
基于R-BERT-CNN模型的实体关系抽取
2023-05-08 03:01曹卫东徐秀丽
计算机应用与软件 2023年4期
曹卫东 徐秀丽
(中国民航大学计算机科学与技术学院 天津 300300)
0 引 言
随着互联网的发展,大量的非结构化数据应运而生,如何从海量的数据中提取出有价值的信息一直是专家学者研究的热点。实体关系抽取便是一项重要且具有挑战性的从非结构化文本中提取信息的任务,其目的是对非结构化的文本中所蕴涵的实体语义关系进行挖掘处理,从而整理成三元组REL(e1,e2)存储在数据库中,为之后的智能信息检索和语义分析提供了一定的支持和帮助。REL(e1,e2),表示REL在实体e1和实体e2之间保持的关系。例如给定一个句子:The most commonwere aboutand recycling。被包裹的词为实体,两个实体audits和waste的关系在SemEval-2010 Task8中表示为Message-Topic(e1,e2)。实体关系抽取作为许多下游任务的基石,在各种自然语言处理应用中起着重要作用,包括文本摘要、生物医学知识发现[1]、知识图谱[2]、问答系统[3]和机器翻译[4]等。
传统上,研究人员主要使用基于特征和基于核函数的方法进行实体关系抽取。Zhou等[5]融合基本的文法分块信息、半自动的收集特征,利用支持向量机进行实体关系抽取,在ACE数据集上F1值达到了55.5%;郭喜跃等[6]利用 SVM 作为分类器,分别研究词汇、句法和语义特征对实体语义关系抽取的影响;刘克彬等[7]在语义序列核函数的基础上,结合k近邻算法(KNN)进行实体关系抽取;郭剑毅等[8]利用融合了多项式函数和卷积树核函数的向量离散化的矩阵训练模型进行实体关系抽取任务,验证了多核融合方法较于单核方法性能更优。
但是传统方法往往严重依赖于手工特征和现有的自然语言处理工具,从而造成误差的积累传播。随着深度学习的发展,许多研究者提出了基于深度神经网络的关系抽取方法。Zeng等[9]在2014年首次提出使用卷积神经网络(CNN)进行实体关系抽取,提高了模型的准确性;Socher等[10]利用循环神经网络(RNN)对标注好的文本数据进行句法分析并不断迭代,在关系抽取任务上取得了比较好的效果;Zhang等[11]使用双向长短时记忆网络(Bi-LSTM),充分利用了当前词语前后的信息,其实验结果相比CNN方法提高了14.6%。但是这些方法通常都依赖于NLP工具获得的高级词汇和句法功能,例如词典(WordNet)[12],依赖解析器、词性标记器(POS)和命名实体识别器(NER)[13],无法有效利用数据本身隐含的信息。
研究表明,语言模型预训练[14]对于改善许多自然语言处理任务是有效的。Devlin等[15]提出的预训练模(Bidirectional Encoder Representation from Transformers,BERT)具有特别重要的影响,并已成功应用于多个自然语言处理任务中。Wu等[16]利用预先训练的BERT语言模型,并结合目标实体的信息来处理关系抽取任务并取得了显著的效果。
本文将预训练的BERT模型应用于实体关系抽取任务,将实体级别的信息融入预训练模型,并用卷积神经网络提取句子级别的信息,提出了预训练卷积神经网络模型(R-BERT-CNN)。模型在将文本输入到BERT进行微调之前,首先在目标实体之前和之后插入特殊标记,以便识别两个目标实体的位置并传输信息进入BERT模型,从BERT模型中定位两个目标实体在输出嵌入中的位置。然后使用它们的嵌入以及句子编码(在BERT设置中嵌入的特殊字符[CLS],[SEP])分别作为输入到CNN和全连接神经网络中进行关系抽取。它能够捕捉句子和两个目标实体的语义,以更好地适应关系抽取任务。本文主要有三个方面的贡献:
