
基于车载毫米波雷达动态手势识别网络
2023-05-10 06:40董连飞马志雄朱西产
北京理工大学学报 2023年5期
董连飞,马志雄,朱西产
(同济大学 汽车学院 智能汽车研究所, 上海 201804)
车载软件和车载智慧屏等智能座舱部件的快速发展和应用,一方面给驾车出行增加了更多智能化和趣味化体验,另一方面也增加了人机交互的频率容易造成驾驶员分心.手势识别作为一种有效的人机交互方式也是目前研究的热点.通过手势动作这种非接触式交互可以快速实现音乐切换、空调开关等简单功能,同时不会分散司机过多注意力,有助于提高出行安全降低事故概率[1].
随着深度学习的广泛应用,基于计算机视觉的手势识别研究取得巨大进展[2].循环神经网络[3]和长短期记忆网络[4]被应用于手势识别任务,这些网络架构可以对动态手势的时间和序列特征进行建模.DHINGRA 等在三维卷积神经网络(3DCNN)模型中应用了注意机制,学习了不同尺度的特征,获得了良好的分类结果[5]然而,这些方法对光照变化条件比较敏感,不能在低能见度条件下工作,无法满足车载应用的需求.王粉花等[6]提出基于YOLO 算法的手势识别方法提升了在肤色和光线明暗不一的背景下检测精度和速度.强彦等[7]提出了小波变换和双边滤波的图像去噪声方法,来应对光照变化、车载环境和摄像头成像质量的影响.针对复杂动态背景下手势分割提取效果差、图像识别率低等问题,强彦团队[8]研究了多特征融合的快速手势识别方法,进一步提升手势识别的准确率.
毫米波雷达可以通过发射电磁波并接收手势运动的回波来进行识别,因此可以不受光照影响,这是与图像手势识别相比的巨大优势.同时毫米波雷达不需要采集车内图像信息,可以保护车内人员的隐私.因此,基于毫米波雷达的动态手势分类越来越受到人们的关注[9].KIM 等[10]利用24GHz 雷达并训练卷积神经网络对三种手势的频谱特征进行识别实现预测分类.ZHANG 等[11]提出了一种毫米波雷达手势识别系统,采用3DCNN 结合LSTM 进行端到端训练,实现不同的动态手势识别.最近,Transformer 网络在自然语言处理、计算机视觉等任务都取得较大的成功.ANDREA 等[12]通过引入Transformer 自我注意力机制,对视频手势进行序列建模,并在手势识别数据集上取得较好的效果.
文中针对车内复杂的光照和动态干扰场景,提出用于毫米波雷达信息的手势识别方法,数据处理流程图如图1 所示.首先,设计典型的手势进行车内环境的数据采集获得雷达原始信号;然后,对雷达信号进行预处理和噪声滤波获得距离-多普勒特征图和距离-角度特征图,并制作特征分类数据集;接着,利用深度学习方法提取各种手势动作特征并提出基于Transformer 的动态手势分类网络.最后,在数据集训练获得最优的手势分类网络模型并进行结果分析.
