
在电影风格研究中,除了色彩分析,景别也是体现影片风格的重要元素之一。针对于此,我们专门设计了电影镜头景别的识别方法[27],自动识别出每个镜头的景别类型,并对每种景别在影片中出现的频率、时长等进行自动统计分析。我们用多部影片进行了测试,图6为我们识别的结果示例,识别准确率达到85.24%。

图6 景别识别结果示例图
再比如,以往的镜头计算基本都采用人工手动标注的方式,面对海量的电影数据,计算效率是其最主要的问题。针对这一问题,计算机视觉领域提出了很多关于自动检测视频镜头边界的算法[28]。尽管此类算法在准确率上,尤其是针对诸如渐进、渐出、融合等镜头剪切方式的准确率低于人工的识别率,但人机合作的识别方式会大大提升镜头的计算效率。如图7所示,为仅通过颜色特征设计的镜头边界检测方法得到的结果。
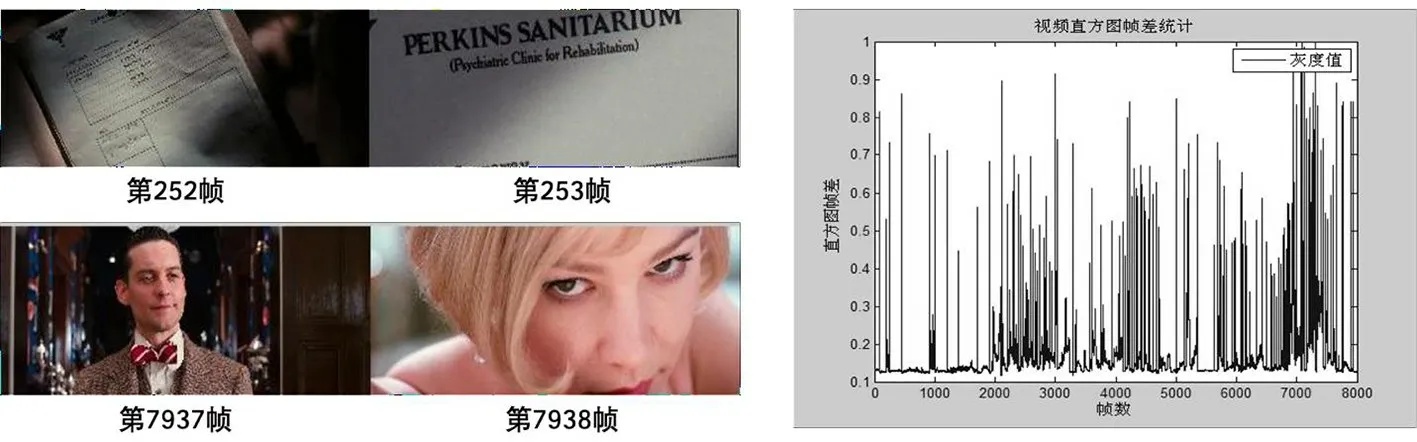
图7 电影《了不起的盖茨比》镜头检测示例图
如何将新的、更有效的人工智能算法应用到对电影视觉、听觉、叙事、美学以及情感的分析研究当中,也是当下以及未来电影研究需要思考的内容和方向。
3 算法意识的培养: 人工智能技术助力电影创作与制作
当下,国内电影的制作大多还依赖于各种较为成熟的工具软件的使用,比如常用的Maya、Nuke、3ds MAX 等。很少有制作团队或人员去深入挖掘软件背后的事情,即其各种算法和程序的支撑,这也导致了具体创作和制作过程中所面临的种种瓶颈和难以解决的问题。面对这些非开源的软件,我们无法针对在电影拍摄或制作过程中所遇到的具体问题进行二次开发,去解决所遇到的实际问题。而如果从算法设计而非软件应用的角度出发,具体问题具体分析,实际问题实际设计,想必在实际创作过程中所遇到的瓶颈和难题便会迎刃而解。当然,这也与国内影视制作团队的人员结构有一定的关系,我们需要的不仅仅是电影艺术的创作人员,还有进行底层算法设计和开发的计算机专业人员。试想,当电影制作人员懂得算法设计、程序设计,可以因地制宜地进行电影制作,那么我们将会拥有一套符合中国电影特点和需求的制作流程和方法,让我们的电影制作从模仿、应用朝着开发、设计的方向发展。此方向虽仍面临诸多困难,但可行且亟待解决。
再比如,影片《阿凡达》《阿丽塔:战斗天使》的拍摄和制作过程中,导演卡梅隆为了捕捉到更为逼真的表情,将动作捕捉技术移植到了表情的捕捉,设计开发了一套头戴式表情捕捉系统,针对具体情况改进了现有的表情捕捉算法,很好地解决了以往所遇到的演员表情高精度采集的问题,如图8所示。
目前,在计算机视觉领域有许多成熟先进的动作捕捉、抠像、表情捕捉、3D 建模、调色等各种影视制作过程中所需要的算法。我们需要一种新的影视创作与影视制作开发相结合的工作模式。
