
基于分层对齐迁移学习的锂离子电池容量估计
2023-05-15 12:13王福金马珮羽赵志斌陈雪峰
储能科学与技术 2023年4期
翟 智,王福金,邸 一,马珮羽,赵志斌,陈雪峰
(1西安交通大学机械工程学院,陕西 西安 710049;2装备运行安全保障与智能监控国家地方联合工程研究中心,陕西 西安 712046)
锂离子电池由于能量密度高、成本低、自放电率低等优点被广泛应用于各个领域[1-2]。在航空航天领域,锂离子电池已成为继镍镉电池和镍氢电池之后的第三代航空储能电池[3]。在汽车领域,各大厂商正在大力推出以锂离子电池作为储能设备的电动汽车。然而,与其他机械或电子设备一样,锂离子电池也会经历性能下降直至失效的过程。锂离子电池的劣化会导致设备故障,甚至严重安全事故。电动汽车中锂离子电池管理不当可能导致火灾甚至爆炸[4]。此外,电池故障也是航空航天领域任务失败的主要原因之一[5]。据2003—2021 年国内外公开的在轨航天器故障及其原因的统计分析表明,电源系统故障占航天器故障的比例高达44%[6]。
为了确保设备的安全可靠运行,制定预测性维护计划,对电池的健康状态(state of health, SOH)和荷电状态(state of charge, SOC)进行实时在线监测和评估具有重要意义[7]。对于锂离子电池而言,容量是反映电池退化状态的关键指标,其有效寿命、SOH 和SOC 的定义都与容量有关。电池有效寿命定义为电池容量降至初始容量80%的循环次数[8],SOH 是第n个周期的容量与初始容量的比值[9],而SOC则为当前可用剩余容量与当前周期最大容量之比[9]。因此,准确估计当前阶段的容量有助于电池的预测性维护。
近年来,很多学者对锂离子电池的容量估计(capacity estimation)和剩余使用寿命(remaining useful life, RUL)预测开展了相应的研究。从方法角度来区分,目前常见的电池容量估计和RUL 预测方法主要分为基于模型的方法和数据驱动的方法。基于模型的方法[10-13]往往需要相关的专业知识,对电池建模也需要电池相关的设计参数,这些条件限制了它们的广泛应用。数据驱动的方法仅依赖于过去的退化数据来建立电池的老化模型,受到不少学者的广泛研究。
戴海峰等[14]提出了一种基于充电曲线特征的锂离子电池容量估计方法,从充电曲线中提取特征作为相关向量机(relevance vector machine, RVM)模型的输入来估计电池容量。韩云飞等[15]从电压-放电容量曲线中提取特征,采用高斯过程回归对电池容量进行估计。周子游等[16]结合RVM 和长短期记忆网络(long short-term memory, LSTM)模型,以健康因子作为输入以估计电池容量。舒星等[17]提出了基于最小二乘支持向量机和Box-Cox 变换的RUL预测方法。然而,以上方法都需要人为从数据中提取特征,工作量大,且需要相关的背景知识。因此,有学者利用深度学习方法来估计电池容量和预测RUL[18-19]。深度学习方法具有能从海量数据中自动提取特征的能力,因而被广泛应用到各个领域。Li 等[20]设计了一种基于卷积神经网络(convolutional neural network, CNN)模型和LSTM的混合模型来捕捉电池退化中多变量之间的层次特征。Du等[21]提出了RUL和SOC估计的统一估算模型。Yang[22]设计了一个基于三维CNN 和二维CNN融合的混合模型,实现了3.6%的RUL 预测误差。Zhang 等[23]提出了一种用于RUL 预测的混合并行CNN 模型,该模型能够基于20%充电容量对应的稀疏数据预测电池RUL。