(1) 将实体级信息纳入预先训练的语言模型,并使用CNN提取句子级的信息,能够更好地捕捉句子和两个目标实体的语义,更好地适应关系抽取任务。
(2) 本文的模型在SemEval-2010 Task 8中获得了89.51%的F1分数,相较于其他的神经网络模型都有了不同程度的提高。
(3) 在没有依赖任何自然语言处理工具下,其性能优于现有的最新模型。
1 相关工作
1.1 预训练模型
预训练模型BERT模型是谷歌提出的基于多层双向Transformer[17]构建的语言模型,内部采用Transformer作为编码结构,比传统的循环神经网络具有更强的信息捕捉能力,在自然语言处理的多项任务中取得了良好的效果。BERT模型的本质是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓的自监督学习是指在没有人工标注的数据上运行的监督学习。在特定的NLP任务中,可以直接使用BERT的特征表示作为该任务的词嵌入特征。所以BERT提供的是一个供其他任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。
BERT的预训练阶段包括两个任务:一是掩盖语言模型(Masked Language Model,MLM);二是下一个句子预测(Next Sentence Prediction,NSP)。简单描述为:在一句话中mask掉几个单词然后对mask掉的单词做预测、判断两句话是否为上下文的关系,而这两个训练任务是同时进行的。MLM使得BERT能够从文本中进行双向学习,也就是说这种方式允许模型从单词的前后单词中学习其上下文关系。只要把对应的标签输入BERT,每一层Transformer层输出相应数量的隐藏向量,如此一层层传递下去,直到最后输出。
图1是BERT执行文本分类时的模型。BERT是一个句子级别的语言模型,可以直接获得整个句子的唯一向量表示。BERT的输入表示的设计应能够在一个标记序列中表示单个文本句子和一对文本句子。每个标记的输入由标记嵌入(Token Embeddings),片段嵌入(Segment Embeddings)和位置嵌入(Position Embeddings)的总和构成。Token Embeddings是在每个输入前面加的一个特殊的标签[CLS],可以使用Transformer对[CLS]进行深度编码,由于Transformer是可以无视空间和距离,把全局信息编码进每一个位置的,而[CLS]的最高隐藏层作为句子/句对的表示直接跟softmax的输出层连接,因此其作为梯度反向传播路径上的“关卡”,可以学到整个输入的上层特征;Segment Embeddings是使用[SEP]将两个句子分开,从而实现以两个句子作为输入的分类任务;Position Embeddings是用来表示输入句子向量中每个字词所对应的位置,由于Transformer无法像RNN一样获取句子的时序信息,所以需要Position Embeddings表示自此在句子中的先后顺序。
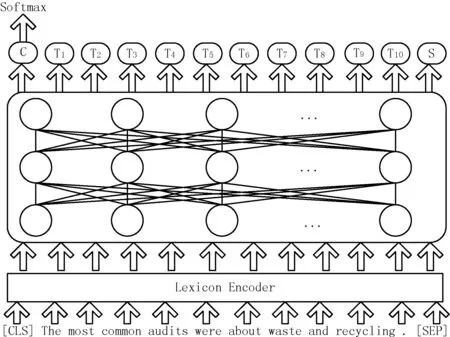
图1 Bert 文本分类结构
连接标签嵌入、分段嵌入和位置嵌入的向量通过框中的多层自注意力机制(变压器编码器),可以将输入语句映射到不同的子空间中,能够更好地理解到语句所包含的信息。对于每个输入标签,都有对应的输出值。其中,C是整个文本的表示形式,因为C获得了所有单词的信息。最后,将C输入到softmax层以获得分类结果。实际上C注重文本中每个单词的重要性,并且每个单词都是平等且独立的,但它不注意文本中某些片段或短语的信息。
1.2 卷积神经网络
