
基于自监督对比学习的病人相似性度量研究
2023-05-13 05:04:52李怡,杨丹
辽宁科技大学学报 2023年1期
李 怡,杨 丹
(辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051)
病人相似性[1]是利用病人的医疗实体作为特征进行学习,把具有相似特征的病人划分为一个病人相似组。正确识别具有相似临床特征的病人可以为诊断和用药提供临床参考。因此,有效利用医疗实体提高病人相似性度量的精准性,对提升医疗服务水平,推动个性化医疗建设具有重要意义。
图神经网络(Graph neural networks,GNN)[2]能够很好地处理像医疗这样复杂的数据,通过聚合邻居信息有效学习节点的向量表示。但图神经网络研究大部分是基于半监督学习,需要大量的节点标签,现实生活中获取节点标签费时费力,且大部分图神经网络通过构建邻接矩阵来表示学习并不能充分学习到结构和语义信息。而自监督对比[3]无需标签也可以学习有意义的节点向量表示,利用不同的对比视图提取节点正样本与负样本,最大程度上使正样本相近而负样本相远,这样不仅能够充分挖掘数据中结构和语义信息,也无需依赖标签。但将自监督对比学习应用于图神经网络以提高病人向量的精准性,还需要解决两个问题:(1)电子病历(Electronic medical record,EMR)[4]中含有多种类型的节点,节点间含有丰富的结构信息及语义信息,将这些节点嵌入低维向量空间具有一定挑战性。(2)仅通过图神经网络来聚合节点信息还远远不够,还要考虑节点间存在一致及差异的特点,学习节点间复杂的相关性。
针对上述问题,本文提出基于自监督对比学习的病人相似性框架SCO4PS。该框架首先从EMR 中构建医疗属性异构信息网络[5],保留数据间丰富的异构关系,从中选取药物视图和程序视图,通过图卷积神经网络学习两个病人特征表示。然后利用自监督对比机制进行视图内与视图间的对比学习,捕获视图中病人节点表示的相互关联、互补的关系信息,提高图编码后的效果。最后,将病人向量表示输入到相似性度量函数中进行病人相似性计算。
1 病人相似性度量
1.1 基于机器学习的病人相似性
传统的病人相似性方法一般是通过机器学习进行病人相似性研究。例如,Huang等[6]提出一种基于Jaccard系数和欧氏距离的病人相似性度量方法,以此建立预测模型,用于糖尿病的预测。Lee等[7]利用基于余弦的病人相似度度量来测量病人间的相似性,通过识别和分析过去相似的病人来构建动态个性化决策支持系统。王妮等[8]提出基于半监督学习的病人相似性度量,并与传统的欧氏距离和余弦距离结果进行比较,证明所提出的病人相似性度量方案的有效性。Chan等[9]使用支持向量机进行病人相似性加权,以此进行相似性分析。Sun 等[10]提出局部监督度量学习的病人相似性方法,通过调整距离找到相似病人。然而,机器学习应用于病人相似性研究具有一定的局限性,既未充分利用各种类型的医疗数据,也未有效学习医疗数据中丰富的结构及语义信息。
1.2 基于图神经网络的病人相似性
图神经网络通过神经网络学习图结构数据,对图中相邻节点信息进行传播和聚合,能够很好地处理像医疗这样节点类型多样且复杂的数据。因此,图神经网络被广泛应用于医疗领域并取得了不错的成果。例如,Huang等[11]提出一种利用患者疾病和药物数据的患者相似度计算方法,通过注释异构信息网络建立模型,并使用S-PathSim来衡量患者的相似性。Gu等[12]提出一种新的深度学习框架SSGNet,将电子病历构建成图来学习节点嵌入和节点间的相似性,并优化病人的图结构,增强模型容量进行病人相似性学习,减少病人间潜在关系的稀疏性给相似性带来的困难。Wei 等[13]提出一个端到端鉴别学习框架SparGE,通过联合稀疏编码和图嵌入来度量相似性。Sun 等[14]提出一种新的基于深度学习的动态患者相似性分析模型,用于计算病人相似性。
2 病人相似性框架SCO4PS
SCO4PS框架主要分为三部分:第一部分为病人的医疗属性异构信息网络构建,第二部分为病人的多视图对比学习模块,第三部分为病人相似性度量模块。框架结构如图1所示。
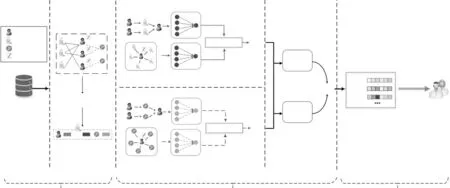
图1 基于自监督对比学习的病人相似性框架图Fig.1 Patient similarity framework based on self-supervised contrastive learning
2.1 病人的医疗异构信息网络构建
从EMR 中提取病人实体及病人相关的医疗实体(药物、程序),构建病人的医疗属性异构信息网络。该网络由病人P={p1,p2,…},药物D={d1,d2,…},程序T={t1,t2,…}三类节点组成,有病人-程序、病人-药物两条类型边,同时每个病人包含一段医疗文本作为病人属性,该文本描述病人的年龄、性别、手术情况、用药情况等基本信息。