尽管数据驱动的方法在电池容量估计和RUL预测领域得到了广泛研究和应用,但这些方法都基于训练数据(源域)和测试数据(目标域)服从相同分布的假设[24]。然而,这种假设在现实中往往得不到满足,因为电池内部化学成分的差异以及不同的充放电策略不可避免地导致不同的数据分布。因此有学者采用迁移学习(transfer learning)或领域自适应(domain adaptation)来解决数据分布不一致情况下的容量估计问题。
从数据预处理角度出发,Li 等[25]提出了一种基于最大均值差异(maximum mean discrepancy,MMD)的数据预处理方法,以减少不同数据分布之间的差异,从而实现跨领域的知识迁移。此外,预训练和微调技术也被广泛用于电池容量估计任务[26-28],该类方法在源域上训练一个模型,并用有标签的目标域数据进行微调,最终用于目标域的预测。Kim等[29]使用变分推理来预测电池RUL,并使用不确定性估计来预测电池退化模式,其中也应用了预训练和微调技术。然而,这些方法都需要来自源域和目标域的标记数据,在许多实际应用中,很难从目标域获得标记数据。除此之外,Wang等[30-31]提出了一种退化趋势对齐方法,使得不同域内处于相同退化阶段的电池数据相互对齐,再根据退化对齐状态计算RUL,从而实现跨领域的知识迁移。陈峥等[32]提出了一种基于迁移模型的老化锂离子电池SOC估计方法。Han等[33]将基于MMD的域适配层集成到LSTM中,以实现源电池和目标电池退化特征的对齐。Ye等[34]提出一种整合相关性对齐(corelation alignment, CORAL)和MMD 的无监督特征对齐方法用于电池SOH估计。
然而,前面所述的基于迁移学习的方法都旨在对齐源域和目标域特征的整体分布,而没有考虑特征的可迁移性。Yosinski 等[35]对深度学习模型提取的特征进行研究,发现深层神经网络的不同层会学习到不同的特征,底层的网络学习学习到的大多是通用的特征,随着层数加深,特征从一般特征过渡到特定于任务的特征。Neyshabur 等[36]也得出相似的结论:神经网络的前几层提取的特征基本是通用特征,高层则提取对任务有强相关的特征。因此,不同层的特征具有不同的可迁移性。有不少学者在不同领域对此展开了研究:Bousmalis 等[37]提出将高层特征解耦成域公有特征和域私有特征,并对齐公有特征的分布实现从源域到目标域的迁移;文献[28]固定提取通用特征的底层网络的参数,并利用目标域数据微调顶层参数以使模型能更好地适应目标域;文献[38]则是微调底层的模型,而利用MMD 约束顶层模型。为解决不同层特征可迁移性不同的问题,本工作提出了基于分层对齐迁移学习(HATL)的锂离子电池容量估计方法。通过构建领域共享的特征提取器,提取来自源域和目标域的特征,考虑到不同层特征的可迁移性不同,在特征提取器不同层间施加MMD 约束和通道注意力一致性约束,形成可跨工况的容量估计模型。该方法以充电过程中采集到的电流、电压和时间数据作为输入集,无需手动提取特征,然后模型输出对应的容量估计值。通过对每个通道进行注意力建模,特征提取器用特定通道的特征来解释电池退化趋势,从而关注于可迁移的潜在属性。最后,在公开的数据集上进行实验,验证了该方法的有效性。
