
基于轻量化YoloV5的谷穗实时检测方法
2023-05-08 06:10:40邱述金赵华民李晓斌张庆辉原向阳
江苏农业科学 2023年6期
李 云, 邱述金, 赵华民, 李晓斌, 张庆辉, 原向阳
(1.山西农业大学农业工程学院,山西太谷 030801; 2.山西农业大学农学院,山西太谷 030801)
谷子是我国的重要杂粮作物之一,其种植面积约为世界总种植面积的80%,其产量约占世界总产量的90%[1]。一直以来,在谷子栽培及育种研究中,谷穗数量都是要依靠人工观察谷穗并统计,不仅效率低且耗时耗力。在实际的田间环境中,谷穗的相似性、密集分布、遮挡及统计人员的主观性使谷穗计数困难,非常容易出错。谷穗是评估谷子产量与质量的关键农艺指标,在营养诊断、生长期检测及病虫害检测等方面具有重要作用。因此,在移动设备上快速准确地检测谷穗能为产量预估及其表型研究提供重要的作用。
随着农业信息技术的快速发展,基于深度学习的农作物图像检测受到广泛关注[2-3]。目前针对谷物穗头检测的研究,以小麦[4-6]、水稻[7-10]等主要粮食作物为主,研究的问题主要针对提高模型检测精度和检测速度。鲍烈等提出,基于卷积神经网络(CNN)的小麦麦穗识别模型,为提高识别精度结合图像金字塔构建滑动窗口实现对麦穗的多尺度识别,该模型准确率为97.30%,利用该模型完成小麦麦穗的计数和预估小麦产量[11]。张领先等实现了一种冬小麦麦穗卷积神经网络识别模型,并与非极大抑制值结合,实现在实际大田环境中快速、准确地检测麦穗与计数[12]。王宇歌等通过改进YOLOV3模型对不同时期麦穗目标进行检测与计数,改进的YOLOV3模型的检测结果表现出较强的鲁棒性,但对遮挡的麦穗及尺寸较小的麦穗检测仍有困难[13]。鲍文霞等的研究基于深度卷积神经网络CSRNet网络,对单幅麦穗密度图进行了研究,根据密度值对麦穗进行计数[14]。Fernandez-Gallego等运用热成像技术和深度学习对麦穗图像进行分割并对麦穗进行计数[15]。刘哲等采用改进的Bayes抠图算法将麦穗从复杂背景中分割出来,运用平滑滤波、腐蚀、填充等算法分割出麦穗小穗并形成连通区域后进行标记、计数,该方法提高了技术精度[16]。谢元澄等研究提出了基于深度学习的麦穗检测模型(FCS R-CNN),通过Cascade R CNN引入特征金字塔网络(FPN)等方法,提高检测精度和检测速度[17]。
在实际的田间环境中,穗头分布密集、遮挡严重,模型在复杂环境中对穗头检测较为困难。为提高模型对困难目标的检测准确率,姜海燕等设计了基于生成特征金字塔的稻穗检测(GFP-PD)方法,针对小尺寸稻穗和叶片遮挡稻穗的噪音等问题,采用构造特征金字塔和遮挡样品修复模块(OSIM)提高模型的检测正确率[18]。张远琴等针对小尺寸稻穗目标问题,基于Faster R-CNN模型引入空洞卷积,用ROIAign替代ROIPooling等方法进行优化提高模型对水稻稻穗的平均检测精度[19]。