
基于预训练的Swin Transformer模型构建及其对糖尿病视网膜病变的诊断效能分析
2023-05-12 04:18WANGGang王洪敏王善志朱永俊柳明杰
中国临床新医学 2023年4期
WANG Gang, 王洪敏, 王善志, 朱永俊, 柳明杰
糖尿病患者常并发糖尿病视网膜病变(diabetic retinopathy,DR),严重者会导致视力丧失,其在视网膜区域可表现为血管扩张、渗漏、出血、组织水肿和微动脉瘤等[1]。DR的早期诊治对预防视力丧失具有重要意义,目前临床上常通过数码眼底彩色照相、光学相干断层扫描(optical coherence tomography,OCT)和眼底荧光血管造影(fundus fluorescein angiography,FFA)等进行DR诊断[2],诊断过程往往需要临床医师花费大量时间和精力重复地进行观察和辨别,且诊断结果容易受主观因素影响[3]。近年来DR患病率和致盲率持续增高也对传统DR诊察方法提出了新的挑战[4]。随着计算机技术的发展,不少研究者致力于建立高度准确的深度学习模型来检测DR的发展阶段[5]。目前,业界已有不少深度学习模型可以完成医疗相关图片的诊断和识别,但是仍较难兼顾高准确率和高效率。本研究使用Liu等[6]提出的Swin Transformer模型来对DR的严重程度进行评价,探讨该模型应用于视网膜眼底图片分类的可能性,并将其与其他已经应用于医学影像分类的模型进行对比,现报道如下。
1 资料与方法
1.1数据收集 本研究所用DR图像来自于数据建模及数据分析竞赛平台(https://www.kaggle.com/competitions/aptos2019-blindness-detection),下载APTOS 2019 Blindness Detection竞赛的训练数据集后得到PNG格式的眼底图片共3 662张,每张图片大小为217~7 495 KB,共8.01 GB。数据对应的病变等级和类别分布见表1。
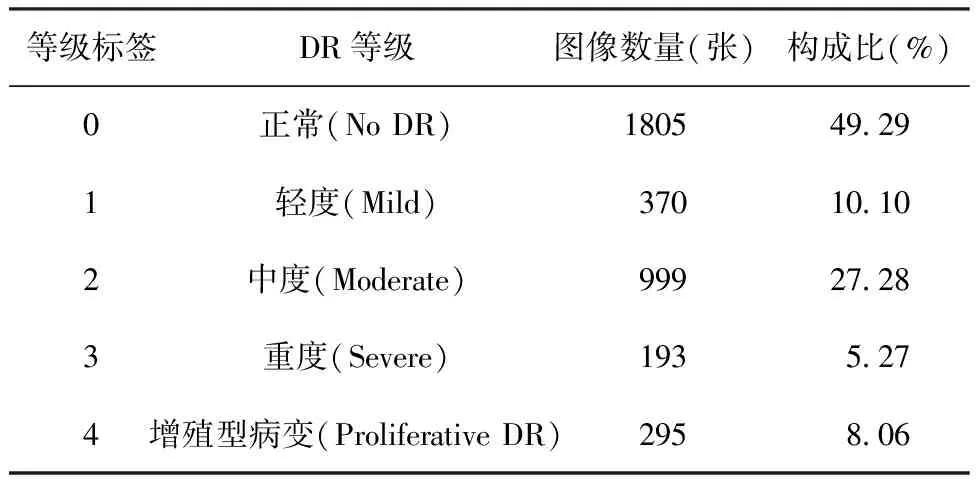
表1 原始数据集的类别分布
1.2Swin Transformer和对比模型的训练方法 应用Swin Transformer的Tiny架构和其他4种对比模型进行试验。模型训练的方法见图1。
1.2.1 数据预处理 原始数据集中的类别分布严重不平衡会导致过拟合的问题,所以对于等级标签为1~4的眼底图片,使用OpenCV的函数库,通过40°~280°的角度旋转、更改亮度和直方图均衡化三种方法的随机组合来进行数据增广[7]。数据增广后的数据集分布见表2。其中包含9 160张图片,类别分布平衡,将其按7∶2∶1的比例随机划分为训练集、验证集和测试集,图像数量分别为6 415张、1 831张和914张。训练集、验证集和测试集彼此不交叉。数据集中与DR等级相对应的样本图像见图2。