1 迁移容量估计问题描述
迁移容量估计问题旨在利用源域有标签的数据训练一个容量估计模型,使模型迁移到目标域时能保持一个较高的估计精度。有标签源域数据表示为表示第i个样本,即电池第i个循环周期的数据,表示第i个周期对应的容量值,Ns表示源域的样本数。同样地,无标签目标域数据表示为由于电池内部化学成分的差异以及充放电策略的不同,两者数据分布差异较大,具体体现在两者的电流和电压曲线存在很大不同,如图1 所示。从统计分析的角度看,假设分别用Ps(xs)和Pt(xt)表示源域和目标域的边缘概率分布,则Ps(xs) ≠Pt(xt)。为更加直观地表示数据分布差异,如图2 和图3 所示,将源域和目标域电池充电电流和电压曲线通过t-分布邻域嵌入[39](t-distribution stochastic neighbor embedding,t-SNE)算法进行二维分布的可视化,可以看出无论是电流还是电压均散乱地分布在二维空间中。

图1 不同充放电策略(域)下两个电池的电流和电压曲线Fig.1 Current and voltage curves of two batteries under different charging-discharging strategies (domains)

图2 源域和目标域电池充电电流曲线的t-SNE可视化Fig.2 T-SNE visualization of charging current curves in source and target domain
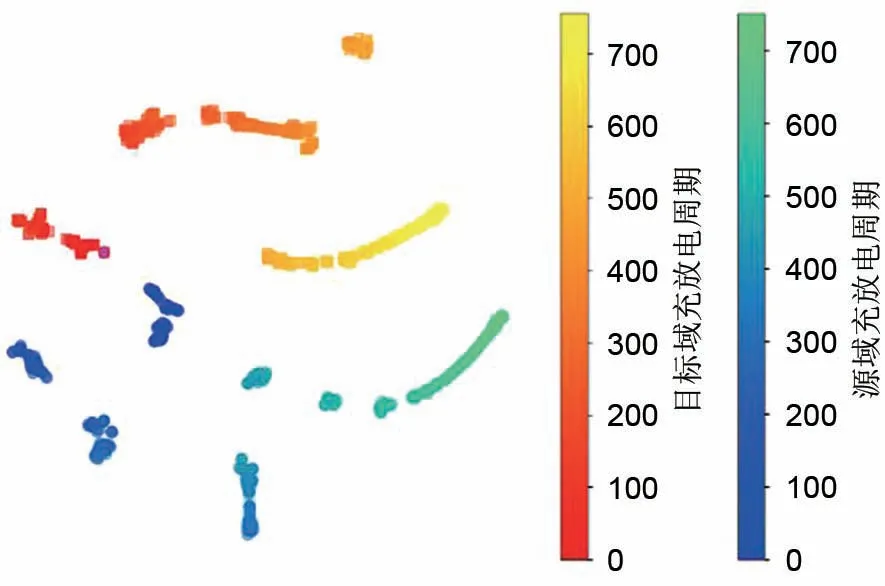
图3 源域和目标域电池充电电压曲线的t-SNE可视化Fig.3 T-SNE visualization of charging voltage curves in source and target domain
在本工作中,充电过程中记录的电流、电压和时间数据被用来预测当前周期的容量值,即和皆由充电时间、充电电流和充电电压组成,最终的容量估计模型可以用公式表示为:=f(xi),其中f(·)表示提出的容量估计模型。
2 分层对齐迁移学习模型架构
针对由一种充电策略至另一种充电策略的跨工况容量估计问题,提出了基于分层对齐迁移学习的锂离子电池容量估计方法。提出的HATL 的整体架构如图4所示。该架构主要由特征提取器和容量预测器组成,源域和目标域共用相同的特征提取器。需要注意的是,本工作提出的是一种通用的针对锂离子电池跨工况容量估计的架构,而并非某一种特定的网络模型。旨在强调关注源域和目标域中相同通道的高层特征,因为更高层的特征更具有表示性,这些通道的特征也更能反映电池的退化信息。
2.1 迁移退化特征提取
特征提取器(图4)主要用来提取能反映电池退化趋势的特征。在本工作中,特征提取器由四个一维的深度残差模块(residual network, ResNet)组成,每个残差模块由卷积层、池化层、批归一化层和激活函数构成。由于源域和目标域数据存在较大差异,若不做任何约束,则特征提取器从数据中提取的特征亦具有较大分布差异。此外,由于目标域数据无标签信息,无法直接用来训练特征提取器的参数。因此,本工作从减小特征边缘概率分布和关注源域与目标域之间的可迁移特征出发,缩小源域和目标域之间的差异。