段凌凤等运用3个全卷积神经网络进行比较,对稻穗进行分割后根据对稻穗图像的计算速度、分割性能,优选出性价比最好的SegNet卷积神经网络,提升边缘不规则、遮挡条件下稻穗的检测准确率及效率[20]。Bao等设计了一种轻量级卷积神经网络SimpleNet,使用卷积和反向残差块构建,并结合卷积注意力机制CBAM模块,可用于移动端对小麦穗病害的自动识别[21]。Zhao等提出了一种改进的基于YOLOv5方法来检测无人机图像中的麦穗,通过添加微尺度检测层和采用WBF算法解决因小尺寸麦穗密集分布和遮挡导致的检测问题[22]。杨其晟等提出一种改进YOLOv5的苹果花朵生长状态检测方法,引入协调注意力(coordinate attention,CA)模块和设计多尺度检测结构,提高模型检测精度[23]。张兆国等通过改进的Yolov4模型设计了一种马铃薯检测模型,使用MobilenetV3网络替换YoloV4模型的CSP-DarkNet53网络减小模型体积并保证了马铃薯的平均检测精度,在嵌入式设备上部署试验,YoloV4-MobilenetV3表现出较强的鲁棒性[24]。
由于谷子在自然大田环境中的生长特点,谷穗形态及空间分布位置不规则,因此在实际环境中应用目标检测模型对谷穗的检测较为困难。本研究以YoloV5模型为原始模型,将其主干特征提取网络使用轻量化MoblienetV3模型代替,以减少模型参数,在此基础上改进特征融合检测结构,后处理引用Merge-NMS算法改进轻量化模型。通过在自建的谷穗数据集上进行测试评估模型,为移动设备上实现快速准确地检测谷穗提供理论依据。
1 制作数据集
1.1 图像采集
谷穗图像采集于山西农业大学申奉村试验田,时间为2021年7月至10月,采集的图像包含抽穗期、灌浆期、成熟期3个时期的谷穗图像(图1),其中抽穗期25幅,灌浆期230幅,成熟期45幅,共300幅。谷子在生长过程中穗头一般以下垂状态为主,故本研究在采集图像时均从侧上方拍摄图像,采集的谷穗图像分辨率为4 032像素×3 024像素,存储为jpg格式。由于实验室中计算资源有限,将原始图像压缩为1 024像素×768像素,加快数据处理时间。在自然田间环境中采集的谷子图像存在被叶片和茎秆遮挡的谷穗、谷穗相互缠绕遮挡、谷穗密集分布等众多复杂情况,对模型检测谷穗有一定的干扰。
1.2 图像预处理
对采集的谷子图像使用LabelImg标注工具按照PASCAL VOC数据集格式制作谷穗图像数据集,对图像中的谷穗进行标注(图2),生成对应的XML文件。为防止数据集较小可能会导致网络模型的过拟合现象,提升网络模型训练结果的泛化能力,因此需要对谷穗数据集使用数据增强(图3)。本研究对自制的谷穗数据集用旋转、翻转、镜像、亮度调整等方法随机进行数据增强,每幅图像对应的标注文件同时进行变换,数据集扩充至2 100幅,按照 8∶1∶1 比例随机将数据集划分为训练集、验证集和测试集。