在电影创作过程中,尽管完全依赖人工智能实现创作过程是不可能,也不现实的,但人工智能技术可以通过自己的方法给创作者提供灵感和帮助。无论任何一种类型的艺术创作都源自于创作者丰富的情感表达,是创作者所积累的生活体验和人生感悟。因此,情感是贯穿艺术创作始终的灵魂所在。而这种从无到有的灵感呈现是目前人工智能技术所无法实现的。鉴于此,我们也曾提出过人机协同的创作模式[29][30],即以人为中心、人机合作的人工智能方法,该方法通过人机交互的方式将人的认知引入人工智能系统当中,让人的认知不断指导和调整深度学习模型的参数,进而让生成的结果越来越接近人们的期待。人机协同的创作模式不仅可以充分地利用机器强大的运算与存储能力,还可以很好地发挥人在艺术创作中的灵魂主导作用,是未来艺术创作方式的发展方向之一。
近年来,基于GAN、CAN、Stable Diffusion等深度学习模型的AI生成艺术形式的出现给电影创作带来了新的可能,比如AI剪辑已经很广泛地应用于许多视频编辑软件中,只要把视频或图像素材导入其中,即使你不懂剪辑,这些软件也可以自动帮助你将这些素材剪辑成一段完整的影像,实现了一键剪辑。甚至,还有许多影视公司用这种方法自动生成电影宣传片。通过这种智能方式剪辑生成的视频遵循各种剪辑规则,并不会存在不合常规的问题。这种自动的、智能的剪辑方式还可以帮助人们从海量的素材中挑选出优质的素材。当然,真正电影级的剪辑工作,仅有剪辑的规则是远远不够的。著名的电影剪辑师、北京电影学院导演系教授周新霞讲到,剪辑师或者导演从粗剪到细剪,这当中不仅会遵循应有的规则,就像作诗一样,很多即时的灵感和剪辑方法是在剪辑过程中自然产生的,这不仅与剪辑师所经历的生活阅历有关系,还与剪辑师当时的心情、情感状态直接相关,这是一种无法言表的东西。如果说要将人工智能剪辑用于电影剪辑的话,或许机器可以帮助我们做一些粗剪工作,素材过滤挑选工作,但无法做到像人一样的剪辑,所剪出来的片子感染力也可想而知。我们也可以做一个测试,同样的素材分别给人和机器进行剪辑,对比一下剪辑的结果会有怎样的不同。同样的道理,对于电影美术的创作、电影声音的创作、电影摄影的创作一样受用。
ChatGPT 强大的文本对话与生成能力引起了我们的创作兴趣。笔者与其研究团队尝试着将《梁祝》的故事作为输入,让ChatGPT 以该故事为背景生成一段剧本文字。经过多次与ChatGPT 沟通,告知其我们的需求,ChatGPT 最终生成一个三幕的《梁祝》剧本,图9为其生成的第一幕剧本文字。从剧本的格式规范上来说,不存在太大的问题,并且每次沟通之后所生成的结果也不尽相同,未来如果在训练模型中可以加入情感因子的影响和计算,由人来主导编剧的方向和主基调,ChatGPT 或许会是编剧的好助手,大大提升编剧的效率。

图9 Chat GPT 生成的《梁祝》剧本示例
再比如,当下比较流行的Text-to-image算法未来也会给电影分镜头画面的生成带来更多可能性。
如图10所示,为电影《老无所依》从故事板脚本文字到分镜头画面的生成。图10 (a)为分镜师J.Todd Anderson所创作绘制的[31],而图10 (b)为三种开源的文本到图像转换 (Text-to-image)方法 (分 别 为 VQGAN+CLIP[32]、Stable Diffusion[33]和ERNIE-ViLG[35]方法)自动生成。