图4 提出的HATL的整体架构Fig.4 The overall architecture of the proposed HATL consists of a feature extractor and a predictor
2.1.1 最大均值差异约束减小边缘概率分布
为逐渐减小源域和目标域数据分布的差异,用最大均值差异[40]对底层的网络进行约束(如图4中的LMMD,1和LMMD,2),使提取的通用特征聚拢到一个更加合理的特征空间。MMD 是一种可以衡量两个分布差异的非参数方法,能把两个分布映射到可再生核希尔伯特空间(reproducing kernel hilbert space,RKHS)并度量它们之间的一阶矩。分别用=代表源域数据和目标域数据经过第I(I=1,2,3,4)个残差模块后得到的表示,则和之间的MMD可定义为:
式中,sup{·}为上确界,H 表示RKHS,Φ(·)表示从原始空间到RKHS的非线性映射函数。本工作用高斯核函数K(xi,yj) = exp( - ‖xi-yj‖2/2γ2)替代非线性映射Φ(·),则和之间基于MMD的经验估计可表达为:
通过最小化LMMD,可适配源域和目标域特征的边缘概率分布。
2.1.2 通道注意力一致性约束关注可迁移特征
原始数据经过特征提取器之后被层层编码,得到的特征逐渐包含特定信息。当遍历特征提取器的深度时,所学习到的特征逐渐从一般特征过渡到特定于任务的特征。因此,更高层的特征更具有表示性,这些通道的特征也更能反映电池的退化信息。本质上,锂离子电池域跨工况容量估计的目标是识别可迁移到目标域的属性,即关注源域和目标域之间共有的能反映退化趋势的特定通道特征。
为了使特征提取器学习到一组能反映退化趋势的特征,受文献[41]启发,在特征提取器最后两个残差模块中引入通道注意力模块G(·)。通过对每个通道进行注意力建模,特征提取器用特定通道的特征来解释电池退化趋势,从而有利于发现可迁移的潜在属性。通道注意力模块G(·)的细节如图5所示。
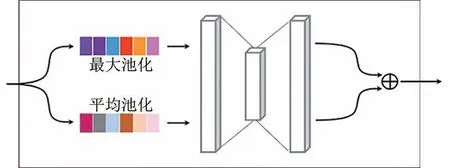
图5 通道注意力模块G示意图Fig.5 Schematic diagram of Channel attention module G
原始数据经过特征提取器之后得到特征矩阵h∈RC×L,其中C表示通道数,L表示长度。由于通道注意力模块G(·)同时作用于源域和目标域,为方便表述,这部分内容在表述特征矩阵h时均省略上下标。通道注意力模块G(·)以特征矩阵h作为输入,经过最大池化和平均池化分成两条支路,然后分别经过卷积核大小为1的一维卷积,最终相加两条支路的结果得到跨通道维度的注意力权重向量w=G(h),w∈RC(如图5所示)。
为了使模型关注到源域和目标域之间共有的能反映退化趋势的特定通道特征,构建通道注意力一致性损失LAC,其被表示为源域和目标域权重向量之间的ℓ1范数:
最小化式(5),可以使模型关注源域和目标域中相同通道的特征。由于源域标签的约束,模型被限制于用这些通道的特征来反映电池的退化趋势,因此,模型可将源域学习到的知识迁移到目标域,实现跨工况容量估计。
2.2 容量估计
原始数据经过特征提取器后得到能反映电池退化信息的特征,该特征作为容量预测器的输入估计电池容量(如图4中的容量预测器所示)。由于只有源域数据存在标签,因此源域数据被用来训练预测器P(·)。用表示源域数据经过特征提取器得到的最终特征表示,则P(·)的前向传播过程可被表示为:
2.3 模型训练与预测