2.2 病人的多视图对比学习
从病人的医疗属性异构信息网络中提取药物视图及程序视图进行多视图学习。多视图学习是基于病人不同的视图来捕获视图间相互关联、互补的关系信息以及自身的信息,使用自监督对比学习来平衡不同视角学习特征,从而得到更准确的病人节点表示。
2.2.1 元路径视图 药物视图和程序视图内部又划分为元路径视图和网络模式视图,如图1 中a和b 所示,元路径视图能够聚合高阶的结构信息,可以学习到二阶或者更高阶的信息。在病人的医疗属性异构信息网络中,两个节点可以通过不同的语义路径进行连接,称为元路径。
给定一条元路径Rn∈{R1,R2},其中R1和R2分别表示病人-药物-病人元路径和病人-程序-病人元路径,以病人目标节点i开始,得到基于元路径的邻居。而后,通过聚合邻居信息学习其不同语义及其相关性,使用特定元路径的图卷积神经网络(Graph convolutional networks,GCN)来编码聚合,计算式
式中:di,dj是节点i,j 的度;pi,pj是节点i,j的投影特征;pRni表示元路径Rn下病人pi的嵌入表示,
2.2.2 网络模式视图 网络模式视图通过节点间的直接聚合,学习病人的一阶邻居信息,考虑病人异构信息网络中的局部结构信息。病人目标节点i连接不同类型邻居Φs∈{Φ1,Φ2},其中Φ1={d1,d2,…,dm}表示药物类型节点,Φ2={t1,t2,…,tm}表示程序类型节点,目标节点通过Φs类型连接的邻居节点被定义为NiΦs。通过聚合这些一阶节点学习病人的局部结构特征,采用GCN聚合方法,计算式
式中:pj为节点j的投影特征;为聚合不同类型节点后病人pi的嵌入表示。
2.2.3 视图注意力聚合 分别得到药物视图下的病人嵌入表示和,以及程序视图下的病人嵌入表示和后,对元路径视图和网络模式视图进行视图注意力聚合学习两个视图的重要性,得到最终的嵌入表示zi
其中,βΦs和βRn分别表示Φs类型邻居和元路径Rn对目标节点i的重要性,以βΦs为例,其计算式
其中,V表示目标节点集,W∈Rd×d,b∈Rd×1是可学习参数,a是视图级注意向量。
2.2.4 视图间对比学习 通过编码聚合分别学习到药物视图和程序视图的最终病人嵌入表示zdrugi和zproi后,将它们输入到含有隐藏层的多层感知器中,以此将它们映射到对比损失空间中
式中:W2,W1,b2,b1为可学习参数,在两个视图中共享;σ表示RELU激活函数。
在计算对比损失函数时需要进行正负样本的选择,且异构信息网络中两个节点之间连接数越多,越能说明这两个节点高度相关。因此,如果两个病人节点间由多个医疗实体连接,那么把这类节点设为正样本,其他则为负样本。假设有目标病人节点i与病人节点j,定义一个函数Ci(j)统计两个病人节点连接医疗实体的总数,计算式为
设置一个正样本阈值Kpos,若Ci(j)>Kpos,则为正样本,记作K+ ,否则为负样本记作K- 。目标节点病人Pi与Pj共同使用的医疗实体(药物、程序)个数超过所设定的阈值Kpos,那么病人Pj就是病人Pi的正样本,如图2所示。

图2 正样本阈值设定Fig.2 Threshold setting of positive samples
选好正负样本后,进行药物视图和程序视图间的对比学习,计算药物视角下的对比损失
同理把程序视图作为目标嵌入,从药物视图中选取正负样本,得到在程序视角下的对比损失Lpro。
将药物视角下的对比损失和程序视角下的对比损失结合,得到视图间的对比损失Linter,这样既保留了药物视图与程序视图之间的相关性,也以此实现跨视图自监督对比学习。
式中:V表示节点集合;α是平衡两个视图的超参数,这里将α设置为0.5。
2.2.5 视图内对比学习 视图内对比学习仅考虑单个视图本身,从自身选取正负样本进行学习,以此保留自身结构及语义信息,具体计算式
其中,Kdrug+表示在药物视图内选取的正样本;Kdrug-表示在药物视图内选取的负样本;sim(·)计算视图内两个病人间的相似度。
程序视图的对比损失与药物视图对比损失计算方法相同,由此分别得到两个视图自身的对比损失和。为了最终全面学习视图内和视图间的病人表示,计算多视图编码模型优化整体损失L
其中,β是平衡不同损失函数的超参数,在实验过程中对β使用不同数值进行测试,通过实验证明参数β为0.5时模型效果最好。
2.3 病人相似性度量
将模型优化后得到的药物视图病人表示和程序视图病人表示相融合,得到病人的低维向量表示,以此进行病人相似性度量。