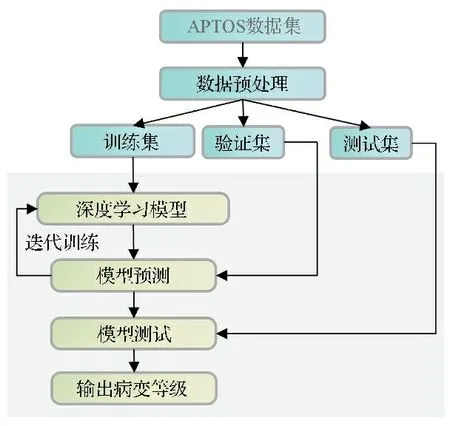
图1 训练方法示意图
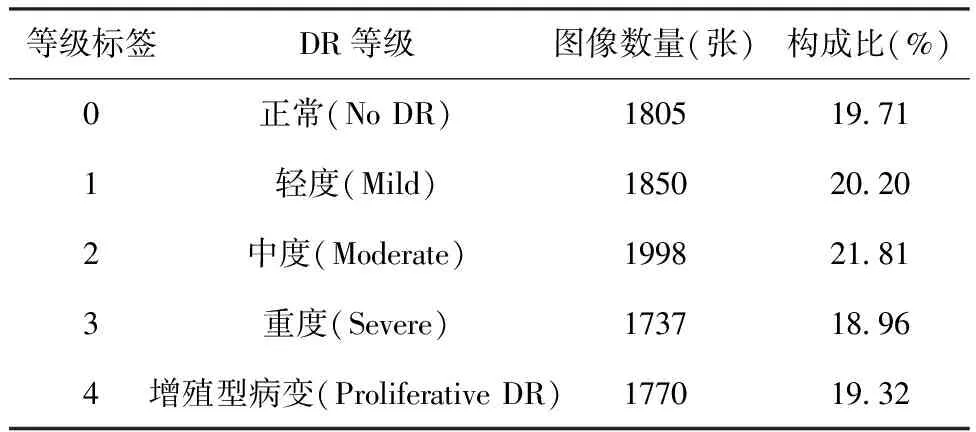
表2 数据增广后数据集的类别分布
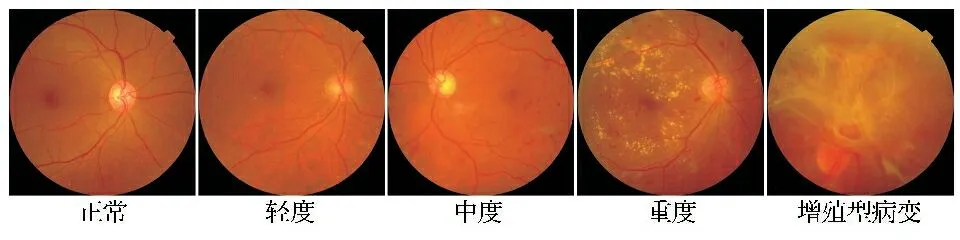
图2 数据集中与DR等级相对应的样本图像
1.2.2 Swin Transformer模型设计 本文将Swin Transformer的Tiny架构应用于DR病变等级分类。采用Liu等[6]的研究设计,将眼底图片分割为不重叠的图块,通过展平和线性嵌入将其转换为图块序列。然后将生成的图块序列输入到4个阶段组成的层次化结构中,每个层次都包含成对出现的Swin Transformer Block(每一对分别是窗口多头自注意力模块和对窗口进行移位的多头自注意力模块,前者输出给后者)。最后经过平均池化和线性分类层,输出病变等级结果。DR分类模型结构见图3。

H:输入图片的高度;W:输入图片的宽度;C:向量的维度
1.2.3 试验环境 硬件环境:Intel(R) Xeon(R) CPU E5-2680 v4处理器,28核;28 G内存;NVIDIA GeForce RTX 3090 24 G显卡。软件环境:Ubuntu 20.04.3 LTS(GNU/Linux 5.4.0-128-generic x86_64)操作系统;Python 3.8编程语言;OpenCV图像处理库;PyTorch 1.12.0深度学习框架;CUDA 11.3 GPU计算架构。
1.2.4 模型训练 为了比较不同的模型架构在相同数据集下的训练结果,本文将试验分为三个步骤进行:(1)使用预训练的Swin Transformer-Tiny模型对患者眼底图片进行DR分类训练。(2)与预训练的Vision Transformer[8]、EfficientNetV2-S[9]、ResNet-50[10]和GoogLeNet[11]四个经典模型进行对比试验。(3)与不进行预训练的Swin Transformer-Tiny模型进行对比试验,分析预训练数据集ImageNet-1K是否对眼底图片的训练有促进作用。所有模型均使用同样的超参数进行训练,具体参数见表3。