2 YoloV5模型与改进
2.1 YoloV5模型
YOLO(you only look once)[25]系列是采用回归方法的单阶目标检测模型,具有较好的性能,YoloV5是YOLO系列中目前比较优秀的模型,根据模型体积和参数量分为4个版本:YoloV5s、YoloV5m、YoloV5l和YoloV5x。由于本研究对检测模型的准确率、实时性和模型体积的要求较高,因此本研究基于YoloV5s模型改进设计实现谷穗目标的检测。

YoloV5模型的结构见图4,YoloV5s模型主要包括4个部分:输入端、Backbone、Neck和Prediction,其中Backbone结构作为中不同次数的特征提取和卷积操作来决定模型复杂度及参数量。
YoloV5s输入保留了和YoloV4相同的Mosaic数据增强方法,将4幅图像随机缩放、剪裁、分布并拼接成一幅新的图片,如图5所示。增加自适应锚框的计算功能,即通过遗传算法和K-means算法在训练过程中不断迭代计算最优的锚框大小,可针对不同目标自动计算预测锚框以提高准确率。将原始图片送入检测网络前,自适应图片缩放功能将其尺寸处理成统一尺寸。
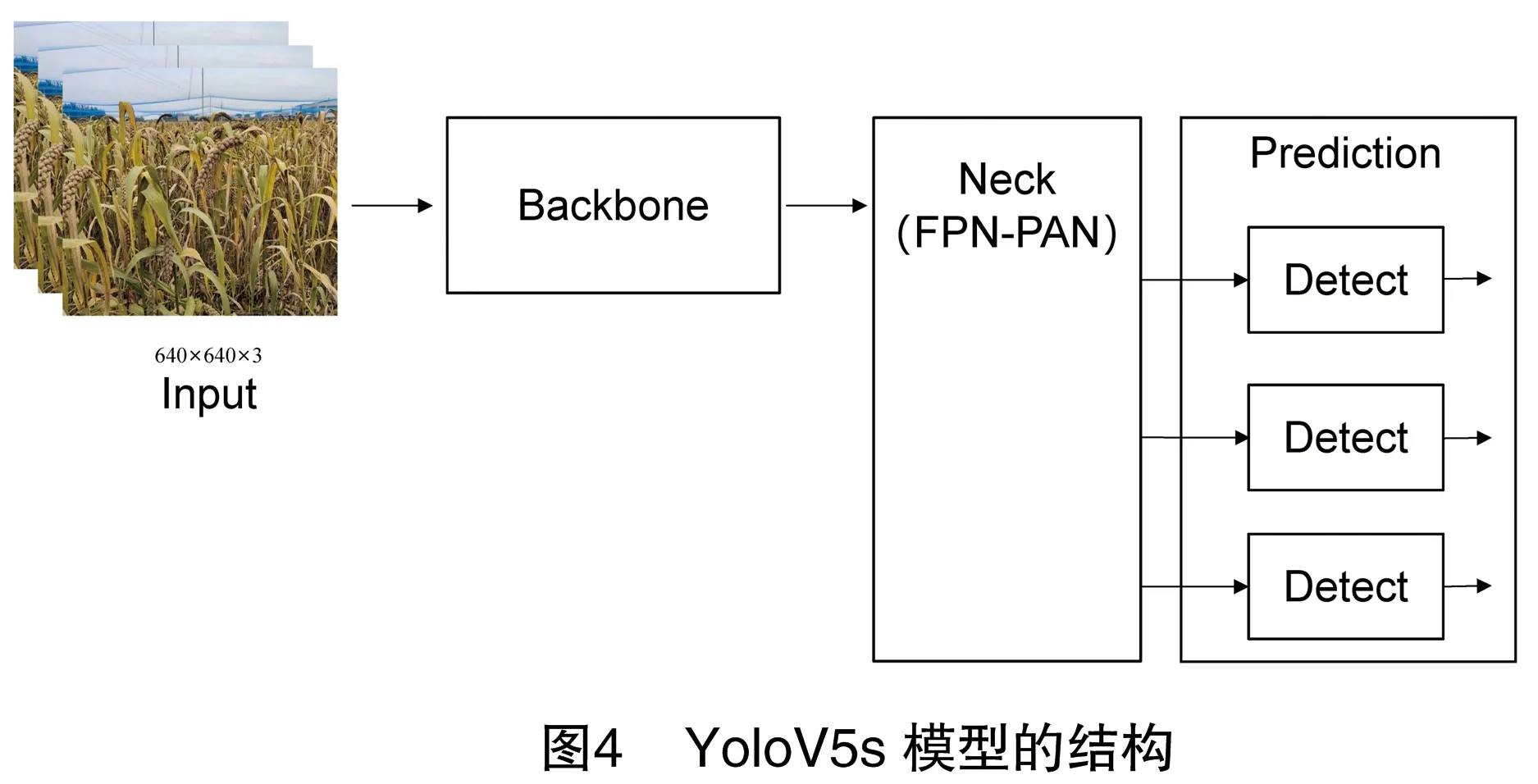

YoloV5s的Backbone增加Focus结构实现输入图像的切片操作,输入特征图的大小为640×640×3,经过Focus结构得到输出特征图的大小为320×320×32。主干网络沿用YoloV4的跨级部分网络(CSP)结构,主要使用残差网络结构提取输入图像的特征,其中卷积运算操作决定整个模型的复杂度和参数量[26]。
Neck使用FPN-PAN结构,特征金字塔网络(FPN)通过上采样将高层特征信息与主干特征提取网络的信息由上向下传递融合,金字塔注意力网络(PAN)结构由下向上通过下采样传达目标定位特征,二者结合使用提高模型的检测能力。
Prediction的边界框损失函数使用CIOU_LOSS(Complete IoU Loss)函数和非极大值抑制(NMS)的方法,可有效获得最佳预测锚框。
YoloV5在训练过程中采用梯度下降法优化目标函数,随着迭代次数的增加,损失值(LOSS)接近全局最小值,学习率也应变小。为使模型经过训练达到收敛状态最佳,YoloV5采用的余弦退火学习率即通过余弦函数降低学习率。余弦函数值随x的增加先缓慢下降,后快速上升,再缓慢下降,目的在于避免陷入当前局部最优点,不断调整学习率使模型收敛到一个新的最优点,直到模型训练停止。余弦退火学习率的原理如下:
(1)
式中:lnew表示最新学习率;i表示第i次执行(索引值);lmin表示学习率最小值;lmax表示学习率最大值;Tcur表示当前执行的epoch数量;Ti表示当前执行下epoch总数。