近年来,深度神经网络在自然语言处理中取得了良好的效果。卷积神经网络(Convolutional Neural Network, CNN)[18]是由动物视觉的局部感受野原理启发而提出的,是深度学习技术中极具代表性的网络结构之一,在图像分析和处理领域取得了众多突破性的进展,在学术界常用的标准图像标注集ImageNet上,基于卷积神经网络的模型取得了很多成就,包括图像特征提取分类、场景识别等。卷积神经网络相较于传统的图像处理算法的优点之一在于避免了对图像复杂的前期预处理过程,尤其是人工参与图像预处理过程,卷积神经网络可以直接输入原始图像进行一系列工作,至今已经广泛应用于各类图像相关的应用中。最近的一些研究者也将CNN应用到自然语言处理领域,并取得了一些引人注目的成果。
卷积神经网络丰富的卷积核可以用于提取各类特征,尽管这些特征大多数都是不可解释的,但却是非常有效的,因此通过不断的卷积,CNN 能够自动发现一些文本中隐含的隐性特征。CNN的网络结构如图2所示。
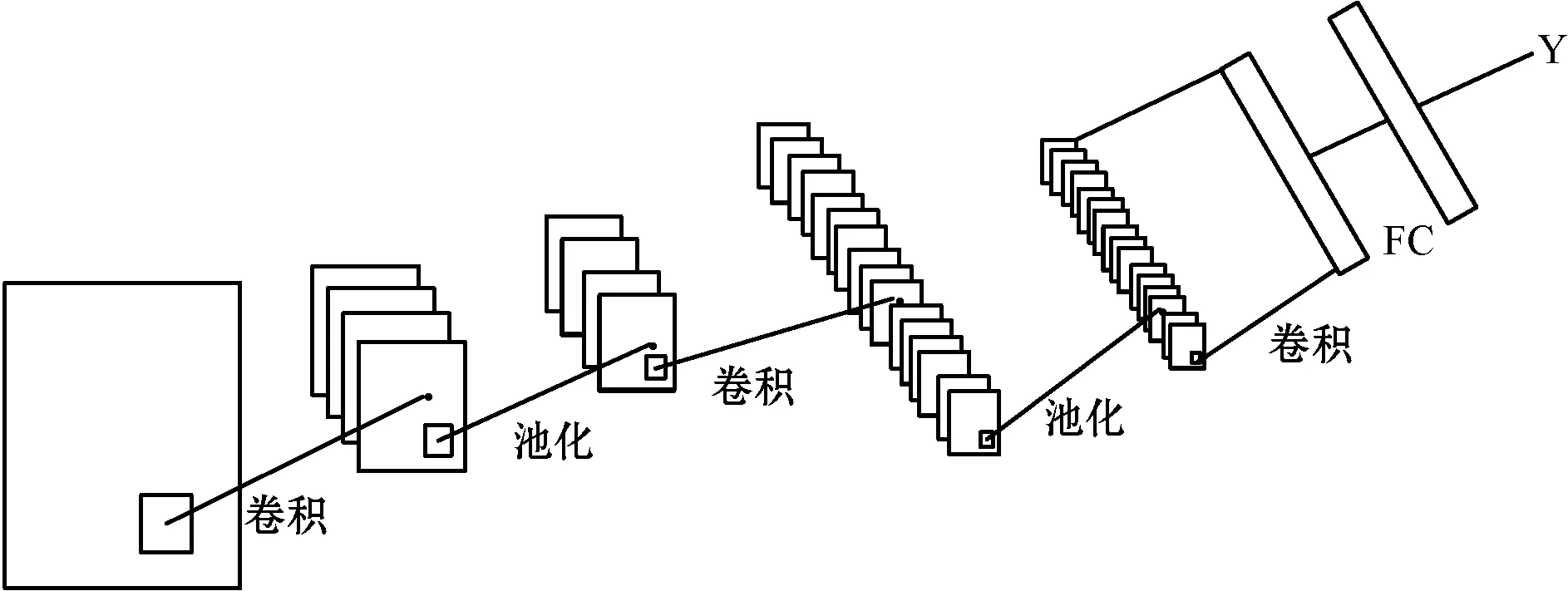
图2 CNN结构图
CNN的本质是输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络进行训练,网络就具有输入和输出的映射关系。CNN通常是由数据输入层、卷积计算层、池化层、全连接层组成。
卷积层是CNN最重要的一个层次,一般会有一个或多个卷积层。卷积层中有两个关键操作:局部关联,把每个神经元看作一个滤波器(filter);窗口滑动,使用过滤器对局部数据集逆行计算。卷积的主要作用就是提取特征,因为一次卷积可能提取的特征比较粗糙,多次卷积,可以提取每一层特征,使得提取的特征更加精细;池化层也叫降采样层,夹在连续的卷积层中间,用于降低数据的维度,避免过拟合,从而提升特征提取鲁棒性,提高计算速度;全连接层通常在卷积神经网络的尾部,其作用主要是对特征进行整合,池化层的输出以全连接的形式传递给全连接层,通过分类器得到分类(预测结果),再将预测的结果与实际的结果进行比较,通过损失函数梯度下降反向传播的方式更新网络参数。
2 R-BERT-CNN模型
为了更好地获得文本和两个目标实体的语义信息,本文提出了用于关系抽取任务的R-BERT-CNN模型。模型主要分为五个部分:输入层、预训练层、语义提取层、全连接层和输出层。构建的模型结构如图3所示。模型进行实体关系抽取任务的流程为:

图3 R-BERT-CNN模型
Step1数据预处理,将数据添加[CLS]、[SEP]标签和一些特殊的规范字符。
Step2将处理好的数据输出到BERT模型中进行预训练。
Step3BERT预训练完成后,对实体向量取平均并激活,再分别使用CNN和全连接神经网络提取句子和两个目标实体中的语义信息。
Step4将提取的标签语义,句子语义和实体语义信息进行全连接。
Step5通过Softmax分类器对实体关系进行抽取,输出两个目标实体的关系。
2.1 输入层
模型的输入是一个具有两个目标实体e1、e2的标签序列s。其中s={x1,x2,…,xn},xi为句子的第i个词向量,n为模型设置的输入句子的最大长度。为了使BERT模块更好地捕获两个实体的位置信息,在第一个实体的开头和结尾,插入一个特殊的规范字符“$”,在第二个实体的开始和结束位置,插入一个特殊的规范字符“#”。同时还在每个句子的开头和结尾分别添加了[CLS]和[SEP]标签。例如,在插入特殊的标记后,对于目标实体为“audits”和“waste”的句子,输入格式为:[CLS]The most common$audits$were about # waste # and recycling.[SEP]。
输入处理模块将每个xi编码成一个包含两个目标实体和特殊标签符号的向量ei的公式为:
ei=Etoken(xi)+Eseg(xi)+Epos(xi)