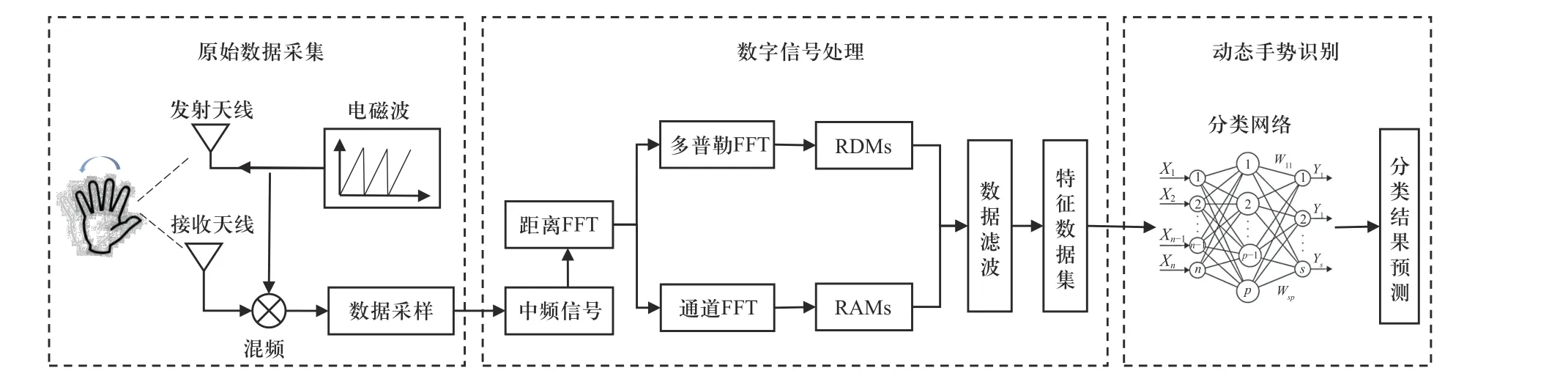
图1 动态手势识别算法数据处理流程图Fig.1 Data processing flow chart of dynamic gesture recognition algorithm
1 动态手势识别网络模型
文中提出的动态手势识别网络如图2 所示,主要由网络输入,特征提取,时间序列编码和分类预测4 部分组成.
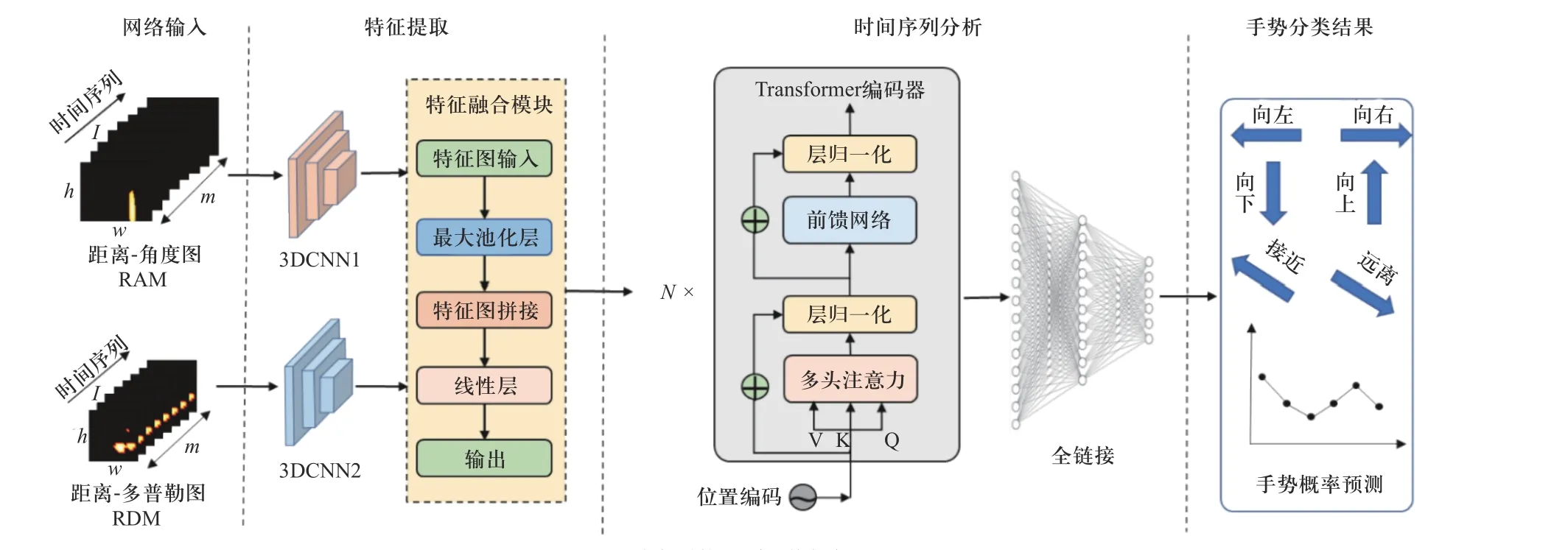
图2 动态手势识别网络框架图Fig.2 Framework diagram of dynamic gesture recognition network
1.1 数据输入
整个手势识别的框架可以定义为一个函数关系:
式中:Γ表示整个网络特征提取和编码过程.R2×m×w×h×c表示每次到网络的输入帧;2 为每次输入为RAM 和RDM 两种模态数据;m为特征图的数量(文中取m=8);w和h分别为特征图的宽度和高度,这里对于RAM图大小为96×96,RDM 特征图大小为24×24;c为通道数,一般图像具有3 个通道表示3 种不同颜色,这里数值含义为雷达回波强度值,所以只有单通道即c=1.对于Rn,n为手势的类别,这里n=6.由连续m张特征图组成了实际输入网络的1 帧记为I,整个输入可以组成数据集S.