2.2 YoloV5模型改进
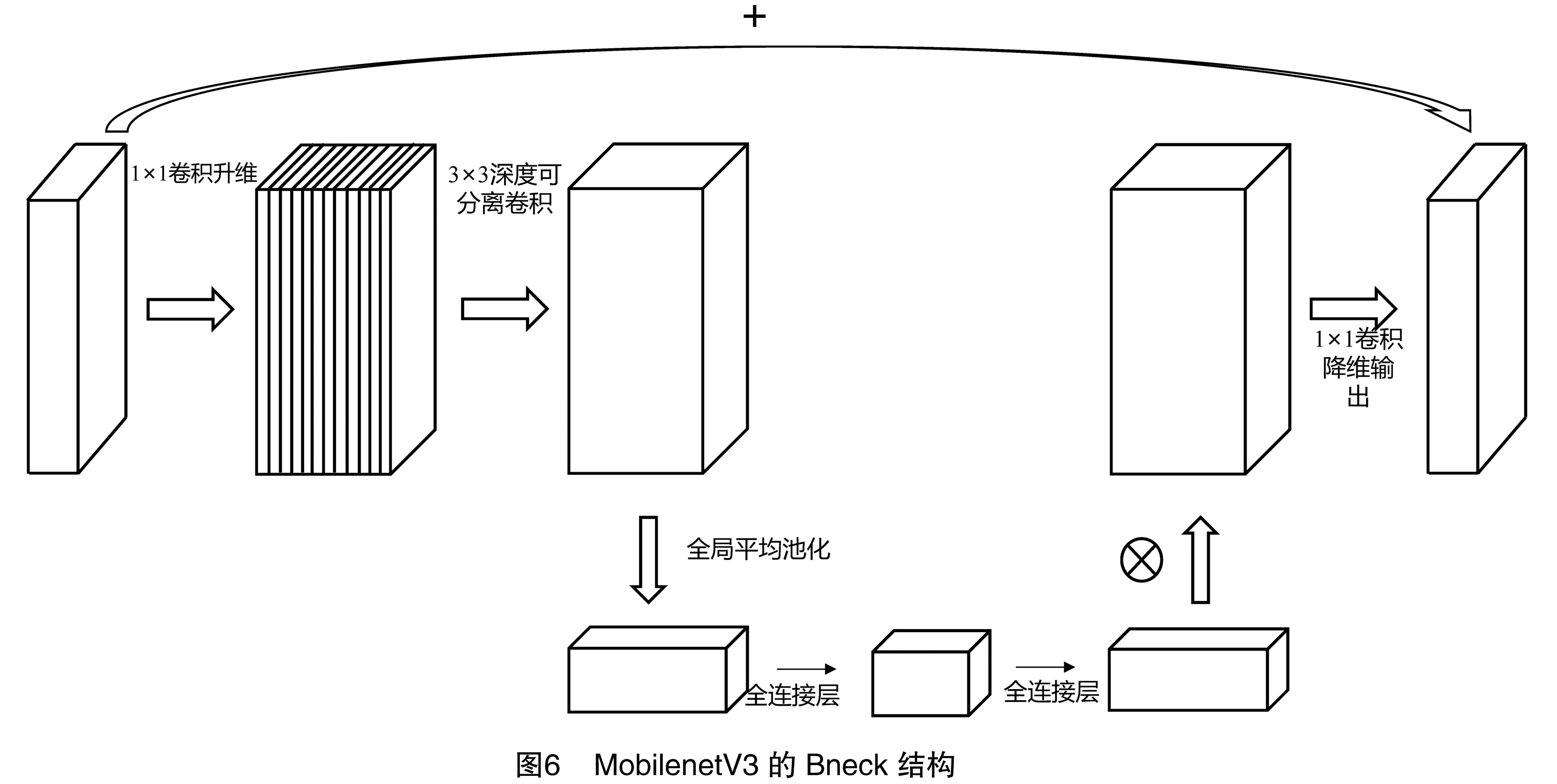
2.2.1 利用MobilenetV3修改YoloV5的模型结构 MoblienetV3[27]是兼并实时、速度、准确率的轻量级神经网络。MoblienetV3的主干网络基于倒置残差块组成的Bneck结构,包括普通卷积和深度可分离卷积,并在全连接层添加注意力机制(SE模块),如图6所示。与标准卷积相比,倒置残差块中的深度可分离卷积可以大幅减少整体模型的参数量及缩小模型尺寸[28]。
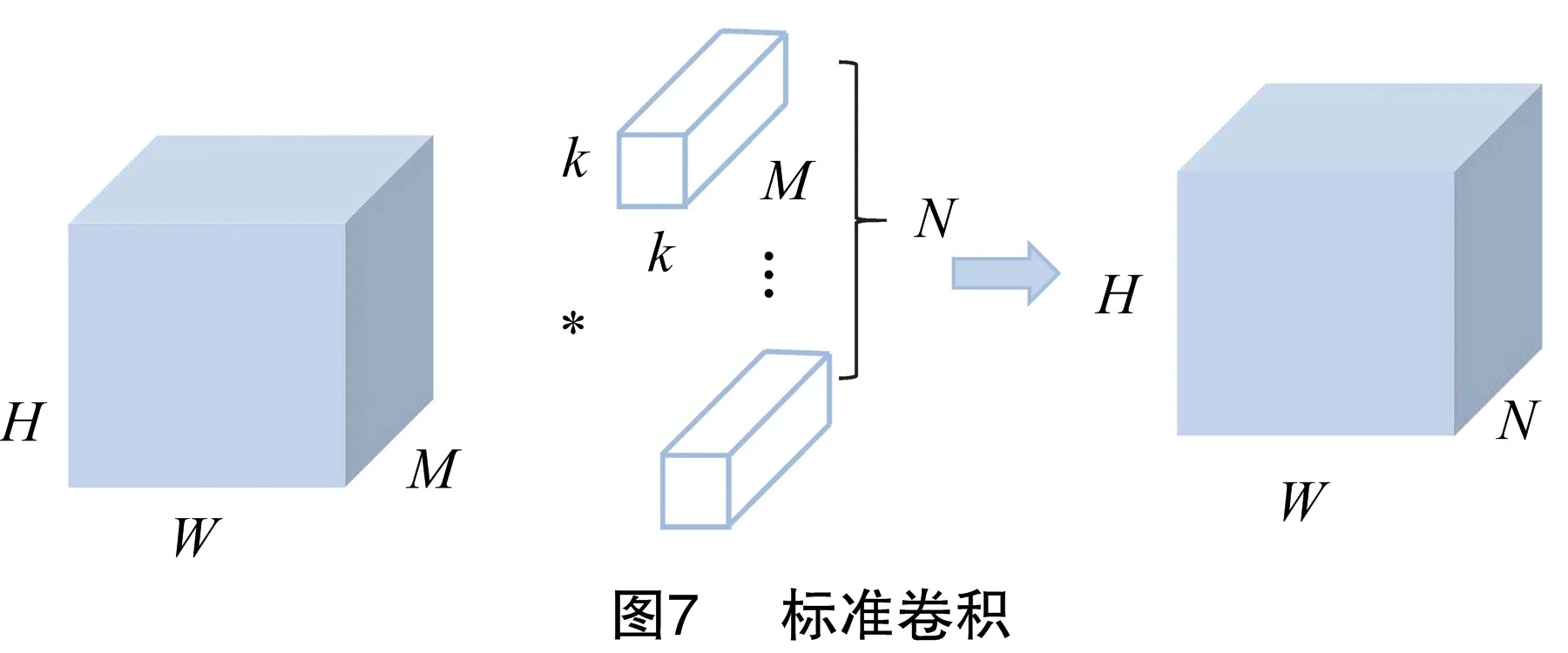
如图7所示,假设输入特征图尺寸为H×W×M(通道为M),经过N个k×k×M的标准卷积后得输出特征图的尺寸为H×W×N(通道为N)。标准卷积的参数量计算如下:
P1=k×k×M×N=k2×M×N。
(2)
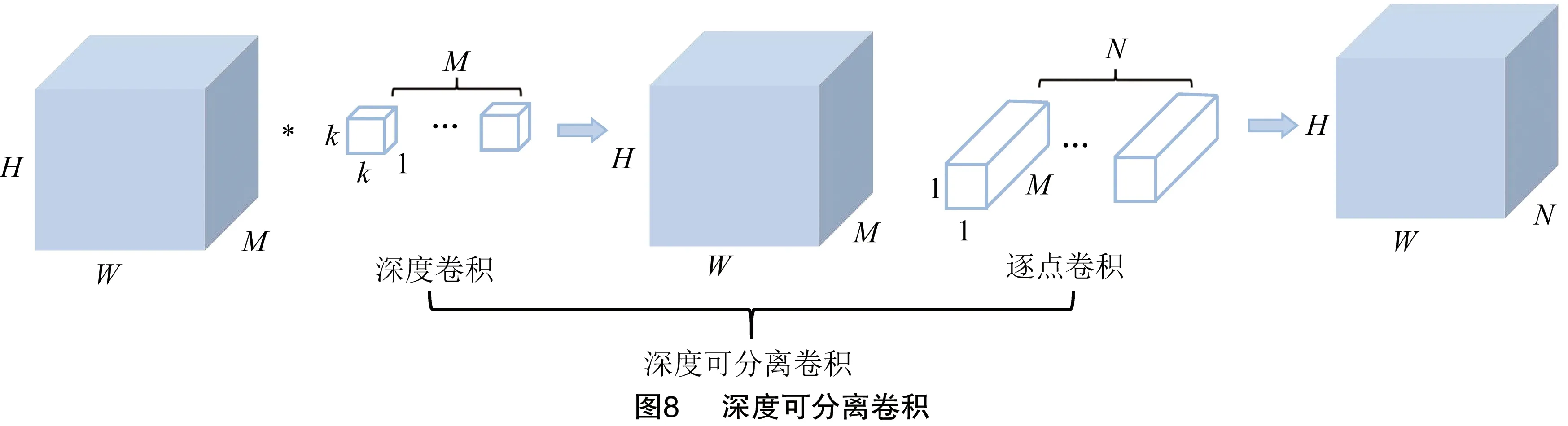
深度可分离卷积由深度卷积和逐点卷积共同组成,如图8所示。深度卷积的卷积核大小为k×k×1,其中有M个卷积核,它负责对输入的每个通道进行滤波。逐点卷积的卷积核为1×1×M,其中有N个卷积核,负责转换通道。深度可分离卷积的参数量计算如下:
P2=k×k×1×M+1×1×M×N=k2×M+M×N=M×(k2+N)。
(3)
因此,深度可分离卷积与标准卷积参数量相比计算如下:
(4)
2.2.2 Merge-NMS算法 图像受分辨率的影响会降低检测性能,即图像的模糊像素会导致检测目标边界模糊的问题。由于这一因素,不易准确区分
重叠谷穗和遮挡谷穗。本研究将标准非极大抑制值(NMS)改进为融合非极大抑制值(Merge-NMS)[29],减轻后处理过程中模糊的谷穗目标边界。标准NMS每次迭代结束只保留得分最高锚框,与这个锚框重叠的锚框都会被抑制,大量有价值的锚框也会被抑制。Merge-NMS利用被标准NMS抑制的锚框信息,并与其他锚框融合,从而得到一个更准确的预测锚框。Merge-NMS的伪代码见算法1,其中Box为检测锚框,Cls为分类置信度,Loc为位置置信度,Cls和Loc相乘得到锚框的最终得分S。开始时所有锚框都按得分S进行排序;在每次循环中,先从所有锚框中将得分最高的锚框(bm)拿出,与bm高度重叠锚框的得分若大于Merge-NMS的阈值,bm将与这些框合并,形成一个新的检测锚框,放入最终检测集D中。新检测锚框计算方法如下:
(5)
式中:xm是bm的坐标;xk是每次循环被选锚框的坐标。位置置信度越高lock的锚框在新检测锚框xm中占有更高的权重。
算法1 Merge-NMS
Input:Box=b1,…,bn;Cls=c1,…,cn;Loc=l1,…,ln;NMSthr,Mergethr。Box是检测边界框N×4矩阵;Cls和Loc分别是边界框的分类置信度和位置置信度;NMSthr是非极大抑制值的阈值;Mergethr为融合非极大抑制值的阈值。