为实现目标域数据的高精度容量估计,结合式(3)、式(5)和式(7)构建用于跨工况容量估计的目标损失函数:
式中,α和β分别为MMD约束和通道注意力一致性约束的惩罚因子。
所提的HATL 架构的训练和预测流程可归纳为如下步骤:
①获取不同充放电策略下的电流、电压和时间数据,构建有标签的源域数据集和无标签的目标域数据集,进一步将目标域数据集划分为训练数据和测试数据。
②构建特征提取器和预测器,组成HATL 架构,并建立相应的损失函数。
③利用有标签的源域数据和无标签的目标域数据训练HATL,最小化式(8)所示的损失函数。
④把无标签的目标域数据输入训练好的模型测试,模型输出跨域容量估计值。
3 实验验证
3.1 数据集介绍
利用文献[42]中公布的电池数据来验证提出的模型。电池型号为18650型磷酸铁锂电池,额定容量为1.1 Ah,标称电压3.3 V,充放电电压上下限分别为3.6 V 和2.0 V。实验温度为30 ℃,使用Arbin 测试系统进行实验。所有电池都经过四个阶段的快充,从0%充电到80%的荷电状态,然后以1 C恒流-恒压的方式充到100%。快充阶段的策略如下:前三个阶段分别以不同的恒定速率充入20%的电量,第四阶段的充电速率由保证四个阶段充电时间为10 min来确定。充满电后,所有电池以4 C的速率放电。更详细的实验细节可参考文献[42]。该文献一共公布了5批电池数据,本工作从最后一批的45个电池数据中选择出10个电池数据(包含两种充电策略)来验证提出的方法。
由于充电策略不同,10 个电池的数据被分为两个域,每个域包含5 个电池,具体细节如表1 所示。源域和目标域电池皆在30 ℃下开展实验,每一次充放电深度都为100%,即以表1 中所示的充电策略充满电,然后以4 C的速率放电至2.0 V。

表1 数据集介绍Table 1 Description of the dataset
3.2 数据集介绍
由于原始数据中每个周期采样的点数不一致,为了方便模型处理,将每个充电周期的时间、电流和电压数据重采样为128个点,并拼接成矩阵构成模型的输入样本xi,即xi∈R128×3。由于原始数据的时间跨度不一样,经过重采样后,其采样频率也不完全一样。因此,采样频率对于提出的HATL架构的性能没有影响。
从源域和目标域中各选择一个编号的电池数据,画出重采样后的充电电流和电压曲线如图1所示。可以看出,由于充电策略的不同,不同域中电池的电流和电压曲线存在较大差异。重采样后每个变量的维度仍然有128维,为了更加直观地看出其统计分布,利用t-SNE把电流数据和电压数据降维至2 维,分别画出其分布,如图2 和图3 所示。从图上可以明显看出由于充电策略差异,两个域的数据之间存在较大的域间隙。本工作利用充电阶段的数据来估计容量,而不是放电阶段的数据,因为充电数据更加可控,且不容易受到噪声干扰。
为了使模型训练更加稳定,减小数据尺度对模型性能的影响,使用归一化技术把原始数据转换到[0,1]区间。
3.3 实验细节
提出的HATL架构通过最小化公式(8)所示的损失函数来更新模型参数,其相应的超参数设置如下:使用的优化器为Adam,初始学习率为1×10-3,权重衰减系数为5×10-4,epoch为50,批量大小为64,权重平衡参数α为0.05,β为0.1。以上所有参数可通过网格搜索技术确定。文章的代码已开源,可通过以下链接获取:https://github.com/wangfujin/HATL.