Stable Diffusion 模 型、VQGAN+CLIP 模 型 以 及ERNIE-ViLG 模型均为比较新的文本到图像转换的计算模型,且在电影制作领域有相当大的应用潜力。输入文本“side angle-inside the truck cab over one man-as he gets in driver is hit in head”,对于剧本内容的表达,图10 (b)中的三种方法所生成的分镜头画面的确可以较为准确地表达出其中的内容。然而,当机器生成的结果与人创作的结果放在一起时,很显然,图10 (a)中的分镜师所创作的分镜头画面更能吸引我们的眼球,尽管是黑白的,依旧能够给我们带来心灵上、情感上的震撼和波澜。很显然,对于艺术创作而言,技术只作为支撑,更多的是创作者情感的表达来赋予作品更丰富的感染力。尽管人工智能技术无法替代艺术家的创作过程,但机器通过其惊人的运算和存储能力所生成的结果无疑会给艺术家更多的灵感和启发。

图10 Text-to-image方法生成分镜头画面示例图
4 结语
在经历了长达近70年之久的起起落落之后,伴随着机器学习算法的迭代与革新,人工智能再次迎来了跨越式的发展,其应用领域也随之愈发广泛。今天,在Chat GPT 掀起了文本领域的新热潮之后,AI生成图像内容 (Artificial Intelligence Generated Content,AIGC)的技术[35]在图像与视频领域也引起了广泛的关注,Open AI同时也在研发ImageGPT 模型[36],对像素序列进行训练以生成高质量的图像内容,未来交互式强化学习的新一代GPT 模型是否也可以在与人的交流过程中不断学习到人对图像的需求来生成更符合人类认知的图像或视频,开辟图像或视频生成领域的新模式,成为我们下一个期待的目标。
回顾电影自诞生至今的发展历程,其每一次里程碑式的进步都离不开技术的支撑与推动。在今天,正值人工智能技术再次繁荣发展的新时代,人工智能技术势必会再次将电影艺术推向一个新的发展阶段,给电影研究、电影制作与创作带来更多的可能与生机。尤其是在追逐高效的电影虚拟摄制技术日益火热的背景之下,在线预览、智能灯光、实时动作捕捉等各种自动化、智能化技术的融入无疑是锦上添花,也是势在必行。近年来,风格迁移[37]、换脸减龄、智能语音合成,以及AI绘画、AI剪辑、AI作曲等新的人工智能技术也都给电影视效、声效的制作等方面注入了新鲜的血液。
另外,随着人工智能逐渐发展成一个较为完整的学科领域,不少大学成立了人工智能学院,很多研究所专门成立了人工智能、智能计算实验室等,这也正是当今的电影学院、电影研究领域所亟需的。❖
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
商界(2019年12期)2019-01-03
小学生学习指导(低年级)(2018年11期)2018-12-03
IT经理世界(2018年20期)2018-10-24
电影(2018年8期)2018-09-21
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