Output:D,检测框最终置信度分数的集合
1:D ← Ø
2:S=Cls×Loc
3:T ← Box
4:while Box ≠ Ø
5: m=argmax(S)
6: Box=Box-bm
7: idx←IOU(bm,Box)>NMSthr
8: Box=Box-Box[idx]
9: idx←IOU(bm,T)> Mergethr
10: bm←∑T[idx]×Loc[idx]/∑Loc[idx]
11: D∪
12:end while
2.2.3 多特征融合检测结构改进 YoloV5s原结构设计了3个尺度特征检测层,对于输入图像分别使用8、16、32倍下采样的特征图去检测不同尺寸的目标。在网络模型中,低层特征图分辨率更高,包含目标特征明显,目标位置较准确;高层特征图在多次卷积操作后,获得丰富的语义信息,但也会使特征图分辨率降低。由于在实际环境获取的图像中谷穗尺寸参差不齐,在YoloV5s原结构的3层检测层下采样倍数较大,容易丢失关于小目标特征信息,高层特征图不易获得小目标的特征信息。本研究通过增加一个微尺度特征检测层,低层特征图与高层特征图通过拼接的方式融合后进行检测,可以有效提高检测准确率。
2.3 基于轻量化YoloV5的谷穗检测模型
如图9所示为基于轻量化YoloV5的谷穗检测模型结构,输入端的自适应图片缩放功能将输入图片处理成统一尺寸640×640×3,将YoloV5的Backbone模块替换为MobilenetV3作为特征提取网络,可以降低模型复杂度和减少模型计算量,但也容易漏检重叠和较小的谷穗。在多特征融合检测结构中增加微尺度特征检测层,减少在特征融合时信息的丢失,能更好地适应在自然田间复杂环境下对谷穗的检测,获得更多的目标信息,提高对小目标的检测。后处理阶段融合采用Merge-NMS算法,利用特征融合结构中获得的位置置信度合并锚框,减少边界模糊造成的误检、漏检。
3 结果与分析
3.1 试验平台
试验于2022年1月至2022年3月在山西农业大学实验室中进行,本研究基于Pytorch深度学习框架进行训练与测试,硬件配置为AMD Ryzen 7 5800H处理器,6 GB NVIDIA GeForce RTX 3060 Latop GPU GPU。运行操作系统为Windows 10,64位,Python 3.8.5,CUDA 11.4,cuDNN 8.2.4。
模型的批处理样本数为4,epoch设置为500个,即进行500次迭代。衰减系数为0.000 5,初始学习率为0.01,动量因子为0.937。
3.2 评价指标