1.2 特征提取
特征提取层主要经过两个3DCNN 主干网络进行空间特征提取,如图3 所示.卷积层可以表示为Conv3D(in, out,k,s),各个参数含义依次为输入通道数,输出通道数,卷积核大小和步长且每个卷积层后面一次包含批归一化层和ReLU 激活函数层;最大池化层可以表示为Maxpooling(p,q),p为为池化核大小,q为步长,其中池化层并不在时间维度进行.IRAM序列经过3DCNN1 得到(32,8,12,12)的特征图记为RAF,IRDM序列经过3DCNN2 得到(32,8,6,6)的特征图记为RDF.在特征融合模块,两个特征张量首先经过最大池化后得到均为(32,8)的二维张量RAF1和RDF1,将两个张量进行拼接得到F1,然后经过线性层得到(8,64)的二维张量作为Transformer 层的输入记为SF.整个过程记为

图3 3DCNN 层Fig.3 3DCNN layer
其中在Linear(·)为输入输出均为64 的线性层.
1.3 时间序列分析
此过程原始的Transformer 编码器用来进行时序特征提取如图4 所示.由于不同帧之间有着严格的顺序关系,在进行3D 卷积时并没有破坏前后的时序特征关系,因此需要对输入序列特征的位置进行编码.
在Transformer 编码前使用位置编码
式中:PE表示位置编码,通过不同频率的正余弦函数生成.O为所处的位置,i为相应的维度,dm为每一帧特征图经过3D 卷积后特征向量的长度,即64.后面处理过程沿用了经典的Transformer 编码过程[13],主要包含多头注意力层和前馈网络层,这里不再赘述.最终得到的编码向量经过一个两层全连接进行手势类别预测,并采用softmax 函数实现最终的概率预测.最终输出为N维的向量Y,其中概率最大值对应的手势类是网络的预测输出结果.
2 数据采集与预处理
2.1 数据采集
为了获取真实场景中的数据集,搭建了如图5所示的数据采集系统,对车内人员手势交互的实时数据进行采集.在数据采集过程中考虑汽车在加速、减速、怠速、匀速与转弯等各种场景产生的震动以及对人员的惯性影响;同时也考虑了各个时间段,车内光照强弱的变化.车内环境比实验室更为复杂,车内人员数量变化,同时也要避免车内人员换挡、转身等非指令动态被误识别.同时,车内外的其他环境噪声的动态变化也会对数据采集造成干扰.
数据采集的硬件平台为德州仪器IWR6843AOP.该雷达载频为60 Hz 带宽为3.2 GHz,同时具有较小的设计尺寸便于嵌入车内座舱.雷达的设计参数如表1 所示:
文中共设计6 种常见的动态手势,所有手势动作采集实验中满足以下要求:
①所有手势动作连续且需要被完整采集.
②手势动作速度适中:动作时间范围1.5 s~2 s;手势速度范围0.2 m/s~0.6 m/s;距离雷达径向距离0.2 m~1 m.