(1)
式中:Etoken(xi)表示词嵌入;Eseg(xi)表示片段嵌入;Epos(xi)表示位置嵌入。
2.2 预训练层
输入处理模块通过BERT中的Transformer预训练后输出相应数量的隐藏向量,一层层传递下去,直到最后输出。设经过预训练BERT后最终输出的隐藏向量是H={H0,H1,…,Hn}。其中包含了[CLS]标签向量,实体e1最终的隐藏状态向量,实体e2最终的隐藏状态向量和其他字向量的隐藏向量。假设[CLS]标签向量为H0,向量Hi到Hj是实体e1的BERT的最终隐藏状态向量,而Hk到Hm是实体e2的BERT的最终隐藏状态向量。
2.3 语义提取层
语义提取分为标签语义提取,实体语义提取和句子语义提取。标签语义主要提取[CLS]标签信息;实体语义提取主要是提取实体标签信息并平均两个实体向量;句子语义提取为使用CNN提取句子级别的信息。
2.3.1 标签语义提取
[CLS]标签向量可以作为整篇文本的语义表示。通过预训练处理后得到[CLS]标签向量,直接输入全连接层并添加激活函数(tanh)获得整个句子的标签信息。输出H′0的过程可以表示为:
H′0=W0(tanh(H0))+b0
(2)
式中:W0是参数矩阵,且W0∈Rd×d,d是BERT的隐藏状态大小;b0是偏差向量。
2.3.2 实体语义提取

(3)
(4)
式中:W1、W2是参数矩阵,具有相同的维度,即W1∈Rd×d,W2∈Rd×d,d是BERT的隐藏状态大小;b1、b2是偏差向量,且W1=W2,b1=b2。
2.3.3 句子语义提取
为了使文本的表现更好地集中在句子中的局部信息上,如一个简短的句子和短语,我们使用卷积神经网络对BERT层的输出矩阵H={H0,H1,…,Hn}进行卷积、降采样操作,然后通过一层拼接层,提取文本特征。假设卷积核长度为k,即每次对k个分词向量进行卷积操作,卷积核滑动的步长一般设为1,对文本矩阵进行上下滑动,则H可以分成{H0:k,H1:k+1,H2:k+2,…,Hn-k+1:n},其中Hi:j表示向量Hi到Hj的所有向量的级联,对于每一个分量执行卷积操作后得到向量C={C0,C1,…,Cn-k+1},而Ci是对分量Hi:i+k-1执行卷积操作后得到的值,称为一个局部特征映射,计算公式为:
Ci=W3THi:i + k-1+b3
(5)
式中:W3是卷积核的参数,按照均匀分布随机初始化,并在模型训练过程中不断学习;b3是偏差向量。
接着对卷积捕获的文本特征映射向量C进行池化操作,采用最大池化操作,公式为:
(6)
则对于q个卷积核得到的结果为:
(7)
卷积操作实质上完成了对文本特征中表示局部重要信息的捕获,池化操作则完成了局部重要特征的提取。经过全连接后CNN的输出向量为最终的向量C′。
2.4 全连接和输出
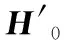
(8)
p=softmax(h″)
(9)
式中:W4∈RL×4d,L是关系类型的个数,b4是偏差向量,p是概率输出。
Softmax输出的是一个概率值,根据概率值可以预测两个目标实体的关系并输出。
3 实验与分析
3.1 实验环境
模型实验环境为:Windows 10操作系统,i7-9570H处理器,16 GB内存,GTX1060 Ti 6 GB显卡,Python 3.7编程语言,PyTorch深度学习框架,PyCharm开发环境。
3.2 实验数据
在SemEval-2010 Task 8数据集上评估本文模型,它是关系抽取的常用基准,并将实验结果与该领域最先进的模型进行比较。数据集中包含10种关系,每种关系及其数量如表1所示。其中前9个关系是有序的,Other没有方向。关系的方向性有效地使关系的数量加倍,因为只有当顺序也正确时,才认为实体对被正确标记,所以最终存在19个关系(2×9+1)。该数据集包含10 717个标注的句子,8 000个样本用于训练,2 717个样本用于测试。