本研究采用平均检测精度(AP,%)、F1分数(F1-score,%)、检测时间(s)、模型大小和浮点运算数(GFLOPs)作为评价指标。平均检测精度为精准率-召回率曲线(P-R曲线)即曲线下方与坐标轴围成的面积。F1分数为综合评价精准率和召回率的指标,反映模型整体的性能。检测时间为模型检测一幅图像的平均时间。模型大小,即模型在系统中占用内存空间的大小。浮点运算数,反映模型复杂度。精准率(P,%)、召回率(R,%)、AP值(%)和F1分数(%)的计算公式如下:
(6)
(7)
(8)
(9)
式中:TP为真阳性样本,表示正确识别谷穗的数量;FP为假阳性样本,即错误识别为谷穗的数量;FN为假阴性样本,即未识别的谷穗目标数量。
3.3 训练结果分析
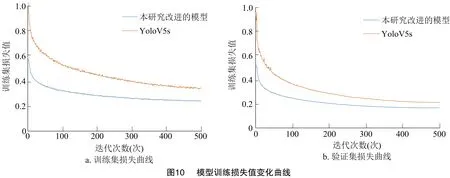
损失值随迭代次数的变化趋势反映模型训练效果,即损失值越接近0训练结束的模型效果越好。图10为本研究改进的YoloV5s模型和标准YoloV5s模型的训练损失值变化曲线。由图中曲线可以看出,2个模型随着训练迭代次数的增加,损失值都在减少,逐渐趋于平稳。改进的模型在迭代200次后,训练集损失值和验证集损失值逐渐收敛,训练集损失值小于0.28,验证集损失值小于0.2,迭代300次之后损失值变化基本平稳。标准模型YoloV5s在迭代350次之后训练集损失值和验证集的损失值逐渐收敛。标准模型YoloV5s趋于稳定后训练集损失值比改进的模型高26.02%,验证集的损失值比改进的模型高44.81%。本研究改进的模型训练集和验证集的损失值更接近0,表明模型训练的效果较好,并且整个模型的泛化能力较强。
3.4 模型改进的性能比较
为了验证各改进方法对模型性能的影响,本研究以标准YoloV5s模型为基础进行对比试验。试验结果见图11、表1,不同模型的检测效果可视化对比见图12,以反映各方法对模型影响的有效性。
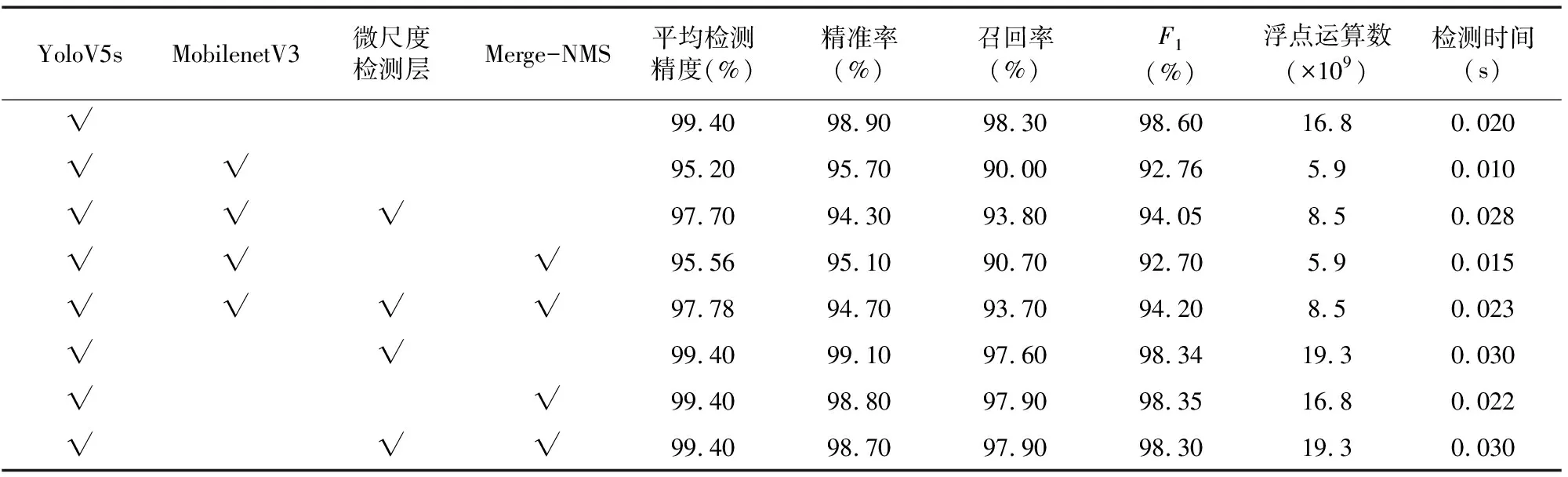
表1 不同改进方法对模型性能影响
本研究采用将MobilenetV3替换标准YoloV5s模型Backbone结构的方法减少模型体积,试验结果见图11。YoloV5s的模型体积为14.19 MB,YoloV5s-MobilenetV3的模型大小为6.77 MB,减少了 7.42 MB。YoloV5s-MobilenetV3模型单独增加微尺度检测使检测部分结构的复杂,会使模型大小略有增加,与YoloV5s-MobilenetV3相比仅增加了 0.79 MB,但仍比YoloV5s模型小46.7%。使用Merge-NMS算法不会增加模型体积,故单独使用Merge-NMS算法的YoloV5s-MobilenetV3模型体积为6.77 MB。本研究改进的模型即在YoloV5s-MobilenetV3上同时使用2种方法所构成的模型,其模型大小为7.56 MB,与标准YoloV5s模型的模型大小仍有较大的下降,下降了6.63 MB,由此证明MobilenetV3替换YoloV5s的Backbone结构的有效性。