训练完成后,将训练好的最优模型在测试集上测试,得到分类结果,并使用准确率、精确率、召回率(即临床研究中的灵敏度)、特异度、F1分数、二次加权Kappa、混淆矩阵[12]、ROC曲线[13-14]和AUC[15]来评估和展示模型性能,并依据美国食品药品监督管理局(Food and Drug Administration,FDA)评估人工智能算法的标准来评估模型是否理想,其标准的阈值为召回率>85%,特异度>82.5%[16]。上述(1)和(2)步骤中的所有模型初始化后都加载对应的预训练参数文件,这些文件中包含了各个模型在ImageNet-1K数据集上训练后学习到的权重值和偏置值。输入的图片统一被随机剪裁、随机翻转和归一化后进入模型进行试验对比,如果每个模型训练的损失和准确率开始收敛,则训练结束。步骤(1)和(2)的试验都在100轮训练内就完成了收敛。步骤(3)的试验在500轮训练内收敛。
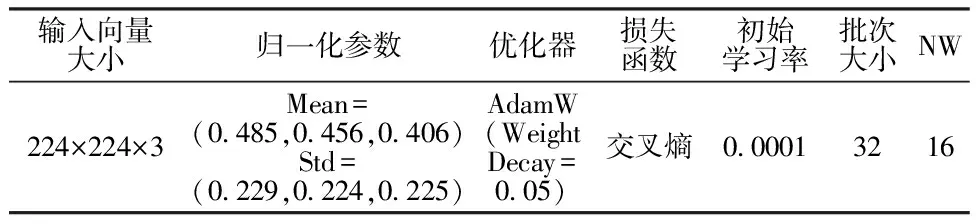
表3 模型超参数
2 结果
2.1基于预训练的Swin Transformer模型的试验结果 基于预训练的Swin Transformer模型的训练过程见图4。训练完成后在测试集上的准确率为94.6%。分类结果绘制的混淆矩阵见图5,ROC曲线见图6,使用宏平均ROC曲线的AUC作为模型的最终AUC,其值为0.996。从图4结果可知,模型在训练集的损失值为0.056。每个DR分类对应的评估指标(精确率、召回率、特异度和F1分数等)结果见表4。提示试验模型对DR等级分类的效果理想。由图5结果可知,该模型的二次加权Kappa值为0.977,提示模型分类的等级结果与真实值之间有很好的一致性。AUC值达到0.996,提示该模型具有很高的分类性能。综上结果表明,该模型能够对DR病变等级进行正确分类。
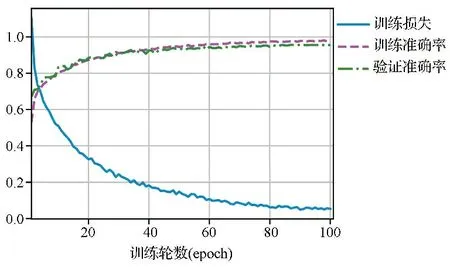
图4 Swin Transformer模型的训练过程图
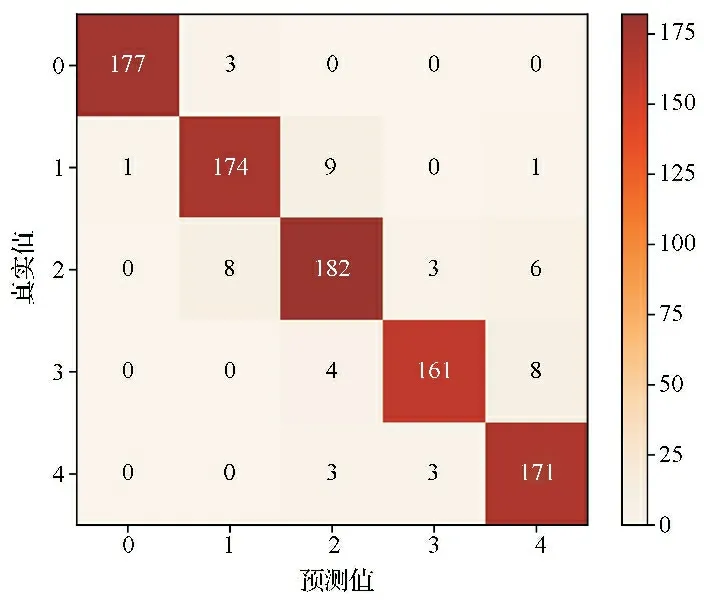
图5 Swin Transformer模型在测试集预测结果的混淆矩阵图

图6 Swin Transformer模型在测试集预测结果的ROC曲线图
2.2不同模型测试结果比较 不同模型在测试集预测结果的评估指标见表4,模型结构和运行的评估指标见表5。数据结果提示本研究使用的Swin Transformer模型优于其他模型,具有最高的精确率、召回率、特异度、F1分数、准确率和二次加权Kappa值。准确率相较于Vision Transformer、EfficientNetV2、ResNet-50和GoogLeNet模型分别提高了1.9%、2.3%、5.4%和7.1%。与同样是基于自注意力机制的Vision Transformer模型相比,其训练速度更快,运算量更少,可支持更大的单次训练样本量。