病人相似性度量通过病人间两相比较,病人的特征向量由药物、程序、医疗文本组合而成。给定一个目标病人,通过将病人的嵌入向量输入到相似性度量函数中,以此计算目标病人与其他病人的相似度。相似度越高,说明两位病人间具有相同标签的可能性越高;反之,说明病人之间具有不同标签的可能性越高。病人Pi和病人Pj的相似度记作
其中,ZP表示病人的嵌入向量。
3 实验结果及分析
为了评估SCO4PS 在病人疾病分类任务中的效 果,将SCO4PS 与Metapath2Vec、GCN、GAT(Graph attention networks)、HAN(Heterogeneous graph attention network)方法进行对比实验。
3.1 数据集
MIMIC-Ⅲ(Medical information mart for intensive care Ⅲ)[15]是一个免费向公众开放的重症监护医学信息的大型数据集。本文从数据集中提取出呼吸衰竭(Respiratory failure)、冠心病(Coronary disease)、心脏病(Heart failure)、败血症(Septicemia)、胃炎(Gastritis)这5类疾病后,从患有这些疾病的病人中提取出药物、程序以及病人的医疗文本数据。对这些数据进行缺失值处理,将预处理后的数据用于后续实验。
3.2 参数设置
对比模型Metapath2vec 的窗口大小设为5,行走长度为100,每个节点的行走长度为40,负样本数量为5。所有模型的学习率统一设为0.001,Drouput 为0.5,采用Adam 优化器,嵌入维度为128。SCO4PS的药物视图和程序视图都使用两层GCN。
3.3 疾病分类
将SCO4PS 与其他基线模型得到的病人节点向量作为病人分类器的输入,进行病人疾病分类任务。采用宏观F1(Macro-F1)、准确率(Accuracy)作为分类任务的评价指标,结果如表1 所示。SCO4PS 各指标都优于其他方法,其准确率为0.879,F1 值为0.850。HAN 模型各指标次之。因为SCO4PS考虑了节点间的异构性,能够更好地保留异构图中丰富的语义及其相关性,因此要优于同构图GCN 和GAT;同时,通过自监督对比学习的预训练提取了丰富的语义及结构信息,最终效果优于HAN。节点特征对下游任务起着至关重要的作用,因此通过图神经网络训练节点特征要优于随机游走的模型Metapath2vec。

表1 疾病分类Tab.1 Disease categories
3.4 病人聚类
聚类分析可以观察到不同疾病分布情况。将SCO4PS 与其他基线模型进行聚类对比,采用兰德指数(RI)、纯度(Purity)、标准化互信息(NMI)三个聚类指标对病人聚类任务进行评估,结果如图3所示。

图3 病人聚类分析结果Fig.3 Clustering analysis results of patients
SCO4PS 在各指标中都优于其他基线模型。SCO4PS 的NMI指标为0.716,比HAN 高出2.1%,比GAT 模型高出2.7%,比Metapath2vec 高出10.5%,比GCN高出11.8%。SCO4PS的RI指标和Purity指标分别为0.796 和0.879,其他基线的RI指标和Purity指标分别为0.689、0.717、0.743、0.759和0.823、0.827、0.853、0.855。这说明从多视图中能够更有效地学习异构图中病人的节点表示,并且通过自监督对比学习能够提取病人节点丰富的语义和结构信息,进一步提高病人的聚类效果。
4 结 论
本文提出一个通过自监督对比学习来捕获异构信息网络中病人的局部结构信息和丰富的异构语义及其相关性的病人相似性框架SCO4PS。首先构建药物视图和程序视图,对两个视图进行编码后,通过两个视图提取到的病人正负样本进行视图内对比学习及视图间对比学习,使视图能够学习自身信息的同时也能够互相交互监督,以此进一步学习到病人的节点嵌入表示,最后将学习到的病人表示输入到病人相似度量函数中计算病人相似性。与其他基线模型在MIMIC-III 数据集中进行对比实验,SCO4PS 指标均好于其他模型,表明本文提出的病人相似性框架的有效性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
小学教学研究(2022年5期)2022-04-28 21:29:36
河北画报(2020年8期)2020-10-27 02:54:20
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
电信科学(2016年11期)2016-11-23 05:07:56
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
通信电源技术(2016年6期)2016-04-20 06:21:36