由图11、表1得出,YoloV5s-MobilenetV3模型相比YoloV5s模型的体积大幅减少的同时,平均检测精度也出现大幅下降,下降了4.2百分点。YoloV5s-MobilenetV3模型的浮点运算数比YoloV5s模型少10.9×109,检测时间为0.010 s,进一步证明用MobilenetV3替换标准YoloV5s模型Backbone结构可以降低模型复杂度,减少检测时间。YoloV5s-MobilenetV3模型的F1分数比YoloV5s模型减少了5.84百分点,反映了模型结构经过轻量化替换其性能也会有一定的退化。分别在YoloV5s-MobilenetV3模型和YoloV5s模型上单独使用增加微尺度检测层,比YoloV5s-MobilenetV3模型和YoloV5s模型的浮点运算数都有较小的增加,说明微尺度检测层可以提升模型复杂度获得更多的目标信息,并且YoloV5s-MobilenetV3模型的平均检测精度从95.20%提高至97.70%,说明微尺度检测层能有效提高对小谷穗目标的检测。
在自然田间环境中谷穗目标分布非常密集,大小目标交替分布,并且谷穗缠绕、谷穗遮挡等情况较多,如图12-a所示,边界模糊的目标样本可能会作为负样本被漏检。评价指标表明TP值和FP值与模型性能直接相关,TP值越高,漏检样本越少,模型性能越好。为提高模型检测效果,本研究在后处理阶段采用Merge-NMS算法减少样本漏检,检测结果见图12。当YoloV5s-MobilenetV3模型后处理阶段采用Merge-NMS算法时,平均检测精度提高至95.56%,在测试集(共2 864个样本)检测的样本数据统计见表2。YoloV5s-MobilenetV3采用Merge-NMS算法后FN样本从286个减少到265个,最终本研究改进的模型FN样本减少到180个,召回率从90.00%增加到93.70%, 表明了Merge-NMS算法解决目标边界模糊问题的有效性。


表2 模测试集检测样本统计
将YoloV5s模型使用MobilenetV3轻量化改进后,模型复杂度的减少,使模型对目标的特征提取不充分,本研究通过在多特征融合检测结构中增加微尺度检测层,将高层特征图与低层特征图提取的目标信息有效融合,减少目标信息的丢失,提高对小目标的检测。同时使用Merge-NMS算法,可以对特征图中具有模糊边界的目标进行有效检测。如图12-f,为本研究改进模型的检测可视化效果图,前排谷穗目标基本被全部检测并标记,黄框中被遮挡的谷穗和尺寸较小的谷穗也被成功检测,表明轻量化模型YoloV5s-MobilenetV3同时使用2种方法可以有效提高模型的检测性能。
3.5 不同目标检测网络的综合对比
为验证在实际应用中谷穗检测模型的有效性,使用YoloV3、YoloV3-tiny、YoloV5-shufflenetV2等经典模型与本研究改进模型进行比较。试验使用相同640×640的图像作为输入,设置相同的模型参数,并在本研究自建的谷穗数据集上进行试验测试,结果见图13、表3。