表1 数据集
3.3 评价标准
对于实验效果的评估主要采用SemEval-2010 Task 8的官方评估指标,该指标基于宏观平均F1得分(不包括Other),并考虑了方向性。另外,一些实验还使用精确率(P)、召回率(R)作为实验的评估指标,其计算公式为:
(10)
(11)
(12)
式中:TP表示属于关系r的样本被正确识别为关系r;TN表示为属于关系r的样本被错误识别为其他关系;FP表示不属于关系r的样本被错误识别为关系r;FN表示不属于关系r的样本被正确识别为对应的关系。
3.4 实验参数设置
用交叉熵作为损失函数。训练期间在每个完全连接的层之前应用dropout方法,防止过拟合。并采用Adam优化器,关于预先训练的BERT模型的参数,参考[15]中的配置。本文实验主要的参数设置见表2。

表2 参数设置
3.5 实验结果分析
3.5.1 单个关系实验结果
为了验证本文提出的R-BERT-CNN模型的有效性,在SemEval-2010 Task 8数据集进行实验,表3的结果显示了针对每种关系类型和总体关系在测试集上模型的性能。总体关系Overall不包括Other。
实验结果显示,除Other关系,Instrument-Agency关系的准确率、召回率和F1值最低,原因是在数据集中这个关系类别数量少,在训练过程中不能更好地学习,导致模型输出这种关系的概率较小;其次性能比较差的是Component-Whole和Member-Collection关系,因为这两种关系在关系清单种类中是两种相近的关系,都是Part-Whole的特殊情况。其余的关系类型在测试集上模型的性能和总体关系各项评价指标相差不大。
3.5.2 对比实验
本组实验使用官方评价标准宏平均F1值比较了本文提出的模型与最近发布的SemEval-2010 Task 8数据集的多个模型,模型的实验结果来自对应的论文。各模型的F1值的实验结果如表4所示。

表4 实验结果对比
支持向量机(SVM)[19]是一种非神经网络模型,使用SVM分类器捕获上下文,语义角色从属关系以及名词可能存在的关系的功能来执行分类,在SemEval比赛中获得了最佳结果;Attention-CNN[20]是基于注意力的卷积神经网络架构,充分利用了词嵌入,词性标签嵌入和位置嵌入信息;Att-Pooling-CNN[21]是一个基于多Attention机制CNN网络的实体关系抽取模型;C-GCN[22]是一种图卷积网络,它能够有效地并行存储任意依赖结构的信息;Entity Attention Bi-LSTM[23]是一种端到端循环神经模型,结合了具有潜在实体类型(LET)方法的感知实体的注意力机制。
实验结果表明,本文R-BERT-CNN模型,相较于基准模型,有了明显的提高,F1值达到了89.51%。支持向量机SVM的性能最差,因为该模型依赖于人工设置的语义关系分类,从而造成误差的积累传播;改进CNN的神经网络Attention-CNN,Att-Pooling-CNN,C-GCN模型也都获得了不错的效果,但它们依赖于NLP工具的高级词汇和句法功能,本文R-BERT-CNN模型在没有使用任何NLP的工具下相较于C-GCN,Attention-CNN,Att-Pooling-CNN,其F1值分别提高了4.71、3.61和1.51百分点;Entity Attention Bi-LSTM可以有效地利用实体及其潜在类型,但没有利用句子级别的信息,而R-BERT-CNN模型可以充分利用句子级和实体级别的信息,相较于Entity Attention Bi-LSTM模型F1值提高了1.51百分点。