一共开展了5组实验,每组实验在目标域数据中选一个电池作为测试,剩余四个电池参与模型训练,如图6所示。

图6 五组实验的数据划分方式Fig.6 Splitting method of the dataset in five experiments
为了量化方法的性能,使用均方误差(MSE)和平均绝对误差(MAE)作为评价指标,定义如下:
式中,yi为真实值,为预测值,N为测试电池的样本数。
3.4 相关方法描述
为了验证提出的方法的有效性,对比分析了其他的四种方法。
①普通ResNet:使用提出的由残差模块构成的特征提取器和预测器构成容量估计模型,但缺少域自适应过程,仅在源域数据上训练,然后在目标域数据上测试。该方法的模型架构与目前很多非迁移学习的容量估计方法类似。
②MMD:文献[33]提出了基于MMD 的方法用于锂离子电池的跨工况容量估计任务。为便于与提出的方法对比,利用提出的特征提取器和预测器构成MMD 方法的模型主干,与提出的HATL 不同,MMD 方法的四个残差模块之间都用MMD约束。
③CORAL:CORAL[43]是一种被广泛使用的域自适应方法,其利用线性变换对源域和目标域的二阶统计量进行对齐。本工作利用提出的特征提取器和预测器构成模型主干,利用CORAL 损失函数对模型进行约束。其他实验细节如3.3节所示。
④DANN:DANN架构最早在文献[44]中提出,目前已被广泛应用于各种场景下的域自适应任务。与CORAL 类似,本工作利用同样的主干实现DANN模型。
需要注意的是,对比的四种方法的主干网络与提出的HATL架构的主干网络是相同的,这样的设置可保证实验的公平性以及验证提出架构的有效性。
4 结果分析及讨论
4.1 跨域容量估计结果
目标域中不同电池的跨工况容量估计结果如图7 所示。可以看出,提出的HATL 的估计结果更接近于真实值,而普通ResNet 的估计结果则与真实值之间存在较大偏差。充放电策略的不同以及电池个体差异导致了不同电池数据分布之间存在域漂移,一般的数据驱动方法在跨工况容量估计中的精度会降低,而提出的方法有效减小了域差异带来的影响,实现了较高的估计精度。图7所示结果也表明了对于跨工况容量估计的任务,迁移学习是一种可行且有必要的方法。
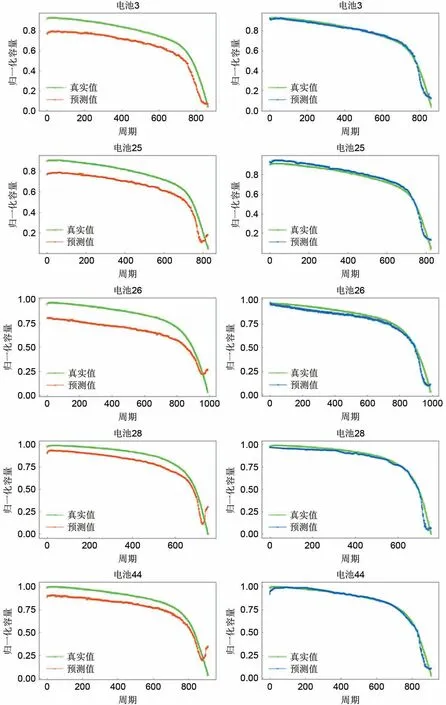
图7 不同电池的容量估计结果:左边为普通ResNet的估计结果,右边为提出的HATL的估计结果Fig.7 Capacity estimation results of different batteries.The left is the estimation result of ResNet, and the right is the estimation result of HATL
4.2 不同方法性能比较
为了进一步验证提出的方法的有效性和先进性,对比分析了其他四种方法,结果如表2 所示。为了保证实验的公平性,所有方法的输入都是3.2 节中构建的特征矩阵,输出为容量估计值,模型训练时的其他超参数保持一致。为避免偶然性,表2 中的所有值皆由5 次实验结果求平均得到。为直观对比不同方法的效果,用粗体标注出最好的结果。

表2 各方法在不同电池上的估计结果Table 2 Estimation results of each method on different batteries