③手势在动作开始和结束有短暂停顿.
每个手势动作在不同场景下分别采集100 个有效的数据样本,最终得到600 个动态手势数据序列.
2.2 数据预处理
数据采集完成后需要对雷达原始数据进行处理获得雷达特征图数据集.雷达的发射信号和接收信号通过混频可以得到中频信号,IWR6843 可以直接输出雷达的中频信号.对中频信号进行快时间维进行傅里叶变换(FFT)得到一维距离特征,在此基础上对慢时间维进行FFT 变换可以得初始RDM;在距离特征基础上做通道FFT 变换可以得到初始RAM,如图6 所示.但是,此时的雷达数据中包含了大量无用的背景噪声,这并不利于模型的迁移应用,为此我们采用背景模型差法进行去背景操作.最后,为了便于进行神经网络的训练,将所有特征图进行标准化,使得数据分布均值为0 方差为1.图6 中展示了向左摆动和靠近雷达两种不同手势的雷达特征图举例,从图中可以看出不同运动模式对应雷达的特征具有显著差异,可以有效地进行手势特征的识别.

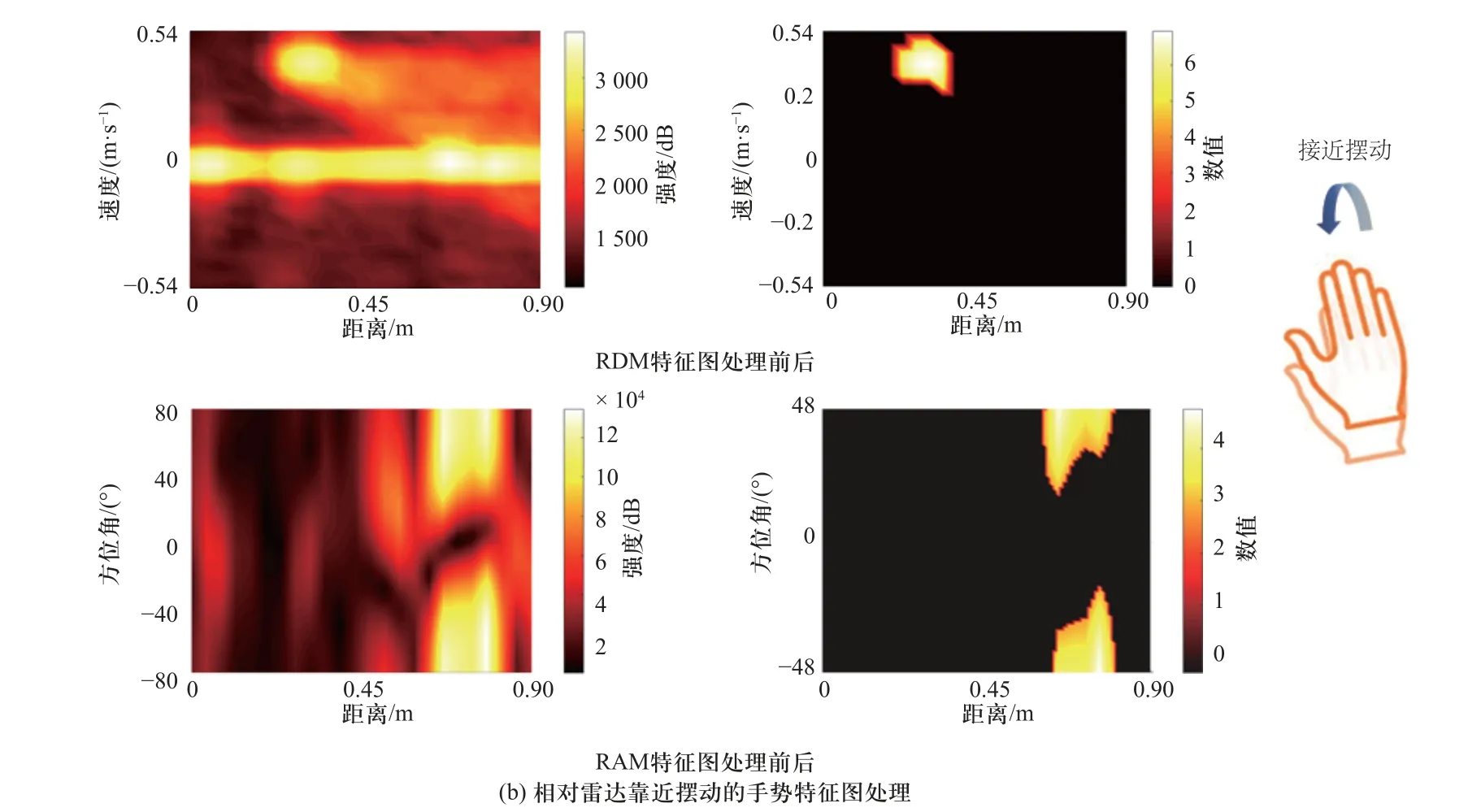
图6 两种手势的RDM 和RAM 特征图处理前后Fig.6 RDM and RAM feature maps of two gestures before and after processing
3 实验与结果分析
3.1 训练过程
采集数据样本按照上一节方法进行预处理,每个连续的手势序列提取连续8 帧的RAM 和RDM 序列,所以最终得到样本集数量为4 800 帧。将数据按照7∶3 比例随机分成训练集和测试集.采用多分类任务中的交叉熵损失作为损失函数.
网络算法框架基于PyTorch1.9,并采用SGD 优化器进行端到端网络训练,批大小设置为8,初始学习率为0.001,权重衰减为0.000 1,共计训练100 个周期.网络采用硬件服务器主要参数GPU:NVIDIA GTX1080Ti-11G*4,CPU:Interl(R)Xeon(R) E5-2630 v4@2.20 GHz,内存:128 G,系统:Ubuntu18.04.
3.2 对比实验结果分析
本实验为多分类任务,将所有类别的平均分类准确率作为评价指标.为了验证算法的有效性,与其他几种手势识别网络进行对照,如表2 所示.