从图13可以直观地看出本研究的改进模型和YoloV3模型的平衡点更接近点(1,1),并且本研究改进模型和YoloV3模型的P-R曲线下方与坐标轴构成的面积大于其他的模型,即平均检测精度较高。由表3对不同模型检测结果的对比可以得出,本研究在保证模型检测精度的同时,还兼具其他优点,如模型体积较小,浮点运算量较少。YoloV5-shufflenetV2模型和YoloV3-tiny模型的模型体积和浮点运算数比较小,但平均检测精度较低。YoloV3模型的检测精度较高,但模型大小达到18.05 MB,浮点运算数为本研究改进模型的2.7倍。结果表明,与其他模型相比本研究改进的模型在降低模型复杂度,减少模型体积的同时,保持了检测准确率和检测速度的平衡。
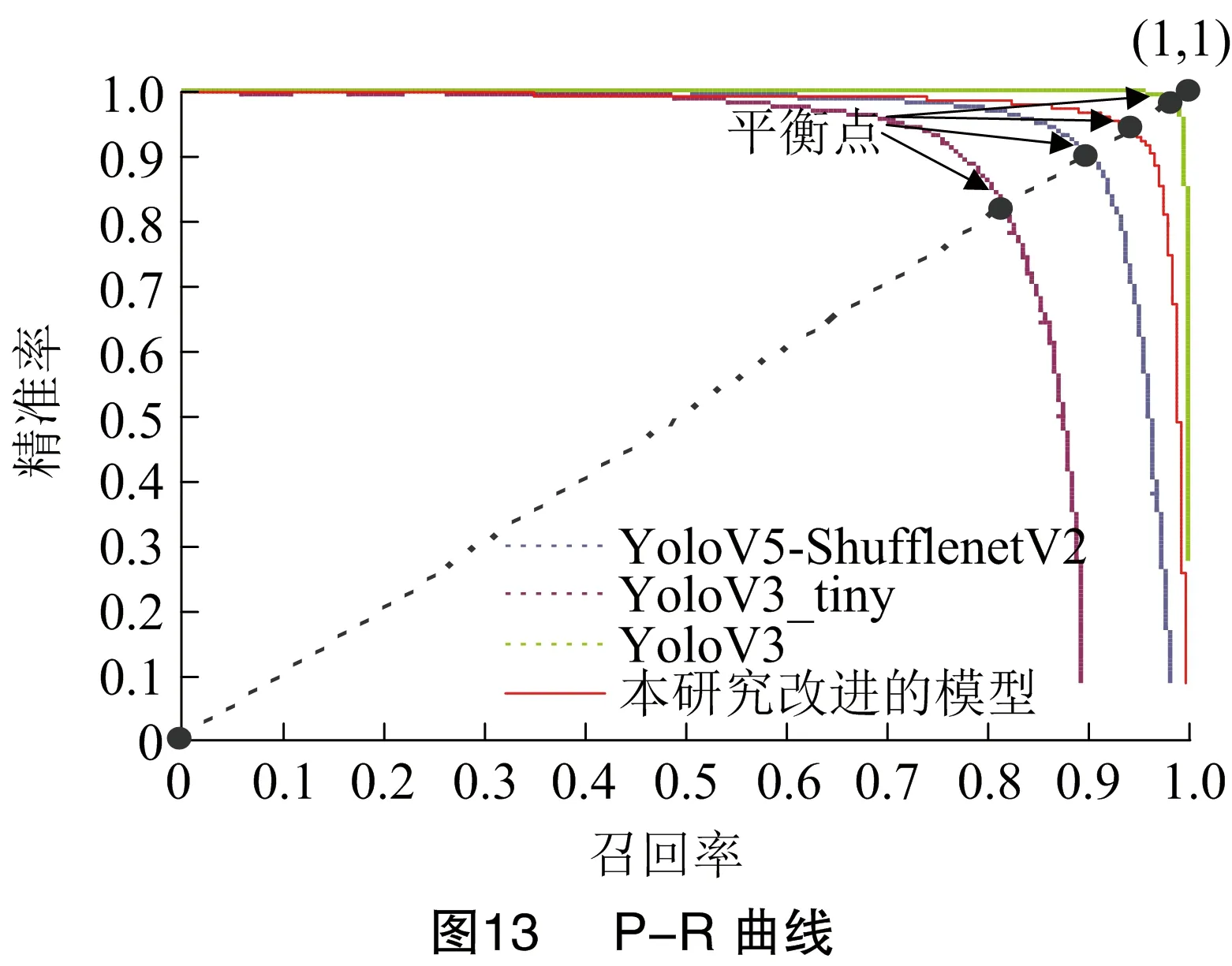

表3 不同模型的检测结果
4 结论
本研究提出一种基于轻量化YoloV5模型的谷穗检测模型,将YoloV5s主干特征提取网络替换成具有注意力机制的轻量级模型MobilenetV3,构建的YoloV5s-MobilenetV3模型具有轻量化特点,提高模型的可移植性。在多特征融合检测结构中增加微尺度检测层,后处理阶段采用Merge-NMS算法。将改进模型对自然田间环境密集、遮挡及目标大小分布不均等多种复杂情景中的谷穗进行检测。结果表明,本研究改进的模型平均检测精度为97.78%,F1分数为94.20%,模型大小和浮点运算数分别为7.56 MB和8.5×109,每幅图像的平均检测时间为0.023 s,为在嵌入式移动平台进行部署提高有利条件,节约人力资源,提高工作效率。根据田间实际环境的自然条件建立谷穗数据集,并使用YoloV3、YoloV3-tiny和YoloV5-shufflenetV2经典的目标检测模型进行测试对比,本研究的改进模型在保证模型轻量化的条件下,保持了较好的检测性能,保证了实时检测的可行性。对谷穗生长状况的检测和成熟后的收获具有重要的影响。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
好孩子画报(2022年6期)2022-12-01 07:10:32
轻音乐(2022年11期)2022-11-22 12:56:18
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
阅读(低年级)(2021年4期)2021-06-15 04:24:11
好孩子画报(2021年2期)2021-03-15 05:57:30
好孩子画报(2020年5期)2020-06-27 14:08:05
好孩子画报(2019年6期)2019-06-30 01:44:00