表5 不同模型结构和运行的评估结果
2.3预训练对Swin Transformer模型最高准确率和训练轮次的影响 不进行预训练,而是将随机初始化全部参数用来进行训练的Swin Transformer模型,其训练100轮并未见收敛,调整总训练为500轮的训练在450轮附近模型收敛。测试集的对比结果见表6,模型的训练过程对比见图7。由图7可知,在未做预训练的Swin Transformer模型训练100轮后未见收敛,测试集的准确率只达到68.1%,与预训练模型比较相差26.5%。总训练为500轮的训练结果准确率最高达到90.2%,但与预训练模型比较仍然相差4.4%,且训练轮次明显增加。提示预训练可以使模型快速收敛,节省大量的训练时间。

表6 Swin Transformer模型预训练与非预训练的对比结果
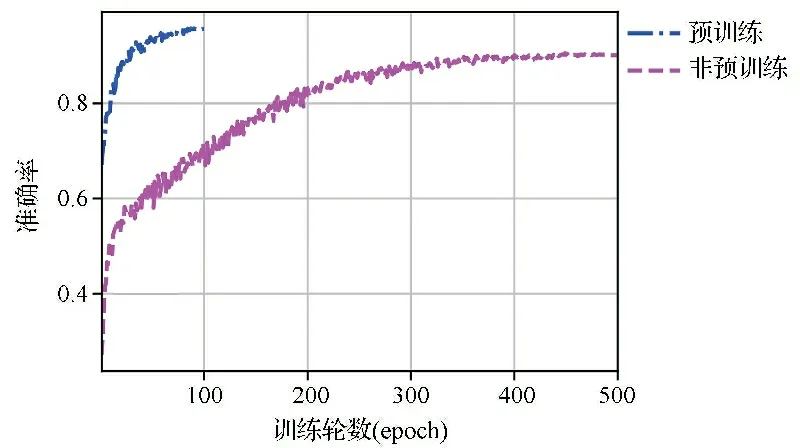
图7 “预训练”与“非预训练”的训练过程对比图
3 讨论
3.1数码眼底彩色照相、FFA和OCT等常用DR诊断方法都是辅以现代化存储介质,将患者眼底影像呈现给专业的医师,医师根据经验及诊断标准给出相应的诊断。而医师的工作是依据脑部存储的相关专业知识,对影像资料进行描述和判断。深度学习是通过计算机技术构建一个包含几亿甚至更多参数的神经网络。该网络通过不断的迭代训练,学习到大量的输入特征和判别结果之间的对应关系,并将之转换为数值保存下来。然后,使用这些学习到的“知识”对新输入的特征资料进行分析,预测出对应的结果。两者在逻辑及操作层面极具相似性,故以深度学习为代表的人工智能必将推动医学的发展。
3.2目前在医疗领域,深度学习在医学图像和信号处理、计算机辅助检测与诊断、临床决策支持、医疗信息挖掘和检索等方面取得了一些成果,展现出了极大的应用前景[17]。医学图像的处理任务主要包括图像分类、图像分割、目标识别等。在图像分类任务中,从卷积神经网络(convolutional neural networks,CNN)到Transformer[18]这一路发展的过程中,有很多深度学习模型出现。Gulshan等[19]提出了一种使用10个CNN(预训练的Inception-v3)诊断糖尿病性黄斑水肿(diabetic macular edema,DME)和DR的方法。