从表2 中可以看出,文中提出的算法达到了最高的平均分类精度97.14%,远好于传统的HMM 算法.仅采用3DCNN 网络的分类准确率只有93.34%,当加入LSTM 和Transformer 模块手势分类精度明显提高.在3DCNN 中添加Transformer 模块要比LSTM模块分类准确率也增加1.1%,证明了Transformer 模块的时序和空间编码方式在本次分类任务中要优于LSTM 网络.为了对比各种手势识别的准确率,绘制每种类别的分类准确率的混淆矩阵如图7 所示.

图7 动态手势分类结果混淆矩阵Fig.7 Confusion matrix of dynamic gesture classification results

表2 对比实验结果Tab.2 Comparison results between proposed and other method
从混淆矩阵可以看出,向左和向右存在较多误识别,分类准确率只有0.96 和0.95;而向上、向下、靠近和远离的手势分类准确率都高于0.97.从整体来看,整个网络的分类准确率没有太大偏差,具体较稳定的动态手势的识别能力.
4 结束语
设计了基于毫米波雷达数据的动态手势识别的数据处理流程,通过数据采集、预处理、网络训练和测试验证来证明了该方案的有效性.提出了针对毫米波雷达特征图的3DCNN+Transformer 的动态手势分类网络,在实际采集的数据集上具有97.14%的分类准确率,满足了动态手势分类任务的需求.与图像手势识别方法相比,文中设计的车载毫米波雷达的手势识别系统具有全天候识别和乘客隐私保护的优点,可以为今后智能座舱的人机交互设计提供参考.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
红领巾·萌芽(2019年9期)2019-10-09
电子制作(2019年11期)2019-07-04
小学科学(学生版)(2018年12期)2018-12-19
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
小学阅读指南·低年级版(2017年6期)2017-06-12