3.5.3 消融实验
为了解实体级信息和句子级信息分别对关系抽取结果的影响,分别创建了单独获取句子信息(BERT-CNN)和单独获取实体信息(R-BERT)的模型,并进行实验结果对比。
BERT-CNN模型是没有将实体级信息融入预训练模型的纯BERT与CNN的结合,即丢弃围绕句子中的两个实体的特殊单独标注(即“$”和“#”),但保持两个实体的隐藏向量输出,换句话说,只在句子的开头添加“ [CLS]”,并将带有两个实体的句子输入BERT模块,然后使用BERT预训练后第一个输出向量H直接输入CNN后添加全连接层和softmax层进行抽取。
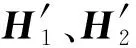
在本组实验中,使用BERT预训练模型的实验结果值均由本文的实验环境运行得出。表5是消融实验的结果。

表5 消融实验结果(%)
表5表明了本文提出的R-BERT-CNN模型综合评价指标优于其他两个模型。在准确率上,比BERT-CNN和R-BERT分别提高了2.87百分点和1.78百分点。在召回率上,与R-BERT模型结果相当,比BERT-CNN模型提高了2.34百分点。在F1值上,比BERT-CNN和R-BERT分别提高了2.61百分点和0.97百分点。分析其原因,BERT-CNN模型只考虑了句子级别的语义关系,没有使用特殊标记字符,无法定位目标实体,造成实体信息丢失;R-BERT模型只在预训练阶段融入了实体信息,没有考虑到文本句子的上下文语义。
为了分析模型的时间性能,本文比较了三种模型的在SemEval-2010 Task 8数据集上完成五次迭代需要的时间,实验结果如图4所示。

图4 模型训练时间对比
图4显示本文提出的模型相较于其他两个模型训练时间分别缩短了15、19 min,这是因为句子语义和实体语义是并行提取的,模型在训练过程中能够获取到所需要的各种数据,所以同时获取文本中的两种语义,并没有增加训练时间,反而提高了训练速度。
综上可以表明,实体语义和句子语义对关系抽取任务有着至关重要的作用,本文提出的R-BERT-CNN模型能够充分利用文本数据的信息,在提高关系抽取任务的各项性能的同时缩短了模型的训练时间。
3.5.4 优化器对关系抽取的影响
优化器对实体关系抽取的效果有很大的影响,因此选用合适的优化器对模型的性能有至关重要的作用。本组实验对比了不同的优化器的性能,分别选用自适应矩估计(Adam)、自适应梯度下降(AdaGrad)和随机梯度下降(SGD)三种优化器,对其实验重复十次,每次实验迭代五次取平均的结果如图5所示。

图5 不同优化器对实验结果的影响
由图可知,使用SGD优化器的模型效果最差,可能是因为SGD更新比较频繁,造成损失函数有严重的动荡,从而陷入局部最优解;AdaGrad优化器使用梯度平方和作为分母,比较适合稀疏的数据;Adam优化器可以计算每个参数的自适应学习率,使得模型达到最高的结果,比其他适应性学习方法效果要好。
4 结 语
本文提出了一种R-BERT-CNN模型,用于抽取实体之间的关系。该模型将实体级信息纳入预先训练的模型,并使用CNN提取句子级的信息,能够更好地捕捉句子和两个目标实体的语义,提升了实体关系抽取任务的性能。模型能够并行提取句子语义和实体语义,提高了训练速度,减少了收敛时间。采用SemEval 2010 Task 8数据集的实验结果验证了该模型在关系抽取任务上在没有依赖任何自然语言处理工具情况下,不仅能够获得较好的评价指标,还缩短了训练时间,在实体关系抽取任务上有重要的应用价值。
本文只考虑了在特定关系类别下的关系抽取,在以后的研究中,将考虑无监督情况下的关系抽取任务,得出文本中丰富的语义关系。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