该模型在Eyepacs-1和Messidor-2数据集中分别具有93.4%和93.9%的特异度以及97.5%和96.1%的敏感度。Bodapati等[20]开发了一种包含门控注意力机制的复合深度神经网络对DR进行诊断,该网络从多个预训练的深度卷积神经网络来抽取眼底视网膜彩色图像的特征,其准确率为82.54%,Kappa值为0.79。李琼等[21]在AlexNet网络的基础上,在网络的每一个卷积层和全连接层前引入一个批归一化层,得到网络层次更复杂的深度卷积神经网络BNnet。该模型将糖尿病视网膜图像按照病变程度分为5类,准确率达到93%。除了基于CNN的方法之外,学者们还提出了基于注意力机制的深度学习方法,在视觉任务上也取得了巨大成功。其中Dosovitskiy等[8]提出的Vision Transformer模型验证了不依赖CNN,将注意力机制应用于图像块序列可以更好地对图像进行分类。
3.3上述模型训练耗时长,且对计算机硬件有着很高的要求,精确率已经落后于新兴模型。本研究使用基于预训练的Swin Transformer DR诊断模型,其多层次结构、注意力机制和移动窗口机制的引入可以获取多尺寸的特征,对比其他分类模型,准确率有不同程度的提升。对比基于自注意力机制的Vision Transformer模型,该模型收敛速度更快,对硬件要求更低。在试验过程中,针对原始数据集分类不平衡的问题,通过角度旋转、更改亮度和直方图均衡化对数据集进行增广,避免了模型训练产生过拟合的问题。本研究构建的模型使用的预训练权重是在ImageNet-1K的数据集中训练得来,尽管ImageNet-1K数据集中并没有人类眼底图片的样本,但是预训练权重是通过海量数据训练得来的,机器模型可以很好地学习到数据中的普遍特征,获得更好的泛化效果。可见,即使是糖尿病患者眼底图片的DR分类,也可以通过迁移学习得到更高的准确率和更快的训练速度。本文使用的模型具有94.6%的准确率,可以为医疗机构建立自己的智能辅助医疗系统提供支撑,对于硬件性能不高,或者训练集需要频繁更新的医疗机构,该模型和试验方法也具有很好的指导作用。
综上所述,基于预训练的Swin Transformer深度学习模型在DR的诊断方面具有巨大的应用潜力,在医学影像诊断和疾病评估方面将会有新突破和快速进展。但本研究所构建的模型与临床要求还有一定的差距,因此在后续的工作中将进一步调整图像预处理算法来突出病变特征,尝试调整网络结构进一步提高检测识别率。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
中国交通信息化(2018年5期)2018-08-21