可以看到,提出的HATL 在5 个实验中的估计误差都是最小的。值得注意的是,五种方法所用的网络结构和超参数设置都是一样的。普通ResNet没有迁移学习过程,因此其估计效果最差;MMD、CORAL 和DANN 等方法通过对齐中源域和目标域特征之间的整体分布,没有考虑到不同层特征的可迁移性不同,效果比普通ResNet 的效果好,但比提出的HATL 的效果差。提出的HATL 拉近低层特征在RKHS中的距离,同时关注高层特征中能反映电池退化趋势并能在两个域之间迁移的特征,因此取得了最好的估计结果。
4.3 可视化分析
原始数据xi∈R128×3,经过特征提取器之后得到一个128 维的向量,为了验证提出的HATL 方法是否真正减小了源域和目标域之间的差异,利用t-SNE 算法对特征降维并可视化,结果如图8 所示。对比图2 和图3 可以看到,两个域的原始数据分布比较散乱,不能看出明显的退化轨迹。经过特征提取器之后,两个域的数据分别形成两条曲线,且两条曲线的形状和延伸的方向比较相似,在一定程度上反映出了两个域的电池的退化轨迹。综上,特征提取器真正学习到了能反映电池退化趋势的信息,而且减小了不同域之间的差异。
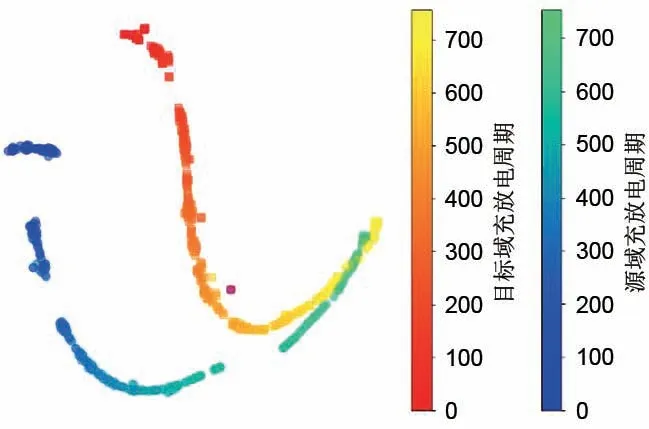
图8 对特征提取器得到的特征用t-SNE降维并可视化Fig.8 T-SNE visualization of features extracted from feature extractor
4.4 计算效率
为探究模型的计算效率,在Intel(R) Core(TM)i5-10400F CPU @ 2.90GHz 上部署提出的HATL,软件环境为Pytorch 1.7.1。分别对模型进行10 次独立训练,每次训练50 个epoch,平均训练时间为3.10 min。同理,对模型进行10 轮独立测试,每轮测试的样本数为4421,平均每轮测试用时2.03 s,平均每个样本测试用时4.59×10-4s。
5 结论
针对不同充电策略下电池数据分布不一致,一般基于数据驱动的容量估计方法无法直接用于跨工况容量估计的问题,提出了基于分层对齐迁移学习的锂离子电池容量估计方法(HATL)。通过约束底层特征之间的MMD 距离,并对高层特征的每个通道进行注意力建模,提出的HATL架构用特定通道的特征来解释电池退化趋势,从而发现可迁移的潜在属性。最终在公开的数据集上验证了方法的有效性。
在实验的过程中,每个充电周期的原始数据被重采样至128个点。因此,原始数据的采样频率对HATL 的性能产生的影响可以忽略不计。另外,本工作利用充电过程的数据来估计容量,相比于利用放电数据的方法来说,充电数据更加可控且容易收集,且不易受噪声干扰。然而,值得注意的是,提出的HATL 不局限于使用充电数据作为输入。如果放电阶段数据更加容易收集,也可以放电数据作为输入来估计电池容量。
尽管提出的方法取得了最好的估计结果,但仍然有改进的空间。在实际工业应用中,电池并不总是放完电才开始充电,因此充电曲线可能是不完整的。未来的工作将继续关注使用部分充电或放电数据来进行跨工况容量估计的研究。
猜你喜欢
计算机技术与发展(2020年11期)2020-12-04
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
电源技术(2016年9期)2016-02-27
电源技术(2015年5期)2015-08-22
电子与信息学报(2015年12期)2015-08-17
噪声与振动控制(2015年4期)2015-01-01
轴承(2010年2期)2010-07-28
